


【程序设计】5.5 [一把抓] 定位选出
5.5 定位选出
从序列中取出子序列(也就是集合取子集)是常见运算,我们已经学过用 to 函数和数列根据成员的位置取出子序列。
有时候我们希望从序列尾部按倒数次序取成员,当然可以用序列长度计算出正数的序号,但有点麻烦。SPL 提供了函数可以使用倒数次序。
函数 A.m(i) 将取出 A 的第 i 个成员,如果 i<0 时取出倒数第 -i 个成员,即
A.m(i)=A(if(i>0,i,i+A.len()+1))
类似地,p 是允许有负数成员的长度为 k 的数列时,有函数
A.m(p)=[A.m(p(1)),…,A.m(p(k))]
经常会使用 A.m(-1) 用来取出 A 的最后的个成员,帕斯卡三角可以再简化一点:
A |
B |
|
1 |
5 |
=[[1],[1,1]] |
2 |
for A1-1 |
=B1.m(-1).(~+~[-1]) |
3 |
>B1=B1|[B2|1] |
还可以按某个步长取成员:
A.step(k,i)=[A(i),A(i+k),A(i+2*k),…]
从第 i 个开始,每隔 k 个取一个。
A.step(2,1) 将取出奇数序号的成员,A.step(2,2) 取出偶数序号的成员。
当然,更常见的还是选择出满足某个条件的成员:
A.select(x) 将返回由 A 中使 x 为 true 的成员构成的序列,其中 x 中可以使用 ~ 和 #等循环函数中允许的符号。select 称为选出函数,它也是个循环函数。
选出函数特别常用,我们举几个例子:
A |
B |
|
1 |
[13,30,45,23,42,98,61] |
|
2 |
=A1.select(~%2==0) |
[30,42,98] |
3 |
=A1.select(~>30) |
[45,42,98,61] |
4 |
=A1.select(~>~[-1]) |
[13,30,45,42,98] |
5 |
=A3.select((~-~[-1])%2==0) |
[98] |
B 列的常数是 A 列选出函数的结果,A5 是在 A3 的基础上进一步做选出。
其实,A.step 也可以由选出函数表示,即
A.step(k,i)==A.select( #-i>0 && (#-i)%k==0 )
实际上是用序号作为条件来实现选出的结果。
利用这些函数,我们来计算 1000 内的质数表:
A |
B |
C |
|
1 |
=to(1000) |
>A1(1)=0 |
|
2 |
for 2,31 |
if A1(A2)==0 |
next |
3 |
>A1.step(A2,2*A2).select(~>0).run(A1(~)=0) |
||
4 |
=A1.select(~>0) |
=A4.select(~[1]-~==2).([~,~+2]) |
|
1000 之内的合数,总有一个不超过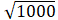 <32 的质因子。我们只要拿 32 内的整数去筛选数列 to(1000),把这些数的倍数都排除掉(相应位置的成员填为 0),剩下不是 0 的成员就必然是质数了。
<32 的质因子。我们只要拿 32 内的整数去筛选数列 to(1000),把这些数的倍数都排除掉(相应位置的成员填为 0),剩下不是 0 的成员就必然是质数了。
A1 生成目标数列,B1 先把 1 排除掉(1 不算质数),即将该位置成员填成 0。然后 A2 从 2 开始循环到 31,如果这个位置的成员已经是 0,说明它是合数,不用管了,跳到下一轮循环。如果是质数,则把它的所有倍数所在位置挑出来,即 A1.step(A2,A2*2),注意要从 A2*2 开始,把 A2 自己跳过去,因为 A2 是个质数要留下。然后这些位置上的成员可能已经有 0 的,说明被之前面轮次给筛掉了,把这些要排除掉,即用 select(~>0) 留下不是 0 的,这些位置都是 A2 的倍数,也就是合数,将这些位置的成员置为 0,然后进入下一轮循环。
全部做完后,再选出剩下的非 0 成员,就是所有的质数了。B4 顺便在此基础上计算出这里面所有的孪生质数对(相差等于 2 的质数),使用了选出函数和我们学过 A.(),结果是个二层序列。
选出运算将从序列中取出成员,反过来,我们还会关心某个数据是不是在序列中以及在序列中的位置。
函数 A.pos(x) 将返回 x 在 A 中的位置,更严格地说,是找出某个 i 使得 A(i)==x,如果有多个 A(i) 都和 x 相同,则会返回第 1 个,如果找不到,则返回 null。后面这种情况更为常用,即用 pos 函数返回值是否 null 来判断某个数据是否在序列中。
类似地,还有个 A.pseg(x) 函数,对于成员值递增的序列 A,就是满足 A(i)>A(i+1),该函数将返回 x 会落在哪一段,即如果 A(i)<=x<A(i+1),则 pseg 将返回 i;如果 x<A(1),它将返回 0;如果 A.m(-1)<x,则返回 A.len()。我们以递增序列为例说明,其实它对递减序列也成立,不过这些小于号都要改成大于号。
日常工作中常常会有分段统计的需求,比如年龄段、销售额分段等,这时候都可以使用 pseg 函数,但我们要等后面学过结构化数据之后再来举这类例子了。
前面那个数字黑洞问题,理论上还可能出现循环的情况,即 a 变成 b,b 变成 c,c 又变回 a,这时候也会导致无穷无尽地循环下去,但我们现在的程序还无法识别出这种情况。只是因为我们事先做过功课,确定地知道四位数中只有单一的黑洞,所以代码也就那么写了,但换其它位数就不一定了。
利用 pos 函数可以找这种循环情况,同时利用 pseg 函数和 insert 函数还能改进排序。
A |
B |
C |
D |
|
1 |
5 |
12345 |
=A1.run(~=if(#>1,~[-1]*10,1)) |
|
2 |
for |
=[] |
=C1.(B1\~%10) |
|
3 |
for C2 |
=B2.pseg(B3) |
>B2.insert(if(C3==B2.len(),0,C3+1),B3) |
|
4 |
=C1.sum(B2(#)*~) |
=C1.sum(B2.m(-#)*~) |
||
5 |
=@|B1 |
>output(B1) |
>B1=B4-D4 |
|
6 |
if B5.pos(B1) |
break |
||
这段程序可以寻找任意位数的数字黑洞。A1 是位数,B1 是起始值。
这里我们运用了之前学过的各种技巧,C1 先利用 run 计算出一个序列 [1,10,100,…],C2 格利用它来拆解出各位数字。排序现在只要一行了,目前结果放在 B2 中,B3 针对每位数字循环,在 C3 用 pseg 找出新数字应该插入的位置,在 D3 用 insert 插入,循环结束时 B2 就是从小到大排列的数字了。B4 和 D4 再次利用 C1 计算出大数和小数。B5 中的 @表示它自己,在程序开始运行时会自动把所有格值清空,那么这个表达式将会不断累积计算出来的数,用一个序列记录这些数。B6 中如果发现新计算出来的数已经在序列中,那说明将会出现循环情况了,就该停止了。
需要注意的是, pos 和 pseg 不是循环函数,其参数中的 x 中不能也不必再使用 ~、# 等符号,如果使用了,则被认为是上一层循环函数的(这些函数可能被嵌套在循环函数中)。
这些道理,我们在本章最后还会再讲解。
我们会关心满足条件的成员,但有时还会关心这些成员的位置。比如我们想从 12 个月的销售额序列中找出哪些月份发生了增长。使用 select 函数只能找出增长的成员,并不能获得发生增长的成员所在的位置。
A.pselect(x) 函数可以帮助我们,它将返回使 x 为 true 的成员序号。换用循环函数的符号来说,就是 select 会返回由 ~ 构成的序列,而 pselect 将返回对应的 #。pselect 被称为定位函数。
我们来试一下:
A |
B |
|
1 |
[13,30,45,23,42,98,61] |
|
2 |
=A1.pselect(~%2==0) |
[2,5,6] |
3 |
=A1.pselect(~>30) |
[3,5,6,7] |
4 |
=A1.pselect(~>~[-1]) |
[1,2,3,5,6] |
我们期望 A 列的计算结果就是 B 列的值,然而,却不是?A2,A3,A4 分别返回了 2,3,1,只是 B 列序列的第 1 个值。
这是怎么回事?
原来,pselect 函数就是这么约定的,它只返回第一个满足条件的 #。
那么,我们希望像 select 那样能返回所有满足条件的 #,该怎么办?
A |
B |
|
1 |
[13,30,45,23,42,98,61] |
|
2 |
=A1.pselect@a(~%2==0) |
[2,5,6] |
3 |
=A1.pselect@a(~>30) |
[3,5,6,7] |
4 |
=A1.pselect@a(~>~[-1]) |
[1,2,3,5,6] |
在函数名后面加个 @a 就可以了。
这又是个什么东西?
@a 这种写法是 SPL 发明的,称为函数选项。理论上讲, pselect 和 pselect@a 是两个无关的不同函数,但这两个函数非常像,都是针对序列的,参数也一样,完成的功能虽然不完全相同,但也很类似。这种时候,我们更愿意把其中一个看成是另一个的变种,在起名时使用相似的名字,这样对于理解和记忆都会更方便一点。
但这两个函数总还是有不同,需要区分。在 SPL 中我们用相同的名字来命名这两个函数,而用函数名后 @后面的字符来区分,好象一个函数有了不同的模式:没有 @a 时,pselect 只返回第 1 个,有 @a 时将返回所有。
SPL 中这种有选项的函数非常多,而且选项常常还不只一种。比如 pselect 还有个 @z 的选项,表示从后面往前找。上例中,A1.pselect@z(~%2==0) 将返回 6。而且,这些选项还可能组合使用,A1.pselect@az(~%2==0) 表示从向往前找所有满足条件的 #,结果会返回 [6,5,2]。
选项书写是没有次序的,pselect@az 和 pselect@za 是一样的。
对应地,select 函数有个 @1 选项,表示找到第一个满足条件的成员就返回。这样的设计的原因是 select 返回所有的情况更常见,而 pselect 返回第 1 个的情况更常见。
SPL 的函数选项能大大简化代码的编写。目前其它程序语言都没有这种语法,有些语言的函数也有选项概念,但一般是作为一个独立参数存在的。我们后面还会看到,在结构化数据处理时,参数会有很复杂的情况,把选项信息作为参数传递并不方便。
我们会用 max 函数找出序列成员的最大值,同样地,我们也可能还会关心最大值所在的位置,SPL 也提供了 A.pmax() 函数来返回对序列 A 中最大值所在的位置。
一个序列的最大值是唯一的,但取值最大的成员却可能有多个,所以 pmax 也和 pselect 类似,缺省返回第一个最大值所在的位置,加选项 @a 则会返回所有,@z 则会从后往前找。
pmax 函数不难理解,这里就不举例子了。而且,对应地当然还也会有 pmin 函数。
我们把 pmax 提出来讲,是为了加深对定位函数的理解。pmax 也是一种定位函数,定位是常见的运算,但很多程序语言中都没有提供相应的库函数,SPL 特别关注了这种运算。
忘了提一句,pos 函数也有 @a 和 @z 选项。
容易被忽略的是,与 max 相关还有选出函数 maxp。
A.maxp()的定义是 A(A.pmax()),就是返回最大值对应的那个成员。
仔细想一下,它不就是 A.max() 吗?为什么还要再造一个新函数?
还是不一样的。简单看,A.pmax()有 @a 选项,它可能返回多个值,这样 A.maxp@a() 也可能返回一个序列,但 A.max() 则不会返回序列的。
不过,A.maxp@a() 即使是序列,成员也都相同,似乎没什么太大意思。
更大的不同在于有参数的情况。A.max(x) 会返回最大的 x,而 A.maxp(x) 则会返回使 x 最大的那个成员。比如:
A |
B |
|
1 |
[13,30,45,23,42,98,61] |
|
2 |
=A1.max(~%10) |
8 |
3 |
=A1.maxp(~%10) |
98 |
看出区别了吗?
我们知道,A.max(x) 就是 A.(x).max(),A.pmax(x) 也等于 A.(x).pmax(),但是,A.maxp(x) 却不是 A.(x).maxp(),它还是定义为 A(A.pmax(x))。
max 返回最大值本身,而 maxp 返回的是使最大值出现的那个成员,对于单纯的序列而言,它们是一样的,但配有表达式时,就可以发现它们的区别了。在后面要涉及到的结构化数据处理中,这种运算是很常见的,比如我们经常会更关心导致销售额最高的那个产品,而不是最高的销售额本身。
max 不是选出函数,它返回的是值。而 maxp 返回的成员(构成的序列),是选出函数。和定位函数类似,选出函数也是一大类运算。
当然也还会有 minp 函数。


[100,50,20,10]
=A1.pseg(22) 这行的值怎么是 0
这里不能用降序,函数参考中描述有误
开源整理时简化成只支持升序了,文档没有及时跟进
A.m(i)=A(if(i>0,i,i+A.len()-1))这一行看着是写错了,相减应改为相加,A.m(i)=A(if(i>0,i,i+A.len()+1))。用一些简单序列测试过
哦,是的。