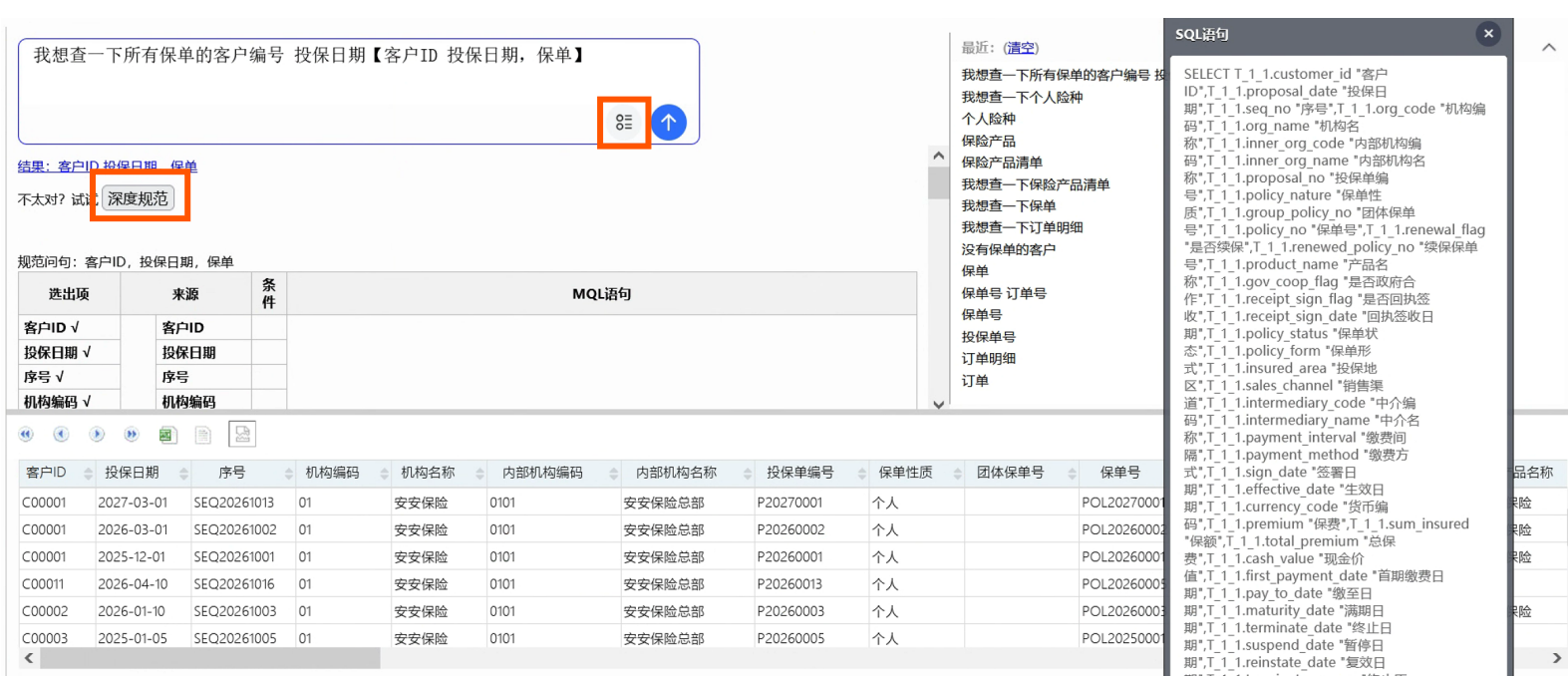
润乾 NLQ 实践(保险行业主题)
1数据准备
保险数据集,数据表和表间关系。
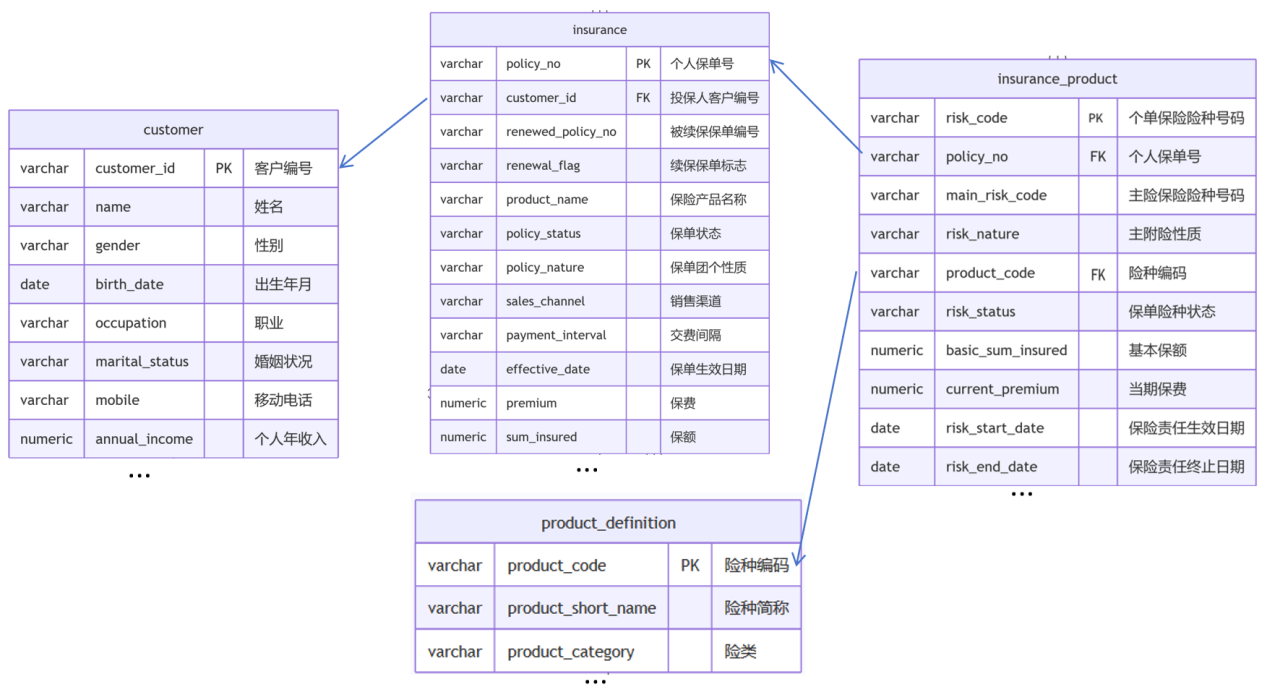
个人保单表:insurance
个人险种表:insurance_product
客户表:customer
险种定义表:product_definition
数据下载(以POSTGRES SQL 数据库为例):
注:数据表和测试数据参考了《金融监管总局保险业监管数据标准化规范(人身保险公司2024 版)数据结构一览表》。
2元数据准备
2.1LLM 辅助生成元数据
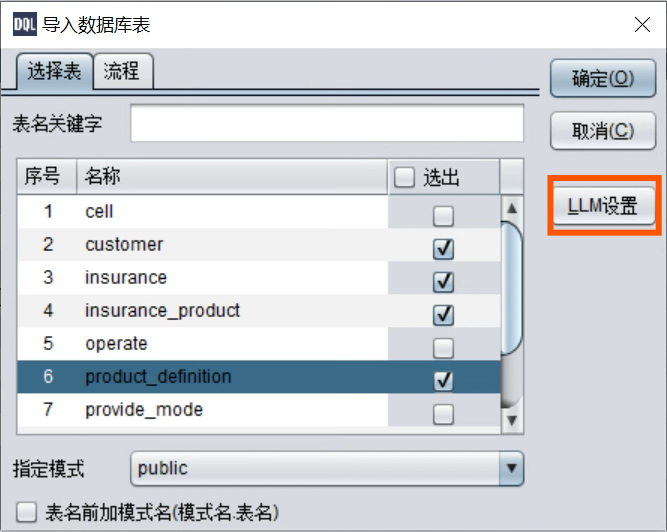
打开DQL 元数据层 配置LLM。
配置LLM。
添加LLM 的 API 信息(URL、模型、秘钥):
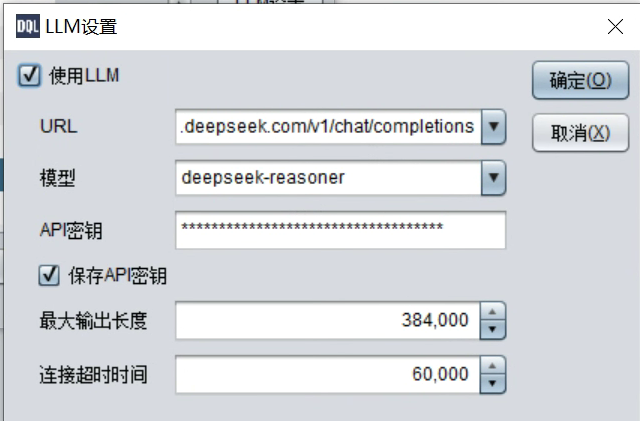
模型选择专家版或者深度思考版,提高准确率,比如图中的reasoner。
这时大模型思考时间会长一些,连接超时时间可以长一些。
在“流程”中选择需要 LLM 生成的内容:
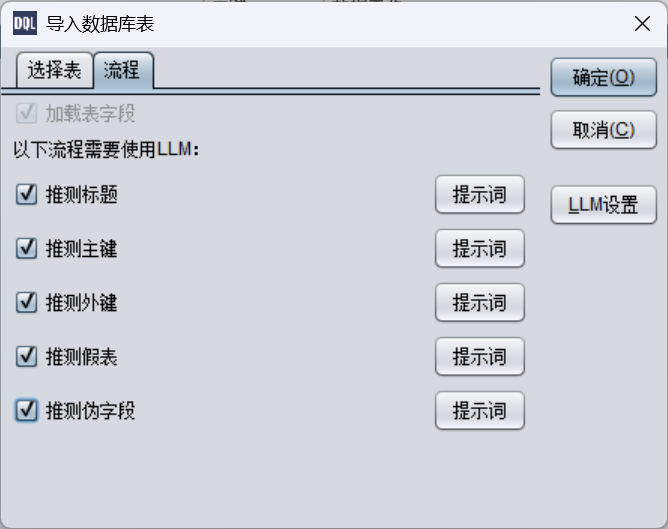
确定后就会自动生成元数据了。LLM 生成元数据可能会有不符的地方(绝大部分是准确的),需要检查后按照前述元数据制作过程手动修改。
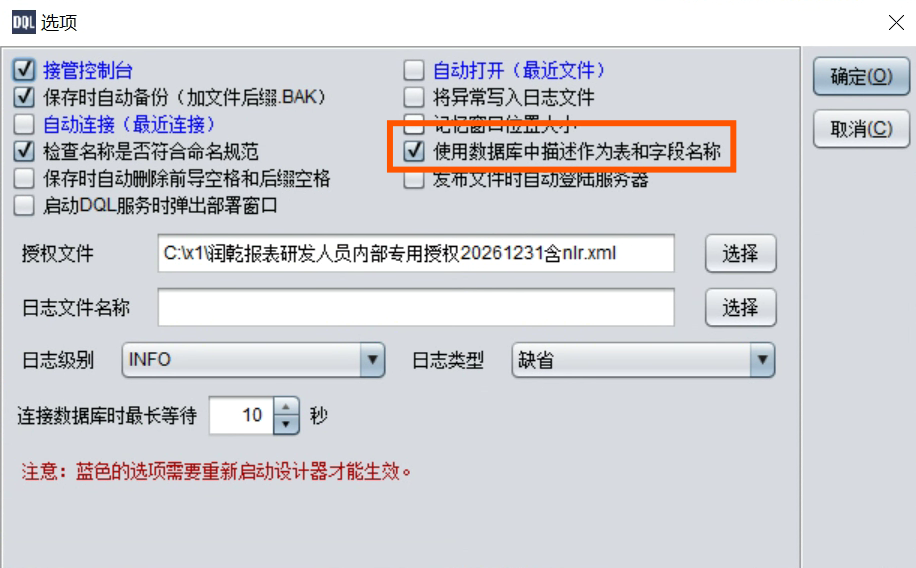
如果数据库中有表、字段的中文注释,可以直接使用:
这样相对更接近用户的习惯用语:
 注意事项
注意事项
鉴于LLM 的幻觉问题,生成后的元数据要认真检查,可能需要手动修改的内容:
1.少量表名和字段名翻译不合适需要修改
2.部分维名需要修改(如将 区域_ 区域 ID -> 区域)
3.少量外键缺失需要添加
检查外键
根据表间关联关系,设置各个表间外键。
外键名 |
外键所在表 |
外键字段 |
引用目标表 |
引用字段 |
fk1 |
insurance |
customer_id |
customer |
customer_id |
fk1 |
insurance_product |
policy_no |
insurance |
policy_no |
fk27 |
insurance_product |
product_code |
product_definition |
product_code |
计算字段做维度
有些维度在表中没有现成字段,需要写表达式计算得到。
比如年龄分类,0-17 岁是少儿,18 到 35 岁时青年,36 到 55 是中年,其他是老年。
这个字段既要计算得到,又要作为维度。这种情况下需要手工配置SQL 型表:
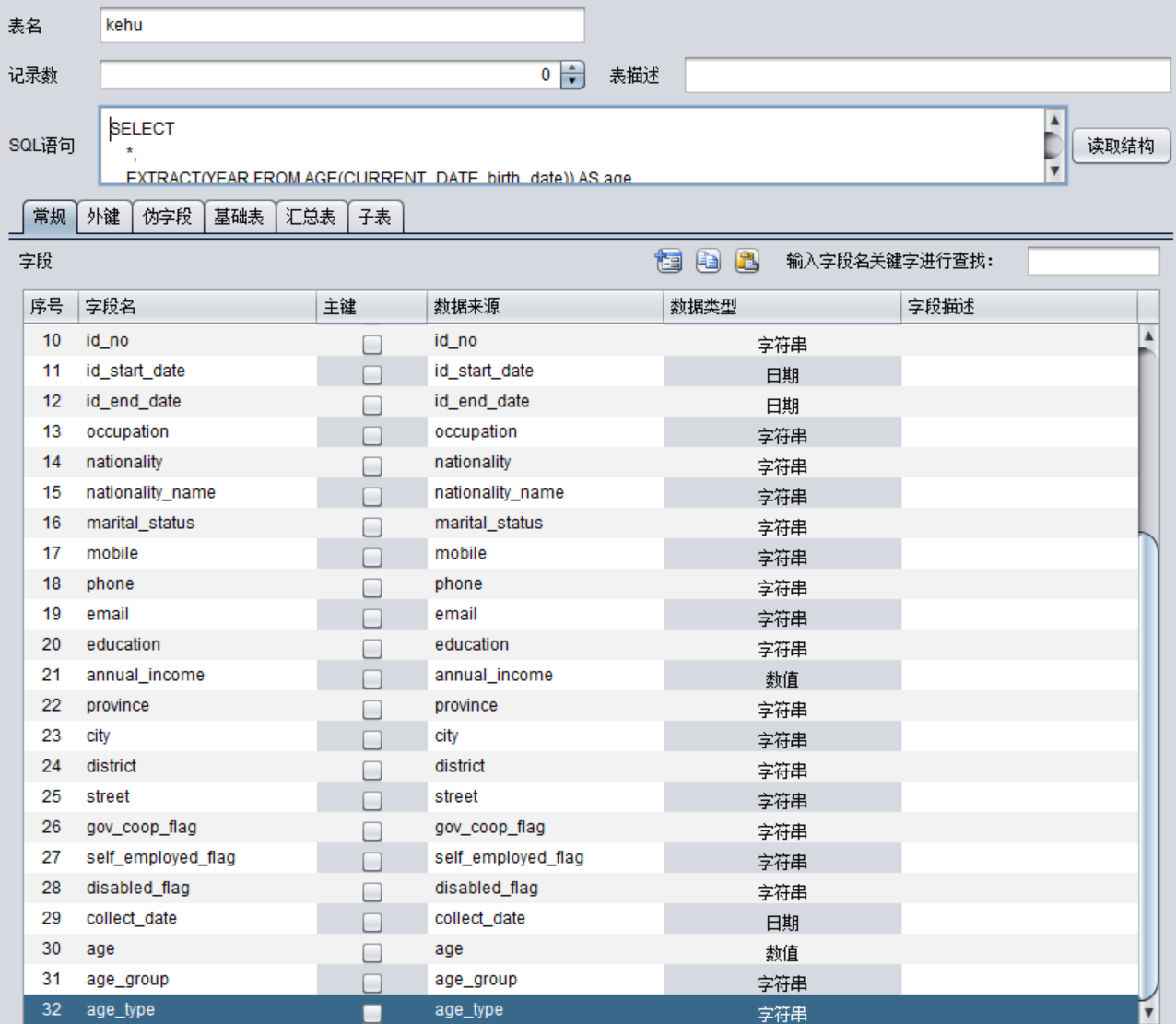
其中的SQL 语句:
SELECT *,
CASE
WHEN EXTRACT(YEAR FROM AGE(CURRENT_DATE, birth_date)) BETWEEN 0 AND 17 THEN '少儿'
WHEN EXTRACT(YEAR FROM AGE(CURRENT_DATE, birth_date)) BETWEEN 18 AND 35 THEN '青年'
WHEN EXTRACT(YEAR FROM AGE(CURRENT_DATE, birth_date)) BETWEEN 36 AND 55 THEN '中年'
ELSE '老年'
END as age_type
FROM customer
点击图中的“读取结构”按钮,系统会自动识别 SQL 结果集的字段(名称、类型等)。
读取结构后,表中有了字段age_type。
和普通字段一样,也可以为这个字段增加假表:
设置外键:
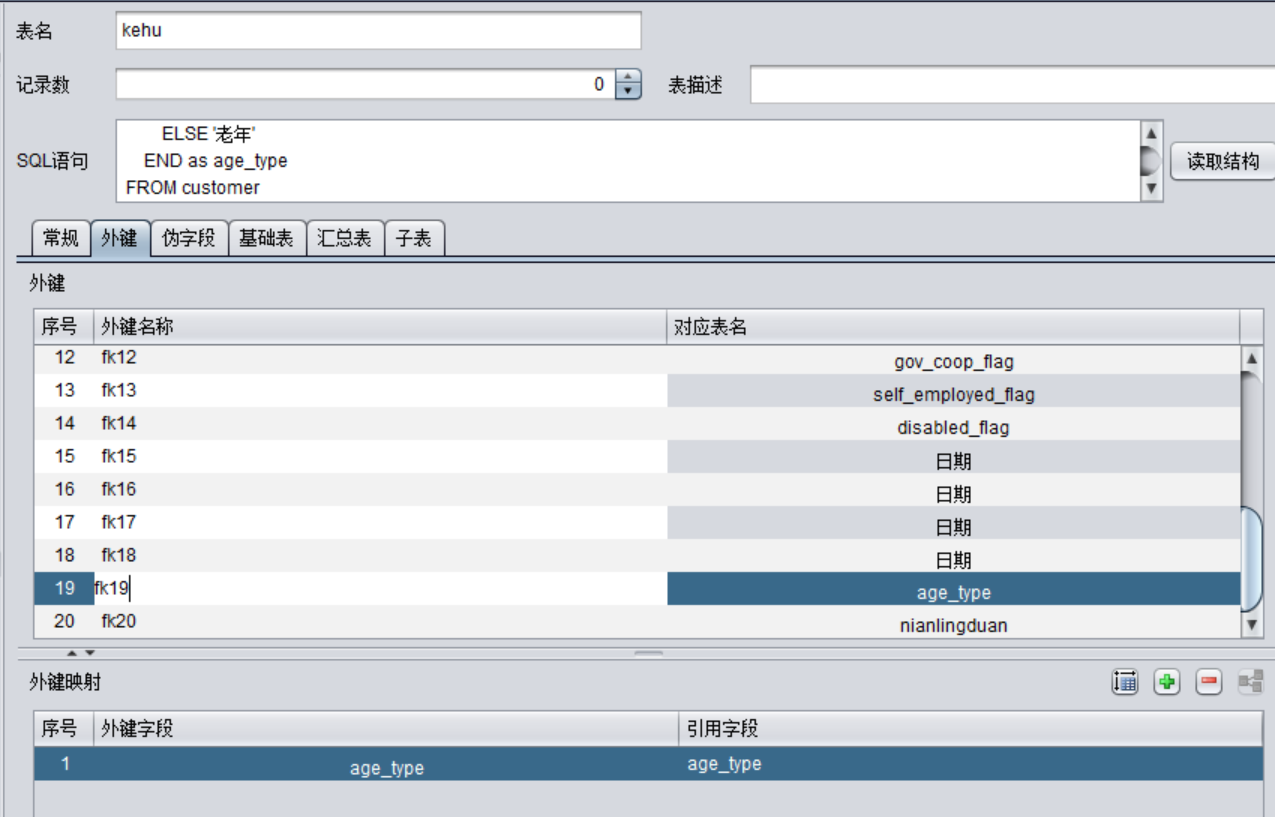
在后续建立词典等过程中,照常使用kehu 表即可。
同样的,还可以增加下面的字段、维度:
客户表- 年龄段:未成年(0-18 岁)、18-25 岁、26-30 岁...
险种定义表- 利率段:无预定利率、低利率 (<2.5%)、标准利率 (2.5%)、较高利率 (2.5%-3.0%)、高利率 (≥3.0%)
DQL元数据下载:
测试元数据
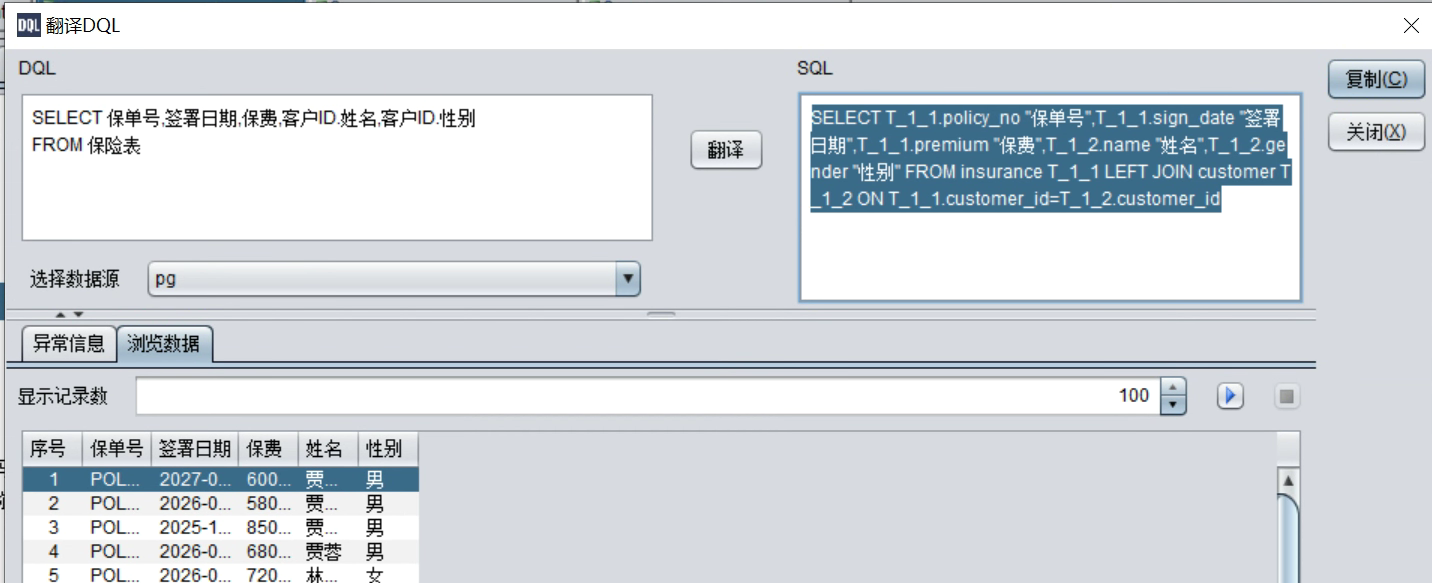
执行 DQL 测试元数据,点击菜单- 系统 - 翻译 DQL。
外键关联查询:
SELECT 保单号,签署日期,保费,客户ID.姓名,客户ID.性别 FROM 保险表
按维(层)分组汇总:
SELECT count(1) cnt,sum(保额) amt
FROM 保险表
BY 签署日期 #年月
多表按维对齐汇总:
SELECT c.count(1) 保单数,s.count(1) 险种数
ON 城市
FROM 保险表 c
BY c.投保城市
union 保险产品表 s
BY s.投保城市
2.2DQL JDBC
DQL 提供标准 JDBC,配置后方便后续词典使用。
新建目录,设置service.xml
注册DQL 服务
在DQL 的 server.xml 中添加:
<SERVICE name="insurance"/>
DQL 具备使用详见文档:https://d.raqsoft.com.cn:6443/report/dql/wdzl1.html
3NLQ 词典
词典是NLQ 的核心,本章利用LLM 辅助生成NLQ 词典。词典比较复杂,LLM 生成的时候采用了更多的分步流程,期间需要多次手动参与。
3.1元数据转成JSON
打开汉语查询 ,连接数据源
,连接数据源
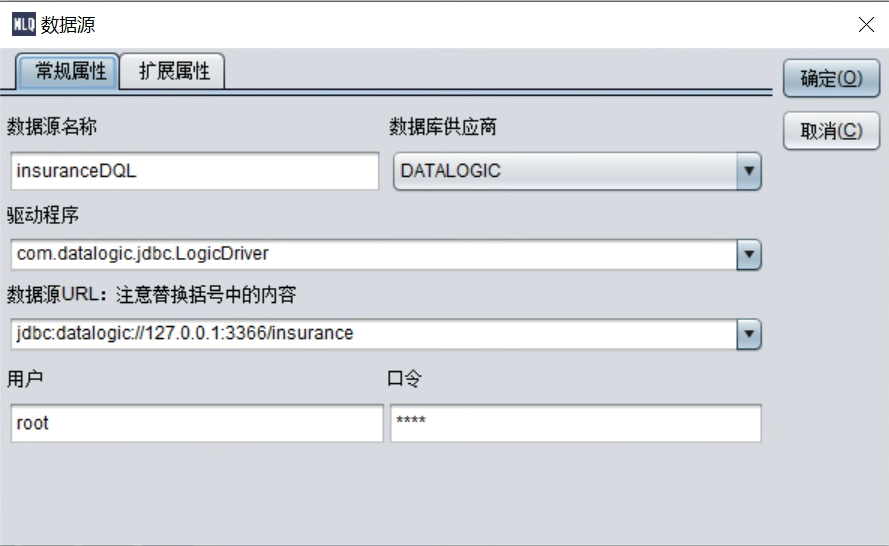
URL:
jdbc:datalogic://127.0.0.1:3366/insurance
工具- 初始数据库信息,可以获得元数据描述的数据结构、默认量纲等信息。
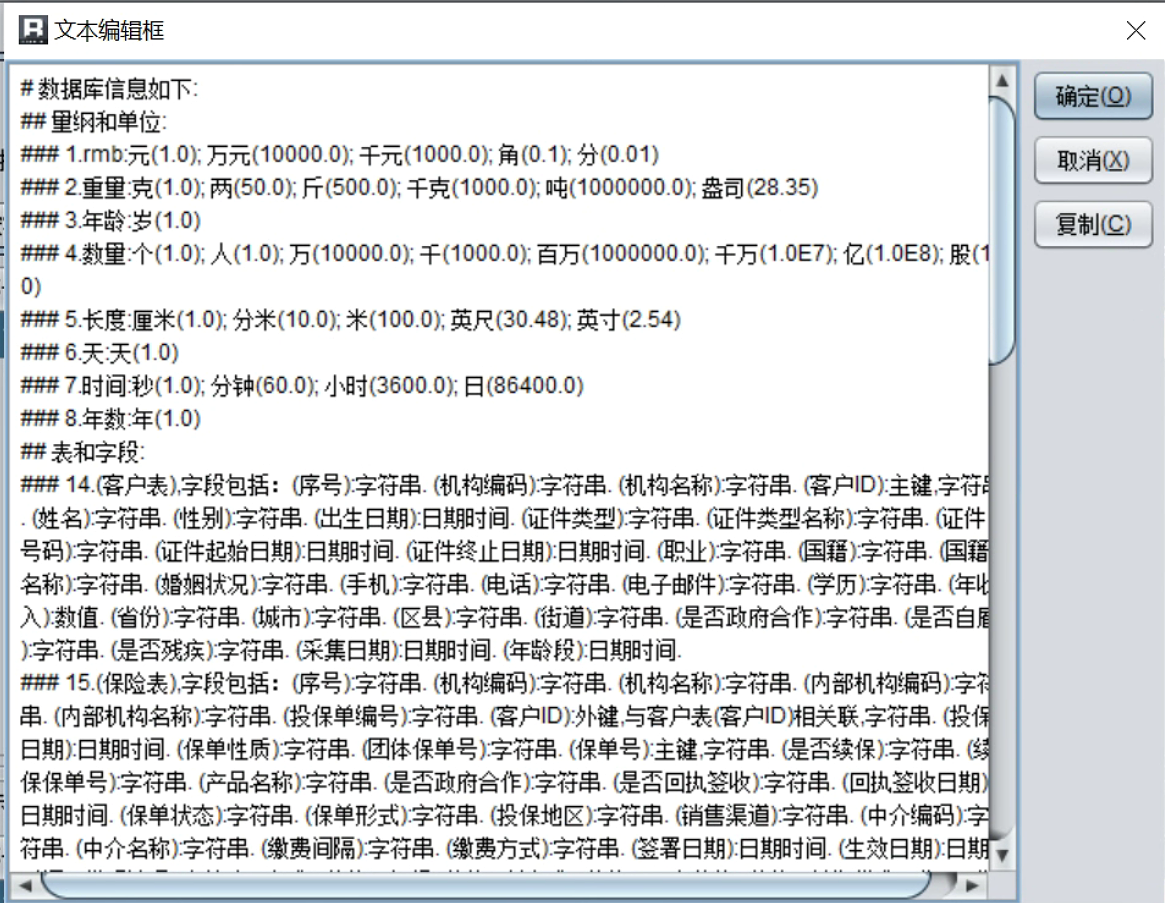
上面是数据库相关信息,每一步分析都是以此为基础的。
接下来要求LLM 完成下面的任务:
【复制上面的数据库信息放到这里】
# 上面是数据库信息描述
# 任务
- 现在以此为基础生出一份中文字典,按表的顺序排列,字典中需要的信息由下列系列任务列出,需依次执行,不能跳步。
## 任务1
- 处理表信息。数据库信息中,开头在括号中提供了表的原始名称(通常为英文),可能会有表标题(通常为中文),如果没有表标题或者表标题为英文,需要生成一个中文表标题。在表标题基础上,需要生成表可能在汉语查询中使用的别名,如员工表,别名可能是“员工、雇员、员工信息”之类,按照通用程度降序排列。各个表的别名不能重复,别名中不允许包含符号或空格。
## 任务2
- 处理表内各个字段的信息。数据库信息中,提供了字段原始名称(通常为英文),可能会有字段标题(通常为中文),如果没有字段标题或者字段标题为英文,需要生成一个中文字段标题。原始名称需要整理为包含本表的原始名,如 EMPLOYEE.NAME。在字段标题基础上,生成字段可能在汉语查询中使用的别名,列出常见同义表达,一般不超过5个,按通用程度降序排列;若实际常用别名不足,不硬凑数量。字段类型,为数值、日期时间、布尔值、字符串这4种之一。
- 查询时可能需要用到沿着一条或多条外键路径可达的任意表中的扩展字段。应遵循外键关系链,将关联对象的核心描述字段(名称、类别、日期等)以及其所在的地点信息(城市和省份,如有)作为本表的可用字段。引入的字段须按该关联在当前表中的业务角色重新拟定中文标题和别名,不得直接搬用源表字段名称(例如源自客户地址的信息在订单中应体现为“收货地”相关称谓)。字段原始名称需包含完整的关联路径(如 表A.外键B.字段X 或 表A.外键B.外键C.字段Y),并给出中文标题和别名。可用的扩展字段添加在每个表的普通字段之后,添加后,使用时与普通字段相同。
- 参考各个表的数据示例,标记字段中使用的单位。要求单位在量纲信息中,注意某一类信息中均包含多个单位,如rmb分类中,提供了“元”“万元”等多个单位。如果单位在查询习惯中经常省略,如单位是“个”,不必添加。
## 任务3
- 查询中可能根据维度汇总,如“按月……”“每个员工……”等等。数据库信息中列出了可能用到的维度,但在查询时,可能使用不同的别名,如“月”“员工”“月份”“雇员”等等。类似表的别名,也列出每个维可能使用的别名,别名允许重复。
## 任务4
- 设置表和字段的别名后,可以使用表名和别名执行汉语查询了。生成10句左右的例句,格式为“[实体] [字段列表]”,其中实体或者字段列表可省略,实体名为表的某个别名,字段列表由若干字段(包括扩展字段)的别名构成。如“员工”,“商品名称 单价 厂家”等。这种类型的查询,实体和字段列表必须在同一个表中。
- 在查询语句最前面可以添加过滤条件,格式为“字段A 条件A [字段B 条件B]……”,条件格式为“[比较符] 常数”,比较符用中文的“大于”“等于”“大于等于”等标准描述,相等的比较可以省略比较符。常数的类型需要和字段匹配,如果字段是字符串类型时常数需用双引号括起来,如:省份 “辽宁” 城市。常数为日期时,可以使用日期的分量,如:签单日期 2025年 订单号 金额。常数为数值且字段有单位时,单位不要省略。再生成10句左右带过滤条件的查询语句。过滤条件中的常数参考数据示例。
# 输出1
- 数据库信息中各个部分按原顺序保留,最前方是量纲和单位,下面是表和字段信息,最后是维度列表。即使无变化也不能省略。
- 在表和字段信息中,表名和字段名中都需要增加中文标题和别名。标题为一个词,标题后在括号内列出实际表名。别名为多个,别名中不包含标题。字段信息中,除了字段标题和字段别名外,还有可能增加单位,记为“单位:xx”。数据示例全部保留。
# 输出2
- 生成的例句,排列在一起,格式如下:
例句A1:……
例句A2:……
……
- 编号从A1至A20
将输出1 转成 JSON 格式
提示词:
【复制前面的输出1 放到这里】
# 上面是数据库信息描述
# 任务1
- 现在,请将中文词典结果用json格式返回,格式如下:
{
"tables": [
{
"tableName": "TABLENAME",
"tableChinese": "表中文名",
"tableAliases": ["表别名1","表别名2",…],
"fields": [
{
"fieldName": "TABLENAME.FIELD1",
"fieldChinese": "字段全名",
"fieldType": "字段类型",
"fieldUnit": "字段单位(如果有)",
"aliases": ["字段别名1","字段别名2",…],
"computedFormula": "字段计算式(如果有)"
},
…
],
"extendFields": [
{
"fieldName": "扩展字段全名",
"fieldType": "扩展字段类型",
"fieldUnit": "扩展字段单位(如果有)",
"fieldChinese": "扩展字段中文名",
"aliases": ["扩展字段别名1",…]
},
…
],
"fieldClusters": [
{
"clusterName": "簇名",
"fields": ["字段中文名1","字段中文名2", …],
"markFields": ["标记字段中文名1","标记字段中文名2", …]
},
…
],
"verbs": [
{
"verb": "动词1",
"leftCluster": "左簇名(如果有)",
"rightCluster": "右簇名(如果有)"
},
…
]
"clusterWords": [
{
"wordName": "簇词名",
"clusterName": "对应的簇名或外键名",
},
…
],
"indices": [
{
"indexName": "指标名",
"clusterName": "对应字段簇(如果有)",
"dims": ["固有维度1",…](如果有),
"function": "函数表达式"
},
…
],
},
…
],
"dimensions": [
{
"dimName": "维名",
"dimAliases": ["维别名1","维别名2",…],
"auto": true,
"dimKey": 维对应表主键(如果有),
"dimNameField": 维对应值(如果有)
},
…
],
}
其中维名是维的源名称,即最开始在括号里的名称。
3.2生成不完全词典文件
在IDE菜单中新建词典,生成方式选择加载JSON,粘贴前面得到的json文字(也可以选择打开json文件),分析后可以生成新的词典文件。
此时,目前设置的字段名称和别名,已经在词典中生成:
3.3手动调整词典内容
上面的步骤完成后,词典内容需要仔细校验。发现问题需要手动修改,可能会存在:
1.词名称不准确,需要修改(如:维词 客户ID->客户)
2.带条件的实体需要自行添加
所有检查和调整完成后我们得到了一个初步的NLQ 词典,这时可以使用第一步中生成的例句进行查询了。
3.4字段簇分析
在IDE的菜单中选择“工具->重新获取数据库信息”,此时获得的信息是在上一步调整好的nlq文件基础上,综合当前连接数据库的信息得到的。注意:在已有nlq文件的基础上继续分析时,本流程以外自行添加的属性、设置等可能丢失,如带过滤的实体,已有字段簇的主键等信息。
在数据库信息之后,说明字段簇分析任务,LLM 提示词如下:
# 上面是数据库信息描述
# 任务
- 现在以此为基础整理各个表中的字段组合,按表的顺序排列,需要的信息由下列系列任务列出,需依次执行,不能跳步。
## 任务1
- 表内可能使用的字段组合,称为“字段簇”。包括:组合名称,组合内包含哪些字段,这里的字段用字段标题表示,字段簇中的字段可以是表的基本字段,也可以是已定义的外键表字段。字段组合能够比较完整地表现一个信息,如“发货”字段簇,可能包含“发货日期,发货城市,发货城市名称,发货省”。同一个字段可能出现在多个字段簇中,字段簇中的字段数一般多于1个。字段簇中不允许包含“同类”字段即使用同一个维度的字段,如不能包含两个日期类字段,也不能包含两个城市编码字段等。
- 每个字段簇从其中的字段列表中,选择至少一个设为“标记字段”。标记字段中应该包含字段簇中使用的主键类字段,也可以包括其它代表字段簇最核心信息的字段。如“发货”字段簇中的标记字段可以选择“发货日期,发货城市”。
## 任务2
- 每个表需要一个默认的字段簇,其中包含表中最关键的字段作为“标记字段”,标记字段中要包含主键。另外,默认字段簇中还要包括一些有可能在查询中不指定字段名,而直接查询的字段。如,“2025年 订单”,这就需要订单的默认字段簇中包含一个能对应日期的字段,对于订单而言这通常会是“签单日期”,又如“河北省 员工”,这就需要员工的默认字段簇中,包含对应“省份”的字段。默认字段簇位于字段簇列表的最前方,名称与其它字段簇保持一致。字段簇本身的命名要简洁明确。
## 任务3
- 设置默认字段簇后,可以在汉语查询中基于默认字段簇中的字段使用过滤条件,过滤条件中不必指明对应字段。生成15句左右这样的例句,格式为“条件A [条件B]……[实体] [字段列表]”。其中实体或者字段列表可省略,实体名为表的某个别名,字段列表由若干字段的别名构成。条件格式为“[比较符] 常数”,比较符用中文的“大于”“等于”“大于等于”等标准描述,相等的比较可以省略比较符。常数的类型需要和默认字段簇中的某一个或多个字段匹配,如果字段是字符串类型但在维度中使用,则不必加引号,如:辽宁 客户。常数为日期时,可以使用日期的分量,如:2025年 订单号 金额。常数为数值且字段有单位时,单位不要省略。这种类型的查询,实体和字段列表必须在同一个表中。过滤条件中的常数参考数据示例。
# 输出1
- 数据库信息修改后的结果,数据库信息中各个部分按原顺序保留,最前方是量纲和单位,下面是表和字段信息,最后是维度列表。
- 在表和字段信息中,表的字段描述和数据示例之间增加可用的字段簇,其中默认字段簇在最前面。数据示例全部保留。数据示例全部保留。
# 输出2
- 生成的例句,排列在一起,格式如下:
例句B1:……
例句B2:……
……
- 编号从B1至B15
得到的结果可以再按前面的步骤转换成JSON 后重新生成词典文件进行调整。接下来都是这样的过程,重复内容不再赘述。
3.5动词分析
生成动词,可以在上一步的词典基础上“重新获取数据库信息”,也可以直接使用“字段簇分析”的输出 1 结果。在数据库信息之后,说明动词分析任务,提示词:
# 上面是数据库信息描述
# 任务
- 现在以此为基础整理各个表中的字段组合,按表的顺序排列,需要的信息由下列系列任务列出,需依次执行,不能跳步。
## 任务1
- 查询时,过滤条件中可能用一些动词表示条件对应的字段组合,在字段组合后面列出可能使用的动词。动词信息包括动词名称,以及左侧和右侧对应的字段簇。
- 左右簇的语序对应规则:定义动词时,必须确保左右字段簇与自然查询语句中的条件位置一致——查询语句中置于动词之前的条件,其对应字段必须属于左簇;置于动词之后的条件,其对应字段必须属于右簇。左簇或右簇可以为空,表示动词仅单侧接受条件。设定左右簇前,应先构思典型的查询句式,确认动词在句中的位置符合汉语表达习惯,再据此分配字段簇方向。
- 动词形式规则:动词必须是完整的独立词形,不允许包含省略号、破折号等任何占位符,不允许使用依赖前后嵌词才能表意的关联结构(如“由…发起”)。
- 动词可能有多个名称,如“发往”“发给”“发到”等,动词的多个名称之间用半角逗号隔开。
- 一个字段簇可能与多个动词匹配。动词关联到某个字段簇时,常常相当于对应多个字段,在查询时不一定多个字段的过滤条件同时使用,可以使用部分条件,也可能查询条件中只包含单侧的字段簇。动词关联到的字段簇,簇中的各个字段都是有可能在查询时涉及的。如果某种条件既可能出现在动词左侧,又可能出现在动词右侧,这种情况动词的左簇和右簇可以相同。
***禁止情形***
- 动词不能仅表示单纯的字段值比较,如不能包含“字段名+比较词”的语义(例如“金额大于”“籍贯是”)。动词应表达一种有动作逻辑的关系,而非直接映射字段筛选。
- 动词不能使用“之前”“之后”这类不承载明确动作含义的时间介词。
- 同一个表中,动词不能重复,也不能和字段的标题或别名重复。
## 任务2
- 设置动词后,可以在汉语查询的过滤条件中使用动词,通过动词关联的字段簇寻找对应字段。生成15句左右使用动词过滤的例句,格式为:
[条件左A] [条件左B]…… 动词 [条件右A] [条件右B] …… [实体] [字段列表]
- 其中实体或者字段列表可省略,实体名为表的某个别名,字段列表由若干字段的别名构成。
- 条件格式为 [比较符] 常数,比较符用中文的“大于”“等于”“大于等于”等标准描述,相等的比较可以省略比较符。常数的类型需要和默认字段簇中的某一个或多个字段匹配。常数的位置必须严格按动词左右簇的语序放置,不可颠倒。
- 常数为日期时,可以使用日期的分量,如:1990年5月 之前 出生 员工。常数为数值且字段有单位时,单位不要省略。
- 过滤条件中的常数参考数据示例。实体和字段列表必须在同一个表中。
# 输出1
- 数据库信息修改后的结果,数据库信息中各个部分按原顺序保留,最前方是量纲和单位,下面是表和字段信息,最后是维度列表。
- 在表和字段信息中,字段簇描述和数据示例之间增加可用的动词。数据示例全部保留。数据示例全部保留。
# 输出2
- 生成的例句,排列在一起,格式如下:
例句C1:……
例句C2:……
……
- 编号从C1至C15
生成JSON 并导入词典,或者直接进行下面的分析。
3.6簇词处理
簇词分析提示词:
# 上面是数据库信息描述
# 任务
- 现在以此为基础整理各个表中的字段组合,按表的顺序排列,需要的信息由下列系列任务列出,需依次执行,不能跳步。
## 任务1
- 字段组合可用于查询简化,这种组合称为“簇词”。簇词对应一个字段簇或一个外键字段,用于在查询中分组引用或消歧。
- 簇词命名规则:簇词名称不得与任何表名、表别名、维度名重复。
- 簇词别名:簇词在查询中可以使用不同的名称,如簇词“上级”可以用“经理、领导、主管”等。别名不得与表名或表别名、维度名重复。
- 簇词定义规则(基于查询消歧需求):
簇词仅在查询需同时引用多个同名字段,且这些字段的别名存在冲突或易混淆时才需定义。冲突来源包括:表自身字段与外键关联字段同名,或表中不同分组的字段同名。
对于外键关联字段:若其引用字段的常用别名与当前表自身字段别名冲突,或查询习惯中经常需要同时引用并加以区分,则应定义簇词;否则可不定义。
对于表内字段:若不同字段簇包含相同别名,且查询中可能需要同时使用这些分组,则需为相应字段簇定义簇词;若各字段别名全局唯一可直接确定,则无需定义簇词。
## 任务2
- 生成10句左右使用簇词的例句,格式为:
[实体] [实体字段列表] [簇词1] [簇词1内字段列表] [实体字段列表] [簇词2] [簇词2内字段列表] ……
- 其中实体或者字段列表可省略,实体名为表的某个别名,字段列表由若干字段的别名构成。
# 输出1
- 数据库信息修改后的结果,数据库信息中各个部分按原顺序保留,最前方是量纲和单位,下面是表和字段信息,最后是维度列表。
- 在表和字段信息中,动词描述和数据示例之间增加可用的簇词。数据示例全部保留。
# 输出2
- 生成的例句,排列在一起,格式如下:
例句D1:……
例句D2:……
……
- 编号从D1至D10
将输出结果转成JSON 后生成词典。
以上步骤都完成后我们就得到了一个完整的NLQ 词典。由于 LLM 的幻觉问题,建议每步生成词典检查,再基于调整后的词典进行下一步工作。
注意:带条件的实体建议在最终调整完的词典基础上手动添加。
3.7指标
为了更方便数据计算,可以实现定义计算指标,然后在查询时直接使用指标词。指标需要手工配置,分为一般指标和复杂指标。比如经常要按年计算保额,就可以在指标中定义一个“yearMoney”。
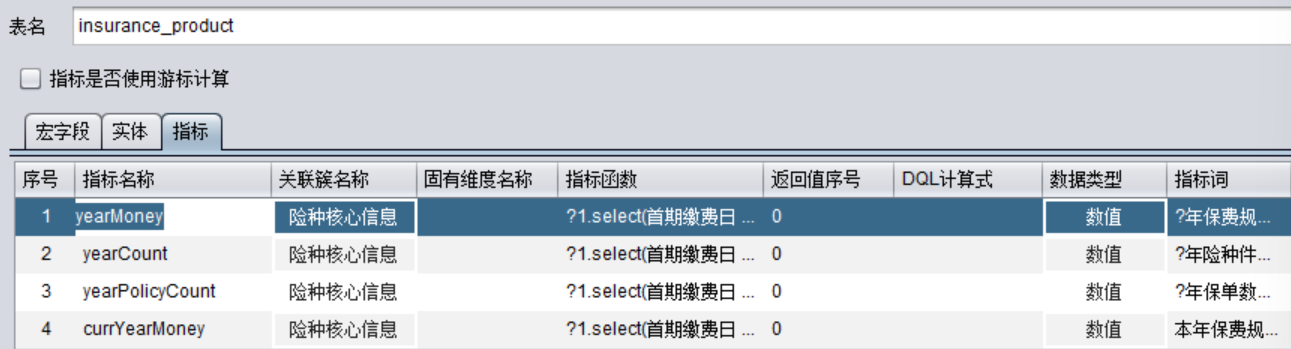
指标函数是:
?1.select(首期缴费日 <= date(y=?2,12,31)
&& (末期缴费日 == null || 末期缴费日 > date(y,1,1))
&& (险种中止日期 == null || 险种中止日期 >date(y,1,1))
&& ["有效","中止"].pos(保险险种状态)).sum(if(缴费频率 = "年交", 当期保费,
if(缴费频率 = "月交", 当期保费 * 12,
if(缴费频率 = "季交", 当期保费 * 4,
if(缴费频率 = "半年交", 当期保费 * 2,
if(缴费频率 = "趸交", 0, 当期保费))))))
设置指标词:
? 年保费规模,? 保费规模
词典文件下载:
3.8查询实验
在词典编辑器中,工具- 查询实验,下面来验证大模型辅助生成的词典。
点击“搜索”,可以看到搜索结果:
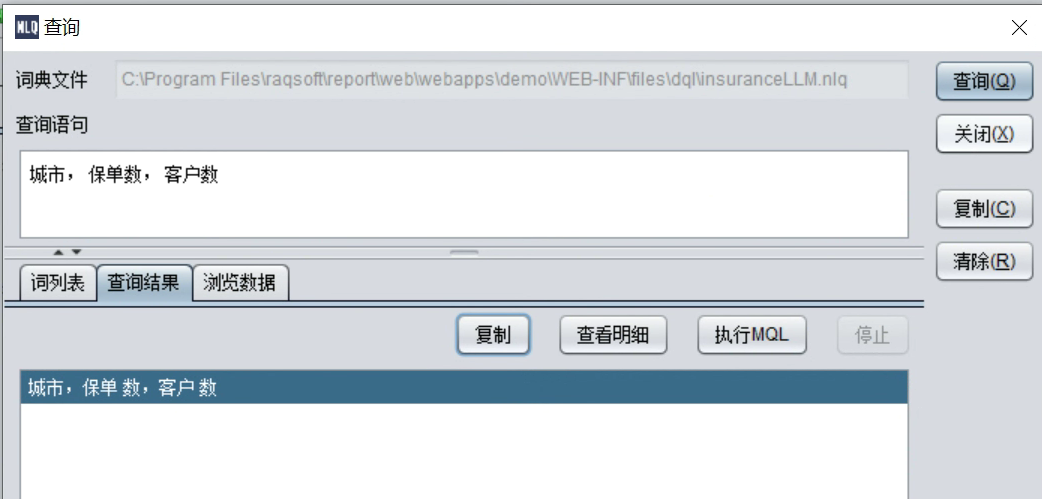
点击“浏览数据”可以看到查询结果集。
在“搜索结果”选项卡下,点击“查看明细”,可以看到具体的详细信息(JSON 格式)。
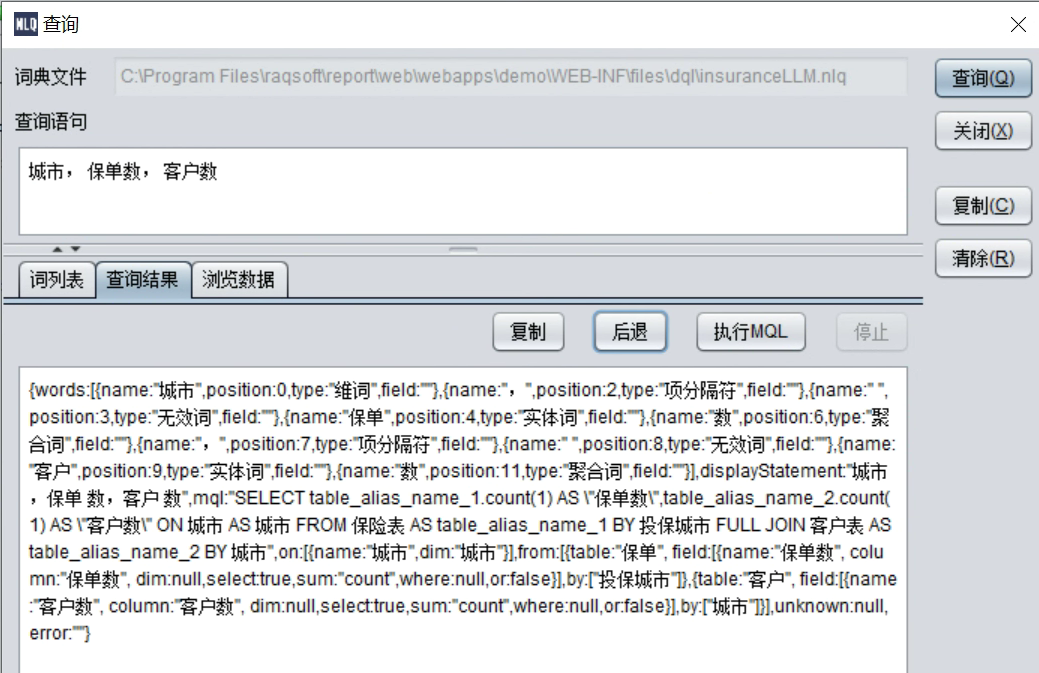
把这个结果结构化一下来看:
{
"words": [
{ "name": "城市", "position": 0, "type": "维词", "field": "" },
{ "name": ",", "position": 2, "type": "项分隔符", "field": "" },
{ "name": " ", "position": 3, "type": "无效词", "field": "" },
{ "name": "保单", "position": 4, "type": "实体词", "field": "" },
{ "name": "数", "position": 6, "type": "聚合词", "field": "" },
{ "name": ",", "position": 7, "type": "项分隔符", "field": "" },
{ "name": " ", "position": 8, "type": "无效词", "field": "" },
{ "name": "客户", "position": 9, "type": "实体词", "field": "" },
{ "name": "数", "position": 11, "type": "聚合词", "field": "" }
],
"displayStatement": "城市,保单 数,客户 数",
"mql": "SELECT table_alias_name_1.count(1) AS \"保单数\",table_alias_name_2.count(1) AS \"客户数\" ON 城市 AS 城市 FROM 保险表 AS table_alias_name_1 BY 投保城市 FULL JOIN 客户表 AS table_alias_name_2 BY 城市",
"on": [
{ "name": "城市", "dim": "城市" }
],
"from": [
{
"table": "保单",
"field": [
{ "name": "保单数", "column": "保单数", "dim": null, "select": true, "sum": "count", "where": null, "or": false }
],
"by": ["投保城市"]
},
{
"table": "客户",
"field": [
{ "name": "客户数", "column": "客户数", "dim": null, "select": true, "sum": "count", "where": null, "or": false }
],
"by": ["城市"]
}
],
"unknown": null,
"error": ""
}
下面解析一下这个JSON 串的含义:
words列出了汉语查询中各个词的分析结果,包括词名称、位置、类型等,比如。
displayStatement中列出了查询语句中与显示字段相关的各个词。
mql为分析后,需要在汉语查询中执行的mql语句,mql语句将在执行时将转换为dql语句并发送到DQL服务器执行查询。
on为表间关联查询时的对齐关系中的字段名和维名。
from列出了查询中涉及的各个子句表。其中table为表名,field为表中各个字段的信息,by为表需要分组统计时的维或者字段。字段信息中,name为字段名,dim为字段关联的维,select为字段是否选出,sum为计算时字段的聚合处理方式,where为字段相关的过滤条件。
unknown为无法识别的词,可能是无效词或者字符串型常数等。
error为没有结果时的错误信息。
实体
基本保额大于10000 的个人险种详情
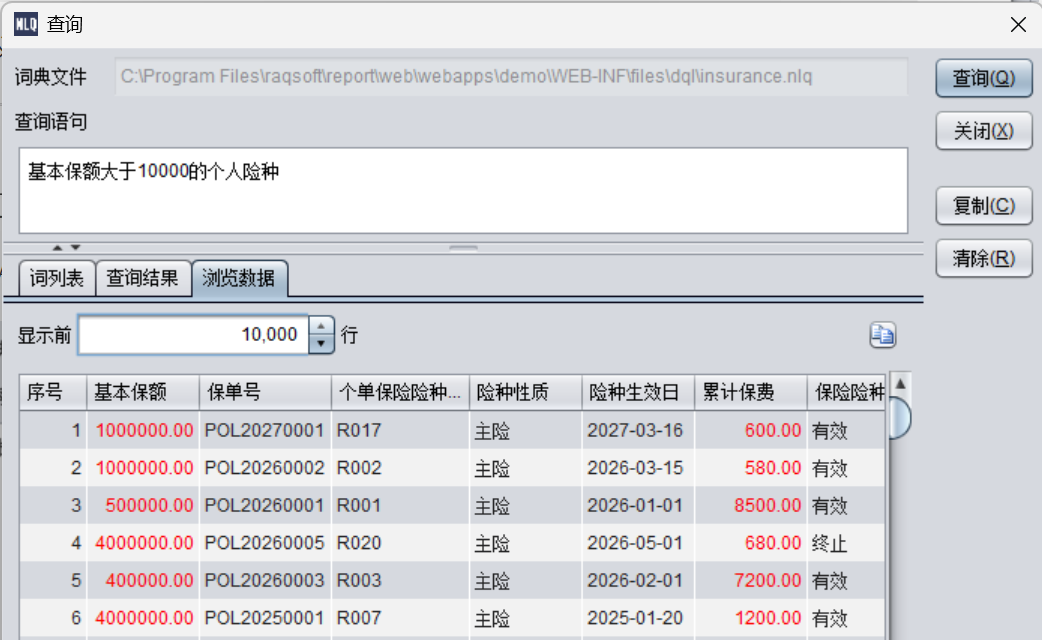
就会把个人险种的所有相关信息(实体中设置的显示列)都列出,而不必写上多个字段词了。
量纲
对于“账户余额超过4000 的客户”的查询,实际查询时经常会会指定单位,比如:
账户余额超过400万元的客户
常数词
北京的客户
不需要指定参数对应的字段“地址所在省”,“北京”作为常数词会自动关联到“省”维度进行过滤,从而实现更自然更口语化的查询方式。
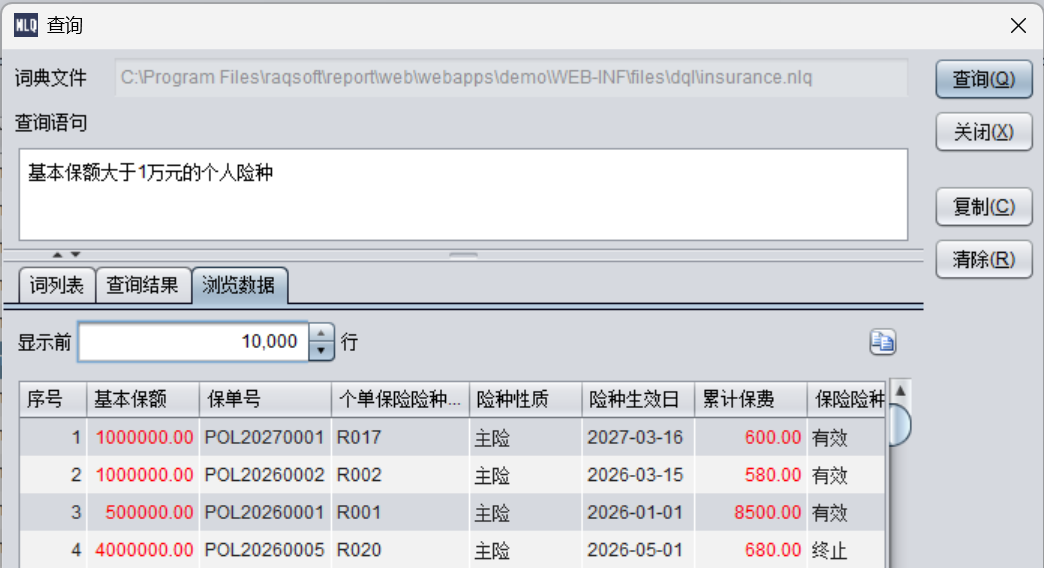
维词
不同国家的客户数和供应商数
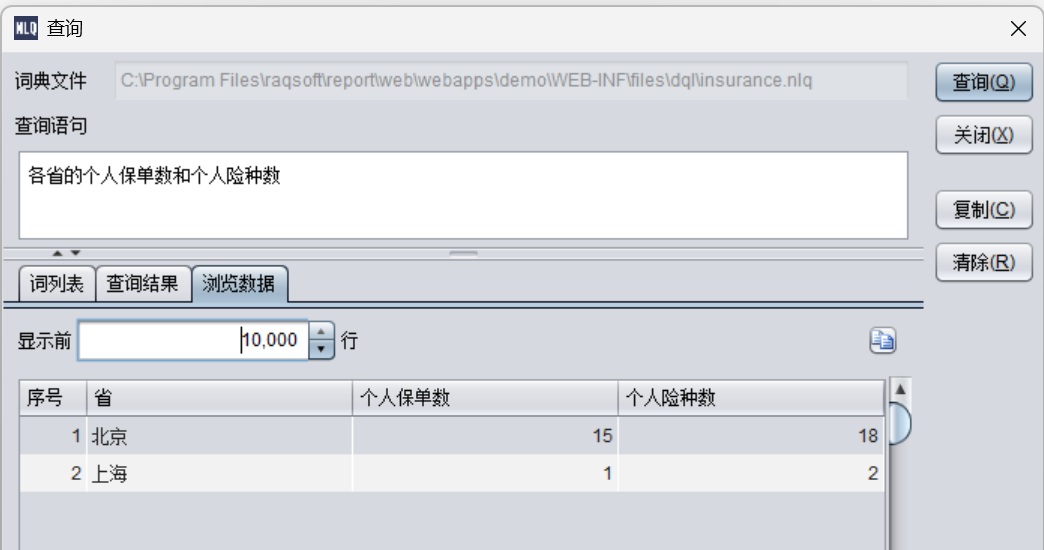
可以看到执行的MQL:
SELECT table_alias_name_1.COUNT(DISTINCT 保单号) AS "个人保单数",
table_alias_name_1.count(1) AS "个人险种数"
ON province AS 省
FROM insurance_product AS table_alias_name_1
BY 保单承保机构所在省
跨两个表按照“省”维度进行对齐汇总,有了维度以后就可以轻松完成这类基于相同维度的汇总计算了。
按年汇总 订单金额 订购数量
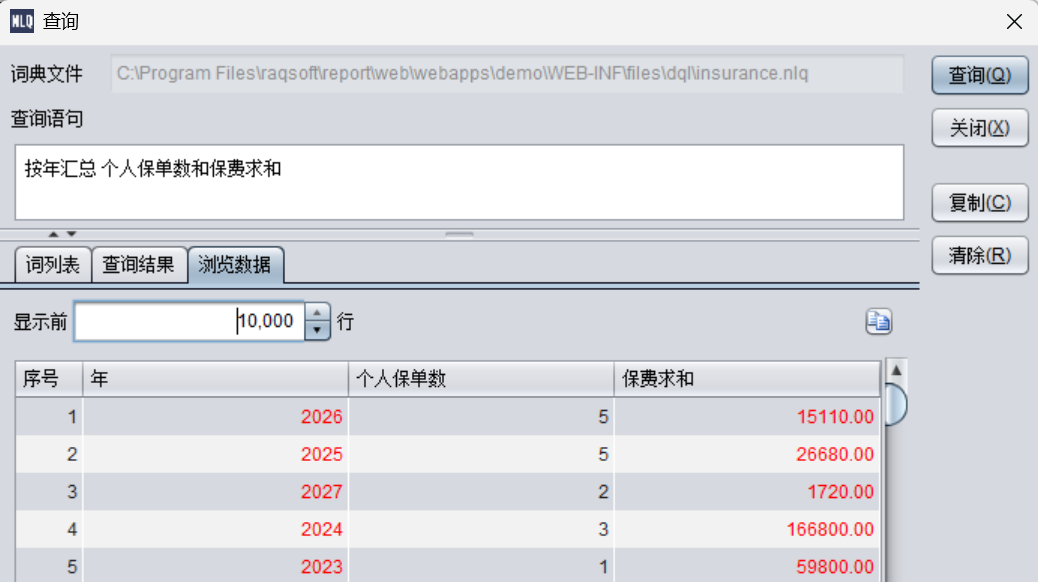
生成的MQL:
SELECT table_alias_name_1.count(1) AS \"个人保单数 \",table_alias_name_1.sum(保费) AS \"保费求和 \" ON 年 AS 年 FROM insurance AS table_alias_name_1 BY 投保日期 #年
可以看到,自动按“投保日期”的“年”层次进行分组汇总了。
签单日期是去年的订单
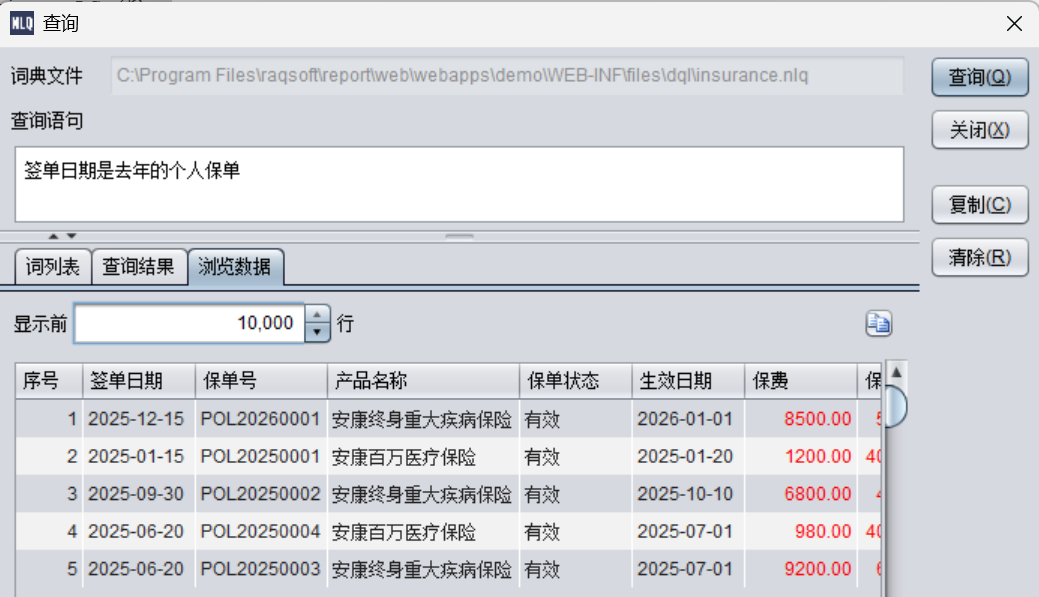
可以看到生成的MQL 语句按照宏词“去年”过滤了数据。
SELECT 签单日期 AS \"签单日期 \", 保单号, 产品名称, 保单状态, 生效日期, 保费, 保额, 累计保费, 客户姓名 FROM insurance WHERE (签单日期 #年 =2025)
还可以做聚合上的条件查询,比如:
(签单日期是去年个人保单数) (签单日期是今年个人保单数)
按客户统计 (去年个人保单数) (今年个人保单数)
继续查询检查
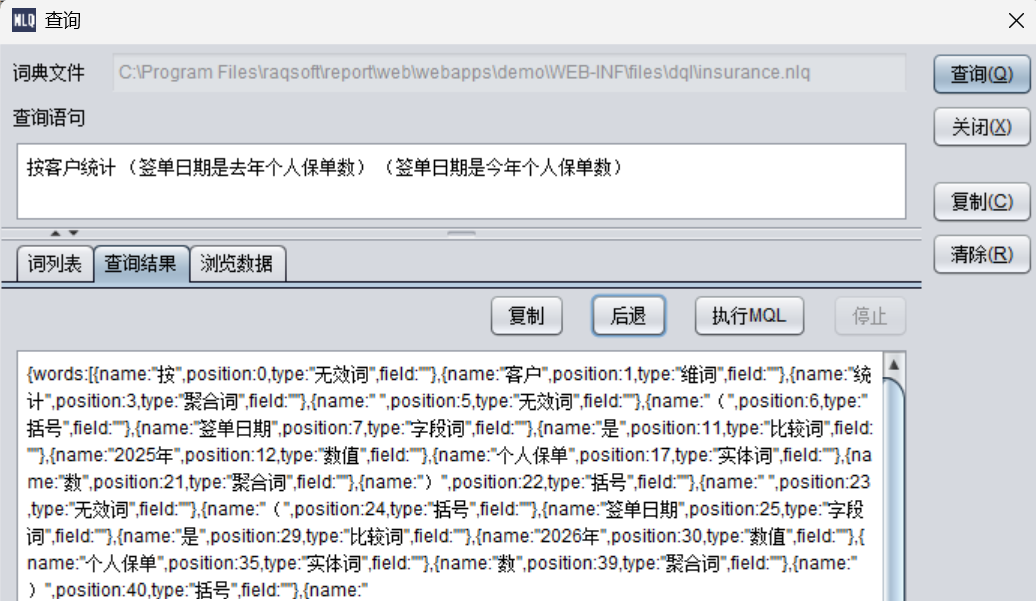
生成的MQL:
SELECT table_alias_name_1.count(1) AS \"签单日期是 2025 年个人保单数 \",table_alias_name_2.count(1) AS \"签单日期是 2026 年个人保单数 \" ON kehu AS 客户 FROM insurance AS table_alias_name_1 WHERE (签单日期 #年 =2025) BY 客户编号 FULL JOIN insurance AS table_alias_name_2 WHERE (签单日期 #年 =2026) BY 客户编号
宏词
签单日期在秋天的个人保单数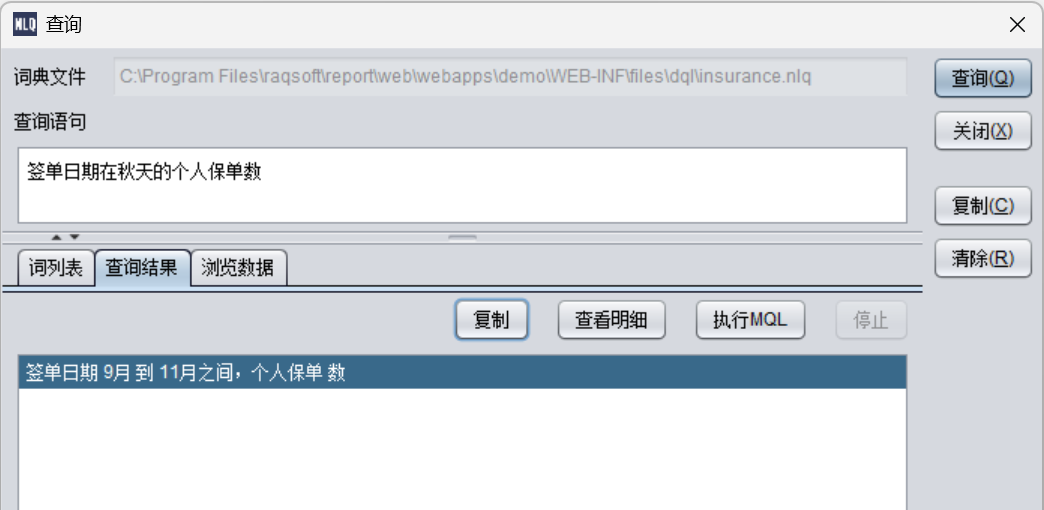
查看MQL:
SELECT table_alias_name_1.count(1) AS \"个人保单数 \" FROM insurance AS table_alias_name_1 WHERE ((签单日期 #月 >=9) AND (签单日期 #月 <=11))
有时我们输入的条件不像上面“上半年”“秋天”这种固定形式而,而是“N 年前”“N 个工作日后”这样的动态条件。比如要查询:
签单日期在3 年前的个人保单
需要通过动态宏词来实现,在词典的宏词列表中增加动态宏词(勾选动态宏)。
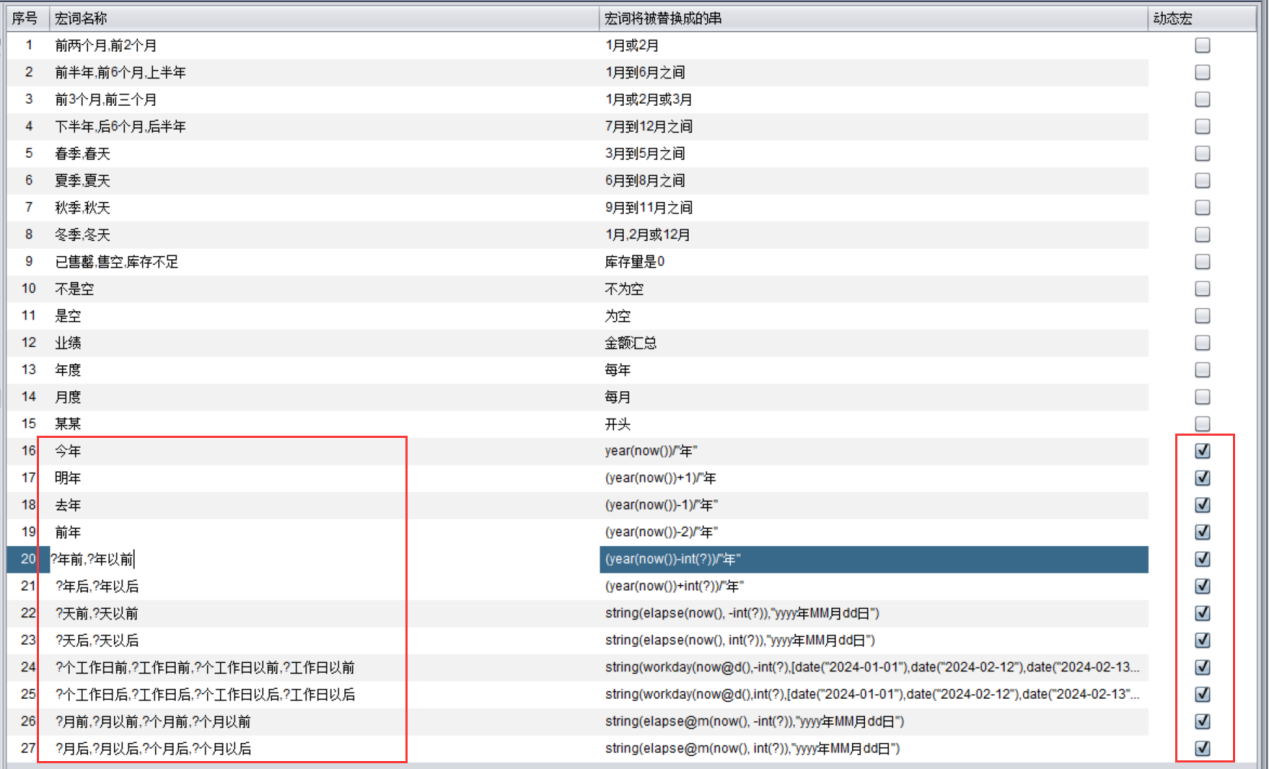
来做查询:
签单日期在3 年前的个人保单
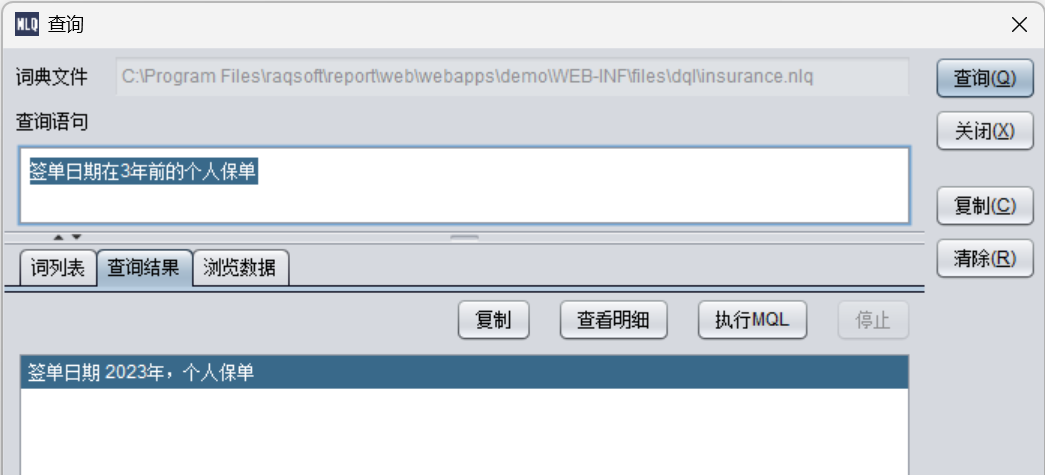
日期自动计算到3年前的2023年,MQL:
SELECT 签单日期 AS \"签单日期 \", 保单号, 产品名称, 保单状态, 生效日期, 保费, 保额, 累计保费, 客户姓名 FROM insurance WHERE (签单日期 #年 =2023)
字段簇
3年前的个人保单
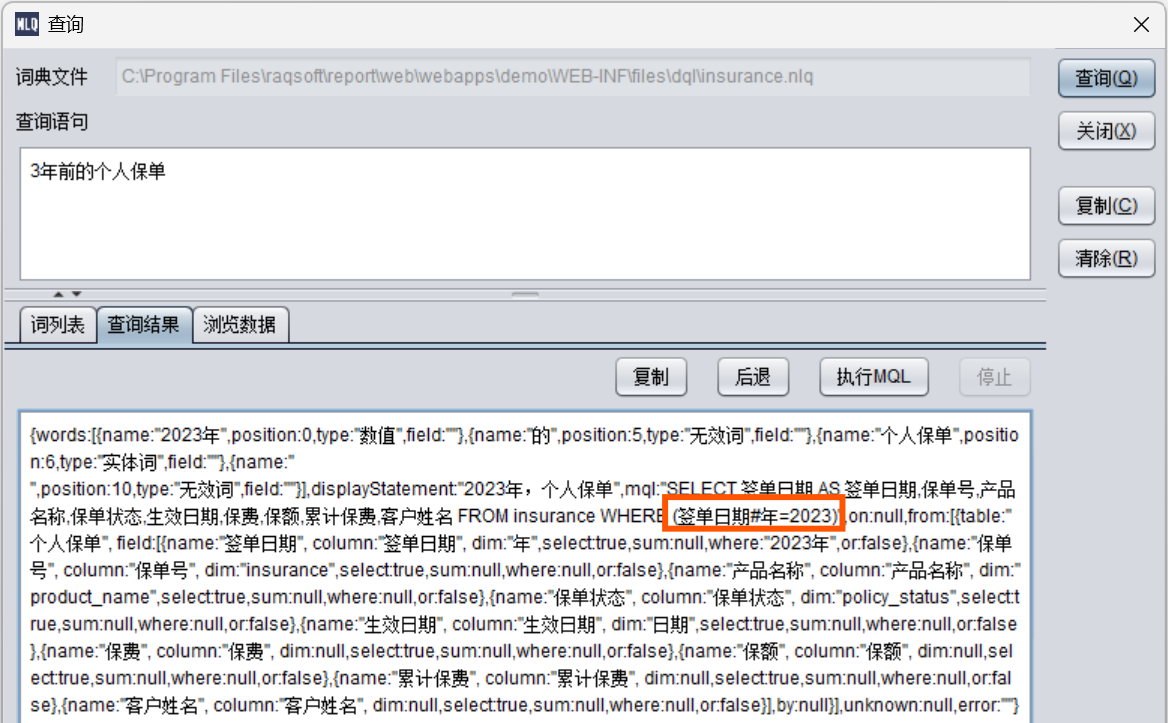
日期参数自动与字段簇中类型相同的签单日期字段对应完成查询。
类似的,可以定义更多字段簇来表示不同业务概念:
产品定义、个人保单、客户、个人险种等。
簇词、外键簇词
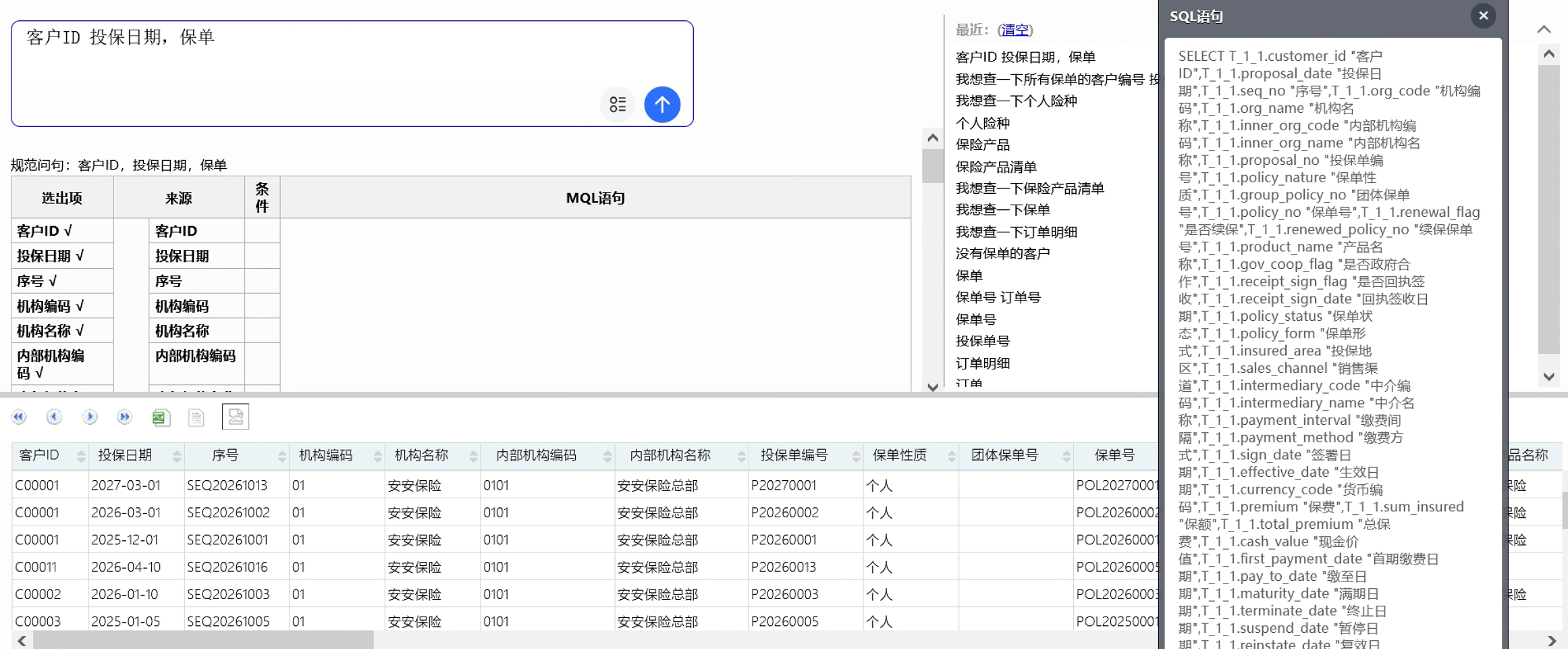
保单号 签单日期 保费 客户编号 客户姓名 客户电话
在引用外键表字段时先指定外键(字段)名称。
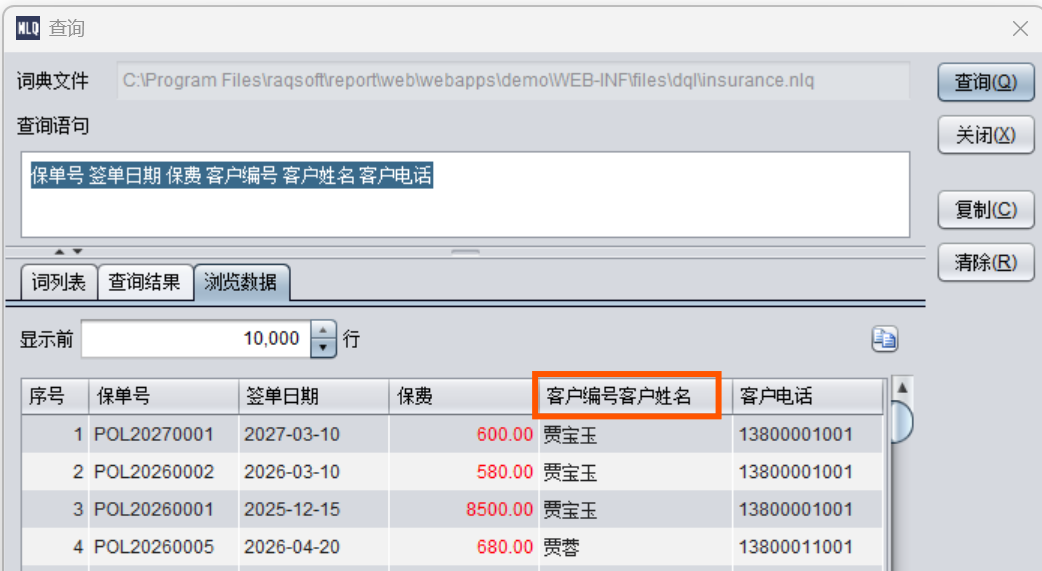
结果出来了,但是发现结果集列名很怪,用了外键名+ 字段名来命名。所以我们在词典设计时可以把外键字段词改成简短的名称,比如“客户”。
同理,客户表的字段词也不必加上“客户”了。
再做查询实验:
保单号 签单日期 保费 客户 姓名 电话
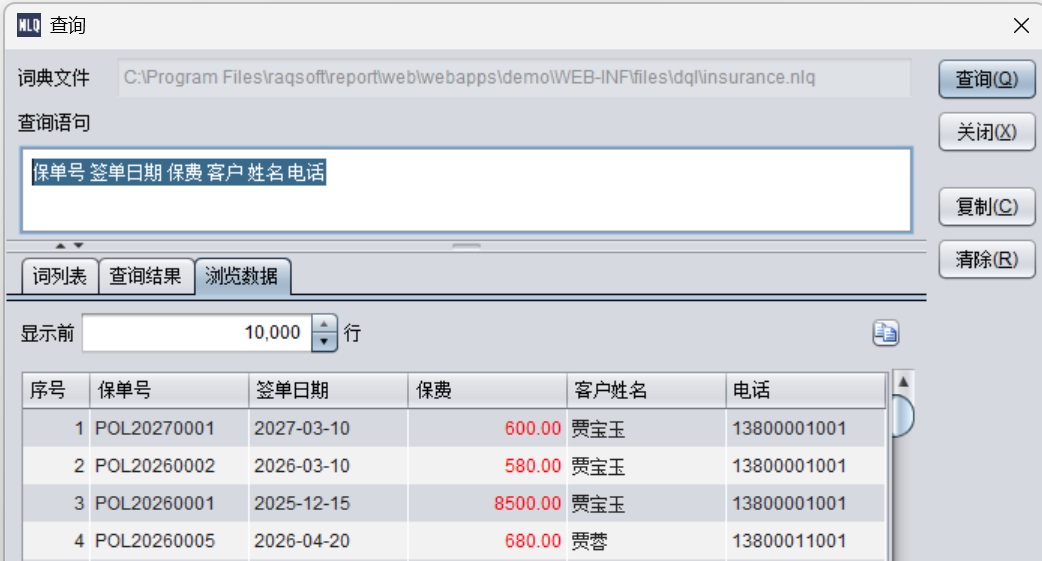
这个结果集列名就很正常了。
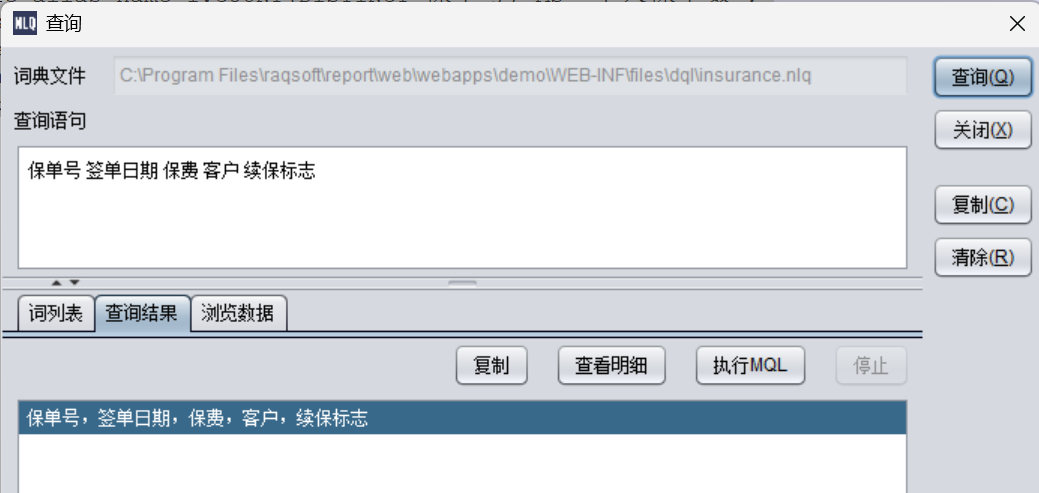
我们也可以通过簇词和外键簇词完成相同的目标,查询:
查询:
保单号 签单日期 保费 客户 续保标志
存在词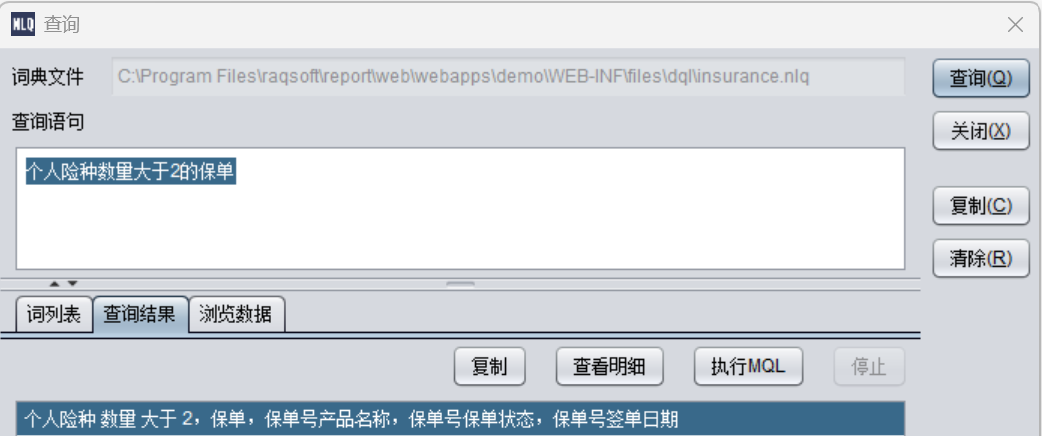
生成的MQL 语句:
SELECT \"保单 \".product_name AS \"保单号产品名称 \",\"保单 \".policy_status AS \"保单号保单状态 \",\"保单 \".sign_date AS \"保单号签单日期 \",table_alias_name_1.count(1) AS \"个人险种数量 \" ON insurance AS \"保单 \" FROM insurance_product AS table_alias_name_1 BY 保单号 HAVING table_alias_name_1.count(1)>2
可以看到已经比较复杂了。
比较随意的口语化查询有时还可能直接问“有没有”,比如:
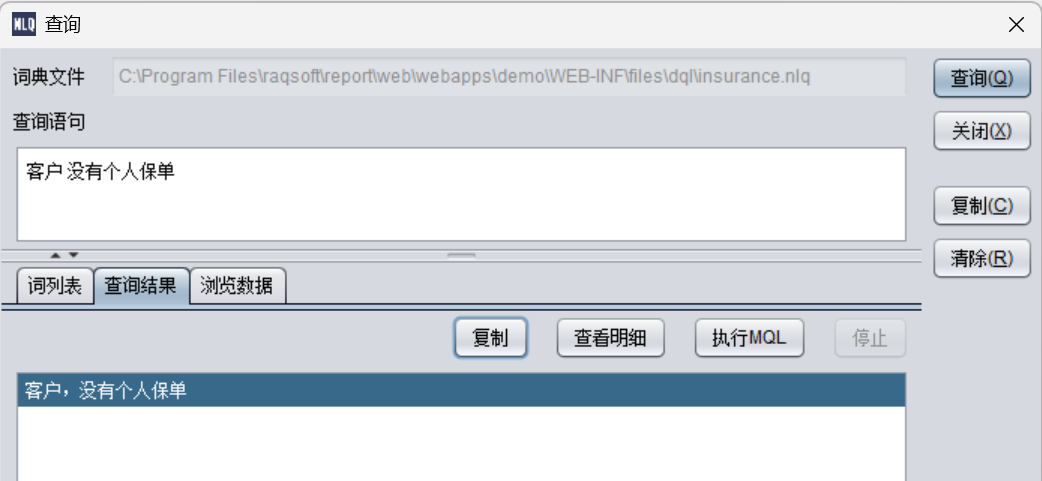
客户 没有个人保单
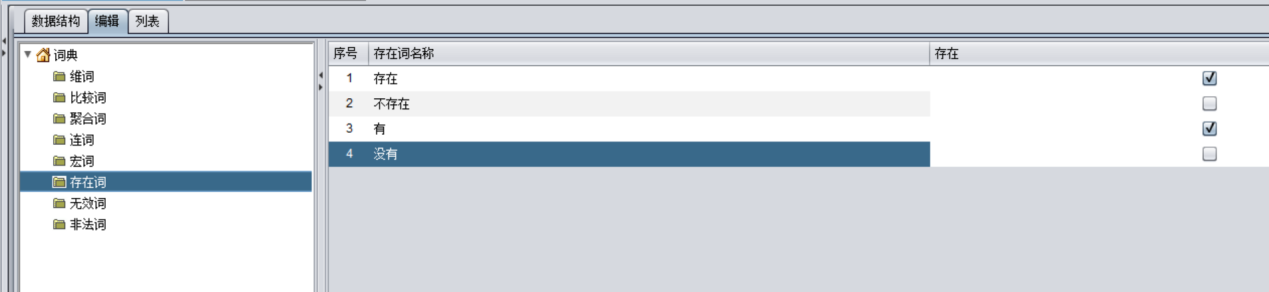
这种判断是否存在的查询可以通过设置存在词来完成。在新建词典时会给出默认的存在词列表。
这样我们再查询时:
生成的MQL:
SELECT 客户姓名, 性别, 出生日期, 证件类型名称, 证件号码, 地址所在省, 地址所在地市, 地址所在区县 ON kehu AS 客户编号 FROM kehu BY 客户编号 LEFT JOIN insurance AS table_alias_name_1 BY 客户编号 HAVING (table_alias_name_1.count(1) is null)
关联多个表同时将存在词转换成HAVING 后的条件。
动词
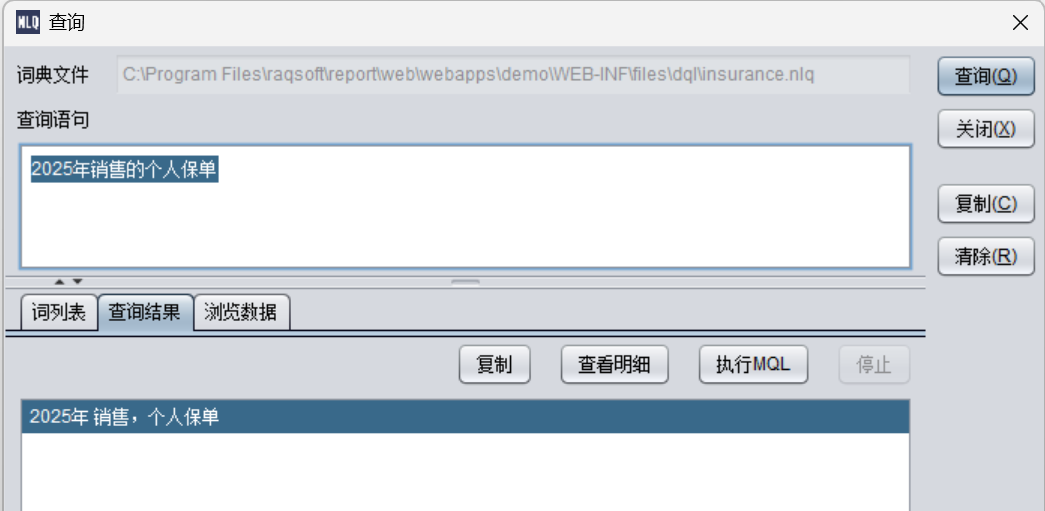
2025 年销售的个人保单
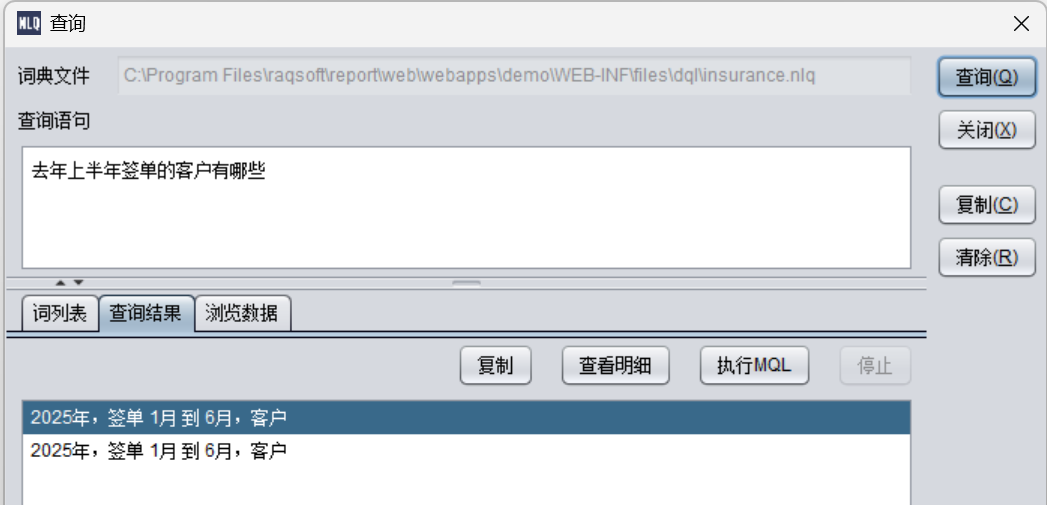
去年上半年签单的客户有哪些
指标词
2025 年保费规模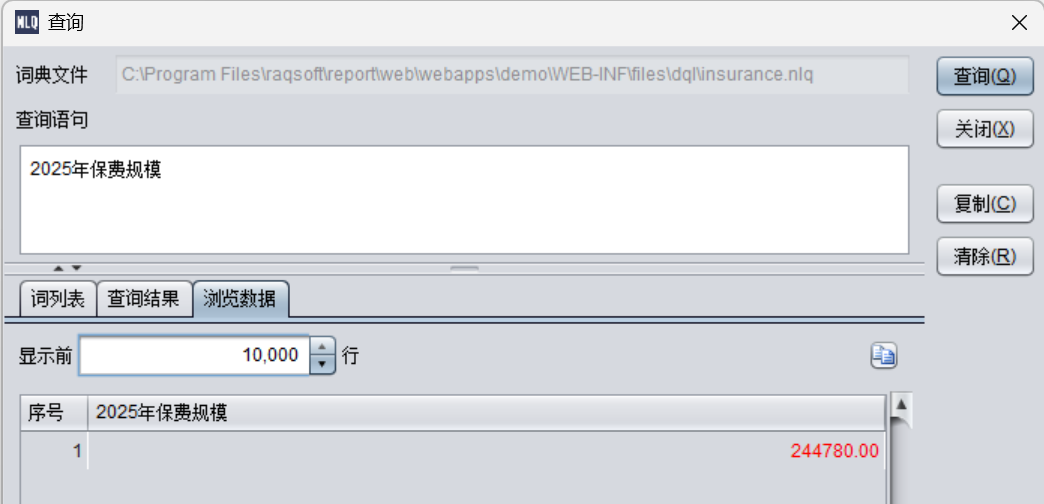
可以看到生成的MQL:
SELECT table_alias_name_1.yearMoney(2025) AS \"2025 年保费规模 \" FROM insurance_product AS table_alias_name_1
4部署
除了在IDE 中进行查询实验,正式应用时需要将其部署到 WEB 上。
4.1配置DQL&NLQ JDBC 连接
修改raqsoftConfig.xml,配置 DQL 和 NLQ 数据源
<DB name="DQL4Insurance">
<property name="url" value="jdbc:datalogic://127.0.0.1:3366/insurance"/>
<property name="driver" value="com.datalogic.jdbc.LogicDriver"/>
<property name="type" value="16"/>
<property name="user" value="root"/>
<property name="password" value="root"/>
<property name="batchSize" value="1000"/>
<property name="autoConnect" value="false"/>
<property name="useSchema" value="false"/>
<property name="addTilde" value="false"/>
<property name="dbCharset" value="UTF-8"/>
<property name="clientCharset" value="UTF-8"/>
<property name="needTransContent" value="false"/>
<property name="needTransSentence" value="false"/>
<property name="caseSentence" value="false"/>
</DB>
4.2词典配置
修改classes\nlqConfig.xml
<NLQ name ="nlqInsurance">
<!-- 在raqsoftConfig.xml中配置好的DBConfig名称 -->
<DB>DQL4Insurance</DB>
<!-- nlq文件路径,支持类路径和绝对路径 -->
<MetaData>web/webapps/demo/WEB-INF/files/dql/insuranceLLM.nlq</MetaData>
<!-- 当NLQ下配置了RaqsoftConfig,以NLQ下的为准 -->
<RaqsoftConfig></RaqsoftConfig>
</NLQ>
4.3Web 访问
http://localhost:6868/demo/raqsoft/dql/jsp/dqlSearch.jsp?dataSource=NLQ4Insurance&hideLeft=1
参数包括:数据源名称dataSource,且隐藏左边部分hideLeft=1
5LLM 规范提示词
通过词典虽然已经可以实现相当灵活程度的Chat 查询,但对于千奇百怪的口语表达来说还不够。LLM 非常擅长将多变的汉语表达转换成符合 NLQ 要求的输入形式(规范文本)。所以扩展灵活性可以将 NLQ 与 LLM 结合使用,借助提示词完成从口语到规范文本的转换。
实际应用中,需要将demo系统切换到其他业务主题(如切换到真实的保险行业中),这时,我们也借助LLM 辅助完成提示词的修改。
5.1demo 系统提示词
Demo 系统规范转换的提示词文件位于应用的classes 目录下,其中nlq-prompt.md 是提示词文件。该文件将所有转换规则、词典和范例整合在一起,一次性交由 LLM 处理,将用户的自然语言查询转换为系统可执行的规范查询文本。
nlq-prompt.md 的文件结构如下:
·NLQ 语法说明:定义了单表明细、单表聚合、主子实体、多维对齐汇总四种规范范式及其构成规则。还有例句和不支持的情况。
·词典信息:包括表、字段、关联、半条件支持、维度等。
·任务说明:包括角色、查询语句要求、字段要求、生成语句要求、输出等规则。
5.2获取词典信息
提示词中的词典信息由程序自动生成,用户无需手动维护。可以在词典设计器中,点击菜单- 工具 - 提示词信息:
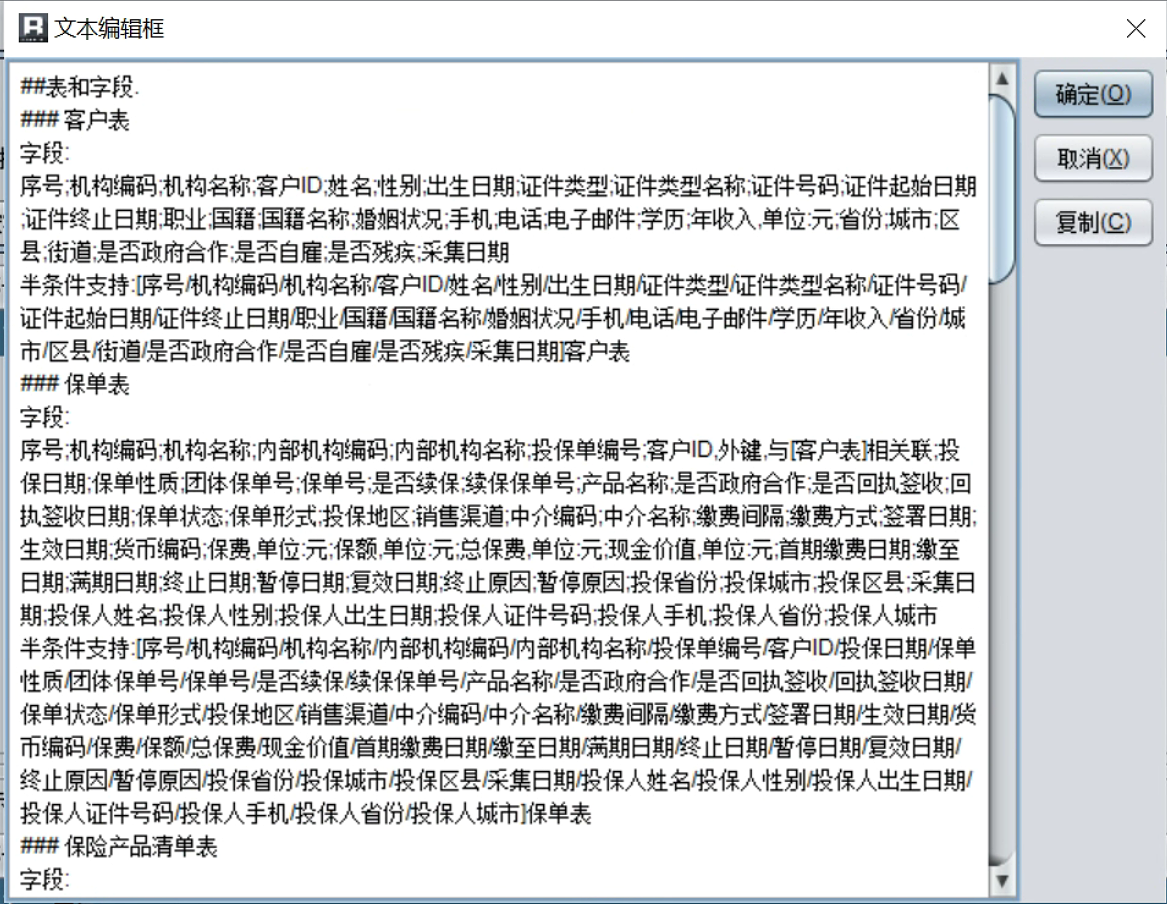
5.3LLM 辅助修改规范化提示词
假设现在要把系统A(比如自带的 demo 系统),切换到系统 B(比如真实的保险业务):
LLM 辅助修改提示词
# 以下是系统 A 的规范化提示词
【此处放置demo 系统提示词nlq-prompt.md内容】
# 任务
现在以此为基础改成系统B 的规范化提示词。
要求:使用下面系统B 的词典,把上述提示词中的相关内容都修改成系统B 的内容。
#系统 B 的词典信息
【此处放置词典信息内容】
人工优化提示词
词典信息中表名、字段名都只有一个“标准名”,比如客户表。一般情况下大模型都可以识别同义词,比如顾客、客人。如果有个别情况无法识别,比如“投保人”,需要手工调整词典信息,加上同义词,比如:客户表(投保人)。
5.4LLM 配置
在dqlSearch2.jsp页面中增加三个核心参数即可接入LLM:
const llmUrl = "https://api.deepseek.com/chat/completions";
const requestJSON = `{"max_tokens":4096,"temperature":1.0,"stream":false,"model":"${thinking==1?"deepseek-reasoner":"deepseek-chat"}","enable_thinking":${thinking==1}}`;
const keyFile = "deepseek.txt";
llmUrl:填写所选大模型的 API 接口地址。
requestJSON:配置 LLM 的调用参数,如模型名称等。
keyFile:指定存储 API 密钥的本地文本文件名(如 deepseek.txt),将对应服务的密钥存入该文件即可。
这里配置了deepseek 的 API 接口地址,以及最大 token 量等参数,并将自己的 APIKey 填入 deepseek.txt 文档,放在 WEB-INF 目录下。
深度规范和普通规范各有优势,前者更准后者更快,两者可以结合使用。配置LLM 后,NLQ默认会使用普通规范,转换后的规范文本如果发现不够准确还可以进步“深度规范”,从而更好完成文本规范。
普通规范与深度规范入口: