


Text2SQL 工业级落地,兼得灵活复杂准确
自然语言转 SQL(Text2SQL)技术旨在降低数据查询的技术门槛,但一直面临“灵活性”、“准确性”与“查询复杂性”难以兼顾的困境。直接由大语言模型生成 SQL 存在语义“幻觉”造成准确性偏低。引入结构化中间层(DSL)可以获得准确性的有限提升,但若中间层设计为机器可读而人不可读的形式,即使系统做到 90% 的正确率,业务用户也无法识别和确认剩下的 10% 的错误,准确性依然不可控,同时还会牺牲查询复杂性,难以满足企业级 BI 需求。
润乾 NLQ 技术采用“规范文本”作为中间层 DSL,区别于传统只面向机器的 DSL,规范文本是一种人机双向可读的 DSL,将不确定性限制在自然语言理解阶段,通过人类可确认的方式解决准确性问题。再利用规则引擎确定性转换准确的 SQL 进行查询,同时“规范文本”的结构化设计还能支持复杂查询。LLM 承担自然语言到规范文本的翻译工作,无需直接生成最终代码,避免了幻觉对查询结果的直接影响。这样将同时获得灵活性、准确性与复杂性,为 Text2SQL 的工业级落地提供了一条可行的工程路径。
背景
在商业智能(BI)领域,让非技术背景的业务人员直接、高效地获取数据洞察,一直是个关键的需求。ChatBI 等自然语言交互式查询技术的出现,正是为了满足这一需求,将用户以自然语言表述的查询意图,转换为可执行的 SQL 语句。大语言模型(LLM)的突破性进展,使得利用 LLM 实现从自然语言到 SQL 转换成为可能。
直接生成:基于大语言模型的“一步到位”及其局限
用 LLM 直接将自然语言转换为 SQL 语句是最直观的技术路径,具体来讲,就是通过提示工程、模型微调或检索增强生成等技术将领域知识注入模型,生成符合业务需求的 SQL 语句。
LLM 能够理解和泛化千变万化的口语,对用户而言几乎没有表达上的限制,体现出强大的灵活性。同时,得益于在海量代码数据上的预训练,LLM 理论上具备生成多表 JOIN、嵌套子查询等复杂 SQL 功能的能力,为处理复杂业务场景提供了可能。
然而,该方案有个根本性的缺陷:LLM 幻觉导致的准确性问题,这对企业级应用是致命的。LLM 可能生成语法正确但语义错误的 SQL,比如混淆关键业务指标、错误构建多表关联逻辑,或在时间计算等业务规则上出现偏差。在企业决策场景中,错误的查询结果就可能导致重大损失,这种不确定性是企业无法接受的。
不幸的是,缺乏有效的确认机制来克服幻觉问题。Text2SQL 的应用场景大都是 BI,其用户是业务人员,LLM 生成的 SQL 对业务人员而言是读不懂的 "天书",也就无法确认查询意图是否被正确理解,这使得语义错误难以及时发现和纠正。
此外,该方案的实施成本极高。无论是通过微调训练专用模型,还是构建 RAG 知识库,都需要专业的 AI 技术团队,其技术难度和实施成本相当于 "为了坐飞机而建立飞行员团队",对绝大多数企业而言不具备可操作性。
中间层路径:引入中间层的“控幻”尝试及代价
为应对 LLM 直接生成 SQL 时的不可控性,业界引入“中间表示(DSL)”的折中方案。将 Text2SQL 任务拆解为两个阶段:首先由 LLM 将自然语言转换为结构化的中间表示(DSL),再用确定性的规则引擎将 DSL 编译为 SQL 执行。引入 DSL 本身是一个正确的方向,通过结构化约束缩小 LLM 的输出空间,提升确定性。
然而,问题的关键不在于是否使用 DSL,而在于 DSL 是否同时面向机器和人类。一般方案设计的 DSL(如 JSON、XML、或自定义的 MQL 语法)只考虑机器可解析性,忽略了人类可读性。业务用户面对这样的 DSL 仍然读不懂、无法确认。即使系统做到了高准确率也无济于事,因为用户没有能力挑出剩余的错误——根本看不懂中间结果。DSL 是否人机双向可读,是 Text2SQL 成败的关键。
而且,这种方案在准确性方面并未得到实质性提升。虽然将 LLM 的任务限定为生成结构固定的 DSL 确实约束了其输出空间,但由于这些 DSL 缺乏公开的大规模训练语料,当 DSL 设计得较为复杂时,未经训练的 LLM 会因不熟悉语法规则反而容易出现更严重的幻觉。为了在表面上提升准确性,不得不严重压制查询的复杂性。将 DSL 设计得足够简单,LLM 受限后准确性确实能提高,但这又导致无法表达很多复杂业务逻辑(如多表关联、嵌套查询等),制约了其实用价值。
实施成本也依然不低。DSL 本身无法解决领域知识缺失的问题,仍需依赖微调、RAG 等技术手段将企业特定的业务知识注入模型,导致整体实施与维护成本难以降低。
当前的技术路径未能完美解决 Text2SQL 的核心挑战,这是一个“三难困境”:在现有的技术框架下,灵活性(理解多样化表达)、准确性(生成正确 SQL)与复杂性(覆盖更广泛的查询需求)三者难以兼得。
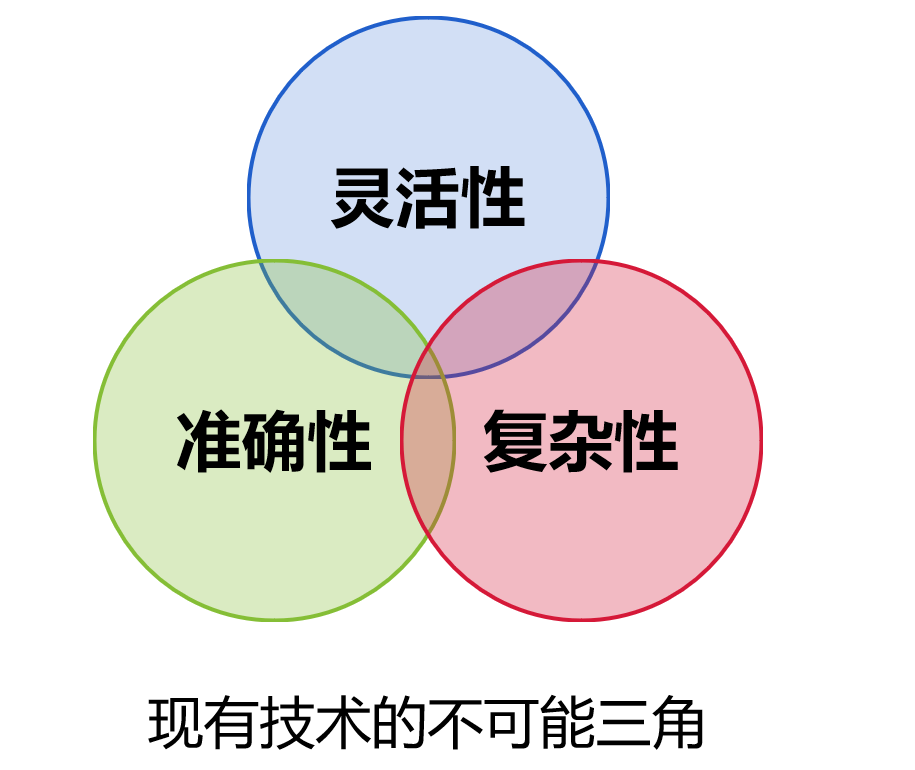
两条路径看似取舍不同,但核心困境如一:生成的 SQL 或 DSL 均无法被业务用户理解和确认。当查询的准确性始终存在疑虑且无法验证时,技术自然难以落地。
即使将缩减查询范围(比如单宽表)后能做到 90% 的准确率,只要业务用户看不懂中间表示、无法确认查询意图,那这 90% 在企业眼中仍然是 0%——没人敢在生产环境使用一个无法判断何时出错的黑箱系统。可确认,比高准确率更重要。
“规范文本”与灵活性
针对上述困境,润乾 NLQ 提出了一种新的三阶段架构,其核心在于可由人类确认的 "规范文本",重构了人机协作的查询生成流程。
流程架构
架构的转换路径:
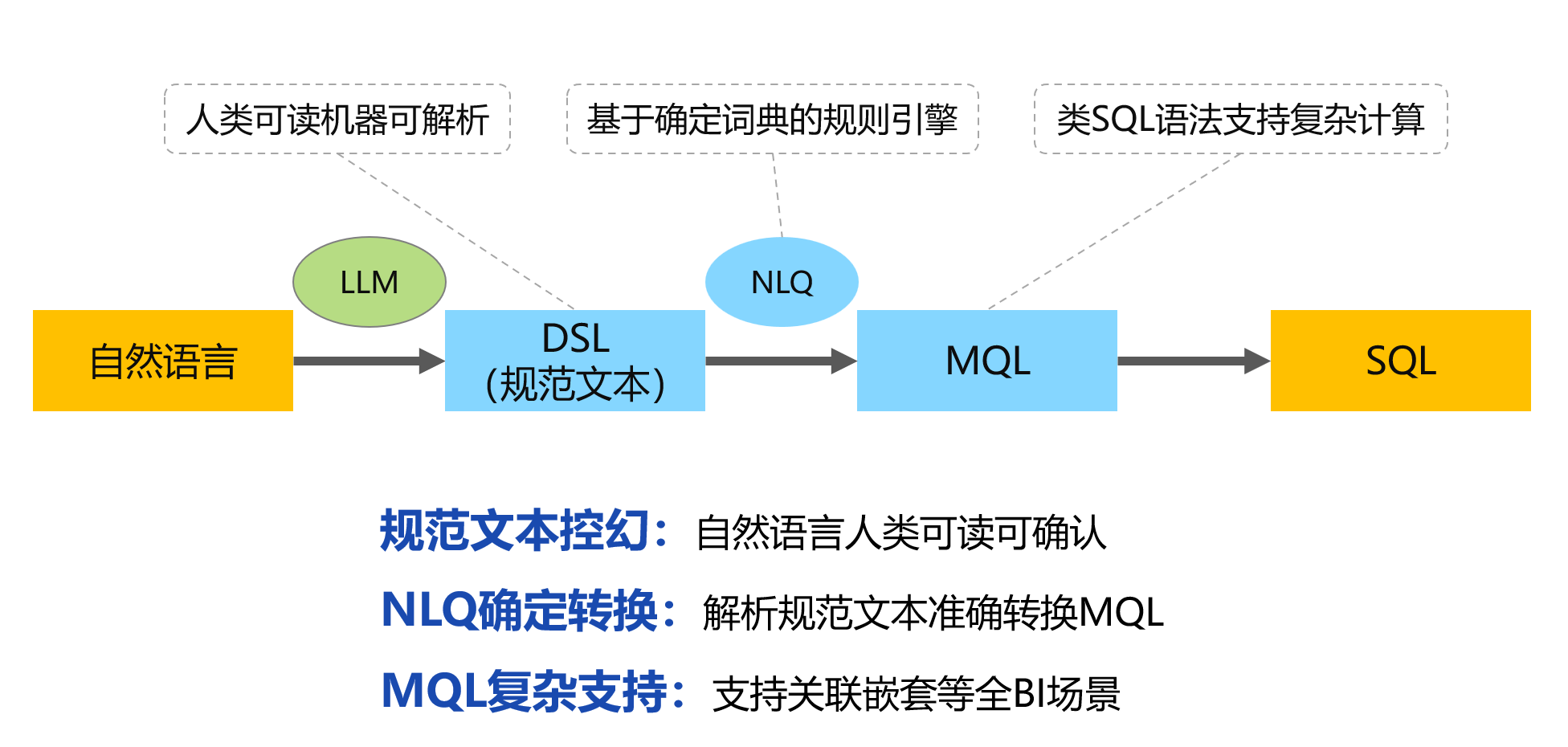
这里增加了一个规范文本环节。从自然语言到规范文本的转换由 LLM 完成——LLM的角色被明确定义为“翻译”,将五花八门的口语表达转写为标准化的规范文本,而非直接生成最终代码;从规范文本到 MQL 的转换由专门的 NLQ 引擎基于词典的规则确定性完成;从 MQL 到 SQL 的转换则是常规的代码翻译程序。
突破在于“规范文本”的引入——规范文本本身就是一种 DSL(领域特定语言),但区别于传统只面向机器的 DSL,它是一种人机双向可读的 DSL。规范文本作为人类可读的中间层,为用户提供了确认查询意图的机会,这是解决准确性问题的关键。
“规范文本”:人机协同的语义枢纽
规范文本,顾名思义,就是一种规范的自然语言形式。作为一种 DSL,其独特价值在于同时具备人类可读性与机器可解析性。
这里列举一些规范文本的例子:
出生日期在 1986 年 1 月至 1986 年 7 月的雇员
订单明细,折扣 最大者,产品 名称
签单日期 上个月,没有 订单,员工
自然语言形式的规范文本对于人类完全可读可理解。
类似的,再举一些不规范文本,也就是灵活的自然语言的例子:
出生日期在 1986 年 1 月至 7 月的雇员(前后单位不统一,后面缺少年份)
订单里哪个商品打折力度最大?(使用了过于口语化的“打折力度”)
去年谁没开单?( “开单”属于行业“黑话”)
将规范文本用作 DSL 会获得一个关键优势:人机双向可读。
人类可确认性。由于采用业务人员熟悉的自然语言形式,而非 JSON、XML 等技术格式,用户能够直观理解并确认:“对,这就是我想查的!”确认环节是解决幻觉问题的关键。即使 LLM 在转写过程中产生了偏差,用户也能一眼看出并纠正——系统不再是一个黑箱。
机器可解析性。虽然表现形式类似于自然语言,但规范文本遵循预定义的结构约束和词汇表限制,可以通过确定的解析规则自动化处理。规范文本的结构化特性为后续的 MQL 设计提供了基础,使其能支持包括多表关联、指标计算等复杂查询功能,而不会像以往 DSL 那样压制查询能力。
规范文本的意义
在这个架构中,LLM 的角色定位发生了根本性转变。以往方法中,LLM 被期望直接生成准确的 SQL 或 DSL,承担了“理解 + 生成”的双重任务。而在新架构中,LLM 的任务被简化为将多变的自然语言表达翻译为标准化的规范文本,这一翻译任务与 LLM 的语义理解能力天然匹配。润乾 NLQ 不是不用 LLM,而是把 LLM 放在它最擅长的位置——做翻译,不做决策。
这种角色转变后,LLM 仅需按照简单的 prompt 规则进行文本变换,无需深度理解企业特定的领域知识。现成的通用大模型就可以工作,不再必须投入高昂成本进行微调或构建 RAG 知识库。实施工作转变为构建 NLQ 业务词典,这个任务的技术门槛远低于模型训练,普通开发人员即可胜任。
在稳定性方面,即使 LLM 在生成规范文本时出现偏差,也有两重保障:一方面,规范文本的人类可读性使用户能够及时发现并纠正问题;另一方面,NLQ 引擎会对输入进行校验,确保只有符合规范的文本才会进入后续流程。
基于规范文本的 NLQ 架构成功解决了 Text2SQL 的困境,实现了灵活性、准确性和复杂性三者兼得。 LLM 处理自然语言的多样性,确保了灵活性;规范文本的可确认性和后续的确定性转换,保障了准确性;规范文本的结构化特性为复杂查询提供了基础,企业级应用的需求能够得到满足。
通过规范文本的创新设计,在自然语言的灵活性与机器处理的确定性之间找到了平衡点。特别是可确认的 "规范文本" 这一中间表示,解决困扰 Text2SQL 领域的准确性问题,为其在企业级应用中落地提供了切实可行的工程路径。
MQL 实现与复杂性
引入 MQL 层具有重要意义。作为规范文本的确定性编译目标,MQL 承担着双重使命:首先,要利用它彻底消除自然语言中可能存在的残余歧义,规范过的文本,仍然有可能存在多种合理的解释或者无法解释,还需要有种严格的语法来确定最终的查询意义;其次,它要通过精心设计的语法结构限制查询能力,杜绝过于随意的查询请求,但仍要保持足够的复杂度。既满足企业级复杂需求,又可以基于可控性获得准确性。MQL 需要精心设计以平衡表达力与规范性。
接下来将继续解析 MQL 的设计逻辑及其实现机制。
MQL:精确语义的承载者
MQL 承担着承上启下的作用。作为规范文本的确定性编译目标,需要建立精确的语义基准,消除自然语言中可能存在的残余歧义。同时通过精心设计的语法结构,在保持对企业级复杂查询足够表达力的前提下,将查询能力限制在合理范围内,确保可控性与准确性。
这种平衡体现在 MQL 的四类查询范式中:单表明细查询、单表汇总查询、多表明细查询、多表汇总查询。这些范式基本覆盖了 BI 场景下的典型查询模式,为从规范文本到精确查询的转换提供了系统的表达框架。
1. 单表明细查询
文本:订单金额不低于 1 千元的订单
MQL:
SELECT 订单金额, 订单编码, 客户名称, 签单日期, 发货日期, 收货日期
FROM orders
WHERE 订单金额 >= 1000
说明:单一数据源,无聚合,仅筛选和字段映射。
2. 单表聚合查询
文本:各城市发货总金额
MQL:
SELECT orders.sum(订单金额) as 总金额
ON city as 城市
FROM orders
BY 发货城市
说明:维度(ON) + 聚合(sum) + 分组(BY)。
3. 多表明细查询
文本:订单数大于 5 的客户信息以及总订单金额
MQL:
SELECT 客户编码, 客户名称, 联系人, 城市编码,
orders.count(DISTINCT 订单编码) AS 订单数,
orders.sum(订单金额) AS 总订单金额
FROM customer
JOIN orders
HAVING 订单数 > 5
说明:主表与子表聚合关联,支持 HAVING 过滤。
4. 多表汇总查询
文本:各个类别的订单总数和在线订单数
MQL:
SELECT orderdetail.count(DISTINCT 订单编码) as 订单总数,
website_event.sum(在线订单()) as 汇总在线订单数
ON ProductType as 类别
FROM orderdetail BY 产品类别
JOIN website_event BY 产品分类
说明:多源独立指标按同一维度对齐计算。
这四项查询范式能够描述从简单筛选到复杂跨源分析的各类 BI 场景,为自然语言查询提供了较全面的表达能力。同时,MQL 采用类 SQL 的语法设计,具备严格的规范性,将查询能力进行限制,杜绝过于随意的查询请求,但仍保持了足够的复杂度,在表达力与规范性之间有效平衡。
DQL:透明化表间关联
MQL 本身不直接处理多对一的外键关联(例如从订单表关联客户表获取城市)。为解决这个问题,MQL 与 SQL 之间加入DQL(Dimensional Query Language),一种基于维度的查询语言,通过“外键属性化”消除显式 JOIN。
示例:查询“北京发往青岛的订单”
用户自然语言 → LLM 转换为规范文本 → NLQ 引擎生成 MQL(只有订单表):
SELECT 发货城市, 收货城市, 订单编码, 客户名称, ...
FROM orders
WHERE 发货城市=30101 AND 收货城市=20201
MQL 转换为 DQL(用 customerid.citycode 访问客户表字段):
SELECT shipcity, customerid.citycode, orderid, ...
FROM orders
WHERE shipcity=30101 AND customerid.citycode=20201
DQL 引擎自动生成含 JOIN 的 SQL:
SELECT o.shipcity, c.citycode, ...
FROM orders o
JOIN customer c ON o.customerid = c.id
WHERE o.shipcity=30101 AND c.citycode=20201
核心机制:DQL 将外键关系抽象为对象属性(customerid.citycode),用户写查询时如同操作单表,无需关心 JOIN。表间关联由预定义的数据模型自动处理,技术人员一次性配置即可。
DQL 让 MQL 能以单表形式表达多表关联,大幅降低复杂查询的编写和理解成本。
SPL:复杂指标计算引擎
尽管 MQL 和 DQL 能够覆盖大部分 BI 查询场景,但在处理复杂业务指标时仍存在局限。诸如股票连涨天数、用户留存率等需要多步计算或特殊算法的场景,SQL 的实现会非常复杂而且难以被嵌入复用,这时候需要引入更专业的计算能力,也就是SPL(Structured Process Language)。
SPL 作为专门处理复杂计算的语言,在架构中扮演着计算引擎的角色:
时序计算:支持移动平均、周期对比、连续增长等复杂时间序列分析
集合运算:处理分组排名、TopN 分析、集合交并差等操作
流程计算:实现漏斗分析、路径挖掘、归因分析等业务场景
数学计算:提供统计分布、相关性分析等高级功能
MQL 可以直接使用 SPL 定义的指标,比如要计算大订单数量,大订单是指订单金额超过最大金额 50% 的订单。这时就可以定义 SPL 计算指标:
(x=?1.max( 订单金额)/2,?1.count(订单金额 >=x))
MQL 碰到用 SPL 定义的指标时,将会先生成读数用的 DQL(再转换成 SQL)执行后再用 SPL 在结果集上继续计算出这些复杂指标。如果 MQL 中没有 SPL 定义的指标,那将会被转换成 DQL 继续解析掉关联生成完整的 SQL 执行。
润乾 NLQ 通过 MQL、DQL、SPL 的协同设计,构建了一个层次清晰、职责分明的 Text2SQL 执行机制。MQL 作为规范文本的精确编译目标,在保持足够表达力的同时确保了查询的规范性;DQL 通过维度建模和关联透明化,降低了数据访问的复杂度;SPL 则专注于复杂指标计算,扩展了系统的分析能力。
NLQ 词典与准确性
NLQ 引擎是另一个关键的技术挑战。它要具备一定程度的语言解析能力,能够准确理解规范文本中多样的表达方式。从技术层面看,这相当于构建了一个小语言模型(Small Language Model),其开发难度也不容小觑。
由于 NLQ 引擎基于规则构建,不同语种的语法规则和表达习惯完全不同,无法直接通用。例如,汉语和英语在语序、分词、句式结构等方面存在根本性差异,需要分别构建独立的解析体系。这里将先聚焦于解决汉语环境下的 NLQ 解析问题。
NLQ 词典:语义的映射基础
NLQ 规则引擎如何能像“理解了一门语言”一样,将仍有相当自由程度的规范文本准确地转换为语法严格的 MQL?这就是NLQ 词典的任务。
NLQ 词典是一个结构化的业务 - 数据映射知识库,定义了业务语言中每个“词”在数据世界中身份、行为逻辑和关联关系。
基本概念:构筑查询语义的积木
NLQ 词典围绕以下几个概念展开,它们共同构成了从自然语言到 MQL 的转换路径:
表与实体:表对应物理表,实体是表的业务化视图
宏字段:查询的最小语义单元,包括计算字段和外键字段
指标:通过表达式定义的聚合度量,复杂指标采用 SPL 语法
字段簇与簇词:处理业务中的组合信息与语义歧义(如区分“发货”和“收货”)
维、维词与常数词:描述分析视角和构建过滤条件
特色词型:应对灵活表达的武器库
为了覆盖多样化的自然语言表达,NLQ 词典配备了多种特色词型:
无效词:用于过滤掉查询中的口语化虚词和语气词。
宏词:用于处理口语化的业务概念,将其转换为规范的查询逻辑。、
动词:用于建立更复杂的过滤逻辑,特别是涉及多个字段簇时。
量词:用于处理带有单位的数值,自动进行单位换算。
比较词与连词:大于、小于、等于等比较词定义了过滤关系。
实例解析:从文本到 MQL 的转换
例 1:基础过滤查询
文本:姓名为李芳的职务、出生日期和年龄
解析:引擎识别出“姓名”“职务”“出生日期”“年龄”为字段,“李芳”为常数,自动构建过滤条件。
生成 MQL:
SELECT 姓名, 职务, 出生日期, 年龄 FROM EMPLOYEE WHERE 姓名 ='李芳'
例 2:字段簇与动词消除歧义
文本:北京发往青岛的订单
解析:“发往”关联“发货”和“收货”两个字段簇,“北京”分配给发货城市,“青岛”分配给收货城市。
生成 MQL(示意):
SELECT ... FROM ORDERS WHERE (发货城市=30101) AND (收货城市=20201)
例 3:复杂聚合与子查询
文本:订单金额总和大于 20 万元的女员工
解析:引擎识别出“女”过滤员工表,“订单金额总和”为聚合条件,“万元”自动换算为数值。查询转换为子表聚合后的过滤。
生成 MQL(示意):
SELECT ... FROM EMPLOYEE WHERE 性别='女' JOIN ORDERS HAVING 订单金额总和 > 20*10000
例 4:多表汇总与复杂指标计算
文本:各省的员工数、产品数和大订单数
解析:“各省”为分组维度;“大订单数”是预定义的复杂指标(SPL 语法:订单金额超过最大金额 50%)。引擎自动按省份关联员工表、产品表、订单表,并调用指标计算。
生成 MQL(示意):
SELECT EMPLOYEE.count(雇员编码), PRODUCT.count(产品编码), ORDERS.大订单数() ON 省份 FROM EMPLOYEE BY 省份 JOIN PRODUCT BY 省份 JOIN ORDERS BY 省份
解析过程是基于词典规则的、确定性的,不用“再训练”,每一步可追溯、可解释、可调试。当出现解析错误或无法解析的查询时,可以在规则框架下快速定位问题,是缺少词条、字段簇配置不当,还是维度映射不完整,当然也有可能是引擎的 BUG。这种可解释性将获得持续优化的能力,通过补充词典配置等操作即可修复问题。相反, LLM 过于复杂而失去可解释性,用它直接生成 SQL 或 MQL 也就缺乏可控性:生成失败时难以诊断根源,即使投入大量成本进行再训练,也难以预测和保证改进效果。
词典的构建、管理与工程实践
词典构建是实现准确性的核心,润乾 NLQ 提供了可视化的设计器来支持这一过程。
元数据导入:从 DQL 语义层自动获取表、字段、维度和关联关系等基础信息,为词典奠定数据基础。
业务化封装:
定义字段词:将“SALARY”改为“薪水”,将“PRODUCT_NAME”改为“产品名称”。
创建字段簇:根据业务逻辑,将字段分组,如创建“发货信息”、“收货信息”、“客户信息”等簇。
设置实体:为同一张表创建不同业务视图,如“员工基础信息”、“员工财务信息”等,并配置不同的字段簇。
配置词汇表:维护维词、常数词、比较词、动词等。
持续测试与优化:通过设计器的“搜索实验”功能,使用真实例句进行测试,查看解析过程与结果,发现并修复词典配置的边界案例,迭代优化,逐步提升解析准确率。
这个过程由懂业务的开发人员实施,技术门槛远低于 AI 模型的训练与调优,确保了 NLQ 方案的普适性和可落地性。
将 LLM 的泛化能力限定在 "文本转写" 范畴,并将企业特有的知识固化为可管理、可优化的词典规则,构建一条通往实用可靠的自然语言数据查询的工程路径。这种基于词典的规则引擎方案,使 Text2SQL 具备了可实施、可维护、可信任的企业级应用特性。
结语
总结一下润乾 NLQ 各个部件的作用:
部件 |
定位 |
解决什么问题 |
规范文本(DSL) |
人机双向可读的中间层 |
让业务用户可确认意图,解决准确性问题 |
LLM |
口语到规范文本的翻译器 |
保障灵活性,无需深度领域知识 |
NLQ 词典 |
业务语言与数据的映射桥梁 |
承载领域知识,实现确定性转换 |
MQL |
精确语义承载者 |
建立标准查询范式,确保可控性 |
DQL |
透明化表间关联 |
消除 JOIN 复杂性,外键属性化 |
SPL |
复杂指标计算引擎 |
处理 SQL 不擅长的复杂计算 |
我们从“规范文本作为人机双向可读的 DSL”破局——区别于传统只面向机器的 DSL,规范文本让业务用户可以确认查询意图,这是解决 Text2SQL 准确性问题、打破“90% 准确率也不够用”困局的关键。用“MQL-DQL-SPL三层架构”实现复杂性——MQL 建立精确语义基准,DQL 透明化表间关联,SPL 处理复杂指标计算。用“NLQ词典”承载领域知识实现确定性转换。三者环环相扣,LLM 在其中承担翻译角色而非最终代码生成,共同构成了一个同时满足灵活性、准确性、复杂性的 Text2SQL 方案。

