




秒级展现的百万级大清单报表怎么做
【摘要】
使用数据库分页机制会遇到两个问题,1 翻页有时会有等待感,2 查询的同时数据库还在插入删除,会出现数据不一致的情况。为了解决这个问题,秒级展现的百万级大清单报表怎么做介绍了一种两阶段双异步线程方法,一个线程负责取数,另外一个线程负责呈现。
数据查询业务中,有时会碰到数据量很大的清单报表。由于用户输入的查询条件可能很宽泛,因此会从数据库中查出几百上千万甚至过亿行的记录,常见的包括银行流水记录,物流明细等。呈现时如果等着把这些记录全部检索出来再生成报表,那会需要很长时间,用户体验自然会非常恶劣。而且,报表一般采用内存运算机制,大多数情况下内存里也装不下这么多数据。所以,我们一般都会使用分页呈现的方式,尽量快速地呈现出第一页,然后用户可以随意翻页显示,每次只显示一页,也不会造成内存溢出。
传统分页呈现的实现,一般都会使用数据库的分页机制来做,利用数据库提供的返回指定行号范围内记录的语法。界面端根据当前页号计算出行号范围(每页显示固定行数)作为参数拼入 SQL 中,数据库就会只返回当前页的记录,从而实现分页呈现的效果。
不过,这样做会有两个问题:
1. 翻页时效率较差
用这种办法呈现第一页一般都会比较快,但向后翻页时,所使用的取数 SQL 会被再次执行,并且将前面页涉及的记录跳过。对于有些没有 OFFSET 关键字的数据库,就只能由界面端自行跳过这些数据(取出后丢弃),而像 ORACLE 还需要用子查询产生一个序号才能再用序号做过滤。这些动作都会降低效率,浪费时间,前几页还感觉不明显,但如果页号比较大时,翻页就会有等待感了。
2. 可能出现数据不一致
用这种办法翻页,每次按页取数时都需要独立地发出 SQL。这样,如果在两页取数之间又有了插入、删除动作,那么取的数反映的是最新的数据情况,很可能和原来的页号匹配不上。例如,每页 20 行,在第 1 页取出后,用户还没有翻第 2 页前,第 1 页包含的 20 行记录中被删除了 1 行,那么用户翻页时取出的第 2 页的第 1 行实际上是删除操作前的第 22 行记录,而原来的第 21 行实际上落到第 1 页去了,如果要看,还要翻回第 1 页才能看到。如果还要基于取出的数据做汇总统计,那就会出现错误、不一致的结果。
为了克服这两个问题,有时候我们还会用另一种方法,用 SQL 游标从数据库中取数,在取出一页呈现后,但并不终止这个游标,在翻下一页的时候再继续取数。这种方法能有效地克服上述两个问题,翻页效率较高,而且不会发生不一致的情况。不过,绝大多数的数据库游标只能单向从前往后取数,表现在界面上就只能向后翻页了,这一点很难向业务用户交代,所以很少用这种办法。
当然,我们也可以结合这两种办法,向后翻页时用游标,一旦需要向前翻页,就重新执行取数 SQL。这样会比每次分页都重新取数的体验好一些,但并没有在根本上解决问题。
润乾报表方案
下面介绍的润乾报表方案,提供的大报表功能可以支持海量清单报表的秒级查询。在这个方案中,取数和呈现采用两个异步线程,取数线程发出 SQL 后不断取出数据缓存到本地,由呈现线程从本地缓存中获取数据进行显示。这样,已经取出并缓存的数据就能快速呈现,不再有等待感;而取数线程所涉及的 SQL,在数据库中保持同一个事务,也不会有不一致的问题,前面提到的两个问题全部得以完美解决。
同时,借助集文件存储格式,报表还可以按行号随机访问记录,而不用每次通过遍历查找数据。也就是说,这种存储格式支持跳转到任意页访问,从而极大地改善了用户体验。不过,由于采用了异步机制,页面端显示的总页数和总记录数会随着取数过程不断变化。
大清单报表运行原理:

需要注意的是,大清单报表中用到的异步机制和集文件存储都是在集算器的基础上实现的,因此该功能需要“集成集算器”功能支持,并不包含在润乾报表基础版中。
下面通过举例来说明润乾海量大清单报表(以下简称:大报表)的开发使用过程。
SQL 源大报表
首先来看一种最基础的大报表,即报表数据来源于数据库的情况。例子中我们需要根据日期范围查询订单表的交易信息,由于数据规模较大,因此需要使用大清单报表呈现。
制作报表模板
与普通报表开发一样,设置参数、准备数据集、绘制报表模板。
报表参数为查询日期起止:

数据集根据参数查询订单表 SQL:
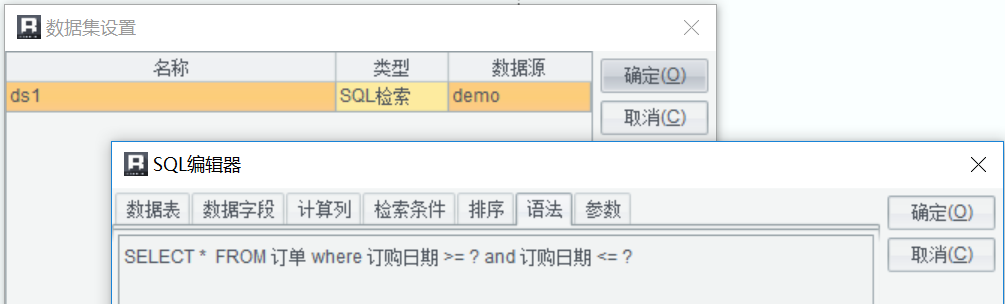
报表模板:

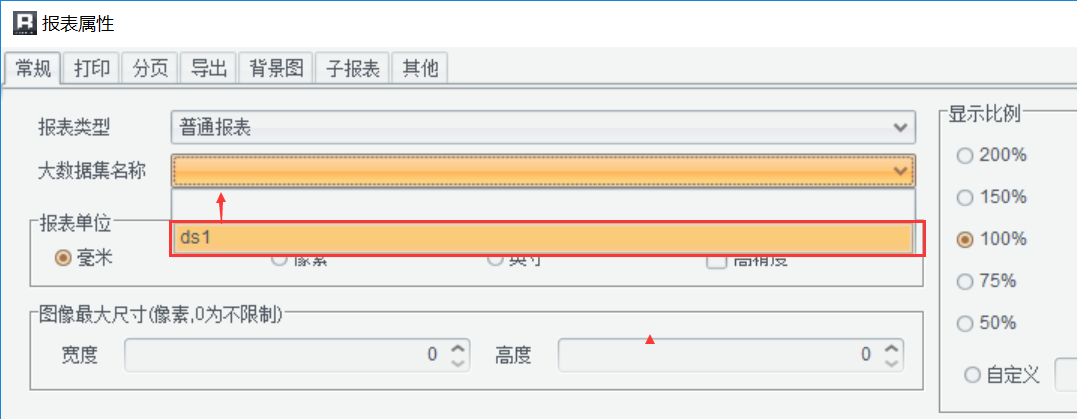
设置大数据集
与普通报表不同,需要在润乾报表属性(报表 - 报表属性)中设置“大数据集名称”,指向数据集 ds1,直接利用 SQL 完成异步取数。
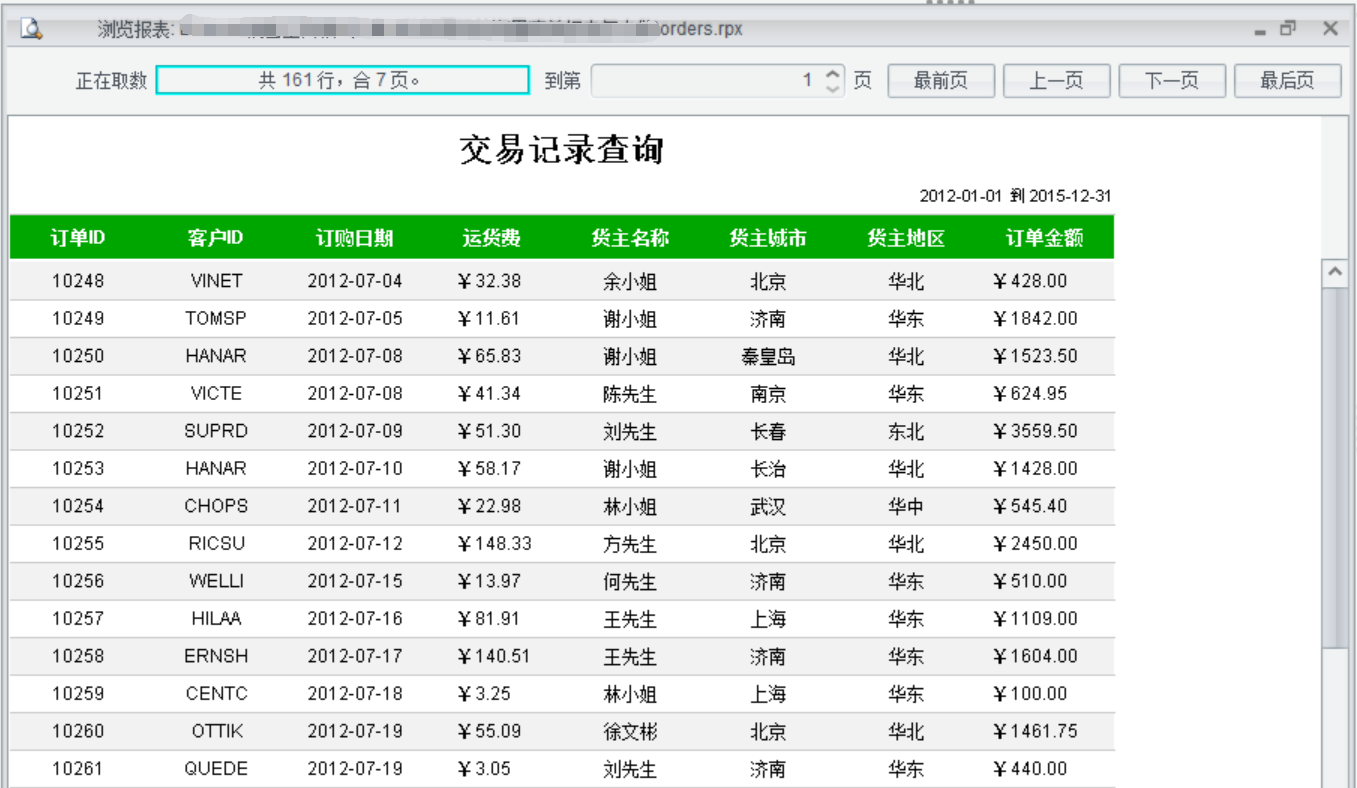
设置完成后,在报表设计器 IDE 中即可浏览报表:
发布到 WEB
与普通报表发布类似,大清单报表也通过 JSP 以 tag-lib 的方式发布。
<report:big name="report1" reportFileName="<%=report%>"
needScroll="<%=scroll%>"
params="<%=param.toString()%>"
exceptionPage="/reportJsp/myError2.jsp"
scrollWidth="100%"
scrollHeight="100%"
rowNumPerPage="20"
fetchSize="1000"
needImportEasyui="no"
/>
其中 rowNumPerPage 属性为每页显示记录数;fetchSize 为每次从数据源读取的数据量。完整发布的 JSP 可以参考报表安装目录下的样例文件:[report\web\webapps\demo\reportJsp\ showBigReport.jsp]。
WEB 端呈现效果:
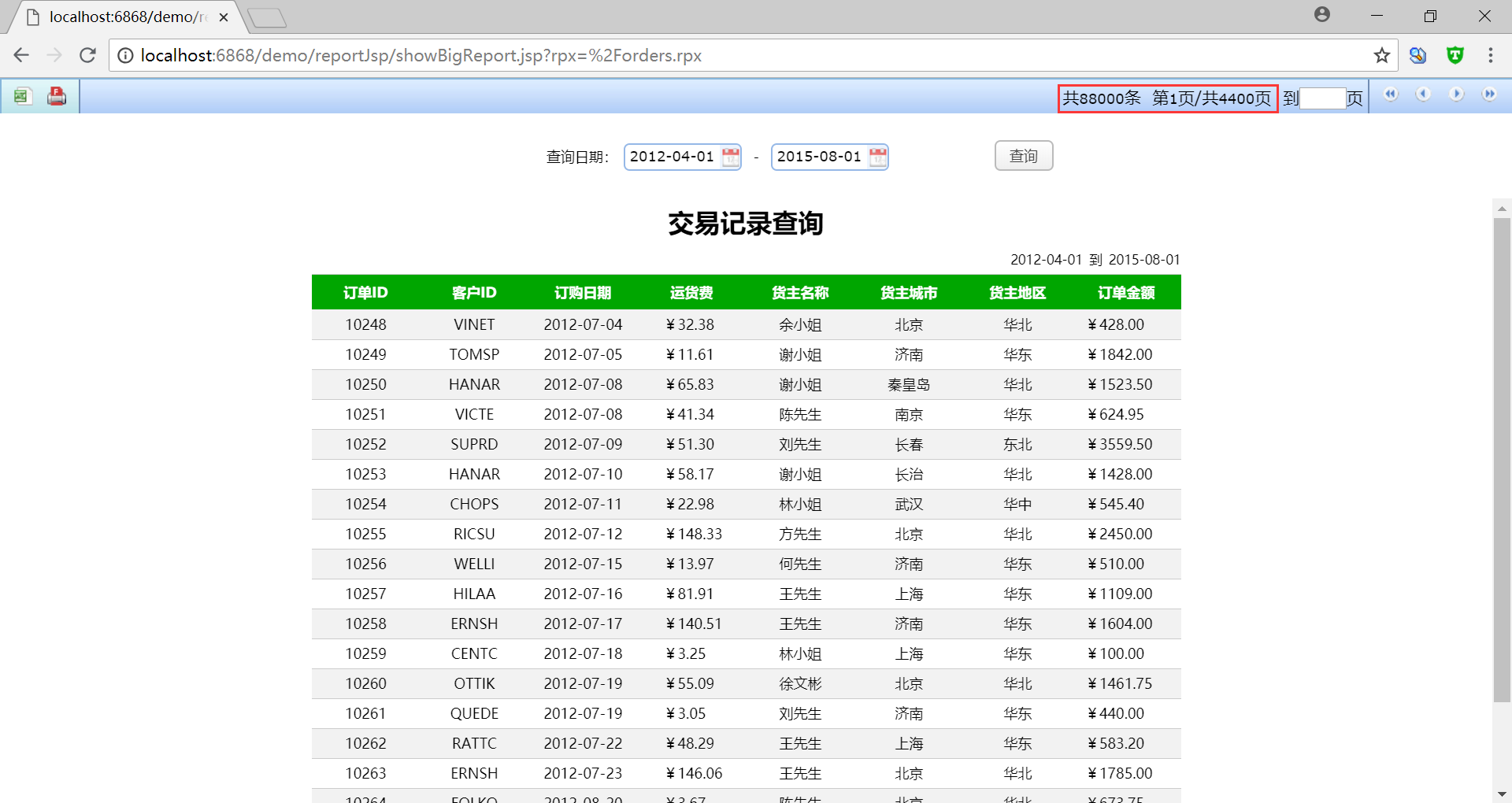
可以注意到,右上角的页码和总记录条数随着异步线程不断读取数据而不断变化。
除了展现,在润乾报表中还支持对大清单报表导出 Excel 和打印。
导出
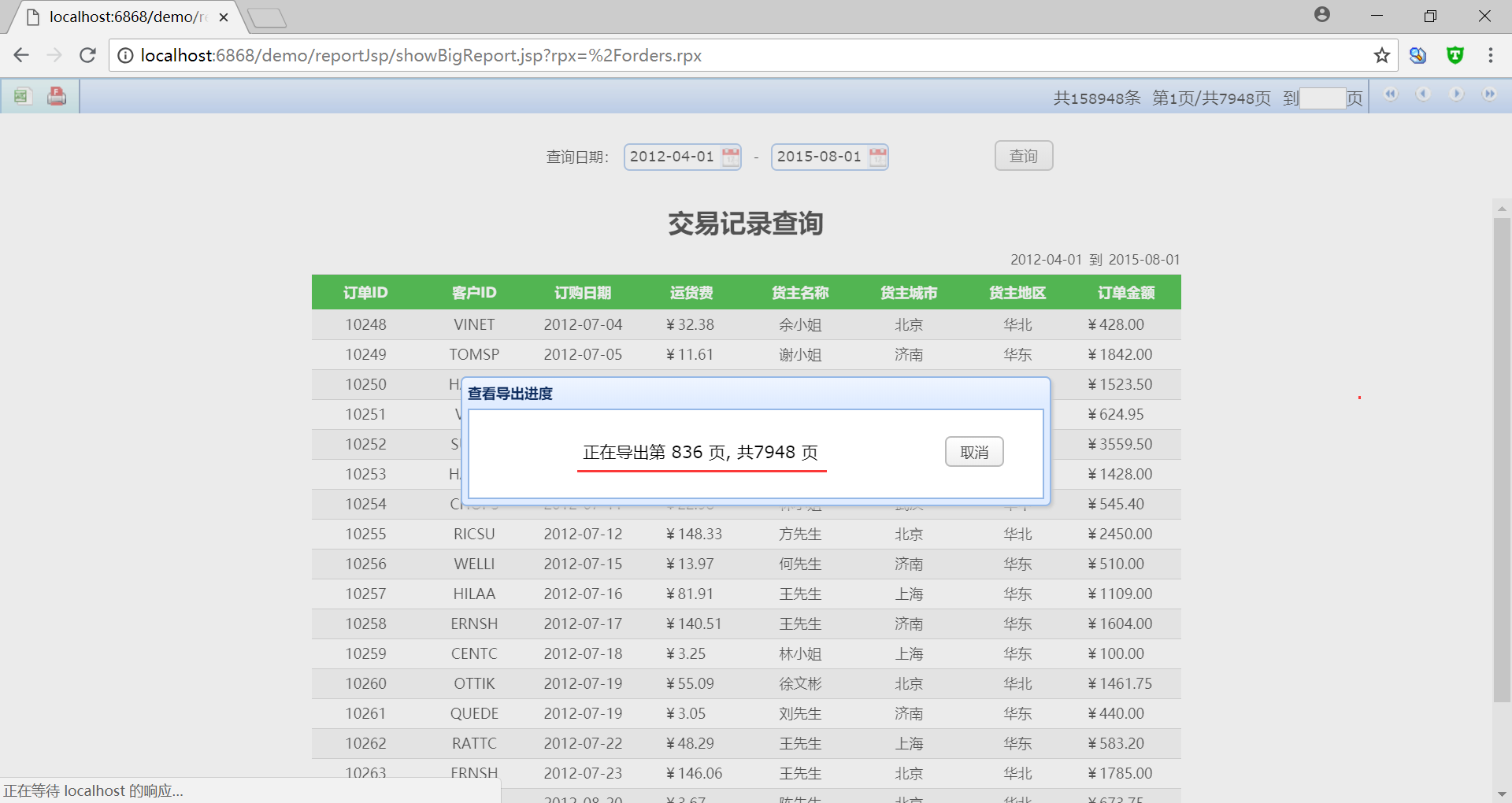
打印
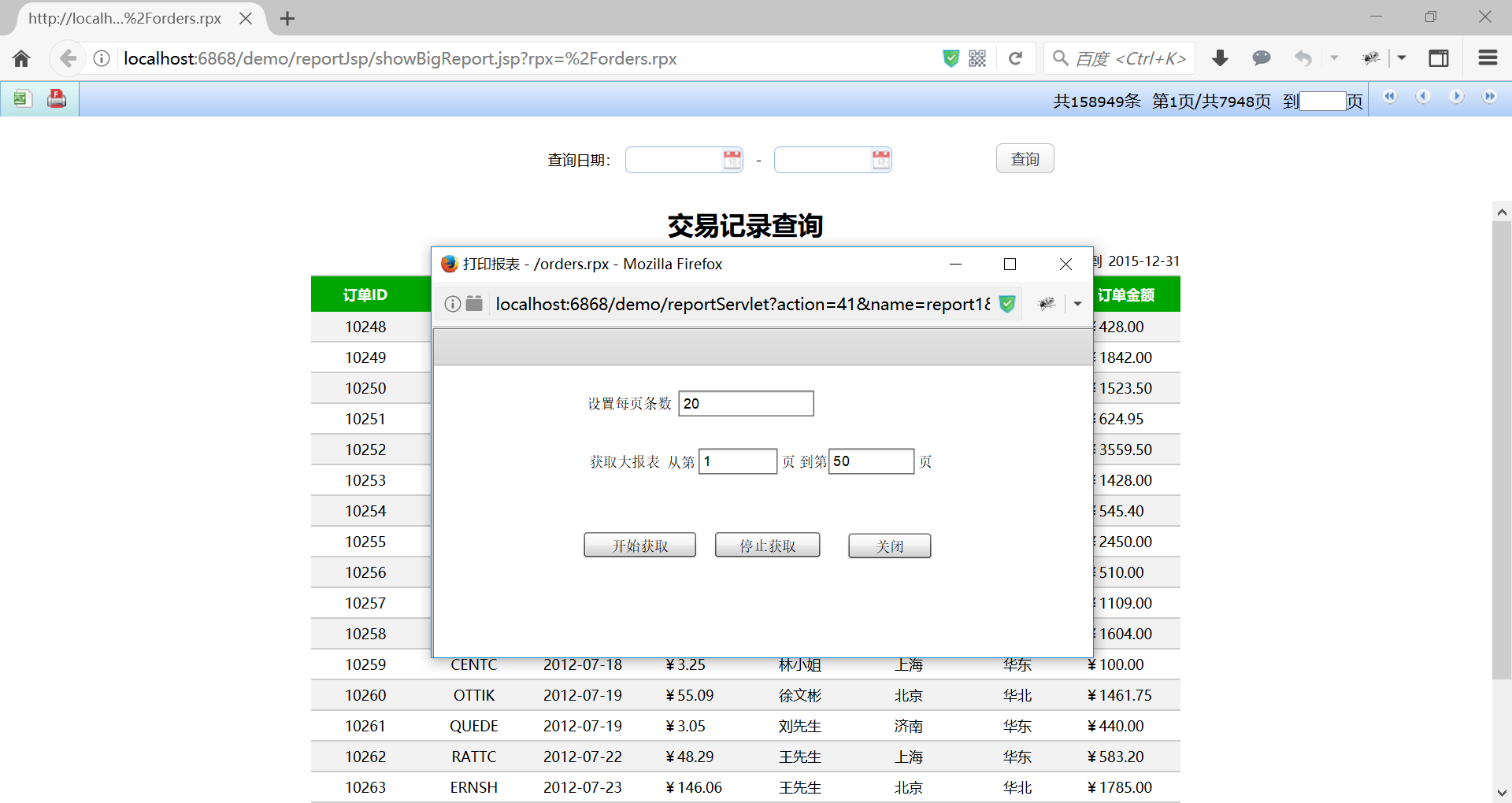
非 SQL 源大报表
当海量数据来源非 RDB 时,由于无法利用数据库分页,因此无法通过 SQL 实现异步大报表。针对这一问题,润乾报表的大报表方案中,采用了两阶段异步线程,其中由集算器定义取数线程负责从非 RDB 数据源取数并缓存数据,再由呈现线程负责读取缓存并分页展现。
下面以文件数据为例,说明非 RDB 数据源的大报表开发过程。例子中的卫星数据以文件(CSV)方式存储,数据规模较大,是典型的非 RDB 数据源。现在我们要按照日期查询某日风速、温度等明细信息。
报表数据准备
首先,我们借助润乾报表的集算器数据集读取文件数据,并为报表返回游标。集算器 SPL 脚本如下:
A |
|
1 |
=file(“source.csv”).cursor@t(;,",") |
2 |
=A1.select(时间 == d_time) |
3 |
return A2 |
A1 建立文件游标;
A2 在游标执行时对数据进行过滤(此时游标尚未执行,数据并未取出);
A3 返回游标过滤结果,为报表提供数据。
将 SPL 脚本存储为 bigReport-file.dfx,并在报表中作为数据集引入:
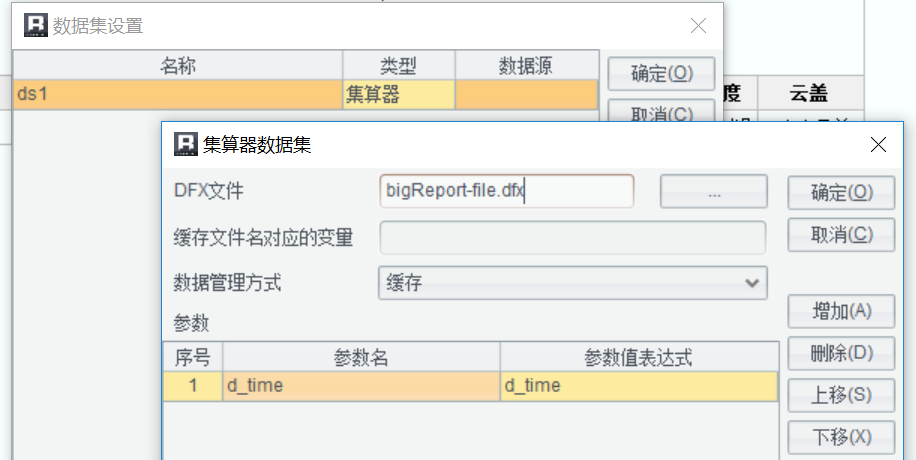
设计报表模板
接下来,我们根据所准备的数据制作报表模板:

同时设置大数据集:

发布到 WEB
然后,将做好的报表发布到 WEB 端:
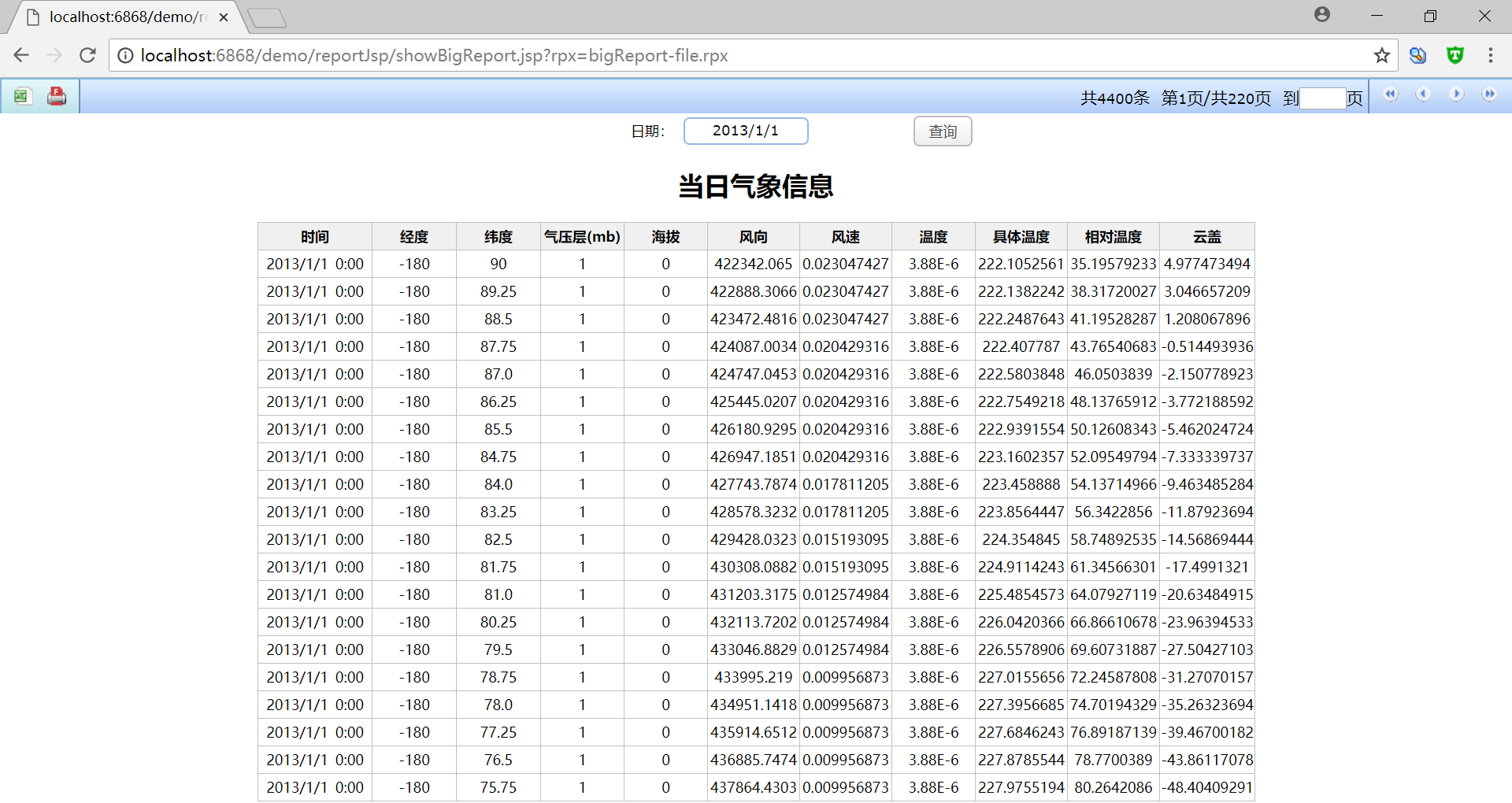
是不是很简单? 这个例子显示了在开发报表时如果涉及海量非 RDB 数据,润乾报表可以借助集算器对多种数据源类型的支持能力,实现大报表开发与呈现。
使用大报表注意事项
上面介绍了开发大报表该有的正确姿势,但任何功能都不是万能的,使用大报表也有需要注意的地方:
1、不排序
大报表的数据集都比较大,如果在意响应时间(谁会不在意呢),那么应该尽量不对数据集进行全表排序(注意我说的是全表排序),毕竟,等排完序再呈现,时间已经过去很久了……
2、不适合高并发场景
大报表采用异步机制,将数据分批加载到内存再交给前端呈现,减少了内存占用,但同时增加了 CPU 和磁盘 I/O 负载,并发高时 CPU 和硬盘可能成为瓶颈从而影响呈现效果,因此大报表不适合高并发的场景。
本文主要介绍了 RDB 和非 RDB 数据源情况下大清单报表的开发方法,在下一篇《百万级分组大报表开发与呈现》中,我们将进一步介绍带有汇总值的大报表和分组大报表的实现过程。
对润乾产品感兴趣的小伙伴,一定要知道软件还能这样卖哟性价比还不过瘾? 欢迎加入好多乾计划。
这里可以低价购买软件产品,让已经亲民的价格更加便宜!
这里可以销售产品获取佣金,赚满钱包成为土豪不再是梦!
这里还可以推荐分享抢红包,每次都是好几块钱的巨款哟!
来吧,现在就加入,拿起手机扫码,开始乾包之旅

嗯,还不太了解好多乾?


👍