


按指定基准对齐的分组运算
【摘要】
在分组时经常会要求结果集必须按基准集合的次序出现,这种对齐分组在日常统计中是很常见的。我们还能把对齐分组推广成更一般的枚举分组。如何简便快捷的处理对齐分组,这里为你全程解析,并提供 esProc 示例代码。按指定基准对齐的分组运算
对照一个基准集合,将待分组集合成员的某个字段或表达式与基准集合成员比较,相同者则分到同一个组中,最后拆分出来的组数和基准集合成员数是相同的。这种分组我们称为对齐分组。对齐分组可能会有空组,也可能有成员未分配到任何一个组中。
1. 普通对齐分组
1.1 每组保留最多一个匹配成员
按某字段的指定顺序,将表中所有记录分组并汇总求和。
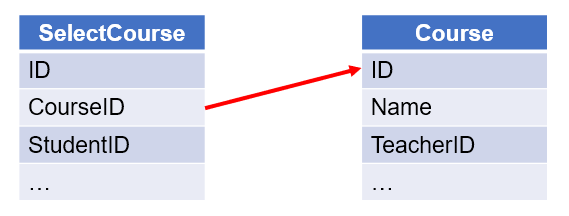
【例 1】 根据相互关联的课程表和选课表,按课程表顺序查询有哪些课程无人选择:
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from SelectCouse") |
/查询选课表 |
3 |
=A1.query("select * from Course") |
/查询课程表 |
4 |
=A2.align(A3:ID,CourseID) |
/使用函数 A.align(),将选课表按照课程表的 ID 对齐,每组选择一个匹配成员 |
5 |
=A3(A4.pos@a(null)) |
/在课程表中选出没有选择(值为 null)的课程信息 |
A5的执行结果如下:
ID |
NAME |
TeacherID |
1 |
Environmental protection and sustainable development |
5 |
10 |
Music appreciation |
18 |
1.2 每组保留所有匹配成员
按某字段的指定顺序,将表中所有记录分组并汇总求和。
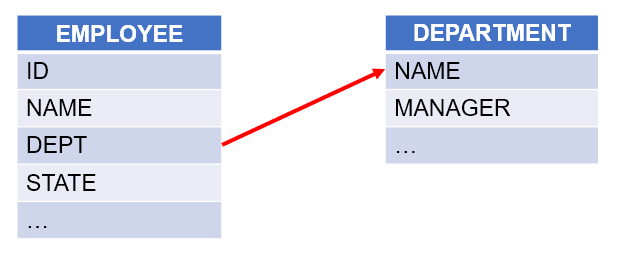
【例 2】 根据相互关联的员工表和部门表,按部门表中的部门顺序统计各部门人数:
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from EMPLOYEE") |
/查询员工表 |
3 |
=A1.query("select * from DEPARTMENT") |
/查询部门表 |
4 |
=A2.align@a(A3:ID, DEPARTMENT) |
/使用函数 A.align@a(),将员工表按部门对齐分组,@a 选项每组返回所有匹配成员 |
5 |
=A4.new(DEPT, ~.count():COUNT) |
/统计各部门的人数 |
A5的执行结果如下:
DEPT |
COUNT |
Admin |
4 |
R&D |
29 |
Sales |
187 |
… |
… |
1.3 不匹配记录放到新组
按某字段的指定顺序,将表中所有记录分组,不匹配记录放到新组。
【例 3】 根据员工薪资表,统计 [California, Texas, New York, Florida] 的平均工资,未指定的州作为“Other”统计。员工薪资表部分数据如下:
ID |
NAME |
STATE |
SALARY |
1 |
Rebecca |
California |
7000 |
2 |
Ashley |
New York |
11000 |
3 |
Rachel |
New Mexico |
9000 |
4 |
Emily |
Texas |
7000 |
5 |
Ashley |
Texas |
16000 |
… |
… |
… |
… |
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from EMPLOYEE") |
/查询雇员表 |
3 |
[California,Texas,New York,Florida] |
/创建地区序列 |
4 |
=A2.align@an(A3,STATE) |
/使用函数 A.align@an(),将雇员表按地区对位分组,@a 选项每组返回所有匹配成员,@n 选项不匹配成员存放到新组。 |
5 |
=A4.new(if (#>A3.len(),"Other",STATE):STATE,~.avg(SALARY):AvgSalary) |
/统计每组的平均工资,产生新序表。最后一组的地区更名为 Other,否则为当前组第一条记录的地区。 |
A5的执行结果如下:
STATE |
SALARY |
California |
7700.0 |
Texas |
7592.59 |
New York |
7677.77 |
Florida |
7145.16 |
Other |
7308.1 |
2. 序号对齐分组
序号对齐分组,是指按照指定的序号进行分组,序号相同的成员分到同一组。
2.1 每组保留最多一个匹配成员
在相互关联的两个表中,查找未被引用的记录。
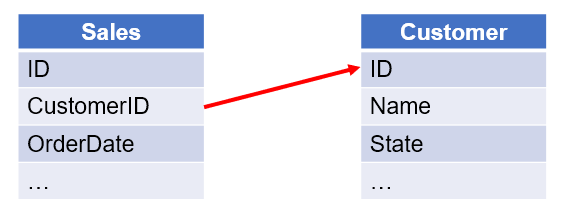
【例 4】 根据相互关联的销售表和客户表,顺序列出 2014 年没有销售记录的客户:
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from Sales") |
/查询销售表 |
3 |
=A1.query("select * from Customer") |
/查询客户表 |
4 |
=A3.(ID) |
/从客户表中选出客户序号 |
5 |
=A2.align(A4.len(), A4.pos(CustomerID)) |
/使用函数 A.align(n,y),将销售表按照客户序号对位分组 |
6 |
=A3(A5.pos@a(null)) |
/在客户表中选出没有销售记录(值为 null)的客户信息 |
A6的执行结果如下:
ID |
Name |
State |
… |
ALFKI |
CMA-CGM |
Texas |
… |
CENTC |
Nedlloyd |
Florida |
… |
2.2 每组保留所有匹配成员
按序号将表中所有记录分组并汇总求和。
【例 5】 根据订单表,顺序列出 2013 年每月的订单总数。订单表部分数据如下:
ID |
CustomerID |
OrderDate |
Amount |
10248 |
VINET |
2012/07/04 |
428.0 |
10249 |
TOMSP |
2012/07/05 |
1842.0 |
10250 |
HANAR |
2012/07/08 |
1523.5 |
10251 |
VICTE |
2012/07/08 |
624.95 |
10252 |
SUPRD |
2012/07/09 |
3559.5 |
… |
… |
… |
… |
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from Orders where year(OrderDate)=2013") |
/查询 2013 年的订单 |
3 |
=A2.align@a(12,month(OrderDate)) |
/使用函数 A.align@a(),将订单表按月份对位分为 12 组,@a 选项每组选择所有匹配成员 |
4 |
=A3.new(#:Month,~.count():OrderCount) |
/列出每月的订单总数 |
A4的执行结果如下:
Month |
OrderCount |
1 |
33 |
2 |
29 |
3 |
30 |
4 |
31 |
5 |
32 |
6 |
30 |
7 |
33 |
8 |
33 |
9 |
37 |
10 |
38 |
11 |
34 |
12 |
48 |
2.3 按序号重复性分组
按计算出的序号数列重复性分组并计算。
【例 6】 根据发帖记录表,按标签将帖子分组,并统计各个标签出现频数。发帖记录表部分数据如下:
ID |
Title |
Author |
Label |
1 |
Easy analysis of Excel |
2 |
Excel,ETL,Import,Export |
2 |
Early commute: Easy to pivot excel |
3 |
Excel,Pivot,Python |
3 |
Initial experience of SPL |
1 |
Basics,Introduction |
4 |
Talking about set and reference |
4 |
Set,Reference,Dispersed,SQL |
5 |
Early commute: Better weapon than Python |
4 |
Python,Contrast,Install |
… |
… |
… |
… |
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from PostRecord") |
/查询发帖记录表 |
3 |
=A2.conj(Label.split(",")).id() |
/将标签按逗号分隔后合并到一个序列,获得没有重复值的全部标签。 |
4 |
=A2.align@ar(A3.len(),A3.pos(Label.split(","))) |
/使用 align 函数的 @r 选项,按照每个帖子的标签在全部标签中的定位分组。 |
5 |
=A4.new(A3(#):Label,~.count():Count).sort@z(Count) |
/统计每个标签的帖子数量,按降序排列 |
A5的执行结果如下:
Label |
Count |
SPL |
7 |
SQL |
6 |
Basics |
5 |
… |
… |
2.4 分段分组
根据指定字段的值,分段分组并汇总计数。
【例 7】 根据员工薪资表,按工资 8000 以下、8000~12000 和 12000 以上分组,并统计各组的人数。员工薪资表部分数据如下:
ID |
NAME |
BIRTHDAY |
SALARY |
1 |
Rebecca |
1974-11-20 |
7000 |
2 |
Ashley |
1980-07-19 |
11000 |
3 |
Rachel |
1970-12-17 |
9000 |
4 |
Emily |
1985-03-07 |
7000 |
5 |
Ashley |
1975-05-13 |
16000 |
… |
… |
… |
… |
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from EMPLOYEE") |
/查询员工表 |
3 |
[0,8000,12000] |
/定义工资区间 |
4 |
=A2.align@a(A3.len(),A3.pseg(SALARY)) |
/使用函数 A.pseg(x) 获取工资所在区间 |
5 |
=A4.new(A3 (#):SALARY,~.count():COUNT) |
/统计每组的人数 |
A5的执行结果如下:
SALARY |
COUNT |
0 |
308 |
8000 |
153 |
12000 |
39 |
根据表达式的计算结果,将记录分段分组并汇总计算平均值。
【例 8】根据员工表,按入职时间 10 年以下,10~20 年和 20 年以上分组,并统计每组的平均工资。员工表部分数据如下:
ID |
NAME |
BIRTHDAY |
SALARY |
1 |
Rebecca |
1974-11-20 |
7000 |
2 |
Ashley |
1980-07-19 |
11000 |
3 |
Rachel |
1970-12-17 |
9000 |
4 |
Emily |
1985-03-07 |
7000 |
5 |
Ashley |
1975-05-13 |
16000 |
… |
… |
… |
… |
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from EMPLOYEE") |
/查询员工表 |
3 |
[0,10,20] |
/定义入职年限区间 |
4 |
=now() |
/获取当前日期时间 |
5 |
=A2.align@a(A3.len(),A3.pseg(elapse@y(A4,-~), HIREDATE)) |
/使用函数 A.pseg(x,y) 获取入职时间所在区间 |
6 |
=A5.new(A3(#):EntryYears,~.avg(SALARY):AvgSalary) |
/统计每组的平均工资 |
A6的执行结果如下:
EntryYears |
AvgSalary |
0 |
6777.78 |
10 |
7445.53 |
20 |
6928.57 |
3. 枚举分组
枚举分组是指,事先指定一组枚举条件,将待分组集合的成员作为参数计算这批条件,条件成立者都被划分到与该条件对应的一个子集中,结果集的子集和事先指定的条件一一对应。
3.1 每个成员只存放到第一个匹配组
根据枚举条件表达式,将记录分组,分组时记录只置于第一个匹配组。
【例 9】 根据中国主要城市人口表,按人口将城市分类。中国主要城市人口表部分数据如下:
ID |
City |
Population |
Province |
1 |
Shanghai |
12286274 |
Shanghai |
2 |
Beijing |
9931140 |
Beijing |
3 |
Chongqing |
7421420 |
Chongqing |
4 |
Guangzhou |
7240465 |
Guangdong |
5 |
Hong Kong |
7010000 |
Hong Kong Special Administrative Region |
… |
… |
… |
… |
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from UrbanPopulation") |
/查询城市人口表 |
3 |
[?>2000000,?>1000000,?>500000,?<=500000] |
/超大城市 200 万人口以上,特大城市 100-200 万人口,大城市 50-100 万,其他中小城市。 |
4 |
=A2.enum(A3,Population) |
/使用函数 A.enum(),将人口按 A3 定义的条件进行枚举分组 |
A4的执行结果如下:

3.2 不匹配成员存放到新组
根据枚举条件表达式,将记录分组,不匹配记录放到新组。
【例 10】 根据员工薪资表,按年龄条件 [小于 35 岁, 小于 45 岁] 将员工分组,统计平均工资,不满足条件的分到新组。员工薪资表部分数据如下:
ID |
NAME |
BIRTHDAY |
SALARY |
1 |
Rebecca |
1974-11-20 |
7000 |
2 |
Ashley |
1980-07-19 |
11000 |
3 |
Rachel |
1970-12-17 |
9000 |
4 |
Emily |
1985-03-07 |
7000 |
5 |
Ashley |
1975-05-13 |
16000 |
… |
… |
… |
… |
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from EMPLOYEE") |
/查询员工表 |
3 |
[?<35,?<45] |
/将年龄段划分为 35 岁以下,45 岁以下 |
4 |
=A2.enum@n(A3, age(BIRTHDAY)) |
/使用函数 A.enum@n(),按年龄枚举分组,选项 @n 不匹配成员存放到新组。 |
5 |
=A4.new(if (#>A3.len(), "Other",A3(#)):AGE,~.avg(SALARY):AvgSalary) |
/统计每组的平均工资,最后一组名称设置为 Other |
A5的执行结果如下:
AGE |
AvgSalary |
?<35 |
7118.18 |
?<45 |
7448.16 |
Other |
7395.06 |
3.3 按照枚举条件可重复分组
根据不同的指定序列,将记录分组并计算,分组时记录可重复。
【例 11】 根据城市 GDP 表,分别统计直辖市、一线城市、二线城市的人均 GDP,分组时可能重复。城市 GDP 表部分数据如下:
ID |
City |
GDP |
Population |
1 |
Shanghai |
32679 |
2418 |
2 |
Beijing |
30320 |
2171 |
3 |
Shenzhen |
24691 |
1253 |
4 |
Guangzhou |
23000 |
1450 |
5 |
Chongqing |
20363 |
3372 |
… |
… |
… |
… |
【SPL 脚本】
A |
B |
|
1 |
=connect("db") |
/连接数据库 |
2 |
=A1.query("select * from GDP") |
/查询城市 GDP 表 |
3 |
[["Beijing","Shanghai","Tianjing","Chongqing"].pos(?)>0,["Beijing","Shanghai","Guangzhou","Shenzhen"].pos(?)>0,["Chengdu","Hangzhou","Chongqing","Wuhan","Xian","Suzhou","Tianjing","Nanjing","Changsha","Zhengzhou","Dongguan","Qingdao","Shenyang","Ningbo","Kunming"].pos(?)>0] |
/枚举直辖市、一线城市和二线城市 |
4 |
=A2.enum@r(A3,City) |
/使用函数 A.enum@r(),按城市枚举分组。选项 @r 表示可重复分组。 |
5 |
=A4.new(A3(#):Area,~.sum(GDP)/~.sum(Population)*10000:CapitaGDP) |
/统计每组的人均 GDP |
A5的执行结果如下:
Area |
CapitaGDP |
["Beijing","Shanghai","Tianjing","Chongqing"].pos(?)>0 |
107345.03 |
["Beijing","Shanghai","Guangzhou","Shenzhen"].pos(?)>0 |
151796.49 |
["Chengdu","Hangzhou","Chongqing","Wuhan","Xian","Suzhou","Tianjing","Nanjing","Changsha","Zhengzhou","Dongguan","Qingdao","Shenyang","Ningbo","Kunming"].pos(?)>0 |
106040.57 |
《SPL CookBook》中还有更多相关计算示例。

