


性能优化技巧:预关联
一、 问题背景与适用场景
SQL中JOIN的性能是个老大难问题,特别是关联表较多时,计算性能会急剧下降。
SQL实现JOIN一般是采用HASH分堆的办法,即先计算关联键的HASH值,再将相同HASH值的记录放到一起再做遍历对比。每一个JOIN都要做一轮这样的运算。
如果数据量相对于内存并不是很大,可以事先全部加载到内存中,那么可以利用内存指针的机制,事先把关联关系建立好。这样做运算时就不必再做HASH与对比运算了。具体来说,就是在数据加载时一次性把HASH和对比运算做完,用指针方式保存关联结果,然后每次运算可以直接引用到关联记录,从而提高运算的性能。
不幸的是,SQL没有指针数据类型,无法实现这个优化逻辑,即使数据量可以在内存中装下,也很难利用预关联技巧提速,基于SQL的内存数据库也大都有这个缺点。而SPL有指针数据类型,就可以实现这种机制。
我们下面来测试一下SQL实现单表计算和多表关联计算的差距,再用SPL利用预关联技巧同样做一遍,看一下两者的差距对比。
二、 测试环境
采用TPCH标准生成的8张数据表,共50G数据(要小到能放进内存)。TPCH数据表的结构网上有很多介绍,这里就不再赘述了。
测试机有两个Intel2670 CPU,主频2.6G,共16核,内存128G,SSD固态硬盘。
由于 lineitem 表数据量太大,这台服务器内存不足以将它装入,所以创建了一张表结构与它一样的表 orderdetail, 将数据量减少到内存能装下,下面就用这张表来做测试。
为方便看出差距,下面测试都用单线程计算,多核并不起作用。
三、 SQL测试
这里用 Oracle 数据库作为 SQL 测试的代表,从orderdetail表里查询每年零件订单的总收入。
1. 两表关联
查询的SQL语句如下:
select
l_year,
sum(volume) as revenue
from
(
select
extract(year from l_shipdate) as l_year,
(l_extendedprice * (1 - l_discount) ) as volume
from
orderdetail,
part
where
p_partkey = l_partkey
and length(p_type)>2
) shipping
group by
l_year
order by
l_year;
2. 六表关联
查询的SQL语句如下:
select
l_year,
sum(volume) as revenue
from
(
select
extract(year from l_shipdate) as l_year,
(l_extendedprice * (1 - l_discount) ) as volume
from
supplier,
orderdetail,
orders,
customer,
part,
nation n1,
nation n2
where
s_suppkey = l_suppkey
and p_partkey = l_partkey
and o_orderkey = l_orderkey
and c_custkey = o_custkey
and s_nationkey = n1.n_nationkey
and c_nationkey = n2.n_nationkey
and length(p_type) > 2
and n1.n_name is not null
and n2.n_name is not null
and s_suppkey > 0
) shipping
group by
l_year
order by
l_year;
3. 测试结果
两表关联 |
六表关联 |
|
运行时间(秒) |
26 |
167 |
两个查询语句都用了嵌套写法,Oracle自动优化后的计算性能比无嵌套时还要好一些(无嵌套时group by和select有可能会有重复计算)。
这两个测试数据是多次运行后的结果,在测试中发现,Oracle 在第一次运行某查询时,往往比第 2、3... 次要慢很多,说明在内存大于数据量时,数据库可以把全部数据都缓存进内存(Oracle的缓存很强),所以我们取多次运行中最快那一次的时间,这样就几乎没有硬盘读取时间,仅是运算时间。
同时,在上面两组测试中,过滤条件始终都为真,也就是没有对数据产生实质过滤,两个查询都涉及orderdetail表的全部记录,计算规模是相当的。
从测试结果可以看出,六表关联比两表关联慢了167/26=6.4倍!性能下降非常多。排除掉硬盘时间后,这里增加的时间主要就是表间关联以及针对关联表字段的判断,而这些判断非常简单,所以大部分时间消耗在表间关联上。
这个测试表明,SQL的JOIN性能确实很差。
四、 SPL预关联测试
1. 预关联
实现预关联的SPL脚本如下:
A |
|
1 |
>env(region,file(path+"region.ctx").open().memory().keys@i(R_REGIONKEY)) |
2 |
>env(nation,file(path+"nation.ctx").open().memory().keys@i(N_NATIONKEY)) |
3 |
>env(supplier,file(path+"supplier.ctx").open().memory().keys@i(S_SUPPKEY)) |
4 |
>env(customer,file(path+"customer.ctx").open().memory().keys@i(C_CUSTKEY)) |
5 |
>env(part,file(path+"part.ctx").open().memory().keys@i(P_PARTKEY)) |
6 |
>env(orders,file(path+"orders.ctx").open().memory().keys@i(O_ORDERKEY)) |
7 |
>env(orderdetail,file(path+"orderdetail.ctx").open().memory()) |
8 |
>nation.switch(N_REGIONKEY,region) |
9 |
>customer.switch(C_NATIONKEY,nation) |
10 |
>supplier.switch(S_NATIONKEY,nation) |
11 |
>orders.switch(O_CUSTKEY,customer) |
12 |
>orderdetail.switch(L_ORDERKEY,orders;L_PARTKEY,part;L_SUPPKEY,supplier) |
脚本中前7行分别将7个组表读入内存,生成内表,并设成全局变量。后5行完成表间连接。在SPL服务器启动时,就先运行此脚本,完成环境准备。
我们来看看预关联后,内存中表对象的数据结构,以orderdetail为例:
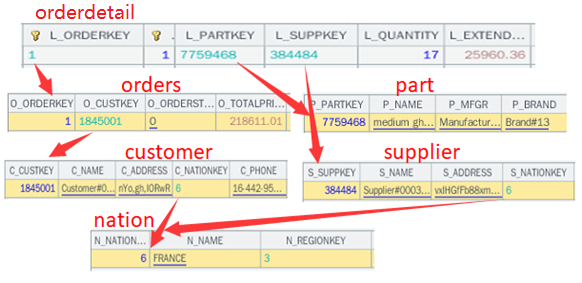
图中只列了orderdetail的第一条记录的预关联情况,其它记录与此类似。限于版面宽度,各表只列出了部分字段。
2. 两表关联
编写SPL脚本如下:
A |
|
1 |
=orderdetail.select(len(L_PARTKEY.P_TYPE)>2) |
2 |
=A1.groups(year(L_SHIPDATE):l_year;sum(L_EXTENDEDPRICE*(1-L_DISCOUNT)):revenue) |
3. 六表关联
编写SPL脚本如下:
A |
|
1 |
=orderdetail.select(len(L_PARTKEY.P_TYPE)>2 && L_ORDERKEY.O_CUSTKEY.C_NATIONKEY.N_NAME!=null && L_SUPPKEY.S_NATIONKEY.N_NAME!=null && L_SUPPKEY.S_SUPPKEY>0 ) |
2 |
=A1.groups(year(L_SHIPDATE):l_year;sum(L_EXTENDEDPRICE*(1-L_DISCOUNT)):revenue) |
预关联后,SPL代码也非常简单,关联表的字段直接可以作为本表字段的子属性访问,很易于理解。
4. 运行结果
两表关联 |
六表关联 |
|
运行时间(秒) |
28 |
56 |
六表关联仅仅比两表关联慢2倍,基本上就是增加的计算量(引用这些关联表字段)的时间,而因为有了预关联,关联运算本身不再消耗时间。
五、 结论
测试结果汇总:
运行时间(秒) |
两表关联 |
六表关联 |
性能降低倍数 |
SQL |
167 |
6.4 |
|
SPL预关联 |
28 |
56 |
2 |
六表关联比两表关联,SQL慢了6.4倍,说明SQL处理JOIN消耗CPU很大,性能降低明显。而采用预关联机制后的SPL只慢2倍,多JOIN几个表不再出现明显的性能下降。
在进行关联表较多的查询时,如果内存大到足以将数据全部读入内存(内存数据库的应用场景),使用预关联技术将极大地提升计算性能!而关系数据库(包括内存数据库)用SQL语言则无法实现这一优化技术。
系列性能优化技巧:
性能优化技巧:遍历复用
性能优化技巧:TopN
性能优化技巧:预关联
性能优化技巧:部分预关联
性能优化技巧:外键序号化
性能优化技巧:维表过滤或计算时的关联
性能优化技巧:有序归并
性能优化技巧:有序定位关联提速主子关联后的过滤
性能优化技巧:附表
性能优化技巧:大维表查找
性能优化技巧:单边分堆
性能优化技巧:有序分组
性能优化技巧:后半有序分组
性能优化技巧:前半有序时的排序


英文版