SQL 难点解决:记录的引用
【摘要】
SQL 虽然是针对记录的集合进行运算, 但在记录的多次利用以及有序运算却经常要重复计算,效率不佳。而集算器 SPL 则要直观许多,可以按自然思维习惯写出运算。这里对 SQL 和集算器 SPL 在记录的利用及有序运算方面进行了对比,如果需要了解更多,请前往乾学院:SQL 难点解决:记录的引用!
1、 求最大值 / 最小值所在记录
示例 1:计算招商银行 (600036)2017 年收盘价达到最低价时的所有交易信息。
MySQL8:
with t as (select * from stktrade where sid='600036'
and tdate between '2017-01-01' and '2017-12-31')
select * from t where close=(select min(close) from t);
集算器SPL:
A |
|
1 |
=connect("mysql") |
2 |
=A1.query@x("select * from stktrade where sid='600036'and tdate between'2017-01-01'and'2017-12-31'") |
3 |
=A2.minp@a(close) |
A3: 计算 A2 中 close 为最小值的所有记录
示例 2:计算招商银行 (600036)2017 年最后的最低价和最早的最高价相隔多少自然日
MySQL8:
with t as (select *, row_number() over(order by tdate) rn from stktrade
where sid='600036' and tdate between '2017-01-01' and '2017-12-31'),
t1 as (select * from t where close=(select min(close) from t)),
t2 as (select * from t where close=(select max(close) from t)),
t3 as (select * from t1 where rn=(select max(rn) from t1)),
t4 as (select * from t2 where rn=(select min(rn) from t2))
select abs(datediff(t3.tdate,t4.tdate)) inteval
from t3,t4;
集算器SPL:
A |
|
1 |
=connect("mysql") |
2 |
=A1.query@x("select * from stktrade where sid='600036'and tdate between'2017-01-01'and'2017-12-31'order by tdate") |
3 |
=A2.minp@z(close) |
4 |
=A2.maxp(close) |
5 |
=abs(A3.tdate-A4.tdate) |
A3: 从后往前查找 close 第 1 个最小值的记录
A4: 从前往后查找 close 第 1 个最大值的记录
2、 查找满足条件的记录
示例 1:计算招商银行 (600036)2017 年收盘价超过 25 元时的交易信息
MySQL8:
with t as (select * from stktrade where sid='600036' and tdate between '2017-01-01' and '2017-12-31')
select * from t
where tdate=(select min(tdate) from t where close>=25);
集算器SPL:
A |
|
1 |
=connect("mysql") |
2 |
=A1.query@x("select * from stktrade where sid='600036'and tdate between'2017-01-01'and'2017-12-31'order by tdate") |
3 |
=A2.select@1(close>=25) |
A3: 从前往后查找收盘价超过25元的第1条记录

示例 1:计算招商银行 (600036) 上一周的涨幅(考虑停牌)
MySQL8:
with t1 as (select * from stktrade where sid='600036'),
t11 as (select max(tdate) tdate from t1),
t2 as (select subdate(tdate, weekday(tdate)+3)m from t11),
t3 as (select max(tdate) m from t1,t2 where t1.tdate<=t2.m),
t4 as (select subdate(m, weekday(m)+3)m from t3),
t5 as (select max(tdate) m from t1,t4 where t1.tdate<=t4.m)
select s1.close/s2.close-1
from (select * from t1,t3 where t1.tdate=t3.m) s1,
(select * from t1,t5 where t1.tdate=t5.m) s2;
集算器SPL:
A |
|
1 |
=connect("mysql") |
2 |
=A1.query@x("select * from stktrade where sid='600036' order by tdate") |
3 |
=pdate@w(A2.m(-1).tdate) |
4 |
=A2.select@z1(tdate<=A3-2) |
5 |
=pdate@w(A4.tdate) |
6 |
=A2.select@z1(tdate<=A5-2) |
7 |
=A4.close/A6.close-1 |
A3: 求最后1个交易日所在周的周日(周日为一周的第一天)
A4: 从后往前查找上周5以前的第1条记录,即上一交易周的最后一条记录
A5: 求上一个交易周的周日
A6: 从后往前查找上一个交易周的前一个周5的第1第记录,即上上交易周的最后一条记录

示例 3:重叠部分不重复计数时求多个时间段包含的总天数
MySQL8:
with t(start,end) as (
select date'2010-01-07',date'2010-01-9'
union all select date'2010-01-15',date'2010-01-16'
union all select date'2010-01-07',date'2010-01-12'
union all select date'2010-01-08',date'2010-01-11'),
t1 as (select *, row_number() over(order by start,end desc) rn from t),
t2 as (select * from t1
where not exists(select * from t1 s where s.rn<t1.rn and s.end>=t1.end))
select sum(end-start+1) from t2;
集算器SPL:
A |
|
1 |
=connect("mysql") |
2 |
=A1.query@x("select date'2010-01-07'start,date'2010-01-9' end union all select date'2010-01-15',date'2010-01-16'union all select date'2010-01-07',date'2010-01-12'union all select date'2010-01-08',date'2010-01-11'") |
3 |
=A2.sort(start,-end) |
4 |
=A3.select(end>max(end[:-1])) |
5 |
=A4.sum(if(start>end[-1],interval(start,end)+1,interval(end[-1],end))) |
A3: 按起始时间升序、结束时间降序进行排序
A4: 选取结束时间比前面所有记录的结束时间都要晚的记录
A5: 计算总天数,max(start,end[-1])选起始时间和上一个结束时间较大者,interval计算2个日期相差天数
注:A4也可以改成 =A3.run(end=max(end,end[-1]))
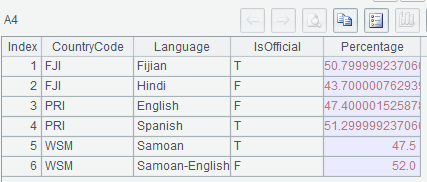
示例 3:列出超 42% 人口使用的语言有 2 种以上的国家里使用人口超 42% 的语言的相关信息
MySQL8:
with t as (select * from world.countrylanguage where percentage>=42),
t1 as (select countrycode, count(*) cnt from t
group by countrycode having cnt>=2)
select t.* from t join t1 using (countrycode);
集算器SPL:
A |
|
1 |
=connect("mysql") |
2 |
=A1.query@x("select * from world.countrylanguage where percentage>=42") |
3 |
=A2.group(CountryCode) |
4 |
=A3.select(~.len()>=2).conj() |
A3: 按国家编码分组
A4: 对成员数超过2个的组求和集
3、 求前 n 个表达式值最小的记录
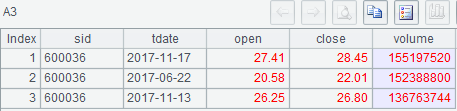
示例 1:计算招商银行 (600036)2017 年成交量最大的 3 天交易信息
MySQL8:
select * from stktrade
where sid='600036' and tdate between '2017-01-01' and '2017-12-31'
order by volume desc limit 3;
集算器SPL:
A |
|
1 |
=connect("mysql") |
2 |
=A1.query@x("select * from stktrade where sid='600036'and tdate between'2017-01-01'and'2017-12-31'") |
3 |
=A2.top(3;-volume) |
A3: 根据-volume排序,然后取前 3 条记录
示例 2:计算招商银行 (600036) 最近 1 天的涨幅
MySQL8:
with t as (select *, row_number() over(order by tdate desc) rn from stktrade where sid='600036')
select t1.close/t2.close-1 rise
from t t1 join t t2
where t1.rn=1 and t2.rn=2;
集算器SPL:
A |
|
1 |
=connect("mysql") |
2 |
=A1.query@x("select * from stktrade where sid='600036'") |
3 |
=A2.top(2,-tdate,~) |
4 |
=A3(1).close/A3(2).close-1 |
A3: 按交易日期倒序取最后 2 条记录 (效果等同于 A2.top(2;-tdate)),最后一天的交易记录序号为 1,倒数第 2 天的交易记录序号为 2
A4: 计算涨幅

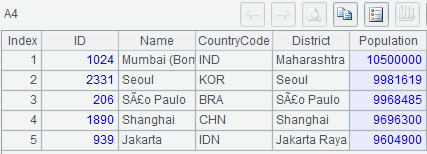
示例 3:计算每个国家最大城市中人口前 5 的城市的相关信息
MySQL8:
with t as (select *,row_number() over(partition by countrycode order by population desc) rn from world.city),
t1 as (select id,name,countrycode,district,population from t where rn=1)
select * from t1 order by population desc limit 5;
集算器SPL:
A |
|
1 |
=connect("mysql") |
2 |
=A1.query@x("select * from world.city") |
3 |
=A2.groups(CountryCode; top@1(1;-Population):city) |
4 |
=A3.(city).top(5;-Population) |
A3: 按国家分组,分组返回人口最多的城市的记录
A4: 取所有国家最大城市中人口前 5 的城市记录
4、 外键引用记录
示例 1:计算亚洲和欧洲人口前 3 城市的相关信息
MySQL8:
with t as (
select co.Continent, co.name CountryName, ci.name CityName, ci.Population,
row_number()over(partition by continent order by population desc) rn
from world.country co join world.city ci on co.code=ci.countrycode
where continent in ('Asia','Europe')
)
select Continent, group_concat(cityname,',',countryname, ',', population order by population desc separator ';') Cities
from t
where rn<=3
group by continent;
集算器SPL:
A |
|
1 |
=connect("mysql") |
2 |
=A1.query("select * from world.country where continent in ('Asia','Europe')") |
3 |
=A1.query@x("select * from world.city") |
4 |
=A2.keys(Code) |
5 |
>A3.switch@i(CountryCode,A4) |
6 |
=A3.group(CountryCode.Continent:Continent;~.top(3;-Population). (Name/","/CountryCode.Name/","/Population).concat(";"):Cities) |
A4: 将 A2 中序表的键设为 Code 字段
A5: 将 A3 中序表 CountryCode 字段转换为 A2 中相应记录,无对应记录时删除
A6: 先根据 Continent 分组,再计算每组人口前 3 的城市,然后将每条记录中的城市名称、国家名称和人口拼成串,最后将每组中的串相连

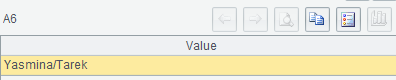
示例 2:以“上级姓名 / 下级姓名”的形式返回指定雇员的所有上级
MySQL8:
with recursive emp(id,name,manager_id) as (
select 29,'Pedro',198
union all select 72,'Pierre',29
union all select 123,'Adil', 692
union all select 198,'John',333
union all select 333,'Yasmina',null
union all select 692,'Tarek', 333
), t2(id,name,manager_id,path) as(
select id,name,manager_id,cast(name as char(400))
from emp where id=(select manager_id from emp where id=123)
union all
select t1.id,t1.name, t1.manager_id, concat(t1.name,'/',t2.path)
from t2 join emp t1 on t2.manager_id=t1.id)
select path from t2 where manager_id is null;
集算器SPL:
A |
|
1 |
=connect("mysql") |
2 |
=A1.query@x("with emp(id,name,manager_id) as (select 29,'Pedro',198 union all select 72,'Pierre',29 union all select 123,'Adil', 692 union all select 198,'John',333 union all select 333,'Yasmina',null union all select 692,'Tarek', 333) select * from emp") |
3 |
=A2.switch(manager_id, A2:id) |
4 |
=A2.select@1(id:123) |
5 |
=A4.manager_id.prior(manager_id) |
6 |
=A5.rvs().(name).concat("/") |
A3: 将manager_id转换成A2中与manager_id相等的id所在的记录
A4: 查找id为123的记录
A5: 依次列出A4上级、上级的上级、……,直到最高上级(即manager_id为null)
A6: 将所有上级按从最高上级到最下上级排列,然后将所有上级的姓名用/分隔相连