


当 AI 生成的 SQL 不再可信:如何重拾对数据的信心
一个正在蔓延的信任危机
把一个任务丢给 AI,几秒钟后它吐出一段几十行的 SQL。你复制粘贴,跑通了。但你心里真的踏实吗?
这恐怕是当今每个数据分析师和开发者的日常。
现代 AI 能生成可运行的 SQL。但问题是,你不知道能不能信任它。当查询涉及深层嵌套窗口函数和多层子查询时,这些代码变得难以 review、难以调试、难以维护、难以跨数据库移植。
更令人担忧的是,AI 的“幻觉”问题在 SQL 生成领域尤为突出。研究显示,当 LLM 缺乏足够的模式上下文和领域知识时,会表现出“臆想”性生成行为,不正确的数据库连接、错误的聚合逻辑、遗漏关键过滤器等。而根据 dbt 2026 年的基准测试,即使是最先进的大模型,在 Text2SQL 任务上的准确率也仅有 64.5%。这意味着,每三个由 AI 生成的 SQL 查询中,就有一个可能存在问题。
Stack Overflow 2025 年的一项调查揭示了一个更令人不安的事实:只有 2.7% 的专业开发者高度信任 AI 工具。而 42% 的提交代码已经是 AI 生成的,其中仅有 48% 经过了人工 review;GitHub 的最新统计描绘出一个危险的画面:AI 在飞快地生产代码,而人类在吃力地追赶验证的脚步。
这是 AI 的问题,还是方法论的问题?
仔细想想,问题的根源或许不在于 AI 本身,而在于我们让 AI 承担了它不擅长的事情。
AI 非常适合“头脑风暴”,帮你梳理思路、拆解复杂需求、探索多种可能的解决方案。但当涉及“精确执行”时,AI 的统计本质决定了它无法给出 100% 确定的答案。把最终代码的生成完全交给一个概率模型,这本身就是一种方法论上的错配。
Stack Overflow 的衰落从侧面印证了这个判断。这个曾经汇聚了全球开发者智慧的问答平台,新提问量从高峰期的每月 30 万 + 骤降至 2026 年 1 月的仅 2640 个。开发者们纷纷转向 AI 寻求快速答案,却发现得到的答案质量参差不齐,难以信任。
于是我们陷入了一个尴尬的境地:不用 AI,效率太低;用了 AI,又不敢完全相信。
有没有一种办法,能把 AI 的灵活性和人类的确定性需求结合起来?
SQLazy:让 AI 帮忙想,让编译器来写
这就是 SQLazy 发布的初衷:用自然语言分步实现复杂 SQL 的意图,再编译成可审计可生产的 SQL。
SQLazy 的核心思路很简单,却非常反主流:不要让 AI 直接生成最终的 SQL。由你自己或 AI 辅助把复杂需求拆解成一步步清晰的逻辑,然后交给一个确定性的编译器,由编译器生成最终的可执行 SQL。
这个模式用一个比喻理解会更清晰:AI 是你的“参谋”,帮你梳理战术思路;编译器是你的“工匠”,按照确定性的流程把战术转化为产品。你全程负责验证思路的正确性,而具体的执行细节交给机器——就像用计算器做算术一样,你只管输入正确的运算步骤,计算器保证输出正确的计算结果。
举个相邻分组计算的例子:
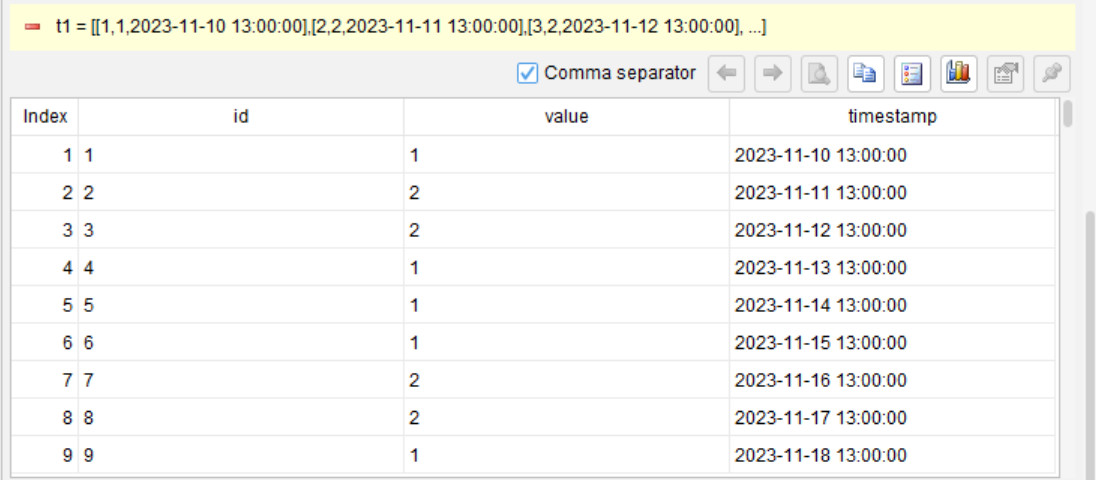
事件表按时间戳排序后,相邻的 value 字段有时连续相同。
id |
value |
timestamp |
1 |
1 |
2023-11-10 13:00:00 |
2 |
2 |
2023-11-11 13:00:00 |
3 |
2 |
2023-11-12 13:00:00 |
4 |
1 |
2023-11-13 13:00:00 |
5 |
1 |
2023-11-14 13:00:00 |
6 |
1 |
2023-11-15 13:00:00 |
7 |
2 |
2023-11-16 13:00:00 |
8 |
2 |
2023-11-17 13:00:00 |
9 |
1 |
2023-11-18 13:00:00 |
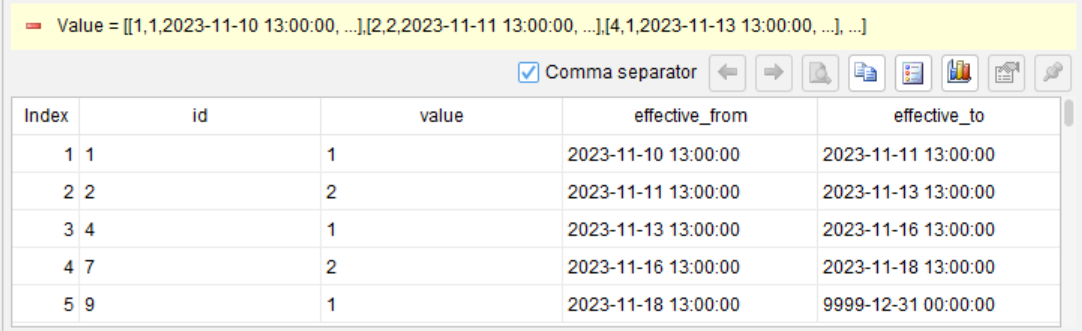
现在要将相邻的 value 相同的记录分为一组,取出本组的开始时刻和下一组的开始时刻,当做本组的起止时刻,组成新的二维表。最后一组的下一组的开始时刻约定为” 9999-12-31 00:00:00”。
id |
value |
effective_from |
effective_to |
1 |
1 |
2023-11-10 13:00:00 |
2023-11-11 13:00:00 |
2 |
2 |
2023-11-11 13:00:00 |
2023-11-13 13:00:00 |
4 |
1 |
2023-11-13 13:00:00 |
2023-11-16 13:00:00 |
7 |
2 |
2023-11-16 13:00:00 |
2023-11-18 13:00:00 |
9 |
1 |
2023-11-18 13:00:00 |
9999-12-31 00:00:00 |
SQL 并不好写,我们用 SQLazy 分步实现:
Name |
Anchor |
Statement |
t1 |
events |
sort timestamp |
t2 |
segment value; change; as gid |
|
t3 |
summarize timestamp first as effective_from, id first as id; group gid, value |
|
t4 |
compute nvl(effective_from[1],datetime("9999-12-31 00:00:00")) as effective_to |
|
derive delete gid |
第 1 步,按时间戳排序,确保数据按时间顺序处理
sort timestamp
第 2 步:相邻分组,标记组 ID
segment value; change; as gid
这是关键的一步。segment 用于分段:遍历数据,每当 value 字段的值发生变化时,就新开一个组。自动生成一个组号 gid。
执行后,中间表会多出一列 gid
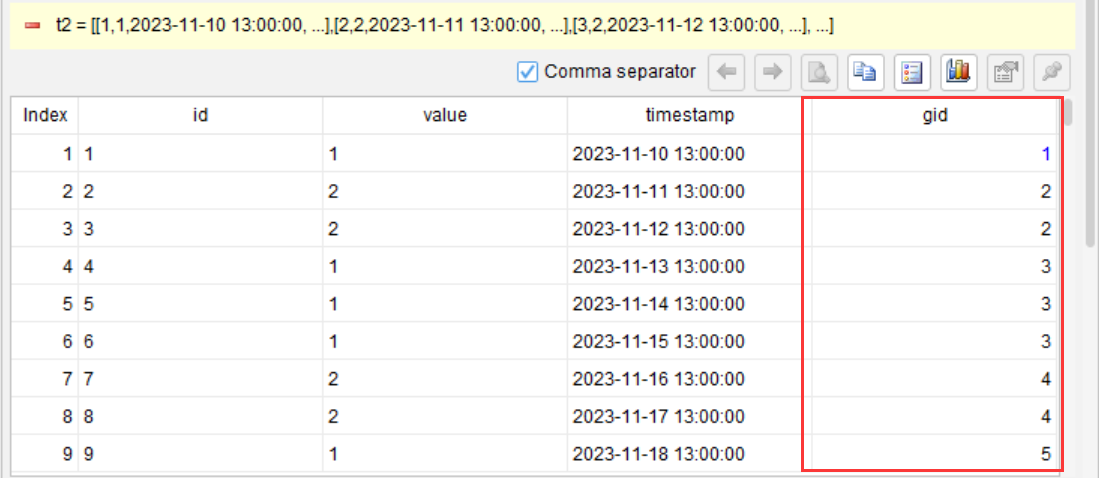
看到 gid 的变化了吗?value 从 1 变 2 → 新组;2 保持不变 → 同组;2 变 1 → 新组……
第 3 步:按组汇总,取每组的第一条记录
summarize timestamp first as effective_from, id first as id; group gid, value
对每个 gid(加上 value 是为了保留这个字段),取该组内最早的时间戳作为 effective_from,取第一个 id 作为组内代表 id(这里 id 是递增的,相当于取组内最小 id)
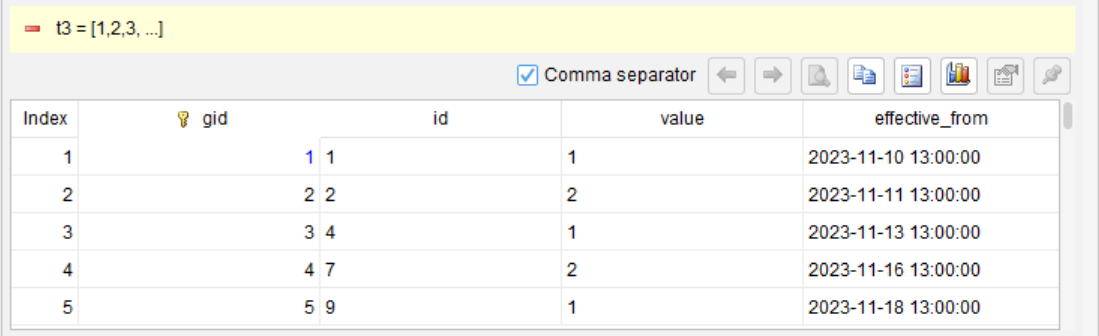
第 4 步:计算结束时刻(下一组的开始时刻)
compute nvl(effective_from[1],datetime("9999-12-31 00:00:00")) as effective_to
这里 effective_from[1] 表示“下一行的 effective_from 值”(类似 SQL 的 LEAD 函数)。nvl 处理最后一组没有下一行的情况,填上约定的最大日期。
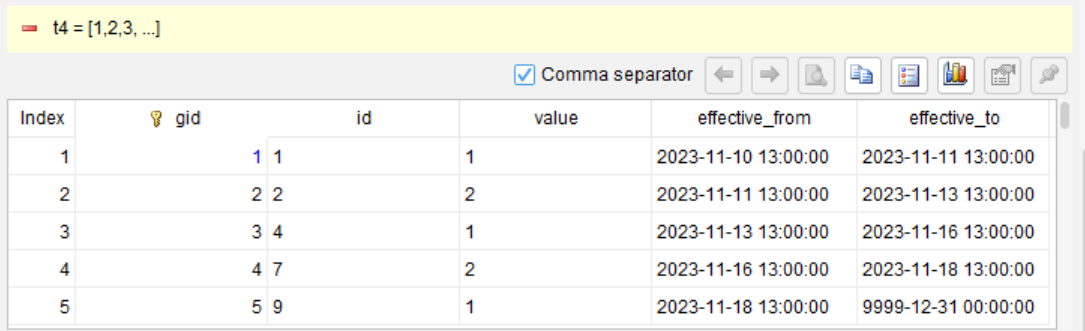
第 5 步:删除辅助列 gid
derive delete gid
这一步只是清理输出,去掉临时用的 gid 列,得到最终结果。
每个步骤和结果都确认正确后,编译生成目标 SQL(这里是 Oracle)。
WITH Value AS (
SELECT
id,
value,
timestamp
FROM
events
),
Value2 AS (
SELECT
gid,
id AS id,
value AS value,
timestamp AS effective_from
FROM
(
SELECT
id,
value,
timestamp,
SUM(
CASE
WHEN value <> col__5 THEN 1
ELSE 0
END
) OVER (
ORDER BY
CASE
WHEN timestamp IS NULL THEN 1
ELSE 0
END,
timestamp ASC
) + 1 AS gid
FROM
(
SELECT
Value.*,
LAG(value) OVER (
ORDER BY
CASE
WHEN timestamp IS NULL THEN 1
ELSE 0
END,
timestamp ASC
) AS col__5
FROM
Value
) sub__6
) Value1
GROUP BY
gid
)
SELECT
gid,
id,
value,
effective_from,
LEAD(
effective_from,
1,
TO_DATE('9999-12-31 00:00:00', 'YYYY-MM-DD HH24:MI:SS') OVER (
ORDER BY
gid
)
) AS effective_to
FROM
Value2
ORDER BY
gid
由编译器生成的最终 SQL,包含了嵌套窗口函数和子查询的复杂查询。但在 SQLazy 的框架下,你根本不需要去读那段 SQL,你只需要确认步骤逻辑正确,编译器就会保证最终输出的准确性。
这正是 SQLazy 区别于其它 AI SQL 工具的关键:
其它 AI SQL 工具 |
SQLazy |
|
输入 |
自然语言需求 |
步骤化逻辑 |
输出 |
直接给最终 SQL |
先可执行步骤,再编译成 SQL |
调试方式 |
手动拆解,反复试错 |
单步执行,即时查看中间结果 |
AI 角色 |
黑盒生成最终代码 |
辅助梳理思路,不参与最终代码生成 |
可审计性 |
低(只能相信 AI 没犯错) |
高(每一步可亲眼验证) |
可维护性 |
低(SQL 难读,原始 prompt 易丢失) |
高(步骤即是活的文档) |
跨数据库移植 |
可能张冠李戴搞错数据库种类 |
编译器自动生成可信的多方言 SQL |
是否产生幻觉 |
经常产生 |
最终 SQL 由编译器生成,完全没有幻觉 |
生成正确的复杂 SQL 并不是终点,SQLazy 还可以搞定下面这些难题:
1. Hard to review(难以审查)
一段 50 行的 SQL,嵌套了 4 层子查询和 3 个窗口函数,即使是有经验的开发者也很难在短时间内判断其逻辑是否正确。而 SQLazy 的步骤式表达,让审查变得极其简单:你只需要检查 5-7 个步骤的顺序和条件,每步的输入输出一目了然。业务人员甚至产品经理都能参与逻辑验证。
2. Hard to debug(难以调试)
传统 SQL 调试是一个“黑盒”体验:你只能看到最终结果,却看不到中间过程。哪一步错了?不知道。只能加 debug 字段、注释部分子查询、反复运行。SQLazy 允许你单步执行,每一步都能看到中间表。发现第 3 步的分组条件写错了,当场修正,后面步骤自动重算。调试时间从小时级降到分钟级。
3. Hard to maintain(难以维护)
三个月前写的复杂 SQL,今天需求变更了。你打开那个文件,盯着窗口函数发呆:“当初这个 LAG 是想干嘛?” 更糟糕的是,原始需求可能早就丢了。SQLazy 的步骤本身就是活文档,任何一个新人打开 workflow 都能在几分钟内理解逻辑。修改需求只需要调整对应的步骤,编译器重新生成 SQL。
4. Hard to port across databases(难以跨数据库移植)
从 Oracle 迁移到 PostgreSQL?原本用 DECODE 的地方要改 CASE,ROWNUM 要改 LIMIT,TO_DATE 格式还不一样。SQLazy 的编译器已经内置了 MySQL、PostgreSQL、Oracle 三种方言支持,Snowflake 和 BigQuery 也在路上。写一次步骤,生成多种 SQL,移植成本归零。
审计与合规:一个常被忽略的价值
对于金融、医疗、政府等强监管行业,数据查询的审计性是刚性需求。合规部门需要知道:这个报表的数字是怎么算出来的?谁写的逻辑?有没有经过验证?
常规 AI 生成的 SQL 根本无法回答这些问题。你只能展示一段代码,然后说“这是 ChatGPT 写的”。合规审查人员不会接受。
SQLazy 的步骤式 workflow 天然满足审计要求:
每一步都有清晰的描述
每一步的执行结果可以截图留档
编译器确定性的本质保证了“相同步骤→相同 SQL”
版本控制友好,workflow 文件可以像代码一样提交到 Git
这意味着,当监管问“为什么这个数据是 20% 而不是 30%”时,你可以给出一个可追溯、可解释、可复现的完整证据链。
SQLazy 的定位:解决哪类问题?
SQLazy 定位的是一类特定的 SQL 需求:复杂到让人头疼的“中重度”分析场景。比如:
连续趋势与涨跌期分析(如股票连续上涨天数)
事件序列与会话划分(用户行为路径分析)
动态条件分组(不同客户组采用不同聚合逻辑)
时间窗口分析(滚动统计与缺失值填充)
金融交易指标计算
SQLazy 的 GitHub 仓库 examples 目录中提供了大量这类场景的真实案例。
什么情况下不需要 SQLazy?
简单查询(3-5 行就能写完)
你已经非常擅长手写窗口函数且不需要他人 review
团队只有你一个人,且不要求文档和审计
在 AI 生成代码浪潮席卷一切的当下,SQLazy 的出现代表了一种不同的技术哲学。
它承认 AI 的效率优势,但不盲从。它坚持人类应当对最终产出负责,因此只把 AI 放在“参谋”的位置上,而不是“决策者”。它用编译器这个确定性工具,来弥补 AI 概率性输出的不足。用一个词来概括,就是:AI 辅助思路,编译器保证结果。
当然,SQLazy 目前还有不少可以改进的地方:桌面版和 Web 版虽然免费,但工具本身不是开源软件;部分高级功能还在开发中。不过,从长远来看,这种方法论可能比单纯的“用 AI 替代写 SQL”更有生命力。因为它解决的不只是写代码的效率问题,更是人类如何在 AI 时代保持对关键决策的控制权,以及如何建立可审计、可维护、可移植的数据资产体系。
与其盲目接受一个自己都看不懂的 SQL 黑盒,不如亲手把逻辑拆解成步骤,让编译器帮你完成最后的落地执行。SQLazy 让这个工作流变得可能。
在线体验:sqlazy.com(免费,无需注册)
安装包下载地址:https://www.raqsoft.com.cn/download-NaturalSPL


英文版