


SQLazy:分组累计求和
问题描述:只保留开票行,金额累计从上次开票开始
有一张业务流水表(包含 ID、Date、Invoiced 和 Amount 四个字段)。每个月有一条记录,其中 Invoiced=1 表示该月开了发票。
现在要输出:每个 ID 下所有开票月份,并且每张发票的金额等于自上个月开票(或开始)到当前月所有金额的总和(包括当前发票本身)。
源数据:
ID |
Date |
Invoiced |
Amount |
AAA |
2023-01 |
0 |
10 |
AAA |
2023-02 |
0 |
15 |
AAA |
2023-03 |
1 |
15 |
AAA |
2023-04 |
0 |
10 |
AAA |
2023-05 |
0 |
10 |
AAA |
2023-06 |
1 |
10 |
BBB |
2022-05 |
0 |
40 |
BBB |
2022-06 |
1 |
20 |
BBB |
2022-07 |
0 |
30 |
BBB |
2022-08 |
1 |
30 |
期望结果:只保留开票行,每行 Amount 是自上次开票以来的累计值。
ID |
Date |
Invoiced |
Amount |
AAA |
2023-03 |
1 |
40 |
AAA |
2023-06 |
1 |
30 |
BBB |
2022-06 |
1 |
60 |
BBB |
2022-08 |
1 |
60 |
以 AAA 为例:
第一张发票 2023-03:之前有 1 月 (10) + 2 月 (15) + 自身 (15) = 40
第二张发票 2023-06:上次发票之后有 4 月 (10) + 5 月 (10) + 自身 (10) = 30
BBB 同理。
SQLazy 分步实现
Value |
Anchor |
Statement |
t1 |
invoice |
sort id,dt desc |
t2 |
compute invoiced cum as grp partition id |
|
t3 |
summarize dt max as dt invoiced max as invoiced amount sum as amount group id grp |
|
t4 |
derive id dt invoiced amount |
下面分别解释一下这些步骤。
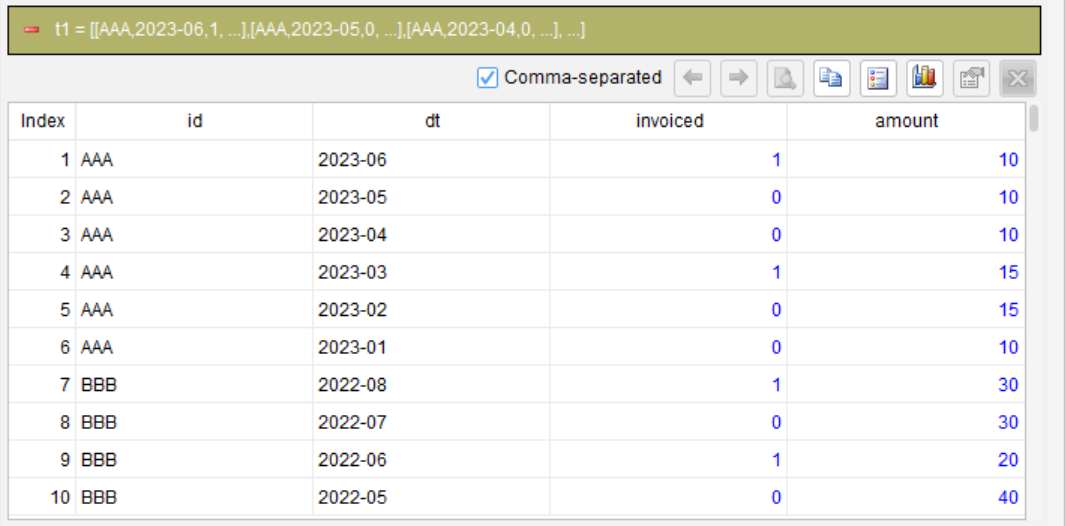
第 1 步:按 ID 和日期排序,日期降序
sort id,dt desc
这一步是为了后续分组做准备。降序排列后,一个发票行与它前面的非开票行会先被处理,累计求和时这些行会被归入同一组。
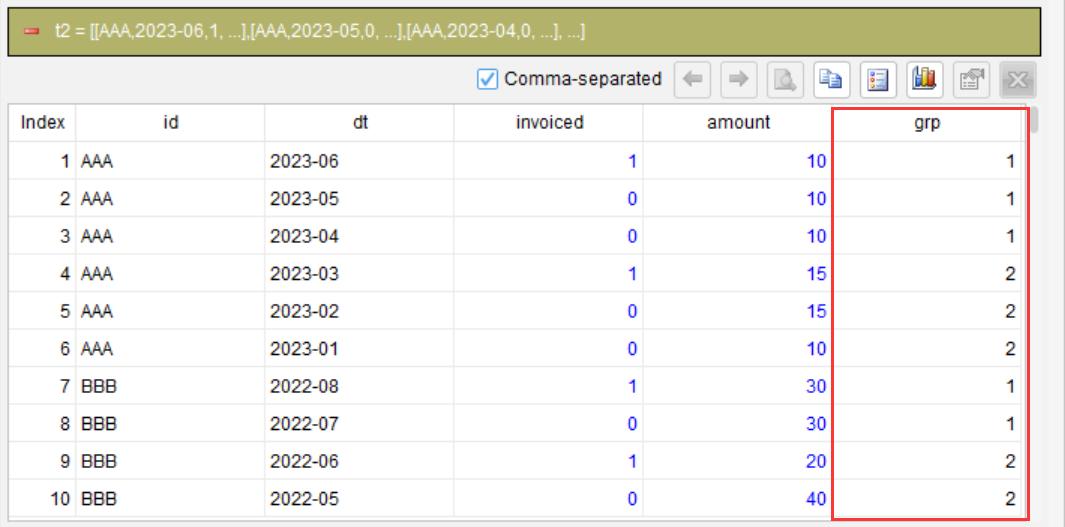
第 2 步:对 invoiced 做累计求和,生成分组号
compute invoiced cum as grp partition id
在每个 ID 分区内,按当前顺序(降序)对 invoiced 进行累计求和(包括当前行)。结果如下:
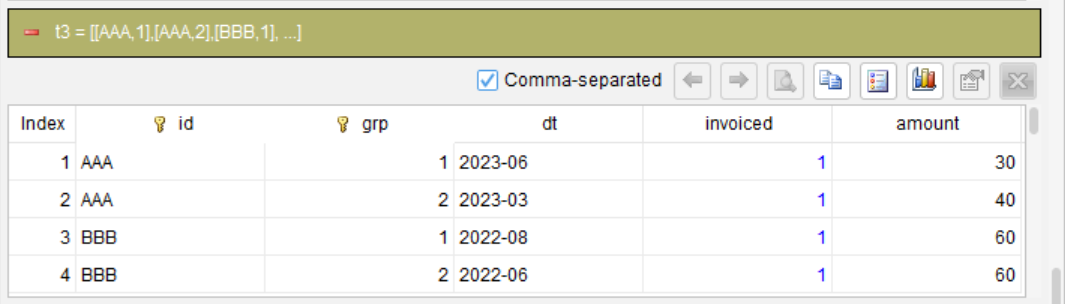
第 3 步:按 ID 和 grp 分组汇总
summarize dt max as dt invoiced max as invoiced amount sum as amount group id grp
dt max:因为降序,每组内日期最大的是开票月份(发票行的日期)。
invoiced max:每组至少有一个 invoiced=1,所以最大值是 1。
amount sum:累加该组所有金额,即自该发票以来(包括自身)的总和。
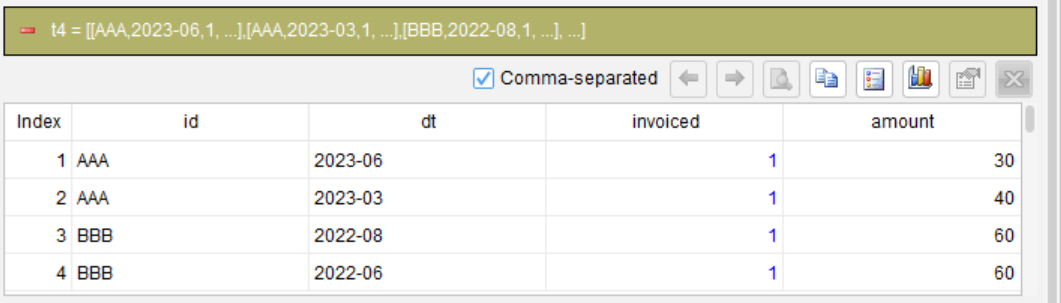
第 4 步:选择需要的列
derive id dt invoiced amount
这一步只是清理输出,去掉辅助列 grp。
编译生成 SQL
完成上述步骤后,通过 SQLazy 的编译器可以生成等价的原生 SQL,无需手动编写。
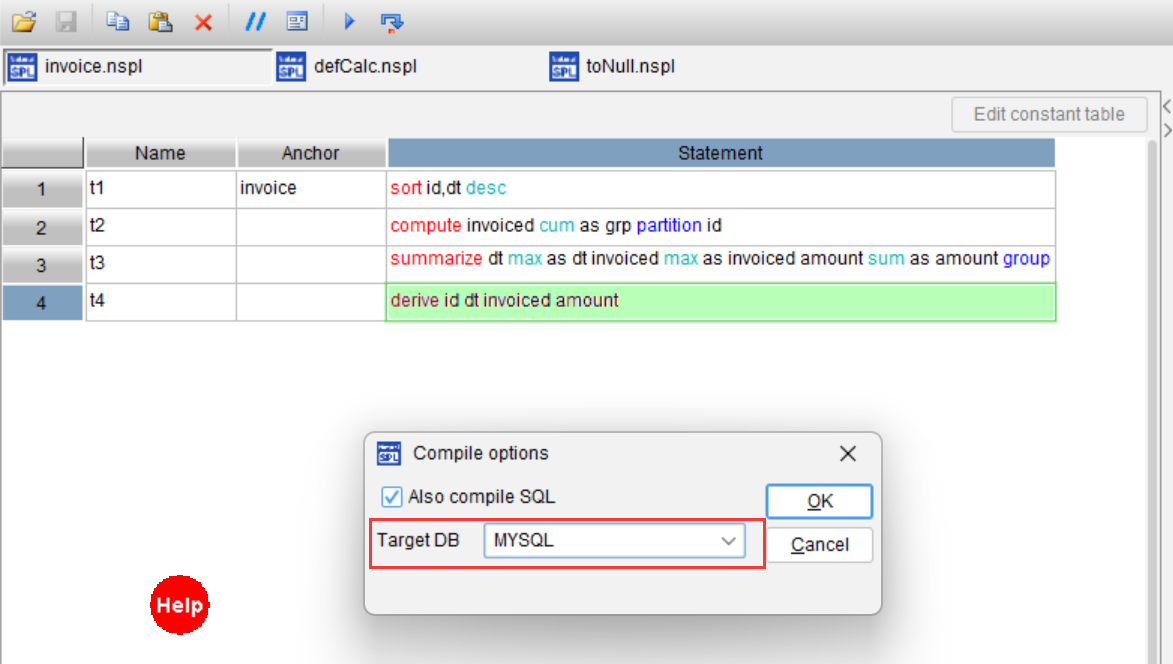
这里生成 MySQL 语句:
WITH t3 AS (
SELECT
id,
grp,
MAX(dt) AS dt,
MAX(invoiced) AS invoiced,
SUM(amount) AS amount
FROM
(
SELECT
id,
dt,
invoiced,
amount,
SUM(invoiced) OVER (
PARTITION BY id
ORDER BY
CASE
WHEN id IS NULL THEN 1
ELSE 0
END,
id ASC,
CASE
WHEN dt IS NULL THEN 1
ELSE 0
END,
dt DESC ROWS UNBOUNDED PRECEDING
) AS grp
FROM
invoice
) t2
GROUP BY
id,
grp
)
SELECT
id,
dt,
invoiced,
amount
FROM
t3
ORDER BY
id,
grp
你不需要读懂或调试这段 SQL,只需确认前面四步的逻辑正确,编译器就会输出可运行的代码。
列个表格总结一下:
传统 SQL |
SQLazy |
|
步骤数 |
多层 CTE + 窗口函数边界 |
4 步(排序→累计→汇总→选列) |
核心技巧 |
晦涩的 ROWS BETWEEN UNBOUNDED PRECEDING AND 1 PRECEDING |
直观的“降序 + 累计求和” |
可读性 |
低,需要理解偏移窗口 |
高,步骤即思考过程 |
调试方式 |
手动拆解 CTE,反复运行 |
单步执行,每一步中间结果可见 |
跨数据库 |
需手动调整方言差异 |
编译器自动生成对应语法 |
这个实例展示了 SQLazy 处理“按事件重置的累计”类问题的自然性:通过一个简单的排序技巧加上累计求和,就能把复杂的分组逻辑拆解为清晰的动作。
SQLazy 在线体验:sqlazy.com(免费,无需注册)
SQLazy项目仓库:github.com/SPLWare/SQLazy


英文版