


AI 写量化策略如何杜绝幻觉
现状
在量化投资领域,AI 生成策略已从“尝鲜”走向普及,但大语言模型天生的“幻觉”特性,在容错率为零的金融领域显得格外致命:编造不存在的函数、误用未来数据、忽略交易成本与风控……这类错误隐蔽性强,非程序员用户极易“盲信”AI 输出,直至回测甚至实盘亏损才发现问题。
目前业界防范 AI 幻觉的主流思路是“多层级防御”:高质量数据微调、检索增强生成(RAG)、自我校正工作流、形式化验证等。这些手段效果显著,但成本普遍较高——需要专业的模型、复杂的验证框架(Harness)以及专家程序员的持续审计。对于普通用户来说这就形成了一个悖论:用户本是为了省事才用 AI,却又需要有专业能力来校验 AI 的输出。
解决方法
那么,还有没有适合普通人的解决方法呢?
有的
如果我们缩小目标,聚焦于可用指标组合实现的离线策略,将量化程序模式化,那么还是能找到低成本、低门槛的破局方法的。AIQT 的 “规范汉语中间层” 模式便是典型解决方案。
AIQT 创新性地引入规范汉语中间层,构建 “自然语言→规范汉语→可执行策略” 的链路,从源头降低幻觉概率,同时让非程序员也能直接校验策略逻辑,彻底打破审核壁垒。

1. 用户用自然语言描述策略
价格突破 20 日高点时买入、跌破 MA10 卖出……
2. AI 根据 AIQT 的规范要求,翻译为结构化、无歧义的规范汉语
20日最高价最大,10 日收盘价平均……
相比与程序代码,规范汉语的可读性很强,普通人也能看懂,彻底降低了策略逻辑的审核门槛。
3. 系统将规范汉语编译执行
精准的编译过程,非概率生成,100% 准确无幻
用 “规范汉语” 替代 “直接代码生成”,还有一个好处就是从根源上杜绝了未来函数的问题。因为在 AIQT 的汉语规范中根本就没有任何计算未来的表达式,比如像明日收盘价,次日开盘价这类的写法都是不支持的。即使 AI 翻译出了这样的语句,系统也会报错,指导 AI 纠正。
AIQT 的核心突破,是定义了一套极简、无歧义、结构化的规范汉语(类似量化领域的 “专用语言”),作为用户与 AI、AI 与引擎之间的 “中间桥梁”:
对用户:用大白话描述策略(如 “5 日线上穿 10 日线买入”),无需懂代码;
对 AI:强制输出规范汉语,而非代码,严格遵循固定格式(指标定义、买入条件、卖出条件、仓位规则),禁止模糊表述或逻辑跳跃;
对引擎:规范汉语可直接解析为可执行策略,无二次翻译误差,避免代码生成环节的幻觉。(精准编译过程,非 LLM 概率输出模式)
这套规范汉语的特点是:无歧义、可验证、易理解—— 每个指标、每个条件、每个规则都有固定表述;同时语言贴近日常,非程序员能直接读懂并校验逻辑。
实战举例
从 “RSI 超买超卖策略” 看如何杜绝 AI 幻觉
比如我们想写一个基于 RSI 指标的超买超卖策略,定义策略的交易规则如下:
1. 选用指标:RSI相对强弱指数(参数14)
2. 买入信号:RSI(14)<20,进入超卖区间,次日收阳开仓
3. 卖出信号:RSI(14)>80,进入超买区间,次日收阴平仓
打开AIQT的 AI 助手,将策略的交易规则输入给 AI
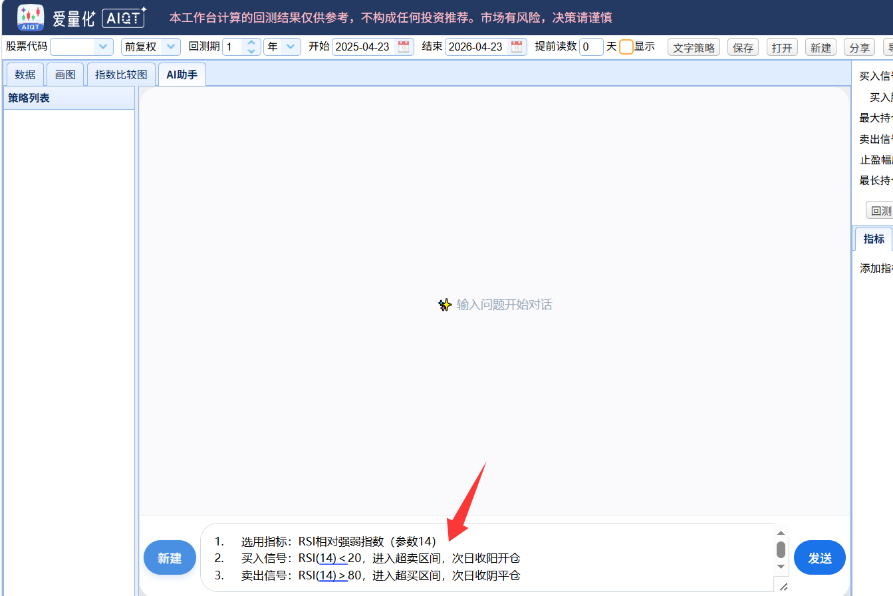
发送后,AI 会生成一个“规范汉语”的策略,下图:
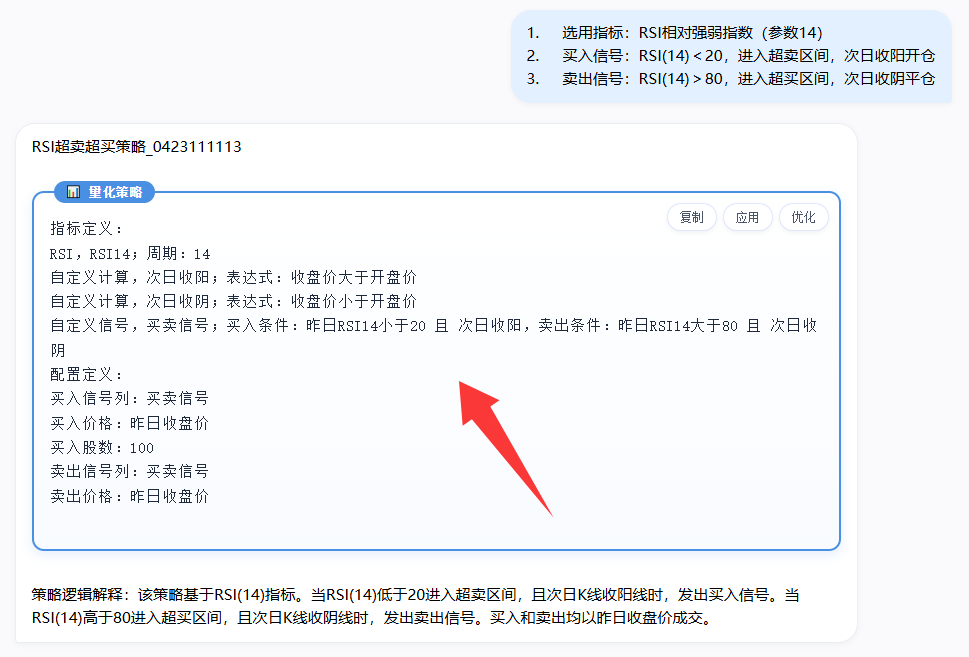
策略内容不再是代码,而是人人都能读懂的规范语言,比如次日收阳,AI 给出的表达式是收盘价大于开盘价,一眼就能看出写的对不对。再比如买入条件和卖出条件中 RSI 指标是引用昨日还是当日的数据也是一目了然。
检查策略符合要求后,点击应用、回测:
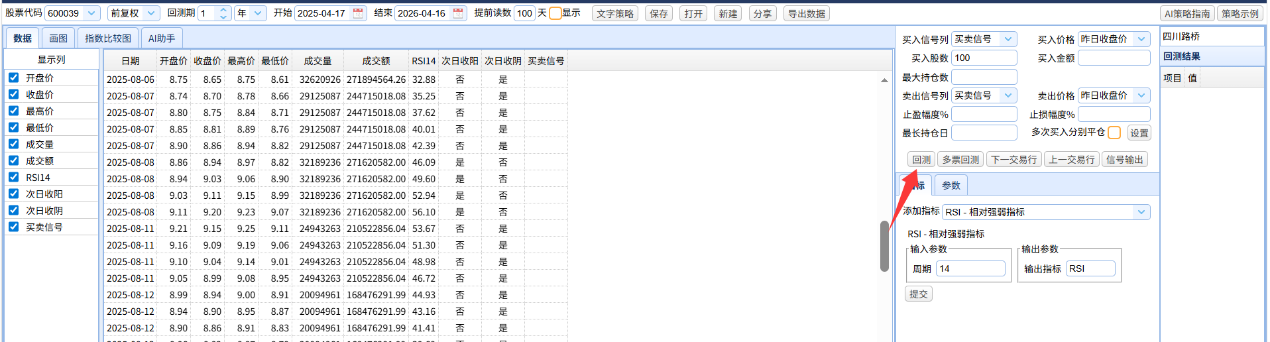
界面右边得到回测结果
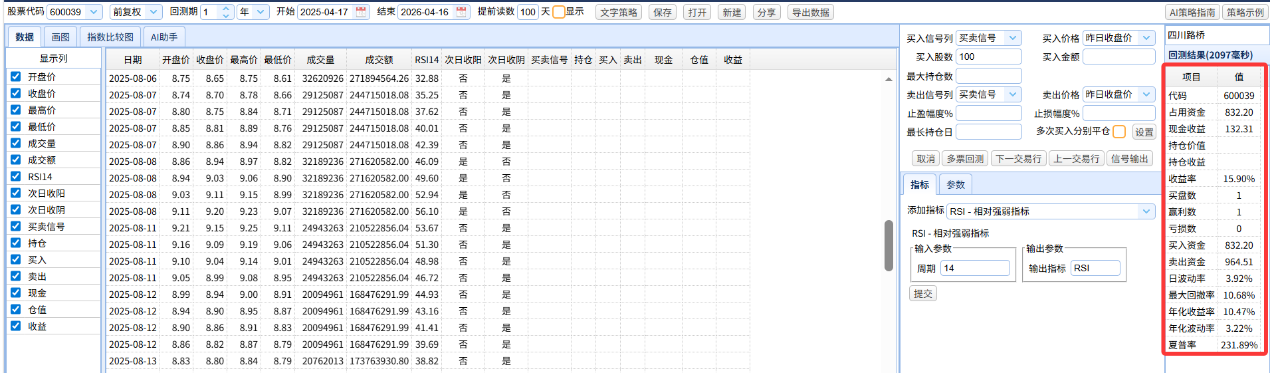
整个过程没有一句代码,人人都能轻松使用。
AI 负责将自然语言翻译成结构化的中间语言(汉语规范),平台负责检查语法错误和将中间语言编译成机器语言。非程序员只需要审核策略的逻辑是否正确,这样就从根源上避免了 AI 幻觉带来的损失。
但需要说明的是,AIQT 主要适用基于日线的离线策略与可用指标组合拼装的量化场景(如常见的技术因子、价量规则等策略)。对于高频实时交易、复杂动态滑点模型、非标数据源接入等场景,目前暂不支持。但对于绝大多数个人量化爱好者而言,这已经覆盖了相当多实用策略的需求。

