


SQLazy:告别盲信 AI,分步构建可靠查询
AI 能写出可以运行的 SQL,但经常无法信任。SQLazy把 SQL 开发变成一个可逐步验证、可审计的流程,编译器来保证最终输出的正确性。
问题:AI 给出的 SQL 是个黑盒
我们都遇到过这种情况。把一个复杂的分析查询需求扔给 ChatGPT 或 Claude,它吐出一坨几十行的 SQL 怪物,然后你想:“这能跑起来……但我应该信它吗?”
现实中,AI 生成的 SQL 常在这些地方翻车:
错误的连接逻辑— 连错表,或者漏掉必要的连接条件
聚合错误—GROUP BY 跟你的意图对不上,或者漏了非聚合列
缺失过滤条件— 遗漏了微妙的业务约束(比如“只统计活跃用户”)
语义偏差— 你说的“营收”跟模型理解的“总金额”可能不是一回事
边界条件被忽略—NULL 值、空集、极端值往往被优雅地忽略
现在的 AI 能生成能跑的 SQL,但你永远不知道能不能信它。一旦查询涉及深层嵌套窗口函数和子查询,就变得难以 review、调试、维护和迁移。
更麻烦的是,当结果不对劲时,你该怎么修?
你只能一段一段 CTE 手动运行,到处插 SELECT * FROM …来排查
或者重新改 prompt,让 AI 再生成一版,但可能越改越乱
最终花的时间比自己写还长
这就是“黑盒 SQL 生成”的真实代价。
SQLazy 的做法
SQLazy 不是直接生成一条巨无霸 SQL 语句,而是把 SQL 开发变成一个可以一步步跟踪的工作流:
用半自然语言描述每一步要做什么
逐步验证每一步的逻辑对不对(能看中间结果)
让编译器生成最终的 SQL
最终 SQL 由编译器生成,而不是 LLM。这意味着:
没有 AI 幻觉导致的 SQL 错误,结果 100% 正确
逻辑完全可审计
产出可直接上生产
举个例子:找出一只股票的最长连续上涨天数
这是一个经典的分析问题,而且在纯 SQL 里比较难写(有些公司把它当面试题,通过率不到 20%)。
下面看看如何用 SQLazy 一步步构建。
先按步骤描述工作流
不用去跟嵌套子查询搏斗,而是把逻辑表达成一连串简单的变换:
Name |
Anchor |
Statement |
stock |
file "stock.csv" csv header |
|
s1 |
filter CODE = 110838 |
|
s2 |
sort DT asc |
|
s3 |
segment CL down as NoRisingDays |
|
s4 |
summarize DT count as ContinuousDays group NoRisingDays |
|
summarize ContinuousDays max as max_ContinuousDays |
就这些。每一步只做一件简单的事。逐行解读:
读入数据,数据来源可以是文件、数据库或内存表(SQLzay 内置)。在 IDE/WEB 里可以直接看到每步的执行结果。
过滤股票代码 110838 的数据
按日期升序排序
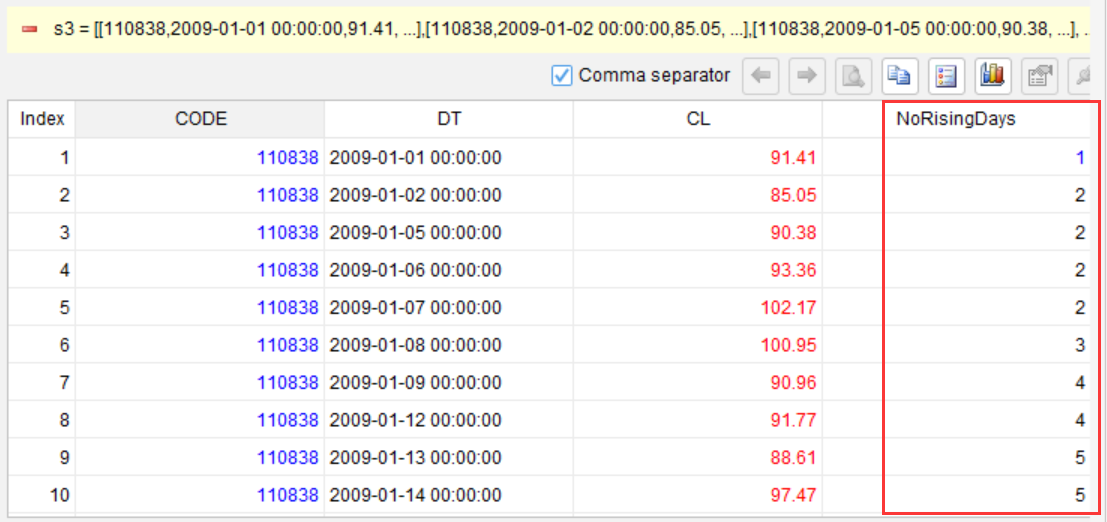
标记上涨中断的点,用来区分连续上涨的组
统计每个连续组里有多少天
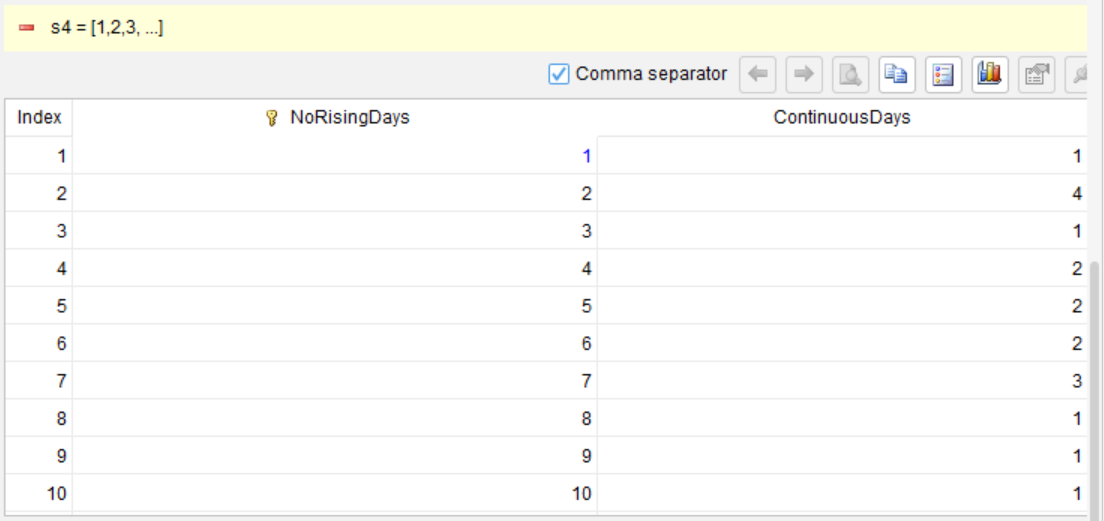
取出最大的天数

谁都能看懂这个逻辑,不需要精通 SQL 就能明白这个查询在干什么。
而且,每一步你都可以实际运行看到中间结果。比如第 3 步分段之后,你会看到多了一列 NoRisingDays,里面是每个上涨组的编号。如果发现编号不对,当场就能调整,不用等最后跑完整个查询再回头猜。
再让编译器生成 SQL
SQLazy 自动把这些步骤编译成原生 SQL(现在支持 MySQL、PostgreSQL、Oracle,Snowflake 和 BigQuery 还在路上)。
WITH s2 AS (
SELECT CODE, DT, CL
FROM (SELECT CODE, DT, CL FROM stock) t_3
WHERE CODE = 110838
)
SELECT MAX(ContinuousDays) AS max_ContinuousDays
FROM (
SELECT NoRisingDays, COUNT(DT) AS ContinuousDays
FROM (
SELECT CODE, DT, CL,
SUM(CASE WHEN CL < col__4 THEN 1 ELSE 0 END)
OVER (ORDER BY CASE WHEN DT IS NULL THEN 1 ELSE 0 END, DT ASC) + 1 AS NoRisingDays
FROM (
SELECT s2.*, LAG(CL) OVER (ORDER BY CASE WHEN DT IS NULL THEN 1 ELSE 0 END, DT ASC) AS col__4
FROM s2
) sub__5
) s3
GROUP BY NoRisingDays
) s4
生成的 SQL 很深、很难 review、很难调试、也很难修改。但 SQLazy 的工作流非常容易阅读、review 和审计。只要这些步骤没问题,最终的 SQL 一定是准确的。
这就是 SQLazy 和普通 AI SQL 助手的本质区别:
普通 AI 生成 SQL |
SQLazy |
|
输入 |
自然语言需求 |
步骤化逻辑 |
输出 |
直接给最终 SQL |
先可执行步骤,再编译成 SQL |
调试 |
手动拆解,反复试错 |
单步执行,即时看到中间结果 |
可审计性 |
低(只能相信 AI 没犯错) |
高(每一步你亲眼验证) |
可维护性 |
低(SQL 难读,prompt 丢失) |
高(步骤即文档,随时可改) |
适用场景 |
一次性、探索性查询 |
需要长期使用、团队协作、合规审计 |
我现在用 SQLazy 跑复杂查询,说几点真实的体验。
好的地方:
每一步都看得见。以前写复杂 SQL,中间结果都是“脑子里想象的”。现在每一步执行完都能看到实际数据表,错了当场发现。那种“终于不用猜了”的感觉,很踏实。
逻辑变成步骤,天然就是文档。写完一个 workflow,如果三个月后需求变了,打开来看,不用重新分析几十行 SQL,直接改对应的步骤就行。同事接手的话,看步骤比读 SQL 快太多了。
调试效率大幅提升。有一次我在第 4 步的分组条件写错了,执行后看到中间表里多了一行不该有的数据,立刻定位到问题。以前遇到这种情况,我得把整个 SQL 跑一遍,然后到处加 debug 字段,再跑一遍……来回折腾。
跨数据库省心。同一个步骤逻辑,生成 MySQL 和 Oracle 的 SQL,不用手动改方言。
需要注意的:
学习成本。需要适应“步骤思维”,不能一上来就想写窗口函数。头两次用会觉得慢,但习惯后反而更清晰。
简单场景没必要。如果是三行就能写完的 SELECT,直接用 SQL 更快。SQLazy 适合的是你开始觉得脑子有点不够用的那种复杂场景。
不是万能的。注意不支持的功能和场景。
动手试试
Web 版(无需注册):https://sqlazy.com,免费使用,适合快速试验。
桌面 IDE:日常工作和处理大数据集时下载使用,无限本地调试。
仓库地址:
https://github.com/SPLWare/SQLazy
项目的 examples 目录里包含多个真实 SQL 问题的逐步求解过程,包括上面演示的“股票最长连续上涨天数”,以及会话分析、金融指标计算等场景。
安装包下载地址:
https://www.raqsoft.com.cn/download-NaturalSPL
哪里还不行?
递归查询还没做(在路线图上)。
非常老的数据库(比如 MySQL 5.5)不支持。
工具本身不是开源的,但所有示例 workflow 和文档都在 GitHub 上,MIT 协议。
希望得到的反馈
你有没有遇到过那种“用纯 SQL 写起来特别绕”的分析场景?我可以试着用 SQLazy 解一下,看是不是真的比纯 SQL 好读。
你现在用 AI 写 SQL 时,最大的痛点到底是什么?正确性、可维护性,还是信任问题?
对于“步骤式”的 SQL 开发方式,你最怀疑的地方是什么?


英文版