


SQLazy:合并有重叠的时间区间
问题描述
一张表记录了多个账户的时间区间,每个账户有多条记录,区间之间可能存在重叠。
源数据:
account_id |
start_date |
end_date |
A |
2019-06-20 |
2019-06-29 |
A |
2019-06-25 |
2019-07-25 |
A |
2019-07-20 |
2019-08-26 |
A |
2019-12-25 |
2020-01-25 |
A |
2021-04-27 |
2021-07-27 |
A |
2021-06-25 |
2021-07-14 |
A |
2021-07-10 |
2021-08-14 |
A |
2021-09-10 |
2021-11-12 |
B |
2019-07-13 |
2020-07-14 |
B |
2019-06-25 |
2019-08-26 |
期望结果(合并每个账户内所有重叠的区间):
account_id |
start_date |
end_date |
A |
2019-06-20 |
2019-08-26 |
A |
2019-12-25 |
2020-01-25 |
A |
2021-04-27 |
2021-08-14 |
A |
2021-09-10 |
2021-11-12 |
B |
2019-06-25 |
2020-07-14 |
以账户 A 为例:
前三个区间(6/20~6/29、6/25~7/25、7/20~8/26)互相重叠,合并为 6/20~8/26;
12/25~1/25 独立;
4/27~7/27、6/25~7/14、7/10~8/14 重叠,合并为 4/27~8/14;
9/10~11/12 独立。
B 同理,两个区间重叠合并。
SQLazy 分步实现
核心思路:判断当前区间的开始日期是否大于前面所有区间的最大结束日期。如果大于,说明当前区间与之前所有区间都不重叠,需要新开一组;否则合并到当前组。
Name |
Anchor |
Statement |
t1 |
acc |
sort account_id, start_date |
t2 |
compute end_date[:-1] max as prev_max; partition account_id |
|
t3 |
segment condition start_date > prev_max as gid; partition account_id |
|
t4 |
summarize start_date min as start_date, end_date max as end_date; group account_id, gid |
|
derive delete gid |
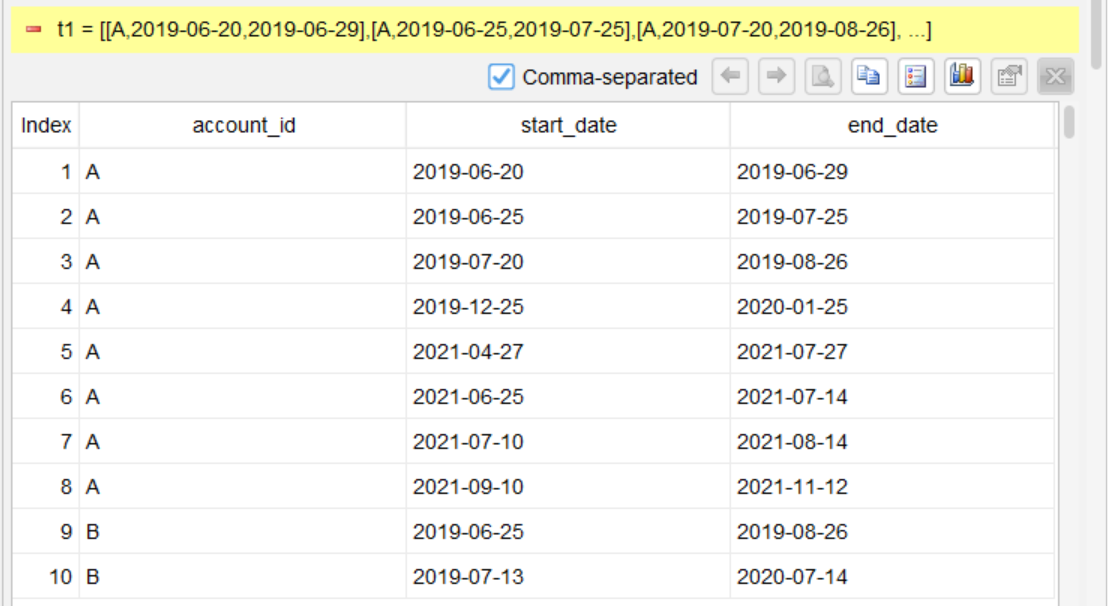
第 1 步:按账户和开始日期排序
sort account_id, start_date
将数据按 account_id 和 start_date 升序排列,确保每个账户内的区间按时间顺序处理。
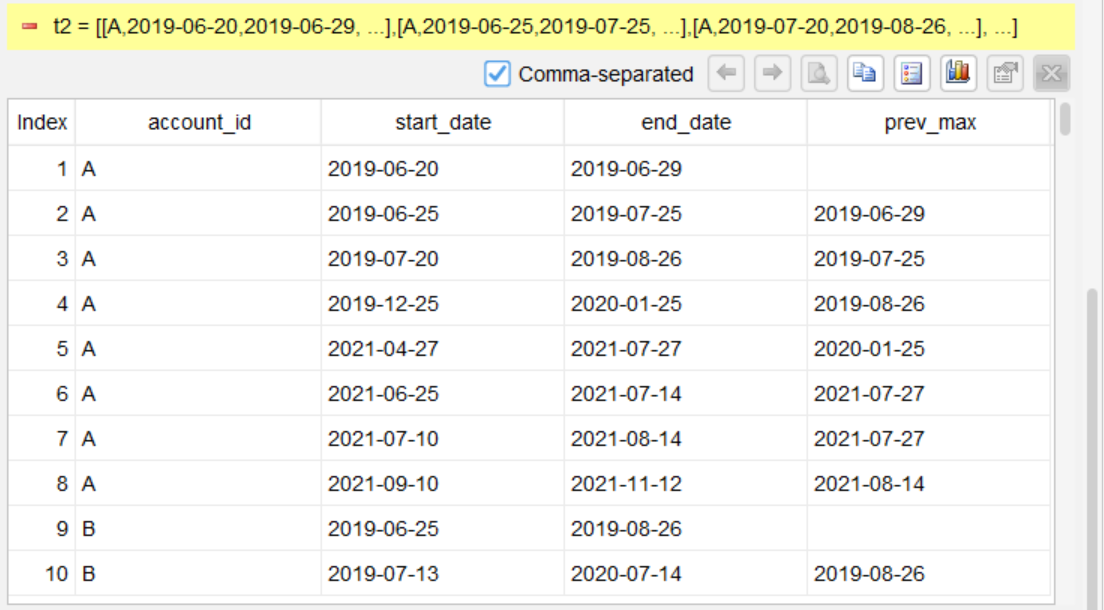
第 2 步:计算当前行之前所有行的最大结束日期
compute end_date[:-1] max as prev_max; partition account_id
在每个账户分区内,计算从第一行到当前行的前一行中 end_date 的最大值,记为 prev_max。
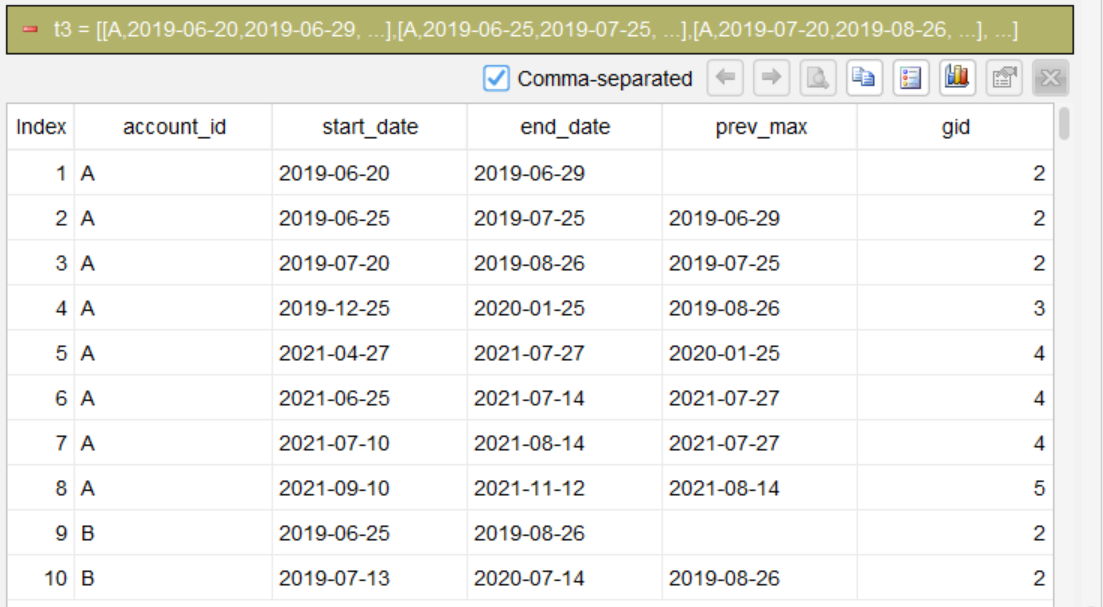
第 3 步:按条件分段,生成组号
segment condition start_date > prev_max as gid; partition account_id
依次检查每行:如果 start_date > prev_max,说明当前区间与之前所有区间不重叠,则新开一组(gid+1);否则归入同一组。
第 4 步:按账户和组号汇总
summarize start_date min as start_date, end_date max as end_date; group account_id, gid
对每组取最早的开始日期和最晚的结束日期,得到合并后的区间。
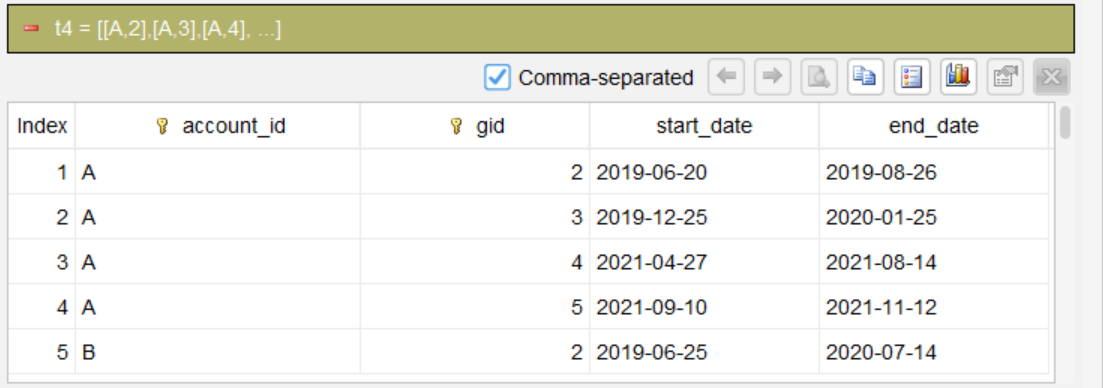
最后删除辅助列 gid。
编译生成 SQL
确认上述 4 步逻辑后,SQLazy 编译器自动生成原生 SQL(以 MySQL 为例):
WITH t2 AS (
SELECT
account_id,
start_date,
end_date,
MAX(end_date) OVER (
PARTITION BY account_id
ORDER BY
CASE WHEN account_id IS NULL THEN 1 ELSE 0 END,
account_id ASC,
CASE WHEN start_date IS NULL THEN 1 ELSE 0 END,
start_date ASC
ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING
) AS prev_max
FROM
acc
),
t3 AS (
SELECT
account_id,
start_date,
end_date,
prev_max,
1 + SUM(
CASE
WHEN start_date > prev_max THEN 1
ELSE 0
END
) OVER (
PARTITION BY account_id
ORDER BY
CASE WHEN account_id IS NULL THEN 1 ELSE 0 END,
account_id ASC,
CASE WHEN start_date IS NULL THEN 1 ELSE 0 END,
start_date ASC
) AS gid
FROM
t2
)
SELECT
account_id,
MIN(start_date) AS start_date,
MAX(end_date) AS end_date
FROM
t3
GROUP BY
account_id,
gid
ORDER BY
account_id,
start_date;
你不需要读懂或调试这段 SQL,只需确认前面 4 步的逻辑正确,编译器就会输出可运行的代码。
为什么这很重要
传统 SQL(手写) |
SQLazy |
|
步骤数 |
多层嵌套 CTE + 多个窗口函数 |
4 步 |
核心技巧 |
需要理解 ROWS BETWEEN 边界和 CASE WHEN 累加 |
直接用 [:-1] 表达“前面所有行”,用 segment 表达分组条件 |
可读性 |
低,窗口函数嵌套难以理解 |
高,每步对应一个明确的业务动作 |
调试方式 |
手动拆解,反复运行 |
单步执行,中间结果可见 |
跨数据库 |
需手动调整语法差异 |
编译器自动适配生成跨库 SQL |
SQLazy 让你用业务语言描述逻辑,而不是用 SQL 语法写嵌套查询。这个“合并重叠区间”的例子只用 4 步就表达清楚了——排序、计算前面最大结束日期、按条件分段、汇总。编译器帮你生成最终的 SQL,你只需要验证每一步的业务含义是否正确。
SQLazy 在线体验:sqlazy.com(免费,无需注册)
SQLazy 项目仓库:github.com/SPLWare/SQLazy


英文版