数据表两层分组拼串
【问题】
I have one table called’activity_data’,table contain following fields
id int(11),
sports_name varchar(20),
activity_date datetime
information ofactivity_datatable
id sports_name activity_date
1 Cricket 2015-05-12
2 Football 2015-05-12
3 Cricket 2015-06-10
4 Basketball 2015-06-08
5 Khokho 2015-06-02
6 Kubbdi 2015-06-04
7 Cricket 2015-05-12
8 Kubbdi 2015-05-12
9 Cricket 2015-06-09
10 Football 2015-06-03
now I’m execute following queries
SELECT GROUP\_CONCAT(id) id ,GROUP\_CONCAT(DISTINCT(sports\_name)) sports\_name,activity_date
FROM filter\_activity\_data
WHERE activity_date BETWEEN '2015-05-12' AND '2015-06-04'
GROUP BY activity_date
ORDER BY activity_date ASC
while executing this:output is getting like this
id sports_name activity_date
1,2,7,8 Cricket,Football,Kubbdi 2015-05-12
5 Khokho 2015-06-02
10 Football 2015-06-03
6 Kubbdi 2015-06-04
… …
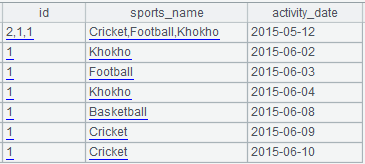
I want to get output total count of eachGROUP_CONCAT sports_name. expected out put like this:
id sports_name activity_date
2,1,1 Cricket,Football,Kubbdi 2015-05-12
1 Khokho 2015-06-02
1 Football 2015-06-03
1 Kubbdi 2015-06-04
… …
【回答】
SQL 写法:
select GROUP_CONCAT(t.name1) as name2 , GROUP_CONCAT(t.count) as counts , t.activity_date from
(SELECT GROUP\_CONCAT(id) id ,GROUP\_CONCAT(DISTINCT(sports_name)) as name1 , count(*) as count , sports\_name,activity\_date
FROM activity_data
WHERE activity_date BETWEEN '2015-05-12' AND '2015-06-04'
GROUP BY activity\_date, sports\_name
ORDER BY activity_date ASC) as t
group by t.activity_date
除了可以通过上面的方法实现,还可以使用 SPL 实现,并且 SPL 相较 SQL 更加简洁,实现思路与 SQL 是一样的,写法如下:
A |
|
1 |
$select * from activity_data |
2 |
=A1.groups(activity_date,sports_name;count(~):c) |
3 |
=A2.group@o(activity_date).new(~.(c).concat@c():id,~.(sports_name).concat@c():sports_name,activity_date) |
A1:执行 SQL 取数
A2:对序列成员进行分组计数
A3:将分组后的序列进行归并运算,A3 执行结果如下: