


可编译执行伪代码(spec)解决 AI 编程幻觉
一段 AI 生成的 SQL,没人敢说“我看懂了”
先看这段 SQL,目标是“找出连续三个月交易额递增的信用卡客户”:
WITH ranked AS (
SELECT customer_id, month, amount,
LAG(amount,1) OVER(PARTITION BY customer_id ORDER BY month) as prev_1,
LAG(amount,2) OVER(PARTITION BY customer_id ORDER BY month) as prev_2
FROM transactions
)
SELECT customer_id, COUNT(*) FROM ranked
WHERE amount > prev_1 AND prev_1 > prev_2
AND prev_1 IS NOT NULL AND prev_2 IS NOT NULL
GROUP BY customer_id HAVING COUNT(*) >= 3
语法完全正确,能跑出结果。但你说它逻辑对吗?没人敢立刻回答。
这是当今数据分析师和开发者的日常:把一个任务丢给 AI,几秒钟后它吐出一段几十行的 SQL,复制粘贴,跑通了,但心里真的踏实吗?现代 AI 能生成可运行的 SQL,但经常无法信任。
AI 给出的 SQL 是个黑盒。代码看起来对、执行起来不报错、返回一个漂亮的结果,但做的事情跟用户想要的压根不是一回事。关键是你只有在它跑完之后才发现错了,review 阶段靠人肉在脑子里执行 SQL,等于把 AI 的活又干了一遍。
更糟的是:即便 AI 生成 SQL 的“准确率”达到 90%,使用者怎么知道这一次有没有落在那 10% 里?数据决策不是抽奖。一个语义跑偏的 SQL,执行成功返回一个漂亮的结果,但根本不是用户想问的,这种错误语法层面检查不出来,而代码 review 阶段去验证它,成本极高:你得一层层拆开 CTE,逐段执行,对比中间结果,才能确认逻辑是否正确。
问题出在哪?
当前 AI 编程有一个基本过程:由人写清楚 spec,AI 才能产出可用代码。
这不是 AI“能不能”的问题,而是当前技术条件下的硬约束。胡乱写两句目标,除非是人人都会写的通用公共任务(比如“写一个冒泡排序”),否则没有哪个 AI 能凭空生成可用的工程代码。真实的 AI 编程流程是:人写 spec → AI 生成代码 → 人 review → 修改 spec → AI 重新生成。spec 是起点,也是贯穿始终的约束。
但 spec 写得再清楚,AI 仍然可能犯错,只是概率高低的问题。spec 写得模糊,AI 猜错的概率就高;写得清楚,犯错的概率降低,但不会归零。因为 AI 本质上在做“猜测”,从输入到输出,它是在概率空间里搜索最可能的答案,而不是在逻辑空间里推导必然的结果。
那怎么办?有没有办法把“猜测”变成“确定”?
答案是:让 spec 规范到可以编译的程度。一旦 spec 可以被编译器解析和执行,就不再需要 AI 来“猜”代码了。编译器是确定性的,同样的输入永远产生同样的输出,不存在“这次对了、下次错了”的问题。你不是在“降低幻觉率”,而是绕过了幻觉产生的环节。
所以整个逻辑链很清楚了:AI 编程需要 spec → spec 写得清楚能降低幻觉率 → 但无法根除 → 把 spec 规范到可编译的程度 → 编译器替代 AI 生成代码 → 幻觉问题自然消失。
可编译的伪代码:spec 的一种进化形态
传统上,程序员写的需求文档是自然语言 + 图表 + 伪代码,给人读的。AI 时代,spec 可以进化成一种同时具备两个特征的新形态:
1. 人类可读:不用懂目标语言(SQL、Java、Python),扫一眼就知道逻辑是什么。
2. 机器可编译:有固定的语法结构,可以确定性地转换成最终代码,不依赖 AI 猜测。
这就是“可编译的伪代码”,一种更规范的 spec。它与传统伪代码的区别在于:传统伪代码不编译,只给人看;可编译的伪代码既能给人看,也能被编译器理解并生成目标代码。
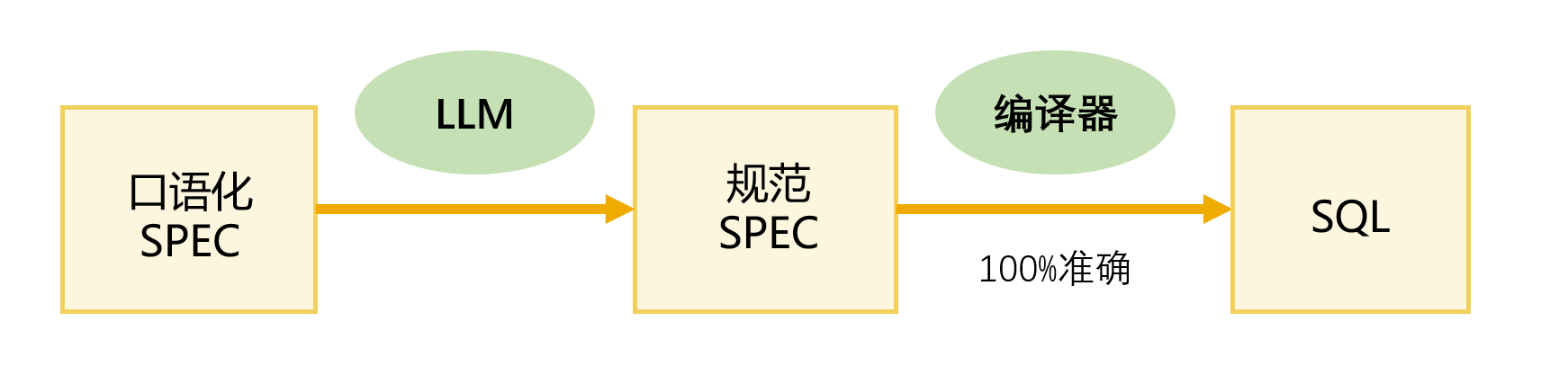
这种 spec 的价值在于:它把 AI 的 "创作空间" 压缩到了最小。AI 不需要 "理解" 业务逻辑、不需要 "设计" 实现方案、不需要 "猜测" 正确的代码,只需要将口语化 spec 翻译规范的 spec。翻译的犯错空间远小于 "从自然语言直接生成代码"。
更重要的是:人可以在编译执行之前确认 spec 是否正确。每一步的逻辑都可以单独验证,错误在执行前被拦截,而不是执行后再 Debug。
SQLazy 的 workflow:可编译的伪代码
SQLazy 把这个理念落到了复杂 SQL 开发领域。它的 workflow 就是一份可编译的伪代码,开发者用自然语言分步描述数据查询逻辑,每一步都可预览中间结果,确认无误后由编译器确定性生成 SQL
还是上面那个需求:“找出连续三个月交易额递增的信用卡客户”。用 SQLazy 的 workflow 写:
Name |
Anchor |
Statement |
t1 |
ccard |
sort customer_id asc cmonth asc |
t2 |
segment amount down as noRising partition customer_id |
|
t3 |
summarize noRising count as ccount group customer_id,noRising |
|
t4 |
filter ccount>=3 |
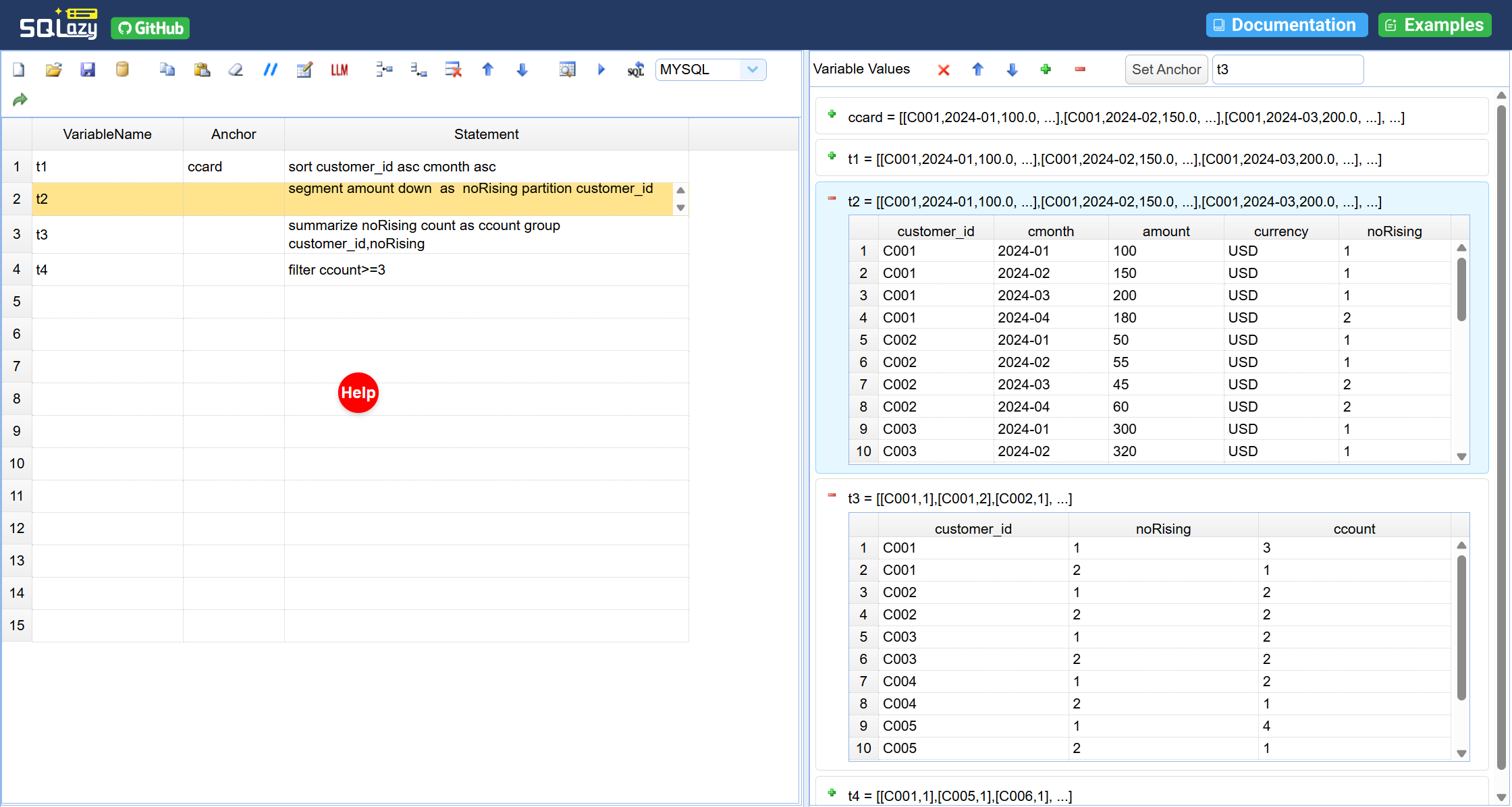
不用懂 SQL,看这 4 步就知道逻辑是什么。每一步都能预览中间结果:
sort:按客户和月份排序
segment:标记交易额下降的记录,生成连续上升区间编号
summarize:统计每个区间包含多少个月份
filter:筛选出连续月份 >=3 的客户
再举一个真实场景的例子。一张表记录了多个账户的时间区间,每个账户有多条记录,区间之间可能存在重叠。需求是合并每个账户内所有重叠的区间。用 SQLazy 实现,只需要 4 步:
sort account_id, start_date:按账户和开始日期排序
compute end_date[:-1] max as prev_max:计算当前行之前所有行的最大结束日期
segment condition start_date > prev_max as gid:按条件分段,生成组号
summarize start_date min as start_date, end_date max as end_date:按账户和组号汇总
确认上述逻辑后,SQLazy 编译器自动生成原生 SQL,100% 准确,不存在幻觉问题。如果目标数据库从 MySQL 换成 Oracle,只需切换一个选项,编译器自动适配 SQL 方言。
SQLazy 的 workflow 就是 spec,编译器就是保证代码质量的最后一道闸门。
在这个过程中,AI 的角色也被重新定义了,在以往做法中 AI 负责从自然语言直接生成最终 SQL,高难度、高幻觉率;而在 SQLazy 中,AI 只做一件事:把用户口语化的步骤描述转译成规范的 workflow 语法。前者是“决策”,后者是“翻译”。即便 AI 转译有偏差,你在 workflow 层面一眼就能发现,纠正成本几乎为零。
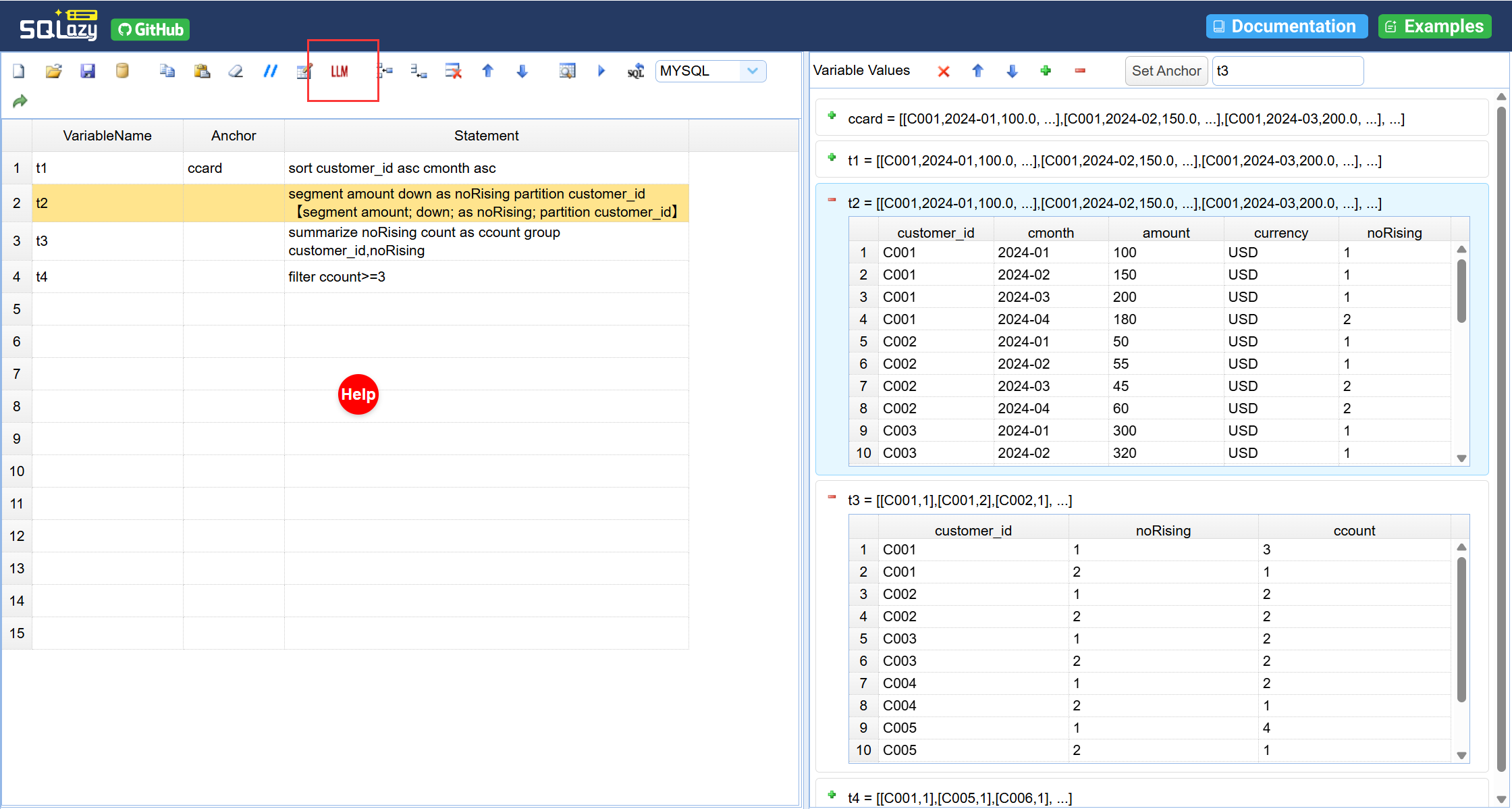
借助 LLM 把自然语言转成 SQLazy 语法
AI 编程的幻觉之所以成为问题,不是因为 AI 偶尔犯错。真正的问题在于:在以往模式下,AI 的错是 "执行后" 才能发现的。代码已经生成,甚至运行完了,你才发现结果不对,纠错成本极高。
SQLazy 这种可编译的伪代码把 "发现错误" 的时机从执行后移到了执行前。人类在 spec 层面确认逻辑,编译器再生成最终代码。AI 的犯错空间被压缩到 "翻译" 这个环节,翻译结果人类可以即时校验,从而解决 AI 编程的幻觉问题。
这不是让程序员回到 "写文档" 的时代。这是重新划分人与 AI 的分工:人负责设计(用结构化的 spec 描述 "要做什么"),AI 负责翻译(把口语化的 spec 转成标准 spec),编译器负责执行(保证产出确定性)。
AI 编程的下一个阶段,可能不是让 AI 写更长的代码,而是让人类写出更清晰的 spec。

