


准确率 100% 的智能问数(Text2SQL)实践,还要关心什么指标?
先别急着批评我在吹牛。这个标题里的“准确率 100%”不是营销话术,而是严谨的技术事实,只不过它和你脑子里马上冒出来的那个“大模型直接写 SQL”的准确率并不完全是一回事。
准确率一直是 Text2SQL 领域的重要指标,经常有人喊能做到 90% 甚至 95%,但从不提分母是什么,也就没什么意义。AI 写 SQL 的正确率和限定范围相关性很强:限制得狠一点(比如就一张 BI 大宽表),到 90% 确实没问题;一旦涉及多表 JOIN,就会锐降到 50%-60%;再要多几层子查询,那就更惨不忍睹。
而且问题不仅在于数值高低,而在于它不稳定:今天对,明天错;这个写法对,换个说法就错。你永远不知道下一次它会不会翻车。对产品团队而言,概率系统的“准确率”是一道统计学题目,不是能承诺的指标。企业分析决策场景里,信任坍塌只需要一次错误结果。
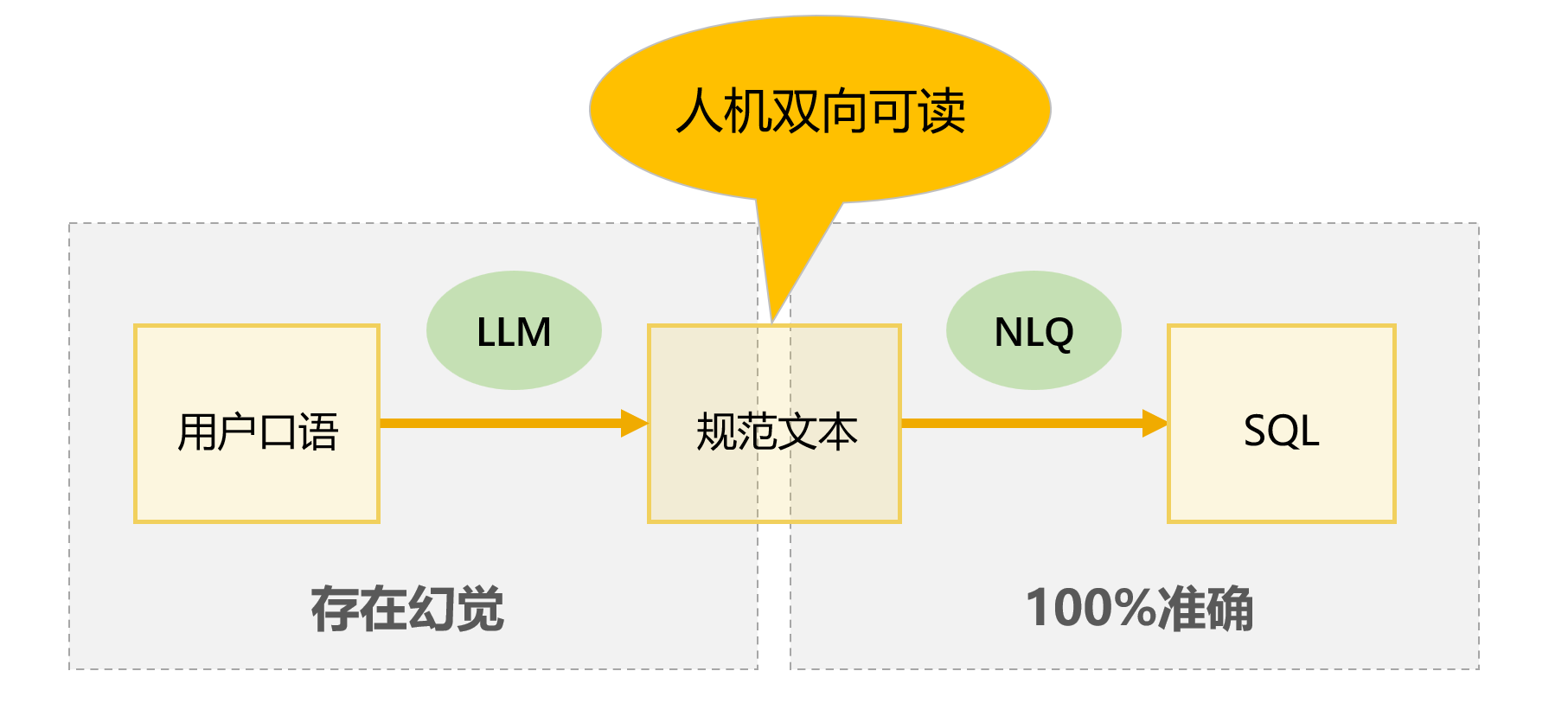
润乾 NLQ走了一条完全不同的路线:不是让大模型去“猜”SQL,而是让大模型(或者用户自己)先把口语问题转成规范文本,然后用规则引擎确定性地编译成 SQL 去执行。
规范文本长什么样?举个例子:
用户口语:帮我查查去年上半年签单的客户有哪些
规范文本:去年 上半年 签单 客户
规范文本是人机都能看懂的中介语言。一旦规范文本被确认(无论用户自己写,还是大模型帮忙转),后面就是确定的、可验证的、100% 可重复的。没有概率,没有“黑箱”,没有“这次对下次错”。
“准确率 100%”的真实含义是指,从规范文本到 SQL 这一段是稳定的 100% 准确。就像用 Excel 的 VLOOKUP 查一个值,查到了就是查到了,查不到就是查不到,不会因为今天是晴天就换个匹配规则。润乾 NLQ 原理一样:规则编译,不是概率猜测。
这里的关键在于:我们要认可 LLM 的不稳定不可克服,我们能做的不是在它身上赌一把,而是在流程中把它约束在“人类可确认”之前。规范文本确认这一步,就是最可靠的质量防火墙。业界其他方案往往让 LLM 一步到位生成 SQL,即使事后用 LLM 倒回来解释 SQL,仍然逃不掉幻觉。润乾 NLQ 把确认环节之后的所有步骤都变成了稳定的编译过程,这是根本的不同。
实践 TPCH
拿 TPCH 数据集做了一次实践。8 张表,9 个外键关联,数据量从几十条到十几万条,典型的企业级场景。
DQL 元数据:多表关联是 Text2SQL 最大的陷阱,LLM 处理 JOIN 经常出错。润乾 NLQ 用 DQL 语义层把表间关系(主键、外键、假表、日期层次)提前描述清楚,查询时不再需要手动写 JOIN 条件。
NLQ 词典:这是最大的工作量,但确定且可控。词典包括字段词、实体、常数词、量纲、宏词、字段簇、动词、指标等配置项。
LLM 规范:词典建好后,还可以配置 LLM 来把口语转成规范文本,大幅提升灵活性。
验证:润乾 NLQ 提供了可视化的查询实验功能,每配完一部分就可以跑验证,边配边测,问题定位直观。
详细的实践过程请参考: 润乾 NLQ 实践(TPCH 主题)
NLQ 实践下来的一些体会:
技术门槛不算高:普通数据库工程师就能完成,不需要 AI 专家、不需要 GPU 服务器。词典设计器提供了导入元数据、一键加载常数词、可视化编辑等完整工具链。
还是有实施周期:建设词典反反复复需要四五天,不太熟悉可能要两周,目前还做不到开箱即用。
可跟踪可改进:发现有不对的查询,可以修改词典后再补充,结果确定可控。
相比之下,业界常见的 AI 微调及 RAG 方案门槛和成本反而要高得多得多。不仅需要专门的 AI 工程师,准备例句、切割文本这些事正常情况一两个月都干不完。而且,所谓“准确率 90%”的说法也不能落地,因为你不知道那 10% 的失败会在什么时候、以什么方式出现。更麻烦的是,每一轮调优都要重新测试这个不稳定概率,没完没了!每次微调模型、调整提示词之后,之前能正确回答的问题可能又答错了。如果业务系统里跑着 100 个查询,每次改完都要重新跑一遍“回归测试”,那这个项目就没法上线交付。相比之下,润乾 NLQ 虽然仍有一定的实施工作,但已经是成本最低的方案了,而且可改进性可以保证不走回头路,持续优化。
100% 的准确率
来验证一下这个“准确率”。碍于篇幅,只能挑几个详细列出来。
想查询中国客户的信息,输入:
中国 客户 名称 账户余额
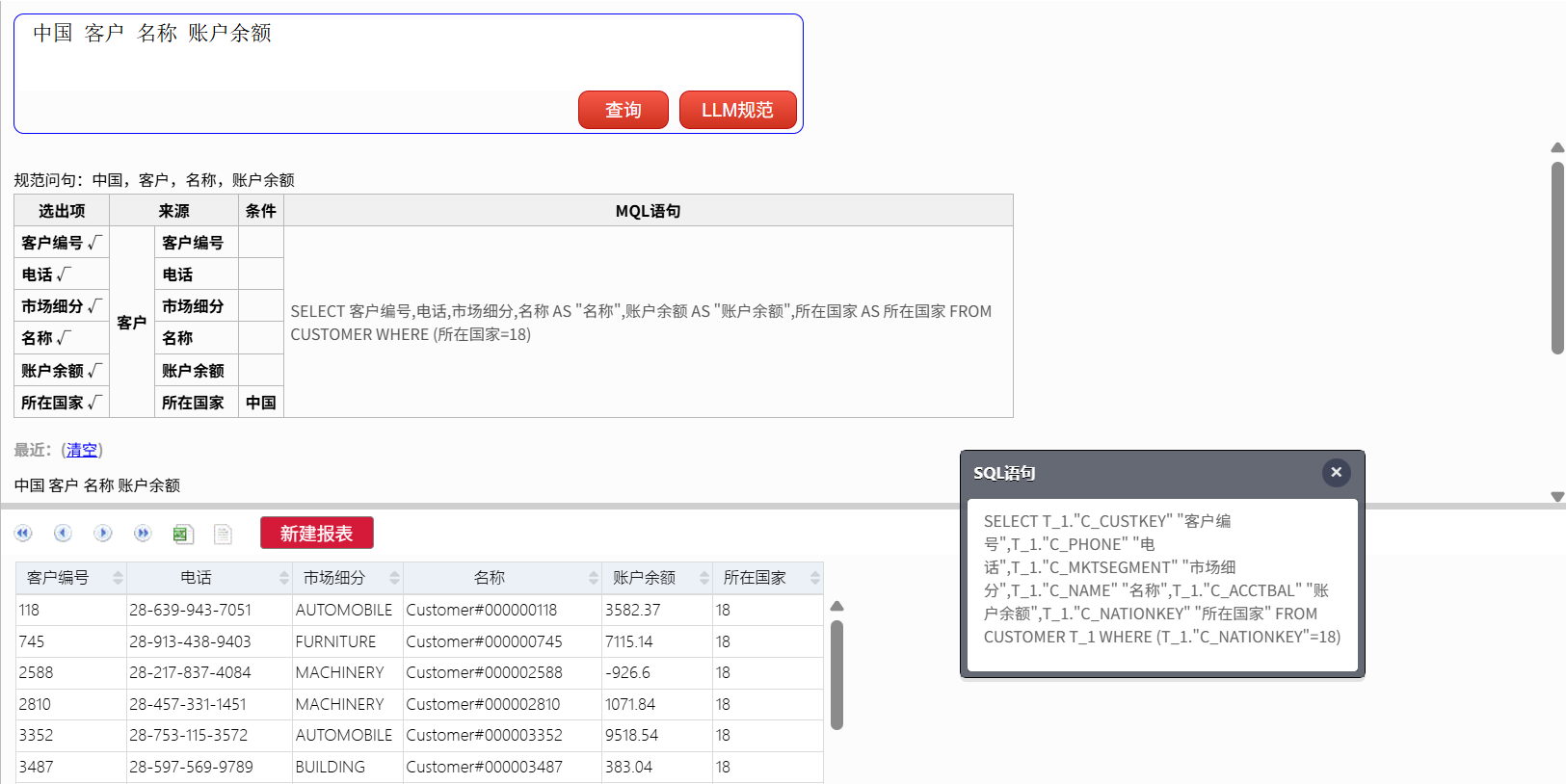
SQL:
SELECT
T_1."C_CUSTKEY" "客户编号",
T_1."C_PHONE" "电话",
T_1."C_MKTSEGMENT" "市场细分",
T_1."C_NAME" "名称",
T_1."C_ACCTBAL" "账户余额",
T_1."C_NATIONKEY" "所在国家"
FROM
CUSTOMER T_1
WHERE
(T_1."C_NATIONKEY" = 18)
这是一个单表过滤查询,还算简单。
再查:
订单总金额 最大的3个 订单
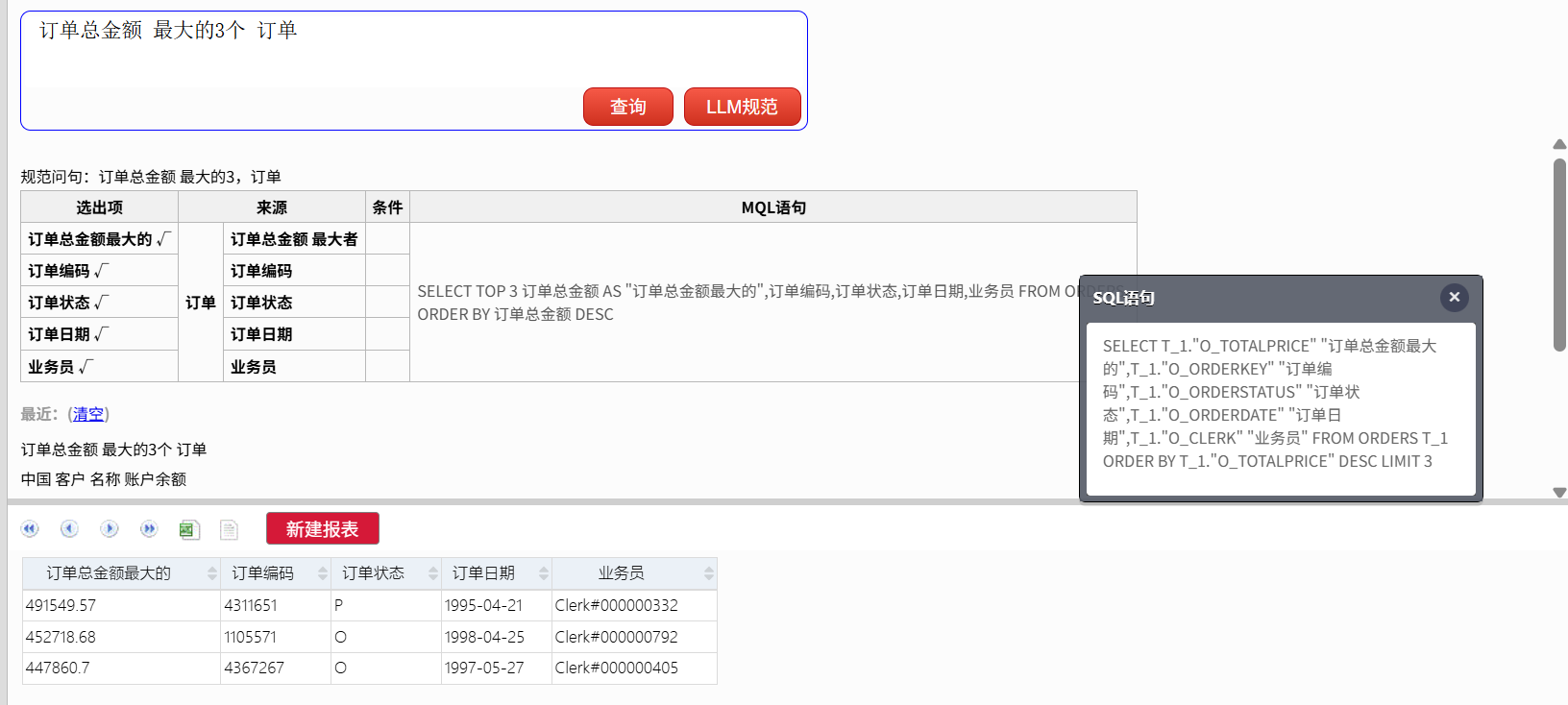
SQL:
SELECT
T_1."O_TOTALPRICE" "订单总金额最大的",
T_1."O_ORDERKEY" "订单编码",
T_1."O_ORDERSTATUS" "订单状态",
T_1."O_ORDERDATE" "订单日期",
T_1."O_CLERK" "业务员"
FROM
ORDERS T_1
ORDER BY
T_1."O_TOTALPRICE" DESC
LIMIT 3
仍然是基于单表,但已经能表达 TOP 类查询了。
再查:
中国 去年 订单总金额 总和 大于 100000 客户
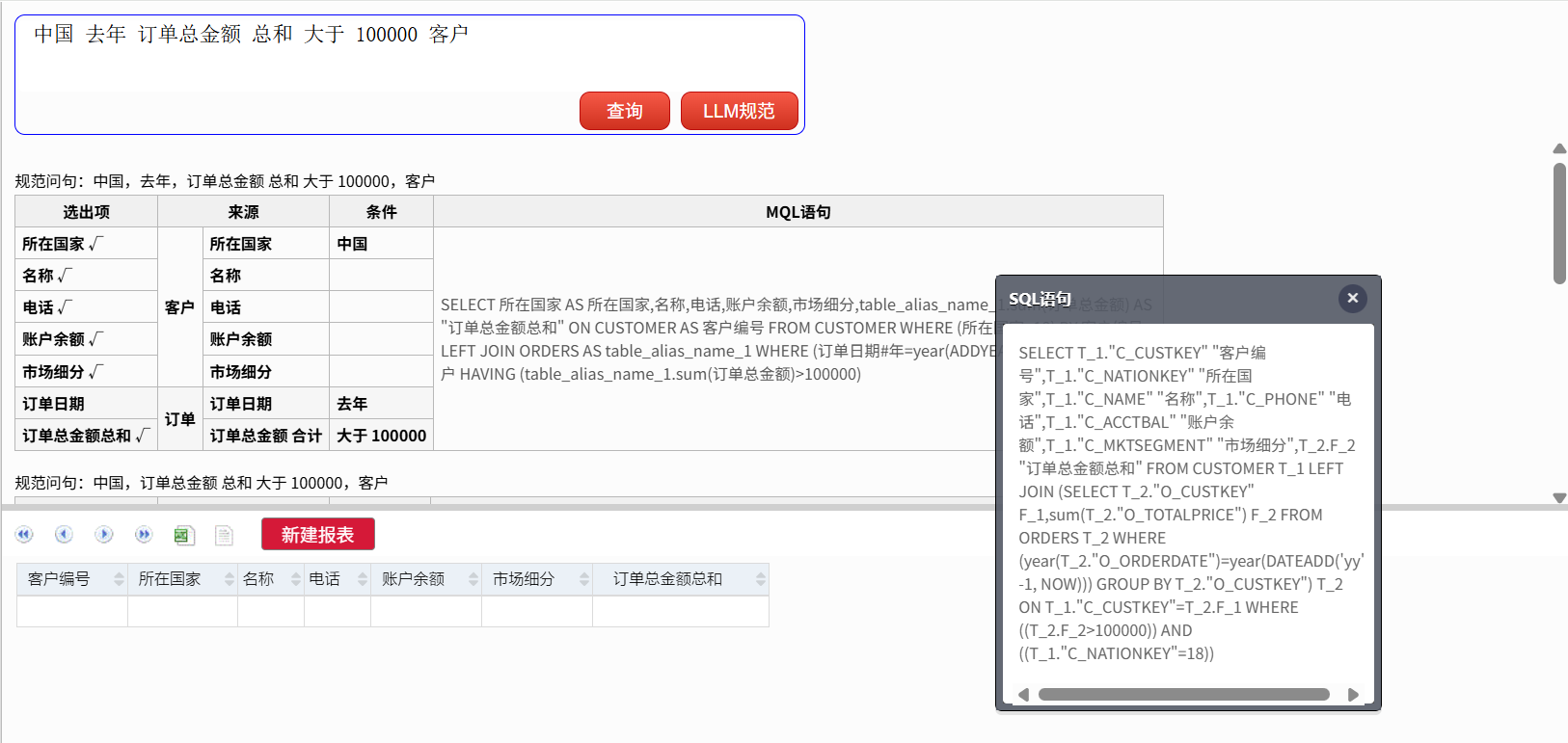
SQL:
SELECT
T_1."C_CUSTKEY" "客户编号",
T_1."C_NATIONKEY" "所在国家",
T_1."C_NAME" "名称",
T_1."C_PHONE" "电话",
T_1."C_ACCTBAL" "账户余额",
T_1."C_MKTSEGMENT" "市场细分",
T_2.F_2 "订单总金额总和"
FROM
CUSTOMER T_1
LEFT JOIN (
SELECT
T_2."O_CUSTKEY" F_1,
sum(T_2."O_TOTALPRICE") F_2
FROM
ORDERS T_2
WHERE
(YEAR(T_2."O_ORDERDATE")= YEAR(DATEADD('yy',
-1,
NOW)))
GROUP BY
T_2."O_CUSTKEY") T_2 ON
T_1."C_CUSTKEY" = T_2.F_1
WHERE
((T_2.F_2>100000))
AND ((T_1."C_NATIONKEY" = 18))
这个查询就比较复杂了,要关联多个表,有子查询,还包括聚合后过滤。
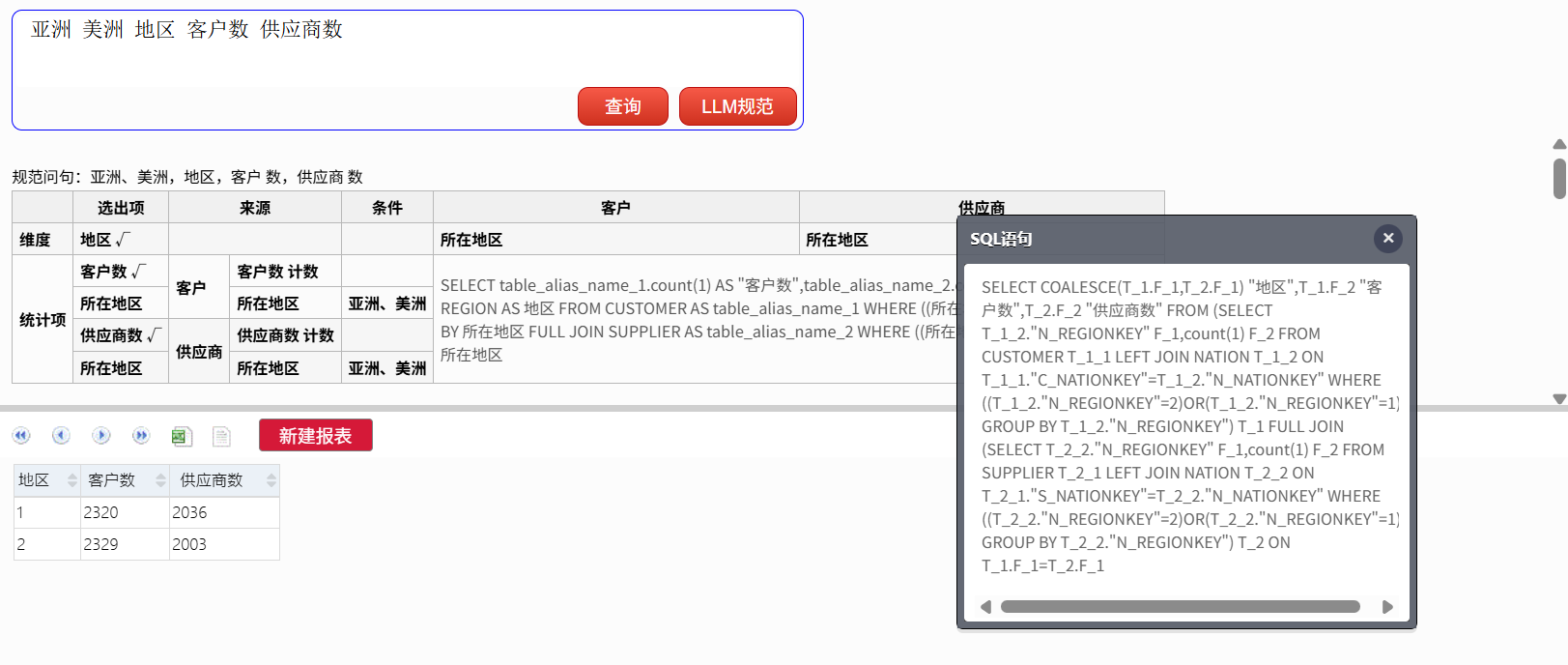
想看看亚洲和美洲地区的客户数和供应商数,查询:
亚洲 美洲 地区 客户数 供应商数
SQL:
SELECT
COALESCE(T_1.F_1,
T_2.F_1) "地区",
T_1.F_2 "客户数",
T_2.F_2 "供应商数"
FROM
(
SELECT
T_1_2."N_REGIONKEY" F_1,
count(1) F_2
FROM
CUSTOMER T_1_1
LEFT JOIN NATION T_1_2 ON
T_1_1."C_NATIONKEY" = T_1_2."N_NATIONKEY"
WHERE
((T_1_2."N_REGIONKEY" = 2)
OR(T_1_2."N_REGIONKEY" = 1))
GROUP BY
T_1_2."N_REGIONKEY") T_1
FULL JOIN (
SELECT
T_2_2."N_REGIONKEY" F_1,
count(1) F_2
FROM
SUPPLIER T_2_1
LEFT JOIN NATION T_2_2 ON
T_2_1."S_NATIONKEY" = T_2_2."N_NATIONKEY"
WHERE
((T_2_2."N_REGIONKEY" = 2)
OR(T_2_2."N_REGIONKEY" = 1))
GROUP BY
T_2_2."N_REGIONKEY") T_2 ON
T_1.F_1 = T_2.F_1
这个 SQL 不仅涉及多个表,多层嵌套带 JOIN 的 SQL 都能跑对。
再查询:
上个月没有签单的客户

这个口语化的查询不能执行,并且给出了原因。
我们借助 LLM 将查询规范一下:
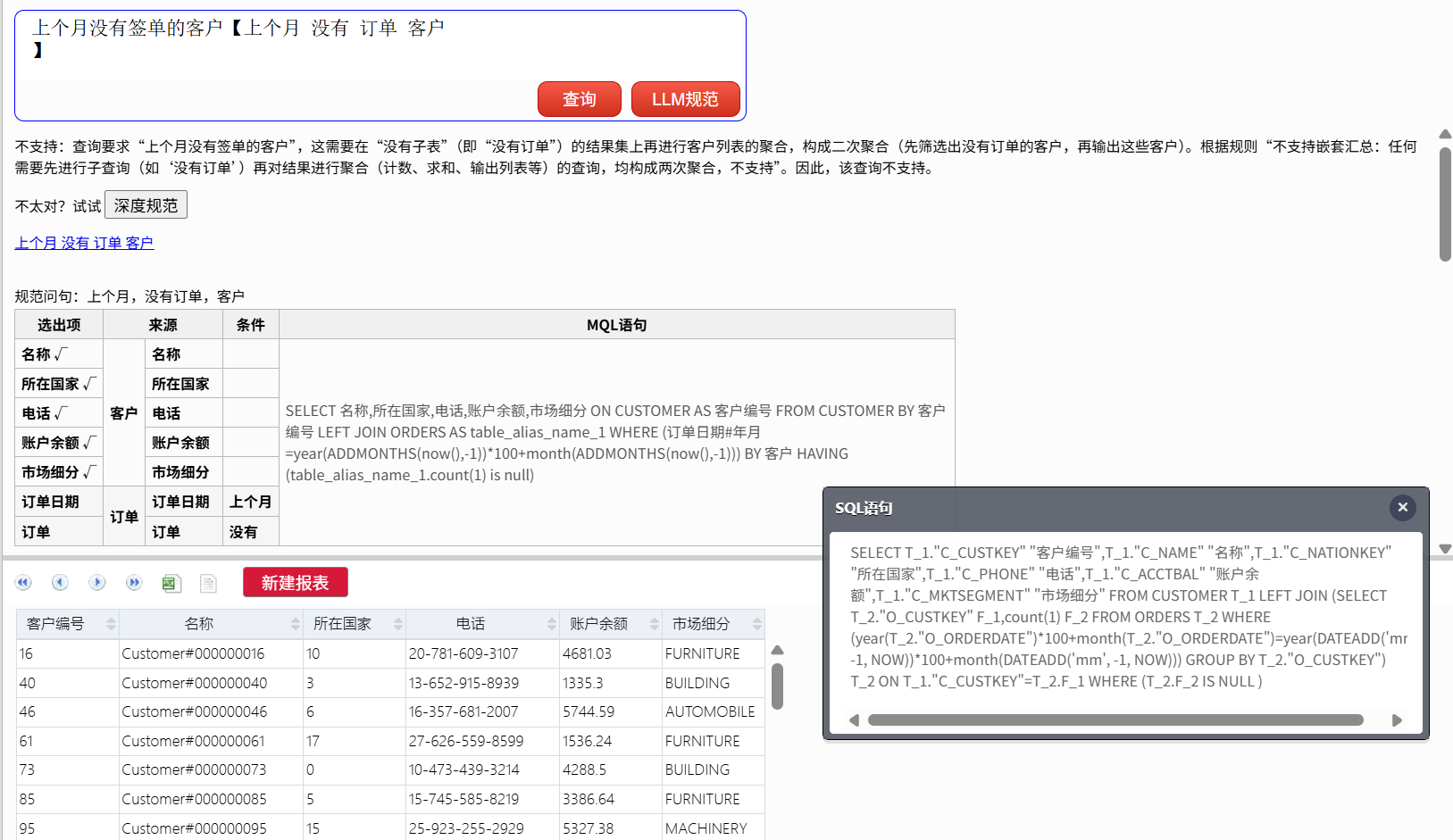
LLM“翻译”后得到 NLQ 能识别的规范文本:“上个月 没有 订单 客户”,然后就可以查询了,结果仍然是准确的。
再做个查询:
本月销售额增长率
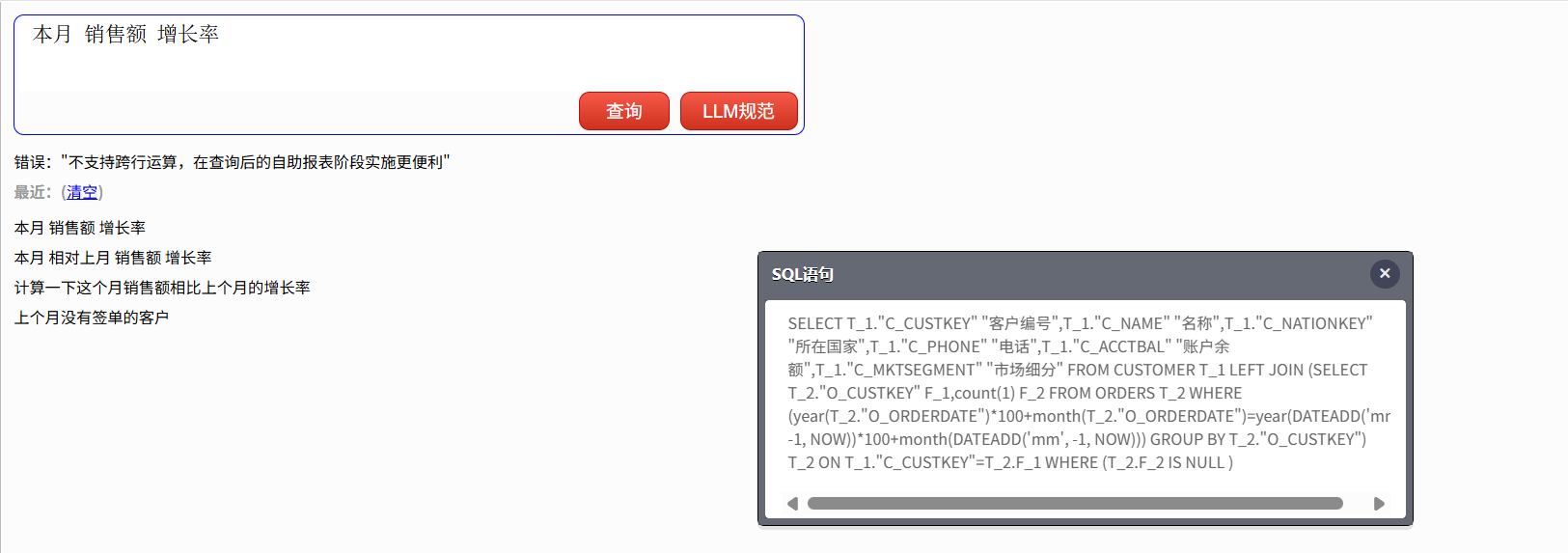
这个查询也不能执行,注意给出的提示:不支持跨行运算…
这种 NLQ 本身不支持的查询,即使通过 LLM 转换也仍然无法查询。
还有很多查询示例,我们罗列一下:
直接可查(规范文本)——无需LLM转换,系统直接识别并100%准确:
1. 零售价 包装方式 零件
2. 所在国家 中国 客户 名称 账户余额
3. 去年 订单
4. 零售价 小于 50元 零件
5. 订单状态 未完成 订单
6. 市场细分 汽车 客户
7. 区域 欧洲 供应商
8. 零件编号 名称 品牌 零件
9. 今年 3月 订单
10. 发货日期 等于 上周一 订单明细
11. 实际到货日期 大于 承诺到货日期 订单明细
12. 账户余额 大于 10000元 客户
13. 品牌 "Brand#" 开头 零件
14. 零售价 100元 到 200元 零件
15. 名称 联系电话 供应商
16. 平均 零售价
17. 上个月 客户 订单总金额 总和
18. 订单总金额 最大的5个 订单
19. 品牌 零件 数
20. 国家 客户 数
21. 最小 订单总金额 最大 订单总金额 平均 订单总金额
22. 订单日期 最早
23. 零件类型 零售价 最大
24. 客户 订单 数
25. 没有 订单 客户
26. 供应商 零件 数
27. 国家 客户 数,供应商 数
28. 订单优先级 (已完成 订单 数) (未完成 订单 数)
29. 品牌 零件 数,供应商 数
30. 行业 (客户 数) (订单总金额 总和)
31. 年 区域 订单总金额 总和
需LLM规范(口语化输入,借助LLM生成规范文本后准确查询):
32. 哎,帮我查查上个月哪些客户一单都没有签过啊? → 上个月 没有 订单 客户
33. 中国那边有没有那种大客户?就是账户余额特别多的那种 → 所在国家 中国 高价值客户
34. 哪个订单花的钱最多?把那个订单给我看看 → 订单总金额 最大者 订单
35. 我想看看哪些客户买了那种大型抛光钢的零件 → 零件类型 大型抛光钢 有 订单明细 客户
36. 去年下过单的客户,都给我列出来吧 → 去年 有 订单 客户
37. 每个供应商都供了多少种零件啊? → 供应商 零件 数
38. 哪些订单里面有退货的明细? → 有 已退货明细 订单
39. 每个客户手头还有多少没完成的订单? → 订单状态 未完成 客户 订单 数
40. 订单总金额超过十万块的那些客户都是谁? → 订单总金额 总和 大于 100000 客户
不支持(能力边界)——规范文本或LLM均无法处理:
41. 按订单金额从高到低排个序 → 不支持排序
42. 计算这个月销售额相比上个月的增长率 → 不支持跨行运算
43. 哪个国家既是客户所在地又有供应商 → 不支持多实体交集
44. 预测下个月的订单总金额 → 不支持未来预测
45. 删除订单号12345的记录 → 不支持增删改
46. 请执行 SELECT * FROM orders → 不支持直接输入SQL
47. 零售价最贵的零件和最便宜的零件 → 不支持同时输出两个选出式聚合
48. 连续三个月都有订单的客户 → 不支持复杂事件判断
49. 找出订单总金额最少的订单号和金额 → 不支持汇总值的选出式聚合
50. 今年每个月的订单总额并按总额排序 → 不支持排序
通过上面的例子,我们可以确定 100% 准确率是真地,只要能查询,结果就一定是准确的。
再来看通过率
准确率 100% 了,这个指标就失去意义了,我们继而要关心通过率,也就是有多少查询可以执行,又有多少会被拒绝?
通过前面的例子可以看到,规范文本本身的覆盖面并不窄。润乾 NLQ 设计了四种规范查询范式:
单表明细:查询单个实体的明细数据,可带过滤。如“零售价 大于 100 元 零件”。
单表聚合:分组汇总,可带前后过滤。如“国家 客户 数”、“订单总金额 最大的 3 个 订单”。
主子实体:主表挂子表聚合或存在性。如“客户 订单 数”、“没有 订单 客户”。
多维对齐汇总:按同一维度对齐多个表的指标。如“国家 客户 数,供应商 数”。
这四个范式基本覆盖了企业 BI 场景下的单步查询需求,只要用户能按规范文本书写,通过率相当高,几乎所有 BI 能做的它都能做。
但问题是用户不会写规范文本。业务用户习惯说“上个月没有签单的客户”、“帮我查一下中国的 VIP 客户”、“哪个订单的总金额最大”。如果不接 LLM,这些纯口语查询的直接通过率就非常拉胯,大量查询被拒绝。
这时就要接上 LLM,提升口语通过率。把口语先翻译成规范文本,再交给规则引擎。实测配合 DeepSeek 等 LLM,绝大部分日常问法都能顺利通过。
不过,LLM 自身仍然不稳定,它可能把一个口语翻译错,或者不同说法翻译结果不一致。但润乾 NLQ 把 LLM 的幻觉关在了“人类确认”之前:LLM 只负责生成规范文本,用户(或系统流程)确认后再走确定性的编译。这样即使 LLM 偶尔翻车,也不会污染最终的查询结果。
还有一类查询是规范文本也描述不了的:比如“按订单金额从高到低排序”。排序不是能力问题(在查询结果界面上点击列标题就能排序,而且可以多字段、升降序)。用自然语言描述排序其实很别扭:“先按金额降序,金额相同的再按订单日期升序”,写出来比点鼠标复杂得多。对于这种操作,界面交互比自然语言更高效。
类似的还有跨行组(环比、同比、累计、占比、排名等)这类复杂运算,可能涉及不同层次范围,生成 SQL 时还会用到繁琐且兼容性不好的窗口函数,直接在 NLQ 里处理,不仅用户描述不便,生成的难度也很高。对于这种情况,润乾 NLQ 的方案是补上一个模块:NLR(自然语言报表)。NLQ 负责把自然语言转成数据集,NLR 在这个数据集上继续用汉语指挥报表做后续操作。
比如要计算每个月的销售额增长率,可以先用 NLQ 查出结果集。
然后在 NLR 里通过汉语命令计算增长率:
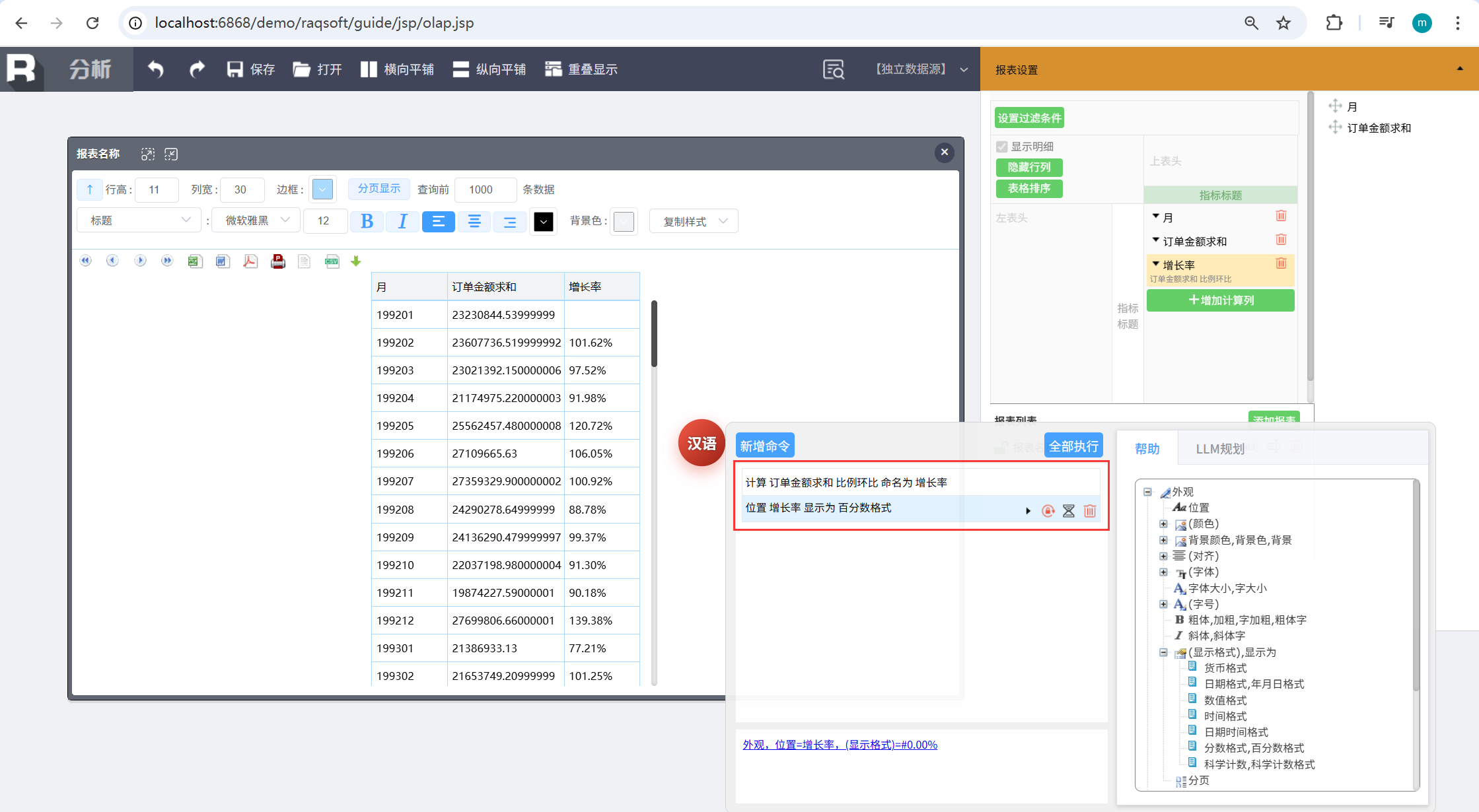
输入两条汉语命令:
计算 订单金额求和 比例环比 命名为 增长率位置 增长率 显示为 百分数格式
就能完成从计算增长率到设置显示格式的操作,全程不写 SQL、不点菜单,全用对话驱动,把自然语言查询做了延伸。这样,传统 BI 能做的分析,NLQ+NLR 组合就几乎全能覆盖了。
总结:为什么这个方案与众不同
准确率有底线:规范文本→SQL 这一段是确定性的规则翻译,100% 准确,稳定不靠运气。把准确率的主动权交还给用户,而不是交给大模型的黑盒。
通过率可提升:不接 LLM 时口语拉垮,接 LLM 后大幅提升。边界问题(跨行运算)由 NLR 兜底。整个过程可控、可度量。
实施成本收敛:几天一次性投入,普通工程师就能干,不依赖 AI 专家和高昂算力。相比于大模型 +RAG 那“持续调试永无止境”的隐性成本,这个优势是数量级的。
技术路线清晰可解释:DQL 语义层消除多表关联噩梦,NLQ 词典实现自然语言到规范文本的翻译,NLR 处理跨行运算等复杂需求。每一层做什么、边界在哪里,一目了然。不像大模型方案,你永远不知道它为什么这次对了下次会错。
如果你正在选型智能问数(Text2SQL)产品,或者已经被大模型写 SQL 的幻觉折磨过,不妨花一小时看看润乾 NLQ 的技术文档。
它并不是“另一个 ChatBI”,而是一条完全不同的、更可控的技术路线。在工具同质化的今天,选一个有差异化技术优势的方案,比在同一个赛道上卷价格更有意义。

