结构化文本计算示例(二)
上一节讲述了结构化文本的一些基本运算,本节继续用案例讲述二目运算和综合运算。
二目运算
集合运算(文件比较)
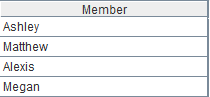
现有文件f1.txt和f2.txt,第一行是列名,需要对文件中的Name字段进行交集运算。部分数据如下:
文件f1.txt:
Name Dept Rachel Sales Ashley R&D Matthew Sales Alexis Sales Megan Marketing |
文件f2.txt:
Name Dept Emily HR Ashley R&D Matthew Sales Alexis Sales Megan Marketing |
代码如下:
A |
B |
|
1 |
=file("E:\\f1.txt").import@t() |
=file("E:\\f2.txt").import@t() |
2 |
=[A1.(Name),B1.(Name)].isect() |
函数isect用于集合间的交集运算,A1.(Name)表示取出A1的Name列,形成一个集合,B1.(Name)表示取出B1的Name列。本案例的最终结果如下:
类似地,求并集用函数union,差集可用diff,合集可用conj(相当于union all)。也可以直接用运算符来代替函数,写法更加简洁,比如交集,并集、差集、合集可以改写为:
A1.(Name) ^ B1.(Name)
A1.(Name) & B1.(Name)
A1.(Name) \ B1.(Name)
A1.(Name) | B1.(Name)
上面的示例显示了读入文本文件并自动拆分为字段后,仅取其中的某一列进行集合运算。那如果想不拆分字段,对整行数据一起比较呢?很简单,在导入的选项加上 s 即可,表示不拆分字段。但需要注意的是,不进行拆分后,相当于直接返回一个只有一列的序表,且此时的列名也没有拆分,变成了Name(Tab)Dept,也就是此时的列名中包含了不可见字符 Tab,这列名是非法的,都没法直接引用了。不过还好可以用序号来表示第几列,此时的代码如下:
A |
B |
|
1 |
=file("D:\\f1.txt").import@ts() |
=file("D:\\f2.txt").import@ts() |
2 |
=A1.(#1)^B1.(#1) |
显然,不拆分字段时,肯定只有一列,与其得到一个非法的列名,还不如不要列名,直接返回成集合(序列)多好,此时需要额外加上选项 i,表示只有一列数据时,直接返回成序列。此时交集直接就是集合的运算了,写成 A1^B1 即可,代码如下:
A |
B |
|
1 |
=file("D:\\f1.txt").import@tis() |
=file("D:\\f2.txt").import@tis() |
2 |
=A1^B1 |
上面两种算法,得到的都是相同的结果:
归并
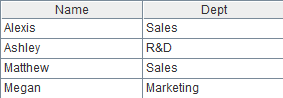
现有table1.txt和table2.txt已按逻辑主键ID1、ID2排序。现在要根据主键用table2更新table1,即主键相同其他字段不同时更新table1,主键不同时向table1插入数据。
源数据如下:
Table1 |
Table2 |
ID1 ID2 Col1 Col2 2 B1 2B1 row 2 B2 2B2 row 3 B1 3B1 4 B3 4B3 Row |
ID1 ID2 Col1 Col2 1 B1 diff row 2 B1 diff row 2 diff diff row 3 B1 3B1 |
用table2更新table1之后,table1应当如下:
ID1 |
ID2 |
Col1 |
Col2 |
1 |
B1 |
diff |
row |
2 |
B1 |
diff |
row |
2 |
B2 |
2B2 |
row |
2 |
diff |
diff |
row |
3 |
B1 |
3B1 |
|
4 |
B3 |
4B3 |
row |
代码如下:
A |
B |
|
1 |
=file("D:\\table1.txt").cursor@t() |
=file("D:\\table2.txt").cursor@t() |
2 |
=[B1,A1].mergex@u(ID1,ID2) |
|
3 |
=file("D:\\result.txt").export@t(A2) |
以游标方式读取table1.txt和table2.txt,按照逻辑主键用B1更新A1。函数mergex可进行数据归并,并保持结果仍有序,@u表示计算并集。最后将计算结果写入新文件。
这个代码使用了游标,不必考虑内存对数据文件的大小的限制,因此可以处理非常大的文件。
如果文件本身无序,那么需要先排序再归并,这时只需要将每个游标附加一个排序表达式即可,A2可以改写为:
[B1.sortx(ID1,ID2),A1.sortx(ID1,ID2)].mergex@u(ID1,ID2)
有序集合运算
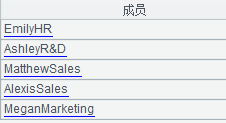
假设文件f1.txt和f2.txt已按Name和Dept排序,需要计算两者的交集。源数据如下:
文件f1.txt:
Name Dept Alexis Sales Ashley R&D Matthew Sales Megan Marketing Rachel Sales |
文件f2.txt:
Name Dept Alexis Sales Ashley R&D Emily HR Matthew Sales Megan Marketing |
当文件有序时,可以通过归并算法来实现集合运算,其性能比普通集合运算更高。代码如下:
A |
B |
|
1 |
=file("D:\\f1.txt").import@t() |
=file("D:\\f2.txt").import@t() |
2 |
=[B1,A1].merge@i(Name,Dept) |
|
3 |
=file("D:\\result.txt").export@t(A2) |
merge表示对序表进行归并,@i表示交集,@u表示并集,@d表示差集。
计算结果如下:
如果文件本身无序,可先用函数sort排序,但要注意小文件排序归并比普通集合运算更慢,所以本方法适合较大的文件。
关联计算
emp.txt是用tab分隔的文本文件,其EId字段对应sales.txt中的SellerId字段,现在要将emp.txt的Name、Dept、Gender这三个字段对齐到sales.txt。
源数据如下:
EId |
State |
Dept |
Name |
Gender |
Salary |
Birthday |
2 |
New York |
Finance |
Ashley |
F |
11000 |
1980/07/19 |
3 |
New Mexico |
Sales |
Rachel |
F |
9000 |
1970/12/17 |
4 |
Texas |
HR |
Emily |
F |
7000 |
1985/03/07 |
5 |
Texas |
R&D |
Ashley |
F |
16000 |
1975/05/13 |
6 |
California |
Sales |
Matthew |
M |
11000 |
1984/07/07 |
7 |
Illinois |
Sales |
Alexis |
F |
9000 |
1972/08/16 |
8 |
California |
Marketing |
Megan |
F |
11000 |
1979/04/19 |
代码如下:
A |
|
1 |
=sOrder=file("D:\\sales.txt").import@t() |
2 |
=emp=file("D:\\emp.txt").import@t(EId,Name,Dept,Gender) |
3 |
=join@1(sOrder:s,SellerId;emp:e,EId) |
4 |
=A3.new(s.OrderID, s.Client, s.SellerId, s.Amount, s.OrderDate, e.Name, e.Dept, e.Gender) |
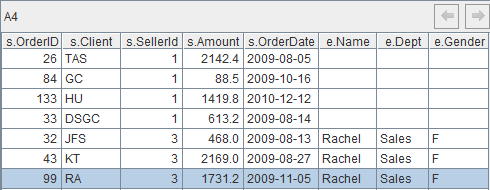
函数join执行连接运算,并将两个表改名为s和e,默认内连接,@1表示左连接,@f表示全连接。之后从连接的表中取得需要的字段,组成新的二维表。结果如下:
综合运算
多层关联
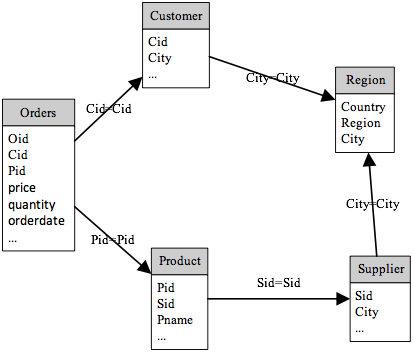
下面的例子中共有5个数据源文件,其中订单是事实表,客户、产品、地区、供应商是维表。我们需要过滤出客户和供应商属于同一个地区的订单,然后根据这些订单按城市分组,汇总各城市的订单数和订单金额。
关系结构如下图:
代码如下:
A |
|
1 |
=file("D:/files/orders.txt").import@t() |
2 |
=file("D:/files/customer.txt").import@t() |
3 |
=file("D:/files/product.txt").import@t() |
4 |
=file("D:/files/supplier.txt").import@t() |
5 |
=file("D:/files/region.txt").import@t() |
6 |
=A2.switch(city,A5:city) |
7 |
=A4.switch(city,A5:city) |
8 |
=A3.switch(sid,A4:sid) |
9 |
=A1.switch(pid,A3:pid; cid,A2:cid) |
10 |
=A1.select(pid.sid.city.region==cid.city.region) |
11 |
=A10.groups(cid.cid:cid;count(oid):count,sum(price*quantity):amount) |
读入文本,建立事实表和维表之间的关联,之后按关联关系查询订单,再进行分组汇总,其中函数switch用于建立外键关联。
异构文件比较
Data.txt是tab分隔的文本,共有6个字段,其中here字段是分号分隔的字符串。另有文件list是单列数据。现在要比较这两个文件,如果某条记录的here字段拆分后和List.txt中的任意一行匹配,则将这条记录输出到result.txt中。
源数据如下:
List.txt
Gee |
Whiz |
Lol |
Data.txt
field1 |
field2 |
field3 |
here |
field5 |
etc |
A |
B |
2 |
Gee;Whiz;Hello |
13 |
12 |
A |
B |
2 |
Gee;Whizz;Hi |
56 |
32 |
E |
4 |
Btm;Lol |
16 |
2 |
|
T |
3 |
Whizz |
13 |
3 |
代码如下:
A |
|
1 |
=file("d:\\Data.txt").import@t() |
2 |
=file("d:\\List.txt").read@n() |
3 |
=A1.select(here.array(";")^A2!=[]) |
4 |
=file("d:\\result.txt").export@t(A3) |
A3格子的代码中使用函数select进行查询,条件为here字段用array拆分为字符串序列后,再跟A2序列求交(“^”)集,结果不为空(“[]”)。
结果如下:
field1 |
field2 |
field3 |
here |
field5 |
etc |
A |
B |
2 |
Gee;Whiz;Hello |
13 |
12 |
A |
B |
2 |
Gee;Whizz;Hi |
56 |
32 |
E |
4 |
Btm;Lol |
16 |
2 |
多级目录文件抽取
目录“D:\files”包含多级子目录,每个目录下都有许多文本格式的文件,从这些文件中读取指定的行(比如第二行),并将这些数据写入新的文件d:\result.txt。
代码如下:
A |
|
1 |
=directory@p(path) |
2 |
=A1.(file(~).cursor@s()) |
3 |
=A2.((~.skip(1),~.fetch@x(1))) |
4 |
=A3.union() |
5 |
=file("d:\\result.txt").export@a(A4) |
6 |
=directory@dp(path) |
7 |
=A6.(call("c:\\readfile.splx",~)) |
参数path的初始值设为“D:\files”,表示从该目录开始抽取数据,之后递归调用本脚本(c:\readfile.splx),每次传入给参数path的值不同。
函数directory用来读出参数path中根目录下的文件列表,选项@p表示文件名带全路径,@d表示只取目录名。
~.skip(1)表示跳过一行。
~.fetch@x(1)表示从当前位置读取一行(即第二条)数据后立刻关闭游标。
分组拆分写出
文件sales.txt存储了大量销售订单,现在将该文件按年和月拆分为多个文件,文件名格式为“年-月.txt”。
代码如下:
A |
|
1 |
=file("D:\\ sales.txt").import@t() |
2 |
=A1.group(string(OrderDate,"yyyy-MM");~) |
3 |
=A2.run(file("d:\\temp\\"+#1+".txt").export(#2)) |
按年月分组解析分组,再按组循环,并写入文件。比如文件2009-01.txt,文件内容如下:
65 YZ 8 29600.0 2009-01-06 62 JAXE 11 8134.0 2009-01-06 64 HP 13 20000.0 2009-01-02 60 PWQ 16 3430.0 2009-01-05 63 SJCH 16 5880.0 2009-01-02 61 SJCH 19 1078.0 2009-01-08 |
源数据超过内存时应用函数cursor读文件,如组内数据仍超内存,应当使用函数groupx分组,但代码结构无变化。
综合运用(库存计算)
文件Stock.txt存储货物的出入库记录,同种货物每天可能出入库多次,也可能连续几天无任何货物出入库,货物初值为0,入库用In表示,出库用Out表示,需要计算出所有货物的每日库存。源数据如下:
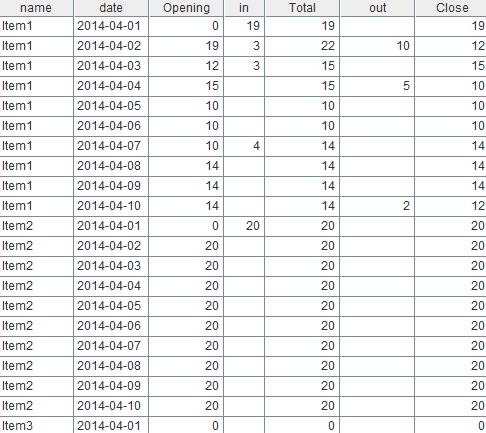
date name quantity flag 2014-04-01 Item1 15 In 2014-04-01 Item1 4 In 2014-04-02 Item1 3 In 2014-04-02 Item1 10 Out 2014-04-03 Item1 3 In 2014-04-04 Item1 5 Out 2014-04-07 Item1 4 In 2014-04-10 Item1 2 Out 2014-04-01 Item2 20 In 2014-04-02 Item3 30 In 2014-04-03 Item3 14 Out |
代码如下:
A |
B |
|
1 |
=file("D:\\stock.txt").import@t() |
|
2 |
=A1.group(name,date;~.select(flag==”In”).sum(quantity):in,~.select(flag==”Out”).sum(quantity):out) |
|
3 |
=A2.group(name) |
=periods((t=A2.id(date)).min(),t.max(),1) |
4 |
for A3 |
=A4.align(B3,date) |
5 |
>c=0 |
|
6 |
=B4.new(A4.name:name, |
|
7 |
>A8=A8|B6 |
|
8 |
||
代码说明:先用A2汇总出所有货物每日的出入库总数,再按最早、最晚日期算出完整的日期列表,存于B3。然后按货物分组,循环每组数据,并将当前组与B3对齐,在B6中计算出当前货物的每日库存,计算完成后将所有库存结果保存到A8。
计算完成后A8结果如下: