


智能问数(Text2SQL)工业级落地,纯AI黑盒都没戏
如果你关注智能问数(Text2SQL)这个领域,一定会发现一个奇怪的现象:各种文章、演讲、视频铺天盖地,厂商们纷纷宣称自己的方案达到了 90% 甚至 95% 的准确率。但你试着在网上找一个可以直接上手测试的公开 DEMO,却会发现几乎找不到。
做个 DEMO 的成本并不高,一个简单的网页加一个后台 API,对任何技术团队都不是难事。但为什么公开 DEMO 这么难找?真正的原因是:因为这些 Text2SQL 技术大都是黑盒方案,而黑盒方案是经不起随意测试的,AI 冷不防就会给一个离谱的错误答案,然后当场社死。
这不是某个厂商的问题,而是所有纯 AI 黑盒方案的宿命。
黑盒方案的困境:不稳定的“90%”,企业承受不起
当前绝大多数的 Text2SQL 方案,无论包装得多华丽,本质上都是黑盒方案。可以分成两类:
早期:AI 直接生成 SQL。用户输入一句话,大模型直接输出 SQL 语句。这类方案最“纯粹”,也最不可控。幻觉、语法错误、表名猜错、JOIN 乱连,你能想到的错误它都会犯。
后来:AI 先生成中间层,再转 SQL。先让 AI 把口语转成某种结构化的中间表示(比如 JSON、自定义 DSL),然后再由程序转成 SQL。相比直接生成 SQL,中间层降低了一点复杂性,准确率有一定提升。
这些过程中可能还会增加 RAG 知识库机制,但无论多精细的提示词、多完善的向量库,最后的关键步骤,仍然是 AI 做的。AI 一天不解决幻觉问题,这个步骤就不可能 100% 可靠。这些手段都只能减少幻觉,不能根除幻觉。
学术界的研究已经给出了令人警惕的证据。在真实企业数据环境下的 Spider 2.0 基准测试中,曾在 Spider 1.0 上达到 86% 准确率的 GPT-4o,在 Spider 2.0 上的整体成功率骤降至6%;o1-preview 从 91.2% 跌至 21.3%。这中间的断崖,就是学术测试与企业真实需求之间的鸿沟。更严重的是,连基准本身都靠不住了。2026 年 1 月的研究发现,BIRD Mini-Dev 的注释错误率高达52.8%,Spider 2.0-Snow 的错误率高达62.8%。在这种情况下讨论“准确率”,连分母都站不稳。
而且问题远不止是数值差异。即使系统在 90% 的情况下输出正确 SQL,剩下 10% 的错误也足以摧毁企业对整个系统的信任。当关键业务决策依赖于数据查询结果时,“这次可能是错的”这个不确定性本身就是不可接受的。
根本的问题,在于执行链条的黑盒性。用户输入一句话,然后得到一个结果,中间过程全黑。大模型匹配了哪些表和列?它为什么这样选择 JOIN 路径?它理解的过滤逻辑与用户意图是否一致?这一切都无法追溯。当结果可疑时,面对技术人员,还可以把 SQL 抛出来确认(虽然也很费劲),但 Text2SQL 的用户往往是看不懂 SQL 的业务人员,给了 SQL 也是白搭。中间层方案也是一样,只是把 SQL 换成 JSON 或 DSL 之类的东西,该看不懂还是看不懂。连问题出在哪里都无从知晓,更不用说指导系统改进了。
所以,黑盒方案的困境是结构性的:关键决策点依赖概率模型,输出不确定,无法审计,无法解释。企业级应用需要的是稳定、可重现、可解释,黑盒方案做不到。
白盒方案的根本区别:把 AI 关进笼子,留出人类审核位
要解决黑盒的问题,不能指望 AI 突然变得完美,而是要在系统设计上承认 AI 的局限,并把它约束在一个可控的范围内。
白盒方案的核心原则有两条:
必须有一个人类可读、可确认的中间层。AI 只负责把口语翻译成这个中间层,然后必须经过人(或业务专家)确认,才能进入下一步。
从中间层到 SQL 的执行,必须用确定的规则编译,不能用 AI。这样才能保证后续环节 100% 准确。
这就是所谓的自然语言对抗自然语言,用人类能看懂的中介语言,把 AI 的不确定性挡在确认环节之前。确认之后,就是纯规则的确定性编译,没有幻觉,没有猜测。
润乾 NLQ走的正是这条白盒路线。它的中间层叫做规范文本,是一种介于口语和 SQL 之间的结构化表达。例如:
用户口语:帮我查一下去年北京发往青岛的订单
规范文本:去年 北京 发往 青岛 订单
规范文本支持动词表达,这句话的完整语义是:去年 发货 城市 北京 收货 城市 青岛 订单。人眼一看就能理解,用户确认“对,我就是这个意思”之后,系统再用规则引擎将规范文本确定性地编译成 MQL,再转成 SQL 执行。整个过程,从规范文本到 SQL 这一段,100% 准确,不存在“这次对下次错”。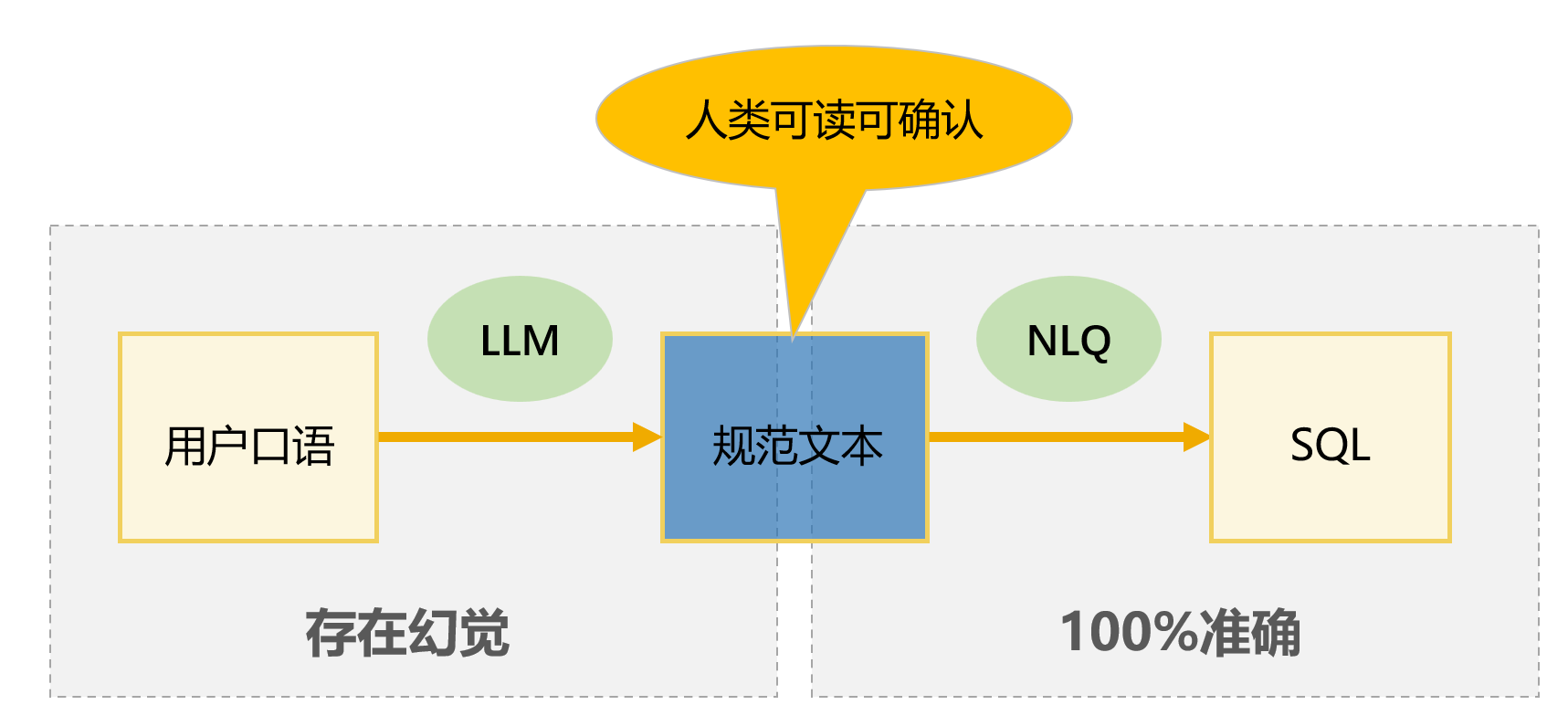
这样润乾 NLQ 就能放出公开 DEMO 了(http://query.raqsoft.com.cn:6999/nlq.html):它可能有查不出来而拒绝的问句,但只要用户确认了规范文本,返回结果就是对的。既使程序有 BUG 偶而出错,也可以追踪调试解决掉,错误会收敛得越来越少。
比如我们使用 DEMO 直接查询:
商品名称 ‘龙虾’ 且 库存量小于50 商品 编码 名称 单价
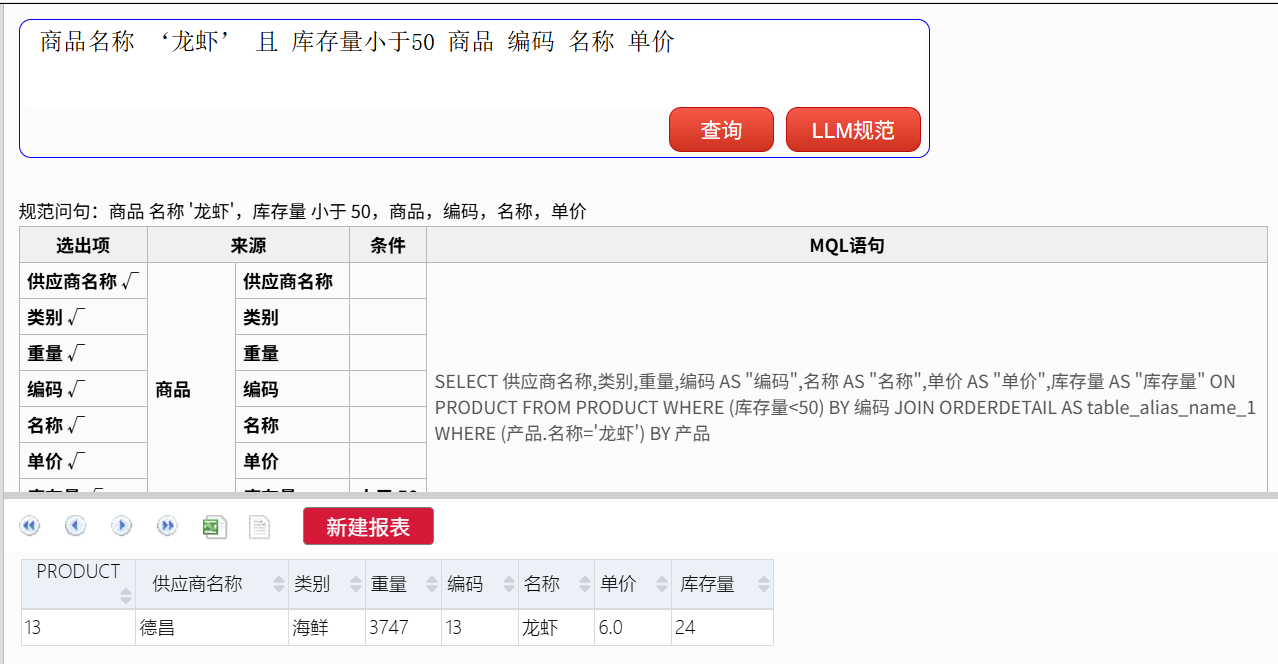
这个规范文本表达了包含了过多个条件的明细查询。
再查询:
2025年 金额最大10 订单
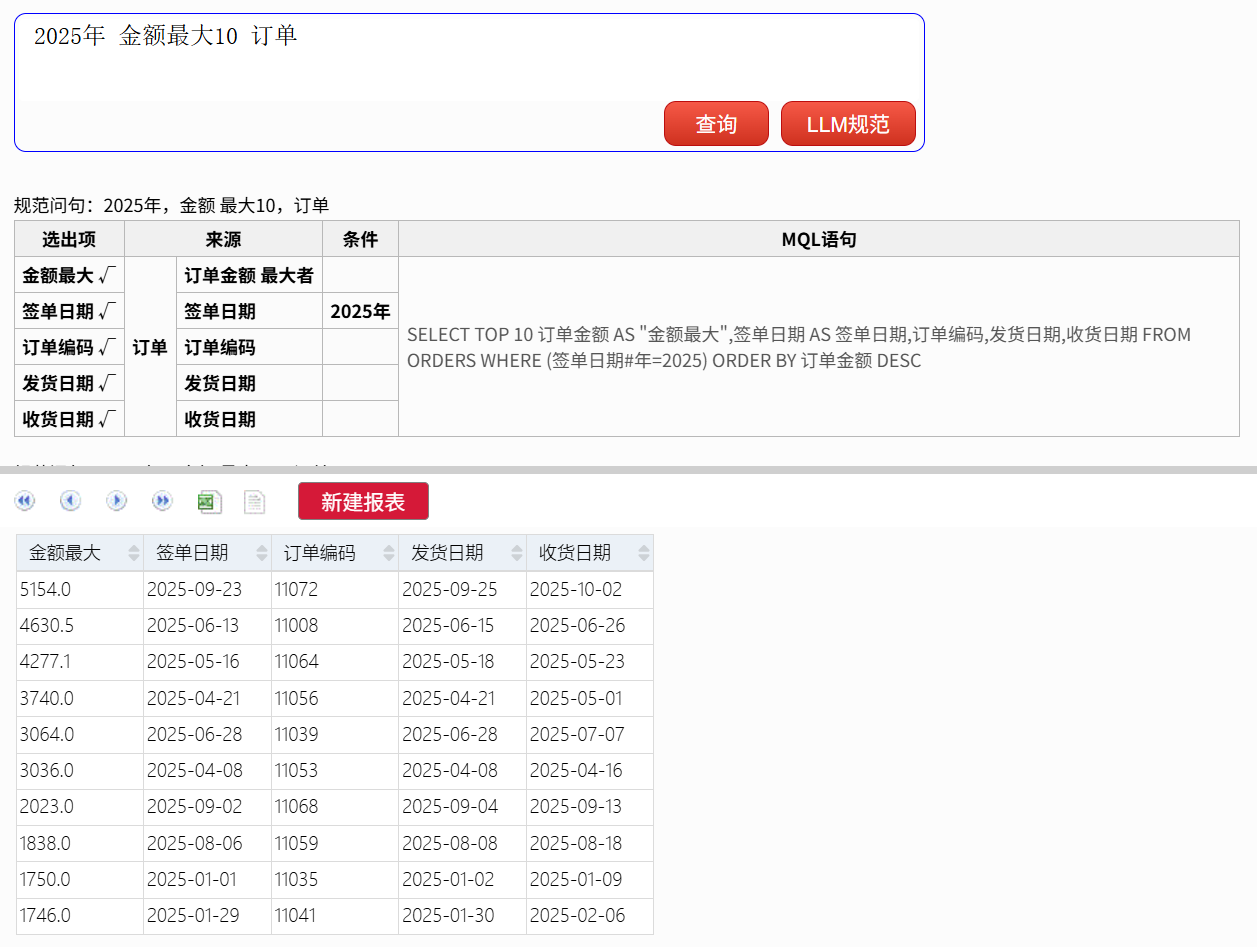
这种单表聚合(TopN)类查询用规范文本也能轻松表达。
还有像这种涉及多表关联、带有聚合后过滤的查询:
去年 北京发货 订单数 大于1 客户信息
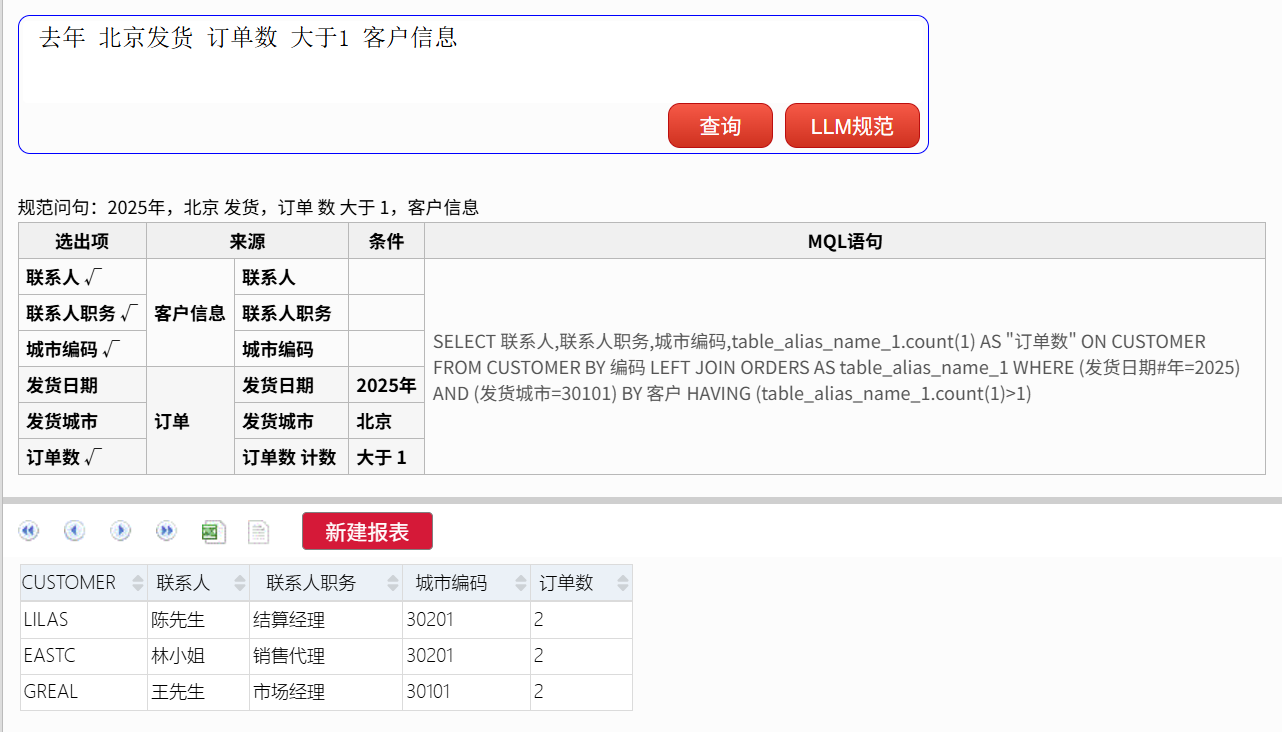
当然,有一些口语化的表达(非规范文本)直接无法查询,比如:
我需要查询商品表中单价在9块五毛钱到等于12块钱的
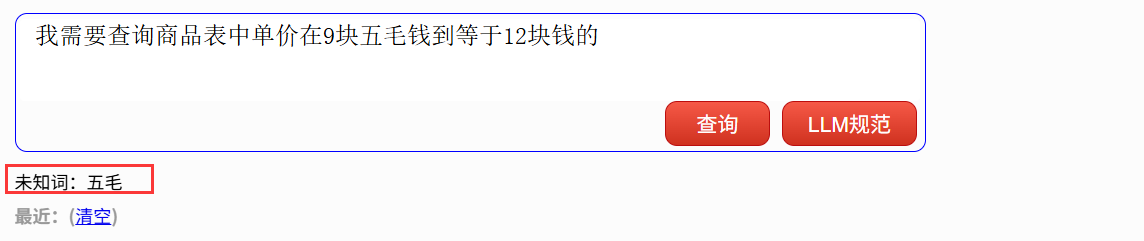
这时需要改成规范文本再查,或者在 DEMO 中提供了“LLM 规范”功能,可以借助大模型将口语翻译成规范文本。
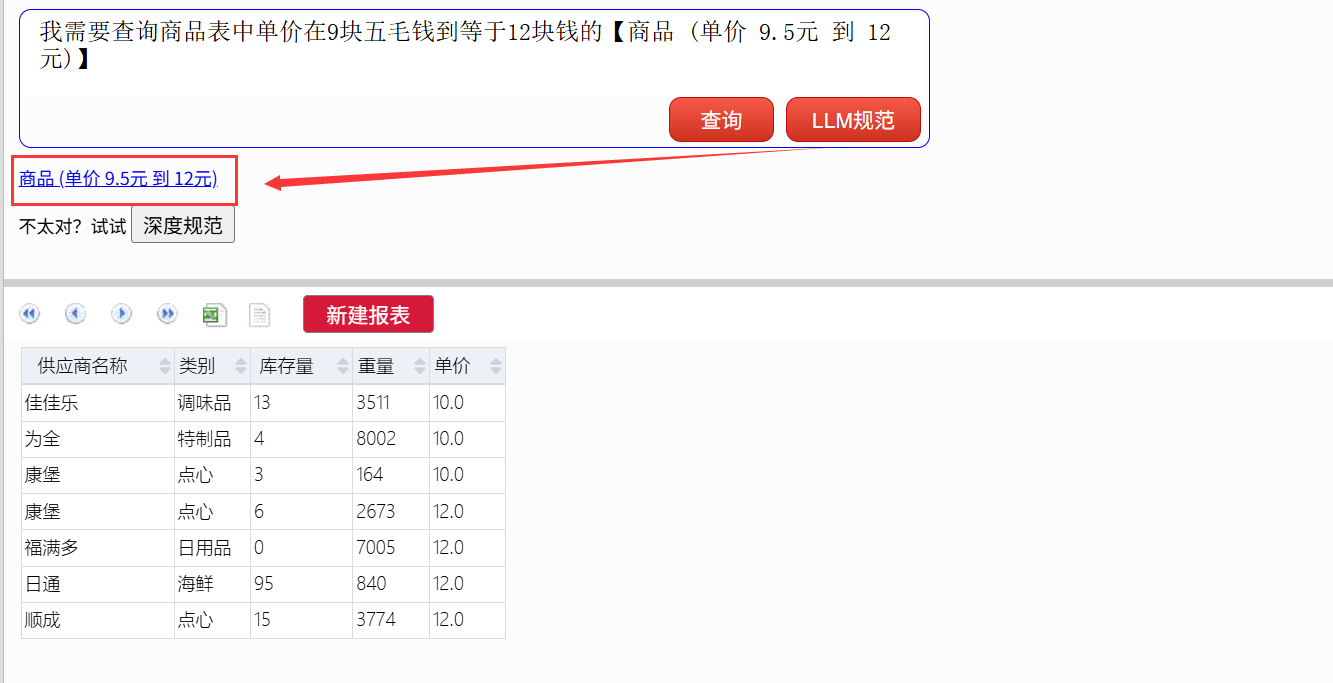
DEMO 还提供了“深度规范”,如果初次转换结果不满意(毕竟 LLM 有幻觉),尝试深度规范还可以更精准地进行转换。
白盒方案的挑战:通过率
那么,纯 AI 方案是不是也能做出类似的“人类确认”机制呢?如果生成的中间层或 SQL 足够简单,简单到业务人员能读懂,那确实可以确认。但这就引出了另一个问题:中间层太简单,能表达的查询范围就严重缩水,通过率会很低。如果中间层设计得较复杂又会导致业务人员无法确认。
有人可能会想:让 AI 先把中间层“翻译”成一段自然语言描述,让用户确认这段描述,然后再执行。但这不是并白盒方案,因为那段用于确认的自然语言仍然是 AI 生成的,它可能与中间层实际逻辑不一致,用户确认了也只是确认了 AI 的描述,而不是确认了将要执行的逻辑,幻觉只是换了个位置,并没有被消除。
白盒方案的核心是:用于确认的文本本身也必须是由规则引擎生成的,或者其本身就是人类可读的确定性表达,并且确认后的执行路径全部是确定性的。润乾 NLQ 直接用规范文本作为中间层,它既是规则引擎的输入,又是人类可直接确认的自然语言,一举两得。
目前规范文本设计得已经足够丰富,支持四种查询范式(单表明细、单表聚合、主子实体、多维对齐汇总),配合词典中的字段词、实体、宏词、动词、指标等配置,能够覆盖 BI 场景中绝大部分的查询需求。这不是一个拍脑袋的简单格式,而是一个经过实践检验的、足够复杂又保持人机可读的中间语言。
可以查询示例来感受规范文本的能力:
一、单表明细
1. 零售价 包装方式 零件
2. 所在国家 中国 客户 名称 账户余额
3. 去年 订单
4. 零售价 小于 50元 零件
5. 订单状态 未完成 订单
6. 市场细分 汽车 客户
7. 区域 欧洲 供应商
8. 零件编号 名称 品牌 零件
9. 今年 3月 订单
10. 发货日期 等于 上周一 订单明细
11. 实际到货日期 大于 承诺到货日期 订单明细
12. 账户余额 大于 10000元 客户
13. 品牌 "Brand#" 开头 零件
14. 零售价 100元 到 200元 零件
15. 名称 联系电话 供应商
二、单表聚合
16. 平均 零售价
17. 上个月 客户 订单总金额 总和
18. 订单总金额 最大的5个 订单
19. 品牌 零件 数
20. 国家 客户 数
21. 所在国家 中国 客户 账户余额 总和
22. 最小 订单总金额 最大 订单总金额 平均 订单总金额
23. 订单日期 最早
24. 零件类型 零售价 最大
三、主子实体
25. 客户 订单 数
26. 没有 订单 客户
27. 客户 零件 大型抛光钢
28. 去年 有 订单 客户
29. 供应商 零件 数
30. 订单总金额 总和 大于 100000 客户
31. 上个月 没有 订单 客户
32. 零件 客户 数
33. 有 已退货明细 订单
34. 订单状态 未完成 客户 订单 数
四、多维对齐汇总
35. 国家 客户 数,供应商 数
36. 订单优先级 (已完成 订单 数) (未完成 订单 数)
37. 品牌 零件 数,供应商 数
38. 行业 (客户 数) (订单总金额 总和)
39. 年 区域 订单总金额 总和
更详细地讨论通过率,需要区分两种情况:
如果不接 LLM:用户必须自己会写规范文本。虽然规范文本覆盖的查询能力很强(单表明细、单表聚合、主子实体、多维对齐汇总,BI 能做的它几乎全能做),但业务用户需要学习这套规则。单纯的口语化输入,比如“上个月没有签单的客户是谁”,不接 LLM 就直接返回不认识,口语通过率会很拉垮。
这里有个用 NLQ 做的 A 股查询界面 https://q.aiqt.cc,没有接入 LLM,可以感受一下。
如果接 LLM:润乾 NLQ 允许接入任意大模型,把口语问题先转成规范文本,再走规则引擎。实测配合一个好用的 LLM(比如 DeepSeek),绝大部分日常问法都能顺利通过,口语通过率大幅提升。
不管接不介入 LLM,润乾 NLQ 都保留了兜底的确定性。LLM 只是帮你把口语转成规范文本的翻译工具(或者直接人工书写)。一旦规范文本被确认并交给规则引擎,后面仍然是确定性执行。大模型在这里扮演的角色是翻译,不是决策者。
即使如此,仍然会有一些查询是 NLQ 的规范文本描述不了的。比如“按订单金额从高到低排序”。NLQ 的处理方案是在查询结果界面上点击列标题就能排序,可以支持多字段、升降序。排序并不是能力问题,用自然语言描述排序其实很别扭:“先按金额降序,金额相同的再按订单日期升序”,写出来比点鼠标复杂得多。对于这种操作,界面交互比自然语言更高效。
类似的还有跨行组(环比、同比、累计、占比、排名等)这类复杂运算,可能涉及不同层次范围,生成 SQL 时还会用到繁琐且兼容性不好的窗口函数,直接在 NLQ 里处理,不仅用户描述不便,生成的难度也很高。对于这种情况,润乾 NLQ 的解决方案不是硬撑,而是承认边界,补上 NLR(自然语言报表)。
比如要计算每个月的销售额增长率,可以先用 NLQ 查出结果集。然后在 NLR 里通过汉语命令计算增长率:
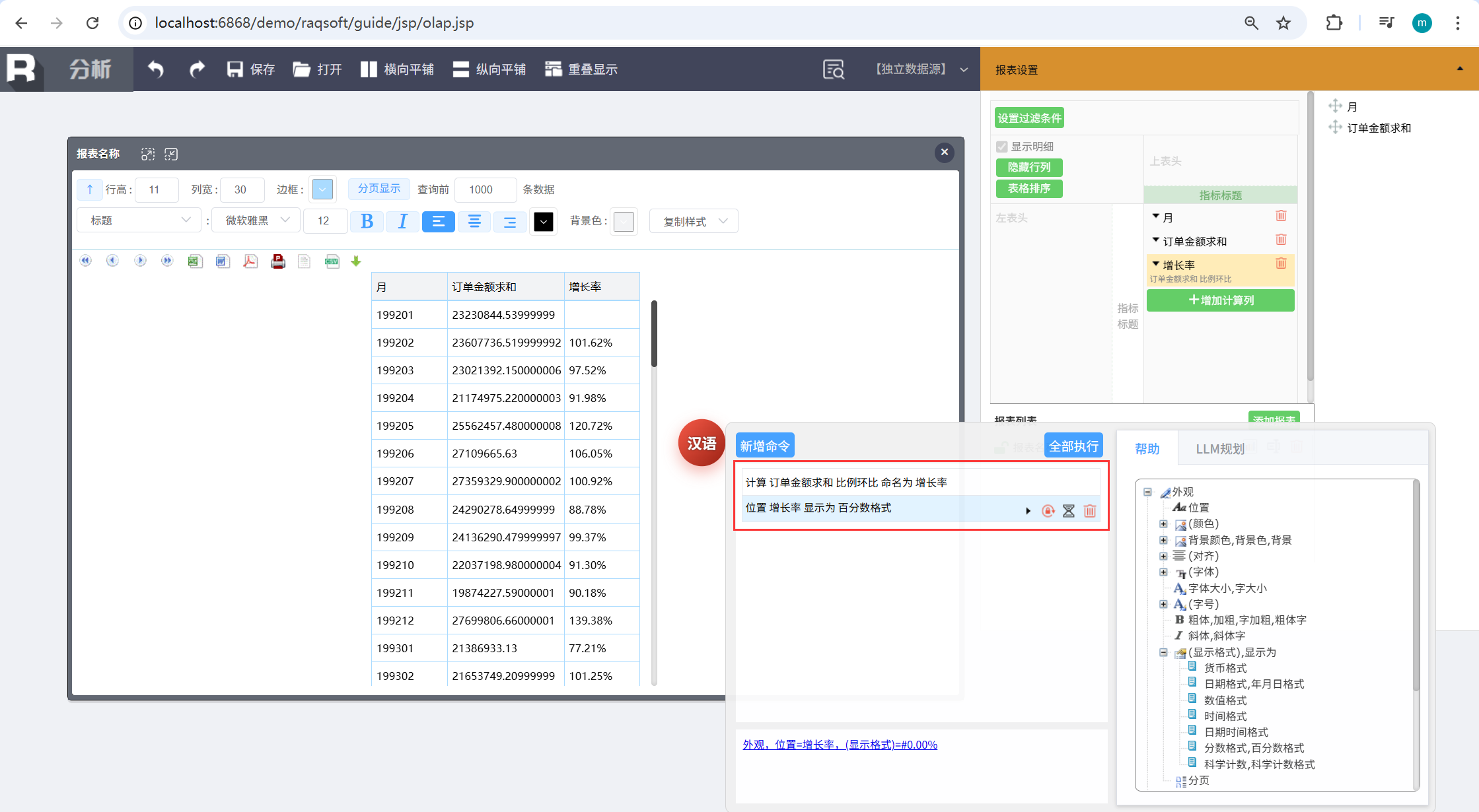
输入两条汉语命令就能搞定:
计算 订单金额求和 比例环比 命名为 增长率位置 增长率 显示为 百分数格式
NLQ 负责把数据查出来,NLR 负责在结果集上继续用汉语做加工:计算环比、排名、设置格式、生成图表。再加上界面排序等辅助功能,查询→分析→展示形成一个完整的闭环。
只有采用白盒机制,加入人类确认环节后,Text2SQL 才能真正实现工业级落地。不是靠吹牛说 100%,而是靠设计上的确定性保证准确,靠规范文本的复杂性来保证通过率。
润乾 NLQ 并不比别人的 AI 更聪明,而是它不把命运交给 AI。白盒方案的本质是用确定性规则兜底,把 AI 的不确定性限制在人类可确认的范围内。这条路看起来没有黑盒方案那么“智能”,但在企业级落地上,这大概是唯一走得通的路。

