


分组?原来你是玩儿真的!
数据计算中,分组绝对是最常用的计算方式之一,相应的,在 SQL 语言中,自然会用到 group by 了。但是,不知道你想过没有,SQL 中的 group by 并不能算是“纯粹”的分组,它实际上并不是针对原始数据分组,而是将结果集分组,最终是为了实现 5 类聚合计算:min/max/avg/count/sum,而单独使用 group by 没有任何意义,只是相当于按照 group by 的条件进行了排序而已。
但实际的数据计算中,针对分组数据的统计要求有可能远远超过 5 类聚合计算的能力。换句话说,对原始记录执行“真实”的分组操作,将记录分为多个子集,这样的分组方式不仅更为自然,而且也便于执行一些更为复杂的分组统计。这种自然而纯粹的思路,在集算器中得到了真正的体现。下面我们会通过分组汇总、分组子集,以及枚举分组三类问题来进一步说明这种思路的真正优势。
1、分组汇总
先来看看用 SQL 的分组计算吧,其实就是各类分组汇总计算。查看 SQL 执行结果的方法和工具很多,我们在这里使用集算器直接调用 SQL 通过 JDBC 执行查询:
| A | |
|---|---|
| 1 | =demo.query(“select * from CITIES”) |
| 2 | =demo.query(“select STATEID,count(*) CITY_COUNT, sum(POPULATION) POPU_AMOUNT from CITIES group by STATEID order by STATEID”) |
| 3 | =demo.query(“select left(NAME,1) INITIAL, avg(POPULATION) AVG_POPU, max(POPULATION) MAX_POPU, min(POPULATION) MIN_POPU from cities group by INITIAL order by INITIAL”) |
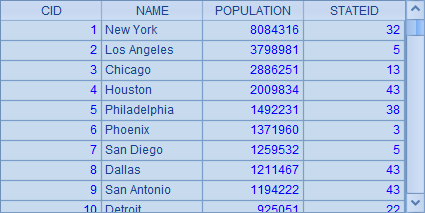
CITIES 表中存储了一些城市的人口数据,A1 中查询出 CITIES 的所有内容,结果如下:

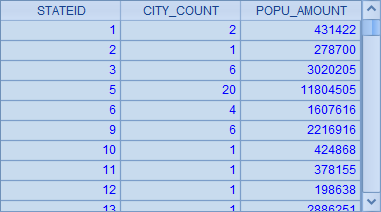
SQL 的 group by 从句可以和各类聚合函数配合完成计算,这里 A2 中的 SQL,就是根据这些城市所在州编号 STATEID 分组,并分别用 count 和 sum 函数统计出每个州中城市的总数和总人口,并按州序号排序。查询结果如下:

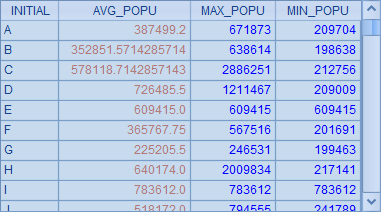
而 A3 中的 SQL 根据城市名称的首字母分组,并计算出首字母相同的城市的平均人口,以及最大和最小人口数,同时将结果按首字母执行了排序,结果如下:
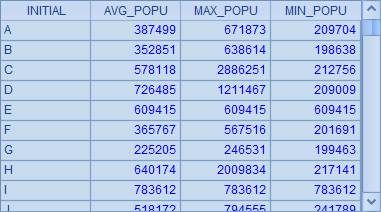
从这两个例子可以直观的看出,在 SQL 中进行“分组”时,得到的并不是“组”,只能得到 “组的计算结果”,更别说能得到分组中的各条记录了。
在集算器中,我们可以利用 groups 函数,实现和上面 SQL 等效的统计计算:
| A | |
|---|---|
| 1 | =demo.query(“select * from CITIES”) |
| 2 | =A1.groups(STATEID;count(~):CITY_COUNT, sum(POPULATION):POPU_AMOUNT) |
| 3 | =A1.groups(left(NAME,1):INITIAL;avg(POPULATION):AVG_POPU, max(POPULATION):MAX_POPU, min(POPULATION):MIN_POPU) |
A1 中取出 CITIES 表中全部数据:
A2 和 A3 中计算分组统计,统计时可以直接使用 A1 中已获得的数据,不必再访问数据库。A2 中分组汇总的结果和前面用 SQL 时的情况是相同的:
A3 中分组汇总的结果和前面有一些区别,由于集算器中计算平均值时会默认使用双精度处理,而 SQL 在计算整数均值时会保留整数部分:
除了 groups 和 SQL 一样能够直接分组汇总之外,在集算器中还可以利用 group 函数“仅仅”将记录分组,然后在分组结果的基础上,进一步进行汇总计算,如:
| A | |
|---|---|
| 1 | =demo.query(“select * from CITIES”) |
| 2 | =A1.group(STATEID) |
| 3 | =A2.new(STATEID,~.count():CITY_COUNT, ~.sum(POPULATION):POPU_AMOUNT) |
| 4 | =A1.group(left(NAME,1)) |
| 5 | =A4.new(left(NAME,1):INITIAL,int(~.avg(POPULATION)):AVG_POPU, ~.max(POPULATION):MAX_POPU, ~.min(POPULATION):MIN_POPU) |
A2 中将数据根据 STATEID 分为多组,结果如下:
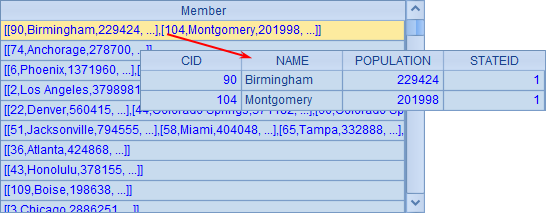
展示数据时,每个分组都可以双击查看,可以发现每个分组都是由 1 条或多条记录构成的。比如 STATEID 为 1 的城市有两个:Birmingham 和 Montgomery。
在 A3 中,根据这个分组结果来进一步查询,统计出每个州中城市的总个数和总人口,这里的语法和 SQL 有所不同,如统计某个组内记录总数写为 ~.count()。A3 中的计算结果如下:
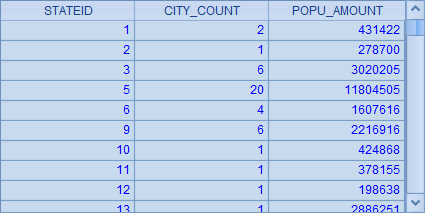
这里的结果和前面用 SQL 和 groups 函数的情况是相同的。两者相比,用先分组再聚合计算的方式,过程比较直观且容易控制,而直接聚合获得结果效率较高。
与 A2 类似,A4 中根据城市名称的首字母将数据分组,结果如下:
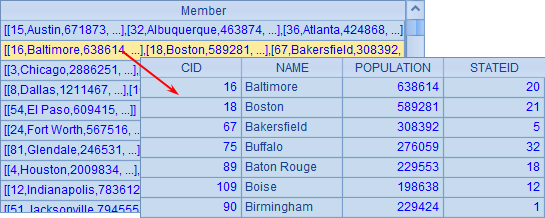
在 A5 中,根据分组结果来计算,统计出每个首字母编组中,人口的平均值和最大最小值。
使用先分组再聚合计算的方法时,统计方法比较自由,并不局限于各类聚合函数,比如这里在计算人口平均值时,就可以用 int 函数保留平均值的整数部分,获得的汇总结果与 SQL 相同:
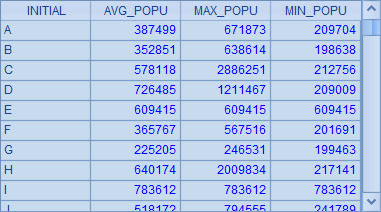
如果不需要查看中间的分组结果,也可以用 group 函数另一种写法直接计算出结果:
| A | |
|---|---|
| 1 | =demo.query(“select * from CITIES”) |
| 2 | =A1.group(STATEID;~.count():CITY_COUNT, ~.sum(POPULATION):POPU_AMOUNT) |
| 3 | =A1.group(left(NAME,1):INITIAL;int(~.avg(POPULATION)):AVG_POPU, ~.max(POPULATION):MAX_POPU, ~.min(POPULATION):MIN_POPU) |
这里,A2 执行的计算其实就相对于前一个例子中 A2 和 B2 中计算,结果也和 B2 中相同。A3 相当于前例中 A3 和 B3 的计算,结果和 B3 相同。这种方式得到的结果和前面使用 groups 时是相同的,不过语法略有不同,能够完成的统计计算更为自由,但计算效率会比 groups 低一些。
2、分组子集
SQL 的分组除了只能得到分组汇总的结果,查询时也只能查询分组时使用的字段和聚合结果,这其实和分组时每组的数据有关,比如下面是按城市首字母分组时,B 开头的城市:
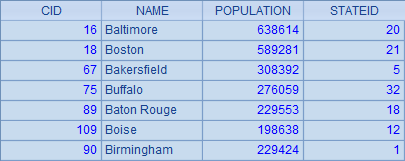
在这样的分组中,除了分组时使用的 NAME 首字母,各条城市记录的其它字段全都来源于多条记录,是不一定相同的。所以用 SQL 查询时结果集中也就仅允许使用两类字段:一类是分组条件中包含的字段,另一类是计数、求和、均值、最大值、最小值这样的聚合结果字段。正是由于这样的模式,如果想进一步获得分组中的某一条记录,或者其中某些记录构成的子集,就会变得非常复杂,如“组内人口最多的城市名称”、“组内人口低于平均值的城市名称”,如果仍然使用 SQL,那么只能用子查询来处理了:
| A | |
|---|---|
| 1 | =demo.query(“select NAME, POPULATION from CITIES c where POPULATION=(select max(POPULATION) from CITIES where left(NAME,1)=left(c.NAME,1)) order by NAME”) |
| 2 | =demo.query(“select NAME, POPULATION from CITIES c where POPULATION<(select avg(POPULATION) from CITIES where left(NAME,1)=left(c.NAME,1)) order by left(NAME,1)”) |
A1 和 A2 中的 SQL 语句,都在 where 条件中使用了子查询。A1 中计算各个首字母的城市中,人口最多的城市名称及人口;A2 中计算首字母相同的各个城市分组中,人口低于组内平均人口的城市名称及人口。A1 和 A2 中的结果如下:
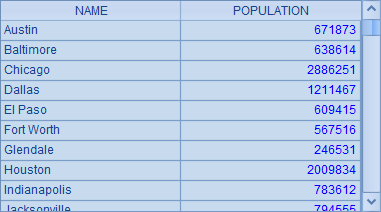
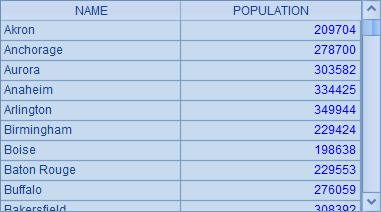
A1 和 A2 中的 SQL 语句相当冗长难读,更麻烦的是,这样的处理方式,需要让数据库在查询每一条记录时都去执行一次类似分组汇总的计算,计算效率非常低,一旦数据量比较大的话就是灾难了。另外,SQL 返回的结果集实际上也看不出分组,只是把满足条件的城市数据依次列出而已。
在集算器中就不一样了,通过使用直观的记录分组,可以让问题解决起来就变得非常简单:
| A | |
|---|---|
| 1 | =demo.query(“select * from CITIES”) |
| 2 | =A1.group(left(NAME,1)) |
| 3 | =A2.(~.maxp(POPULATION)) |
| 4 | =A3.new(NAME,POPULATION) |
| 5 | =A2.((avg=~.avg(POPULATION),~.select(POPULATION>avg))) |
| 6 | =A5.conj().new(NAME,POPULATION) |
A2 中根据城市名称的首字母将数据分组,上面的两个问题都可以利用 A2 的分组结果来计算。A3 中可以很简单地获得每个首字母城市组中,人口最多的城市记录,结果如下:
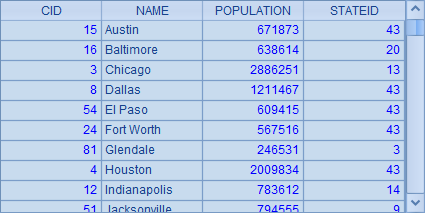
这里获得的是原始表中的记录,如果只需要 NAME 和 POPULATION,可以使用 A4 中的方法计算结果:
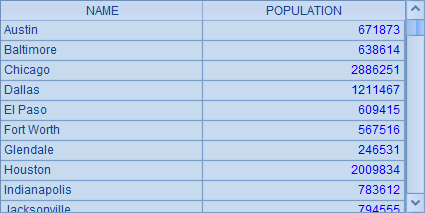
这个结果和前面用 SQL 获得的是相同的,但计算过程就简单得多了。
A5 中的处理也类似,计算出各个同首字母的城市组中,人口低于平均值的记录,为了避免重复计算,在每个分组中先计算出人口均值记录为 avg。A5 中结果如下:
如果需要获得和 SQL 查询相同的结果,可以将各个分组中的记录合并在一起再取出所需字段,如 A6 中的结果:
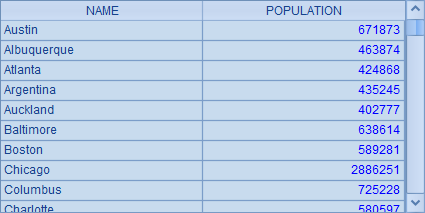
3、枚举分组
以上提到的分组,其实都是“等值分组”,就是按照相同的字段值或计算结果将记录分组。还有一种更麻烦的情况,“按条件分组”。
这里,我们以一个“按枚举条件分组”的例子来看一下,仍然使用前面城市信息数据,现在需要计算分别以 G,R,O,U,P 这 5 个字母作为首字母的城市各有多少个,以及这些城市的平均人口。如果仍然使用 SQL 执行查询,通常的方法就只能用 union 去写出一个超长的语句去处理了,如下:
| A | |
|---|---|
| 1 | =demo.query(“select 1 LOC, left(NAME,1) INITIAL, count(*) CITY_COUNT, round(avg(POPULATION),2)AVG_POPU from CITIES where left(NAME,1)=’G’ group by INITIAL union select 2 LOC, left(NAME,1) INITIAL, count(*) CITY_COUNT, round(avg(POPULATION),2)AVG_POPU from CITIES where left(NAME,1)=’R’ group by INITIAL union select 3 LOC, left(NAME,1) INITIAL, count(*) CITY_COUNT, round(avg(POPULATION),2)AVG_POPU from CITIES where left(NAME,1)=’O’ group by INITIAL union select 4 LOC, left(NAME,1) INITIAL, count(*) CITY_COUNT, round(avg(POPULATION),2)AVG_POPU from CITIES where left(NAME,1)=’U’ group by INITIAL union select 5 LOC, left(NAME,1) INITIAL, count(*) CITY_COUNT, round(avg(POPULATION),2)AVG_POPU from CITIES where left(NAME,1)=’P’ group by INITIAL order by LOC”) |
这里调用的 SQL,需要将 5 个类似的 select 语句 union 到一起,同时为了得到所需顺序,还需要添加一列用来排序,执行后结果如下:
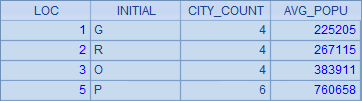
这种情况在用 SQL 处理一些不那么常规的查询时经常会发生,每次都不得不去写长长的一串 SQL,万一在复制粘贴时出点什么差错,也是相当难以纠正的。
由于集算器和 SQL 不同,支持真正的分组操作,所以这类个性化的问题,反而正是集算器所擅长的:
| A | |
|---|---|
| 1 | =demo.query(“select * from CITIES”) |
| 2 | [G,R,O,U,P] |
| 3 | =A1.align@a(A2,left(NAME,1)) |
| 4 | =A3.new(A2(#):INITIAL,~.count():CITY_COUNT, int(~.avg(POPULATION)):AVG_POPU) |
A3 中用函数 align 将城市记录按照所需的首字母对齐分组,结果如下:
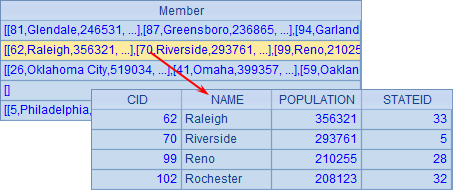
A4 中统计出每个分组中的城市总数和平均人口,考虑到其中可能存在的空组,首字母直接从 A2 中按位置获取:
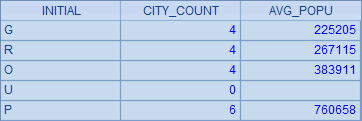
如果不需要其中不包含任何城市的“U”分组,可以把 A4 中的表达式修改为:=A3.select(~.count() > 0).new(left(NAME, 1):INITIAL, ~.count():CITY_COUNT, int(~.avg(POPULATION)):AVG_POPU)。
在上面的问题中,根据不同的首字母分组,也可以写为用表达式表示的条件,在集算器中可以 enum 函数来分组计算:
| A | |
|---|---|
| 1 | =demo.query(“select * from CITIES”) |
| 2 | [left(?,1)==”G”,left(?,1)==”R”,left(?,1)==”O”,left(?,1)==”U”,left(?,1)==”P”] |
| 3 | =A1.enum(A2,NAME) |
| 4 | =A3.new(A2(#):INITIAL,.count():CITY_COUNT, int(.avg(POPULATION)):AVG_POPU) |
A2 中的分组条件用更直观的方式表示,如 left(?,1)==”G”表示首字母为 G,等等。这种情况下使用枚举分组函数 enum 就能根据 NAME 的首字母按条件分组。A3 中的分组结果,以及 A4 中的汇总结果和用 align 的情况是相同的。
实际上,用 align 对齐分组时,解决的仍然是“等值分组”的情况,而用枚举分组时就很自由了,只要能用表达式表示的条件都可以作为分组依据。如下面按人口数将城市分组:
| A | |
|---|---|
| 1 | =demo.query(“select * from CITIES”) |
| 2 | [?>5000000, ?>2000000, ?>1000000] |
| 3 | =A1.enum(A2,POPULATION) |
| 4 | =A3.new(A2(#):POPU_SCALE,~.count():CITY_COUNT, int(~.avg(POPULATION)):AVG_POPU) |
A3 中按照人口将各个城市分为 500 万以上,200 万以上和 100 万以上三组,结果如下:
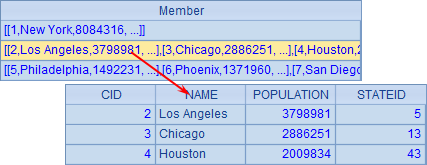
A4 中根据分组结果统计计算:

使用 enum 函数执行枚举分组时,还支持多种分组模式,如:
| A | |
|---|---|
| 1 | =demo.query(“select * from CITIES”) |
| 2 | [?>5000000, ?>2000000, ?>1000000] |
| 3 | =A1.enum@r(A2,POPULATION) |
| 4 | =A1.enum@n(A2,POPULATION) |
A3 中枚举分组时,添加了 @r 选项,此时分组时允许记录重复出现在不同的分组中,分组结果如下:
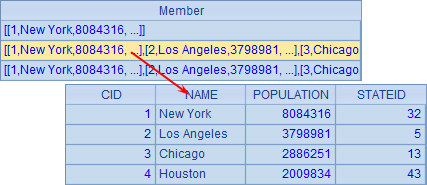
从结果中可以看到,由于人口 500 万以上的城市当然也能满足人口在 200 万以上,所以在这种分组方式下,第 2 组中也包含了第 1 组中的 New York。
A4 中使用了 @n 选项,分组结果如下:
可以发现,这时分组时在最后多了一组,不满足 A2 中任何一个分组条件的城市记录,都被分在了第 4 组中。
在集算器中使用枚举分组时,可以处理各类灵活的分组计算问题,而这种问题往往是用 SQL 时所面对的最大的烦恼。所以,是时候摆脱又长又烦的 SQL 语句了,就让集算器来帮你放松一下吧。


英文版