


AI 加持下的自助报表还能这么做!
在软件项目里,“报表需求”从来都是个让开发团队头疼的难题。客户的业务在变,报表需求也在变:今天要按地区汇总,明天要按产品线细分,后天又得对比同期数据。每一次变化落到开发团队头上,就是一轮新的数据查询、接口开发和界面调整,项目利润就这样一点一点被消耗掉。
为了摆脱这种困境,很多厂商尝试引入自助报表工具。但市面上的方案,通常是重型 BI 系统的部件,集成起来需要处理权限对接、数据同步一堆麻烦事;而且操作逻辑也比较复杂,用起来并不方便。投入不小,效果却不理想。
有没有更务实的办法?
润乾报表的思路:提供能轻松嵌入业务系统的自助报表模块,并加入自然语言交互能力,让自助报表制作像对话一样简单,真正将报表任务交付给最终用户。。

润乾报表嵌入应用;规则引擎实现自然语言制作报表(NLR);AI 大模型作为智能助手,支持口语化输入并协助规划制表任务;两者结合,让 AI 真正为人所用。
为集成而生的自助报表
润乾报表的优势之一在于良好的集成性。它不是一个独立部署、单独访问的庞大系统,而是一个轻量的“报表能力引擎”,可以通过组件形式深度嵌入到 CRM、ERP、OA 等业务系统内部。
用户无需跳出熟悉的业务界面,即可在某个功能模块旁直接发起报表设计与查看。与业务流一体的体验,解决了“不好集成”的痛点,让自助报表能被自然用起来。
汉语对话,扫清使用障碍
我们最希望的做表方式是:描述完我想要的效果,发给系统就能自己实现,然后有什么不合适的地方再调整。这就是润乾报表 NLR 模块的工作机制。
在这个过程中,AI 是得力的助手。润乾报表引入 LLM 来增强自然语言交互能力,同时保留规则引擎的稳定可控,既有智能,又有底气。
一步一看,随想随做
很多情况下,用户是一步一步构建报表,每步都能观察结果、确认无误后再继续。润乾报表支持通过汉语命令分步操作,每一步都实时响应。
第一步:筛选关键数据
筛选订单金额大于 2000 的大订单,输入如下命令:
过滤 订单金额大于 2000
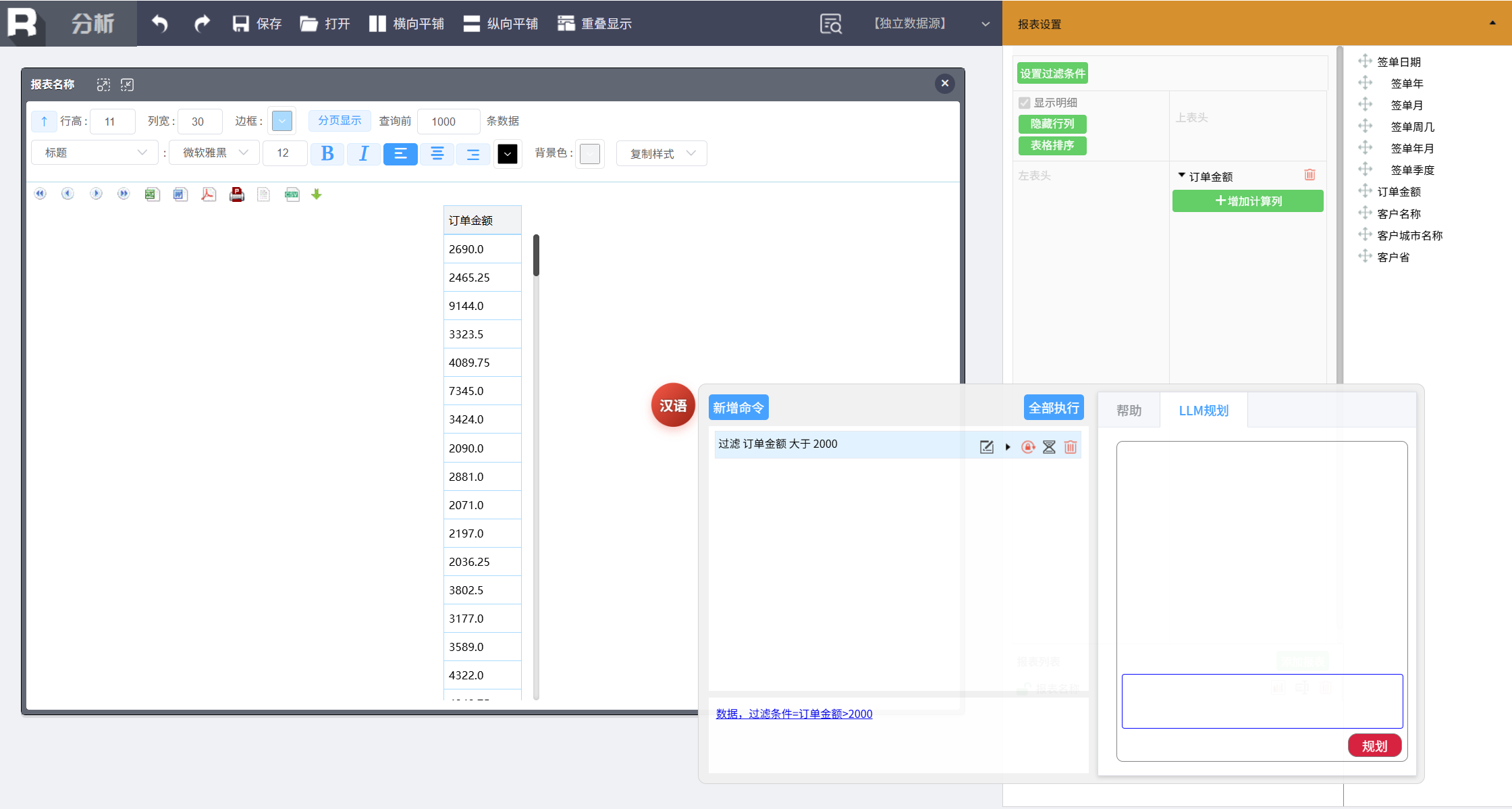
这样就可以轻松完成过滤。
由于输入的命令要符合 NLR 规范,而有时我们的输入可能没有那么标准,那样就查不出来了。比如输入:
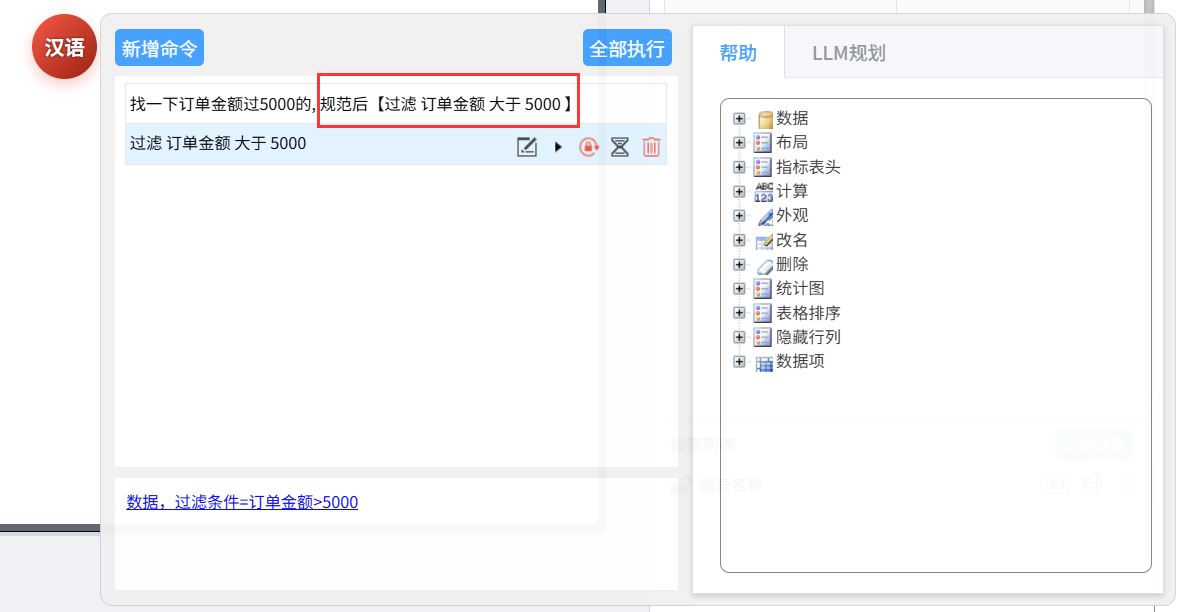
找一下订单金额过 5000 的
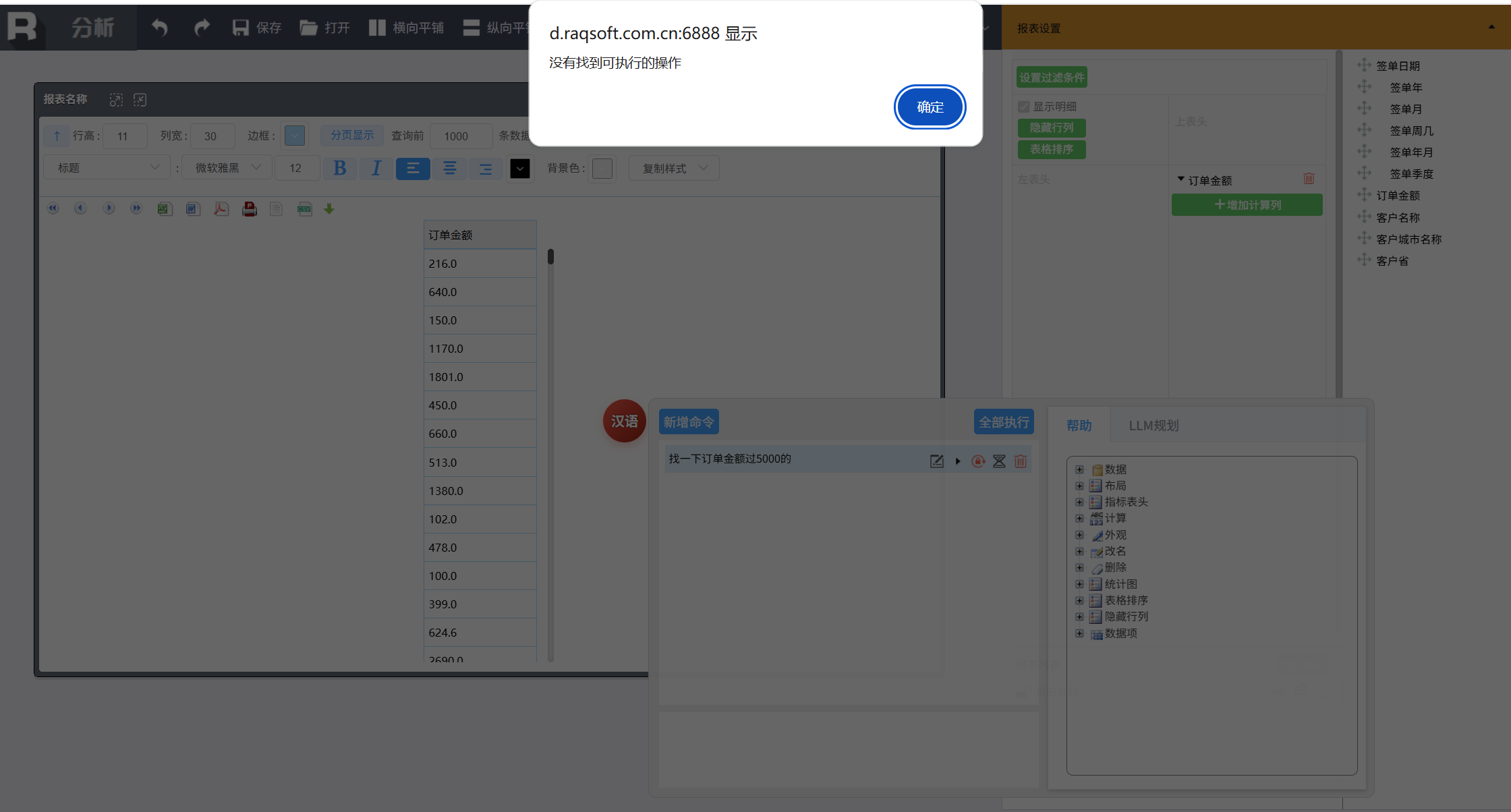
这时可以使用“LLM 规范”功能,将口语化的表达转换成规范问句。
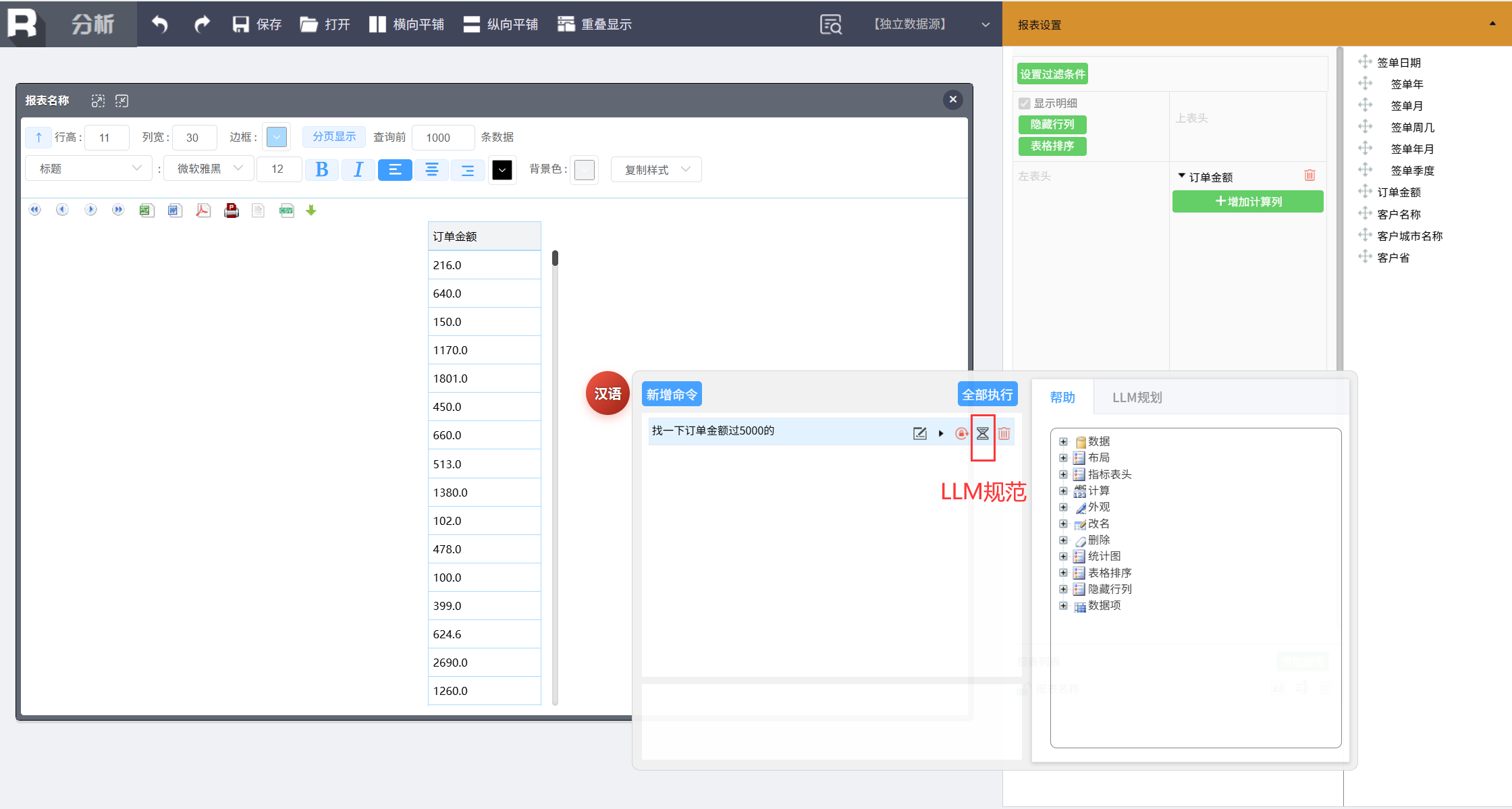
规范后的语句再执行就能顺利得到查询结果了。
“LLM 规范”功能对 LLM 的要求不高,市面上小参数模型就能胜任,成本很低,因为它只负责把“人话”转成规则引擎能理解的规范句式,不涉及复杂的推理。
第二步:分组汇总
按照省份和年份汇总大订单金额。新增命令,先分组,输入:
表头 客户省 签单年
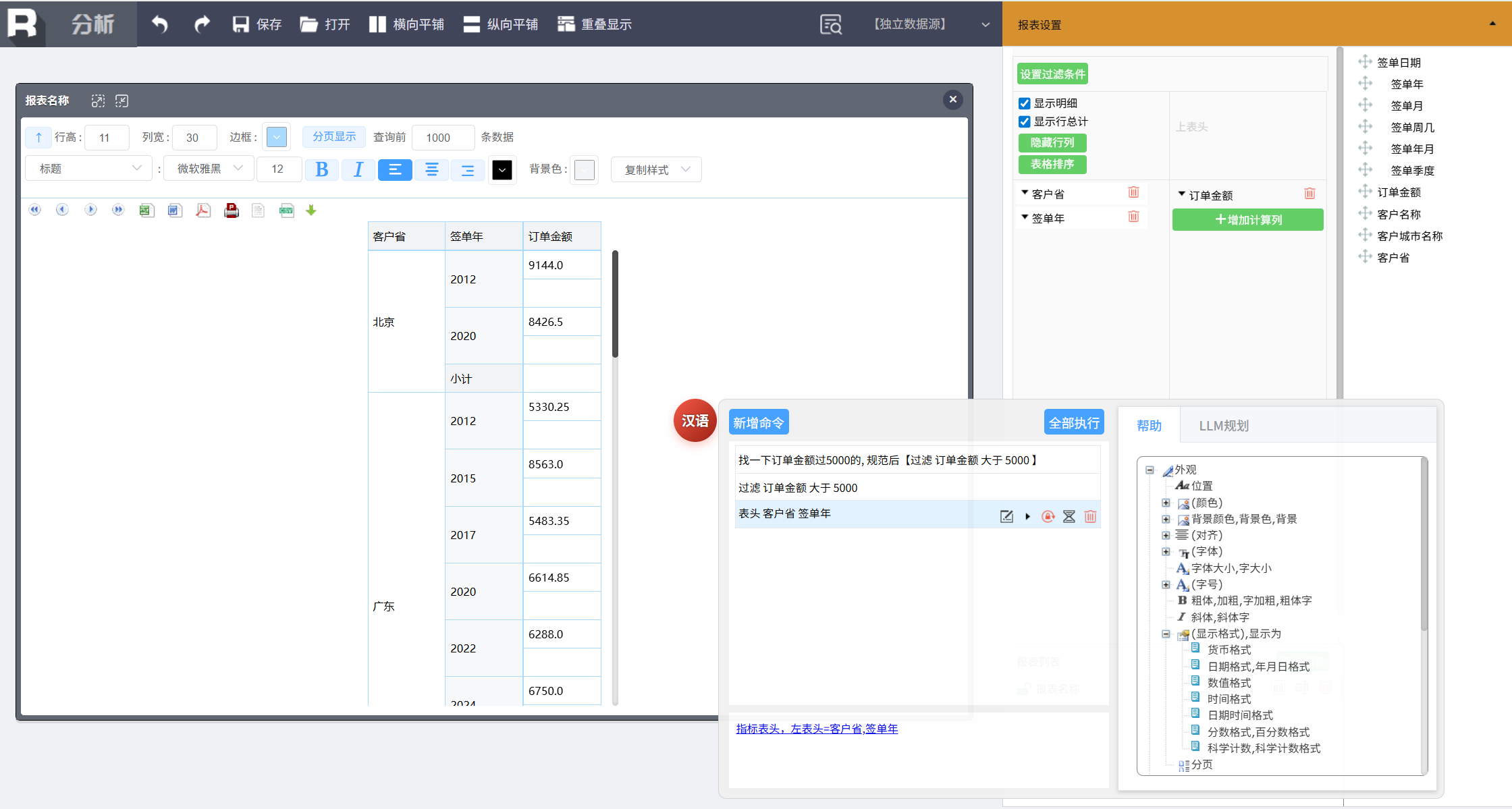
同样,这里也可以输入“按省份和年份分组”,然后使用 LLM 规范将其转换成规范语句。
添加汇总指标项,新增命令:
订单金额求和
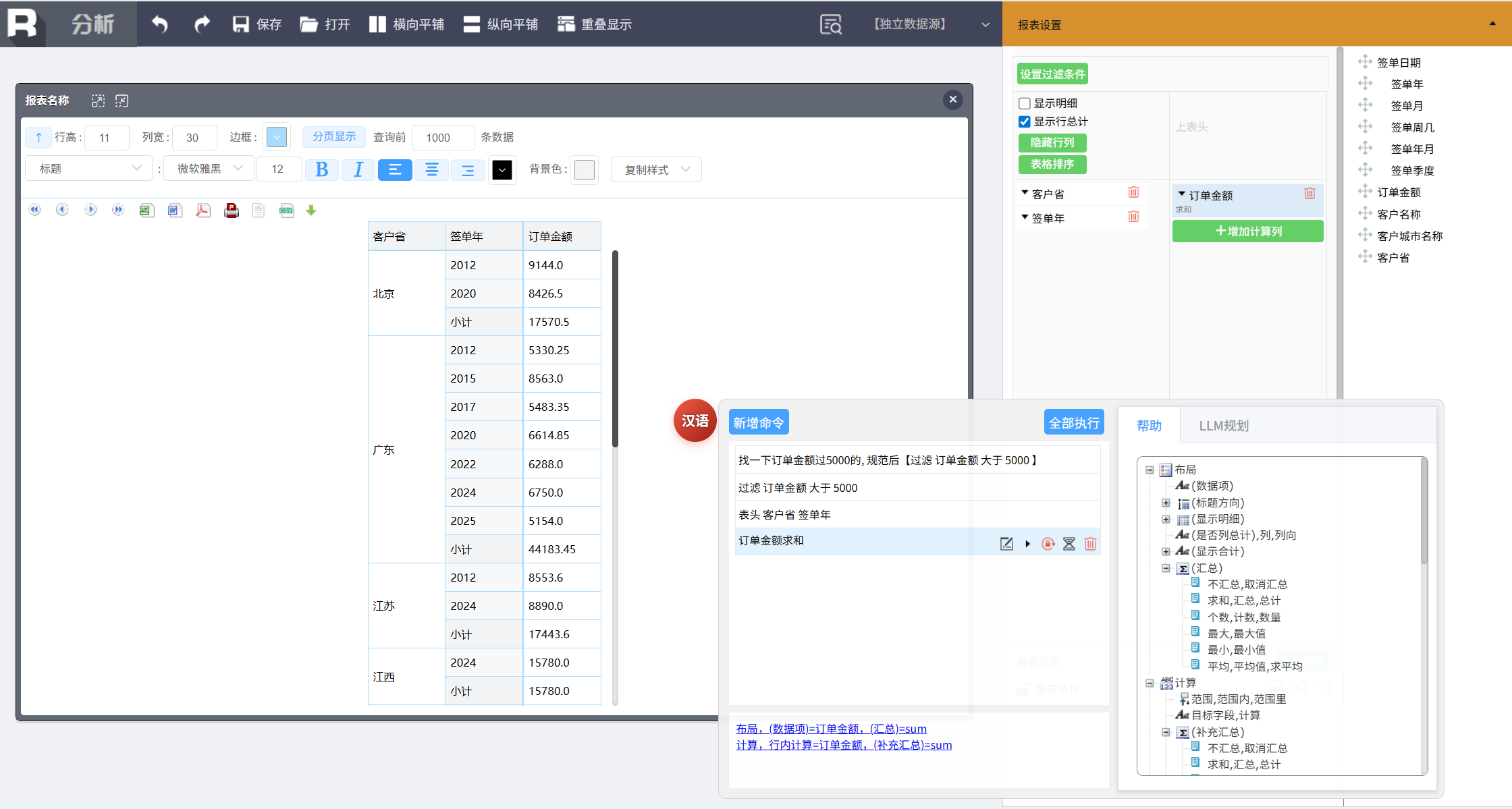
第三步,计算关键指标
计算每个省每年的订单金额环比增长率,新增命令:
在客户省范围内 计算订单金额比例环比 命名为订单环比
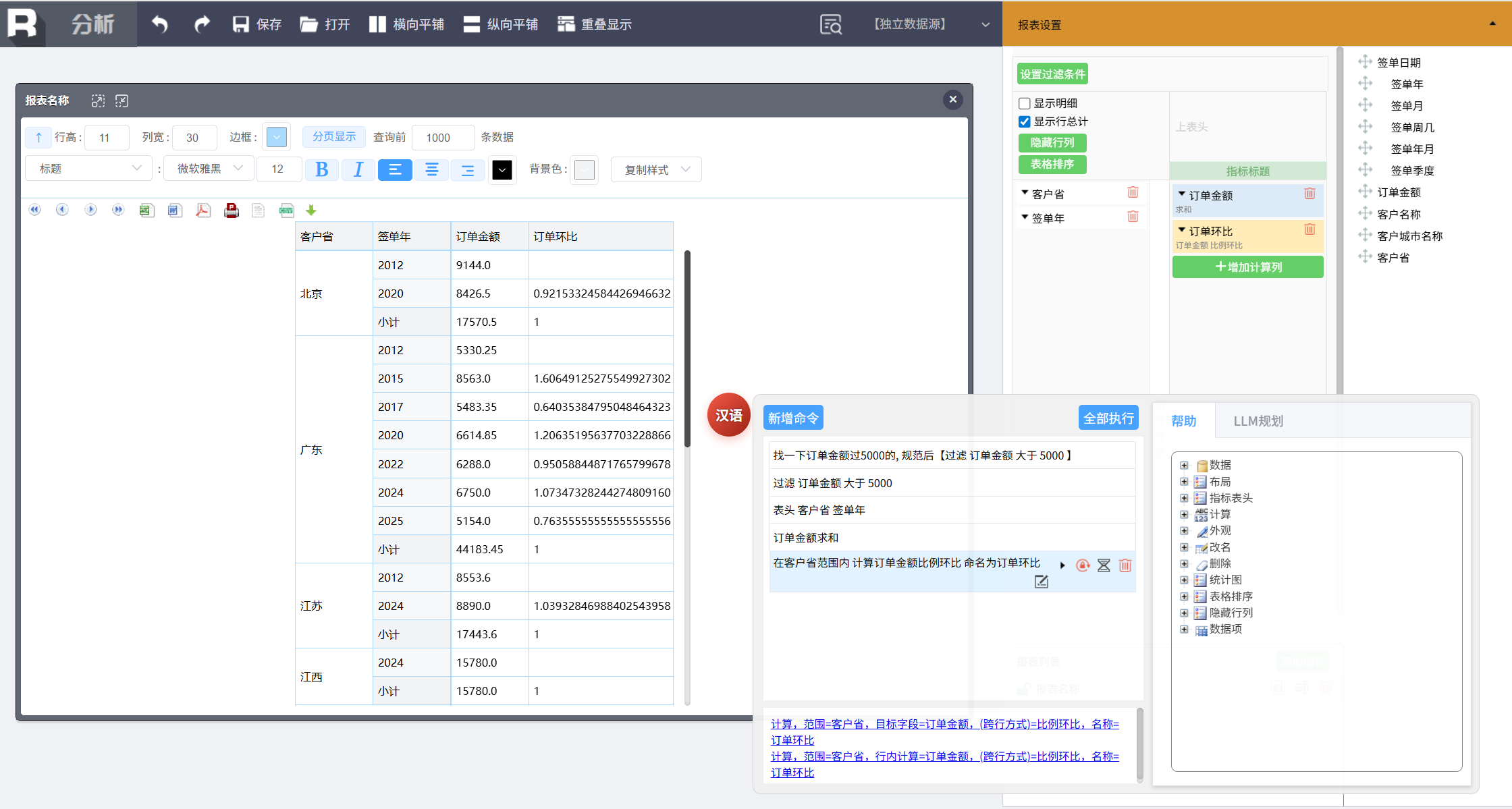
设置环比显示格式,点中报表中的环比列所在单元格(任意格),新增命令:
显示为 "#0.00%"
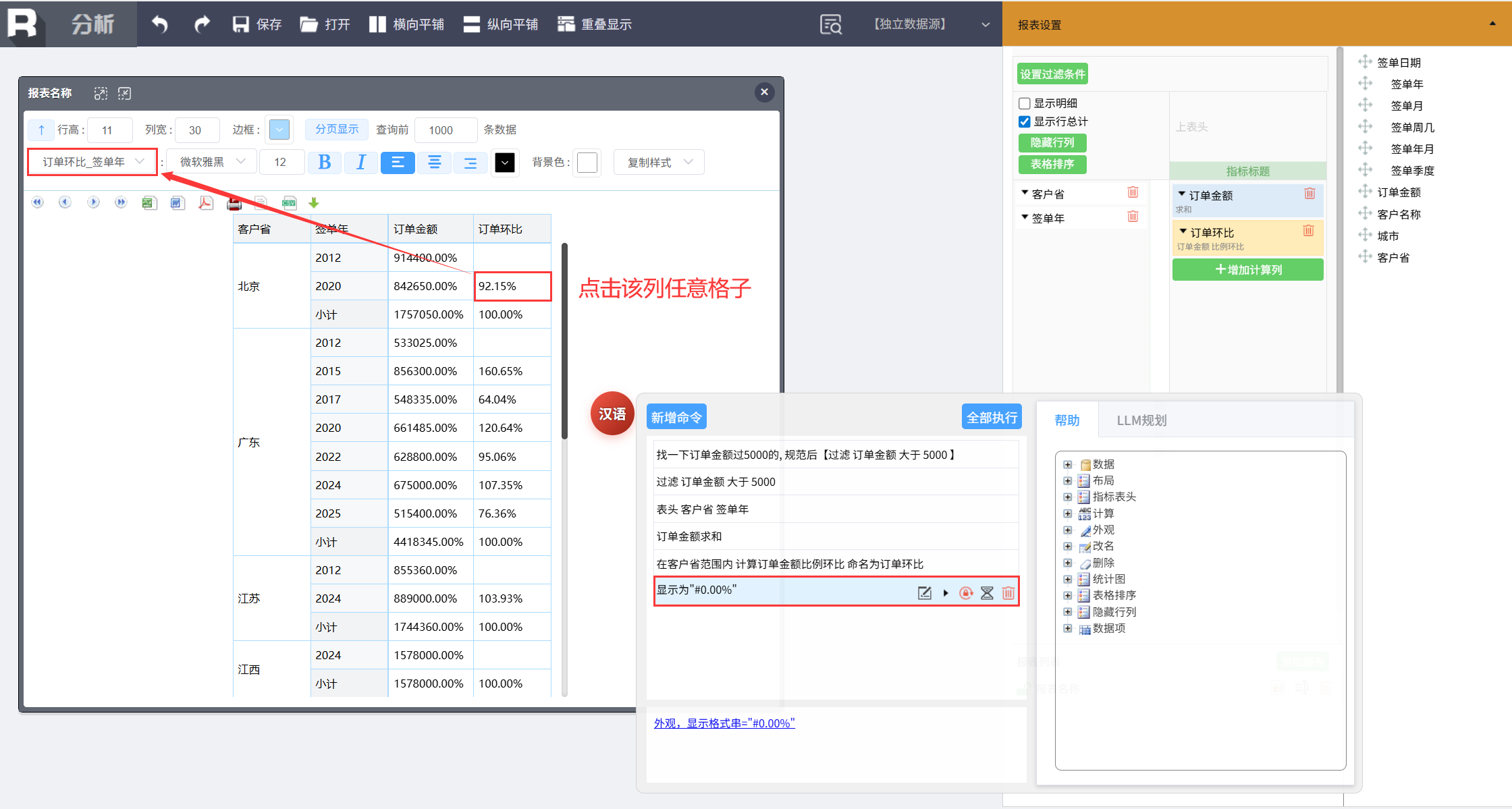
第四步,突出特殊数据
将增长率超过 100% 的订单环比突出显示,点击订单环比列任意格,新增命令:
大于 1 红色加粗
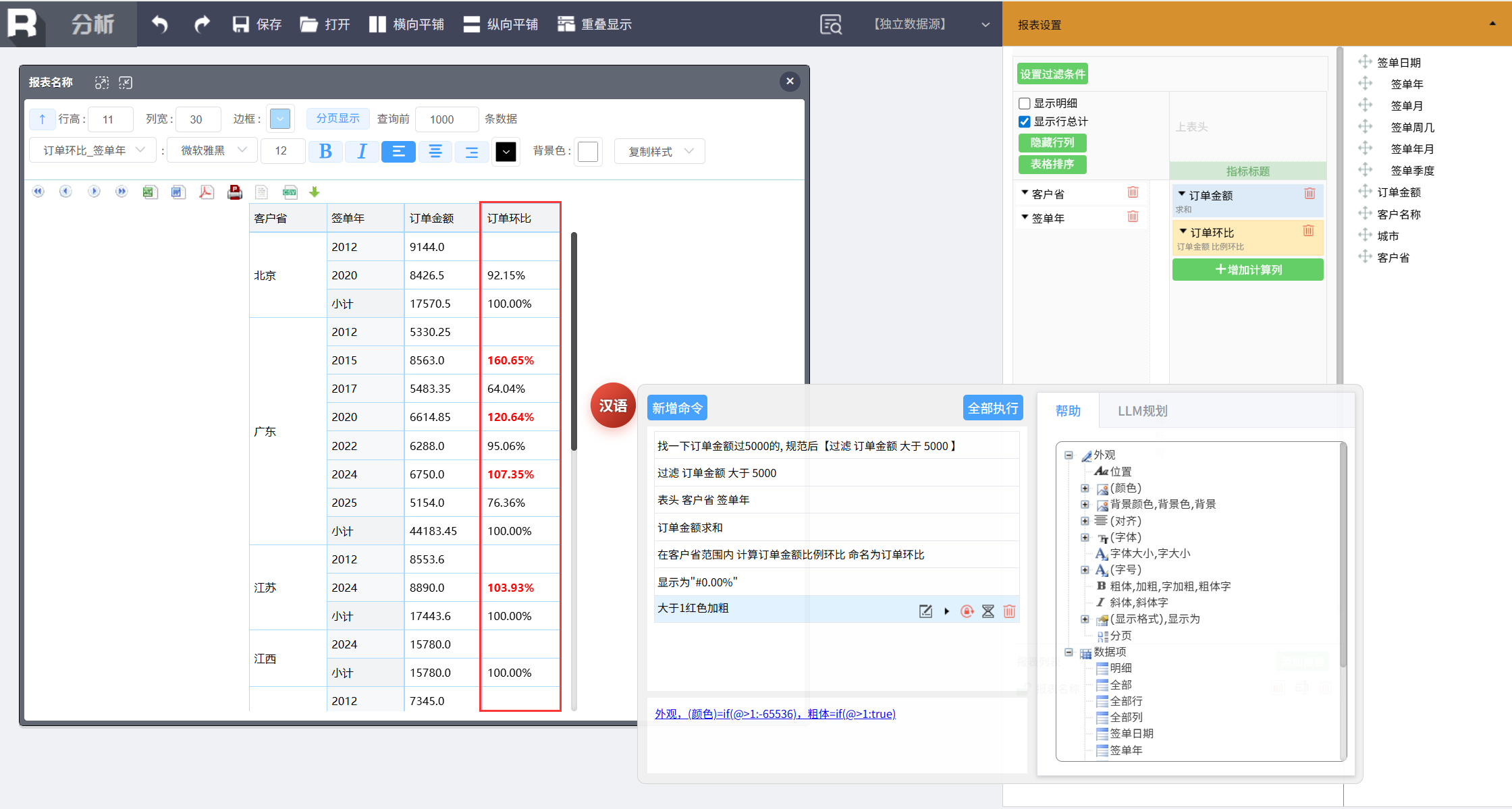
最后只想保留订单金额超过 10000 的行,新增命令:
隐藏 签单年 订单金额 小于 10000
隐藏没必要的报表行。
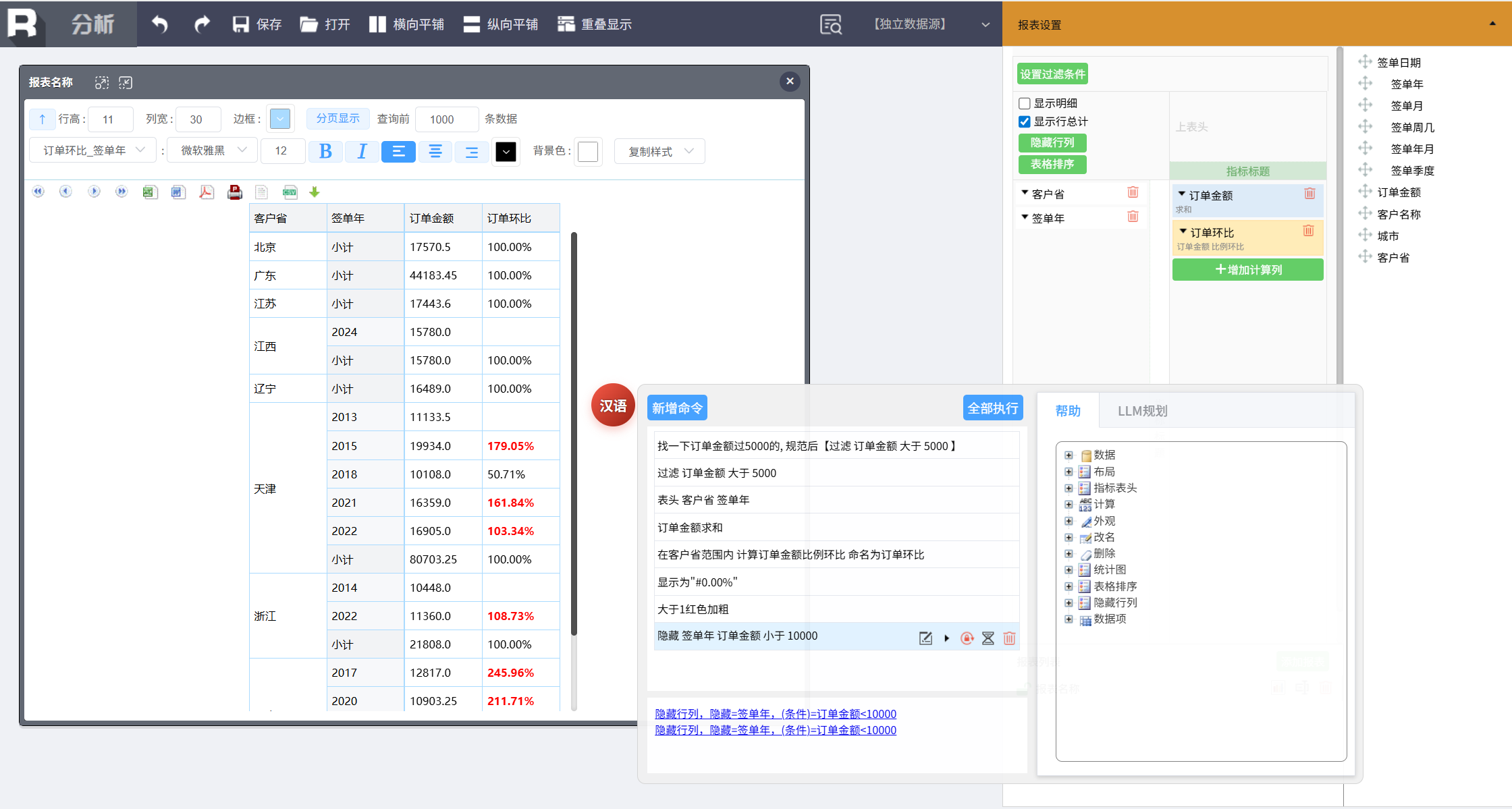
就这样,用户通过一步步的命令(配合 LLM 规范来降低输入门槛),就能轻松完成一张销售分析报表。熟练后可以直接输入规范命令,零延迟;偶尔遇到口语输入,用 LLM 规范转一下也很方便。
智能规划,一次到位
能不能一次到位,一句话描述需求,系统自动拆解成多步命令?没问题,这就是“LLM 规划”。
“LLM 规划”可以将一个复杂的报表任务,自动拆分成多个规范命令,然后一次性或分步执行。用户只需要用口语说出想要的结果,系统负责“动脑子”规划路径。
比如我们输入:
只要订单金额超过 5000 的数据,然后按省份和年份分组汇总订单金额,再计算省内金额比例环比,环比以百分比显示,金额按货币格式
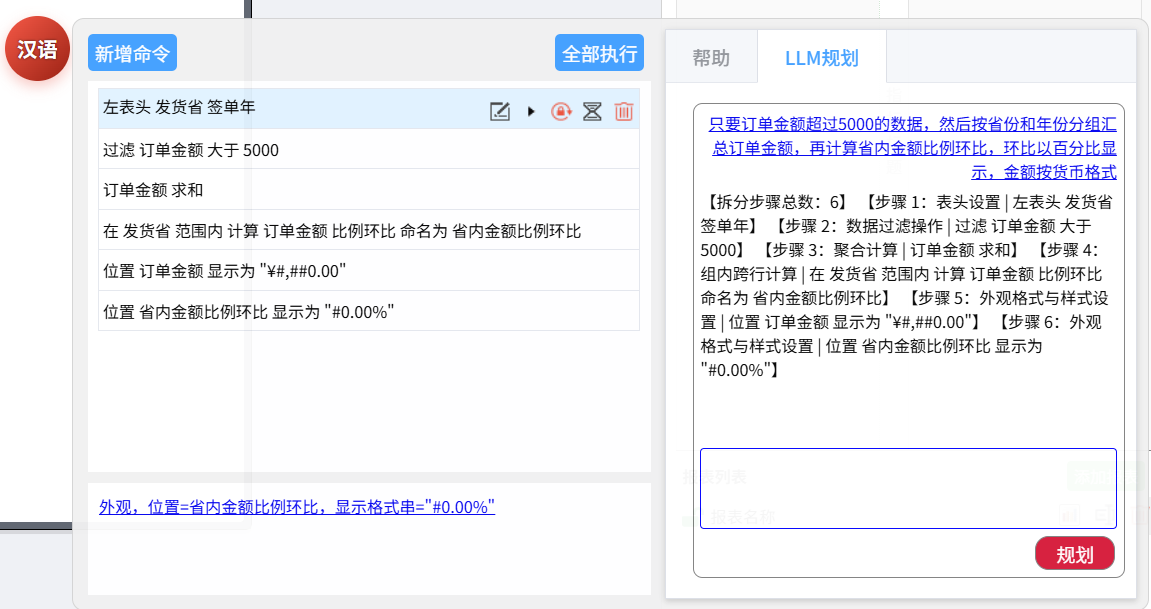
点击规划,得到了这样的拆分结果:
【拆分步骤总数:7】
【步骤 1:表头设置 | 左表头 发货省 签单年】
【步骤 2:数据过滤操作 | 过滤 订单金额 大于 5000】
【步骤 3:聚合计算 | 订单金额 求和】
【步骤 4:组内跨行计算 | 在 发货省 范围内 计算 订单金额 比例环比 命名为 省内金额比例环比】
【步骤 5:明细字段显示控制 | 隐藏全部明细】
【步骤 6:外观格式与样式设置 | 位置 订单金额 显示为 "#,##0.00"】
【步骤 7:外观格式与样式设置 | 位置 省内金额比例环比 显示为 "#0.00%"】
同时左侧命令面板上出现了这些命令:
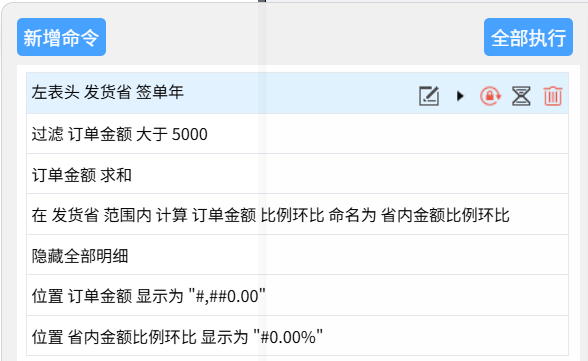
这里注意设置显示格式的命令:“位置 订单金额 显示为 xxx”,用到了“位置”参数,用于指定要设置的目标位置。而前面执行单个命令(“显示为 xxx”)时通过鼠标点击已经选定了“位置”,所以省略了这个参数。
规划完成后,可以点击“全部执行”,一次性得到结果报表:
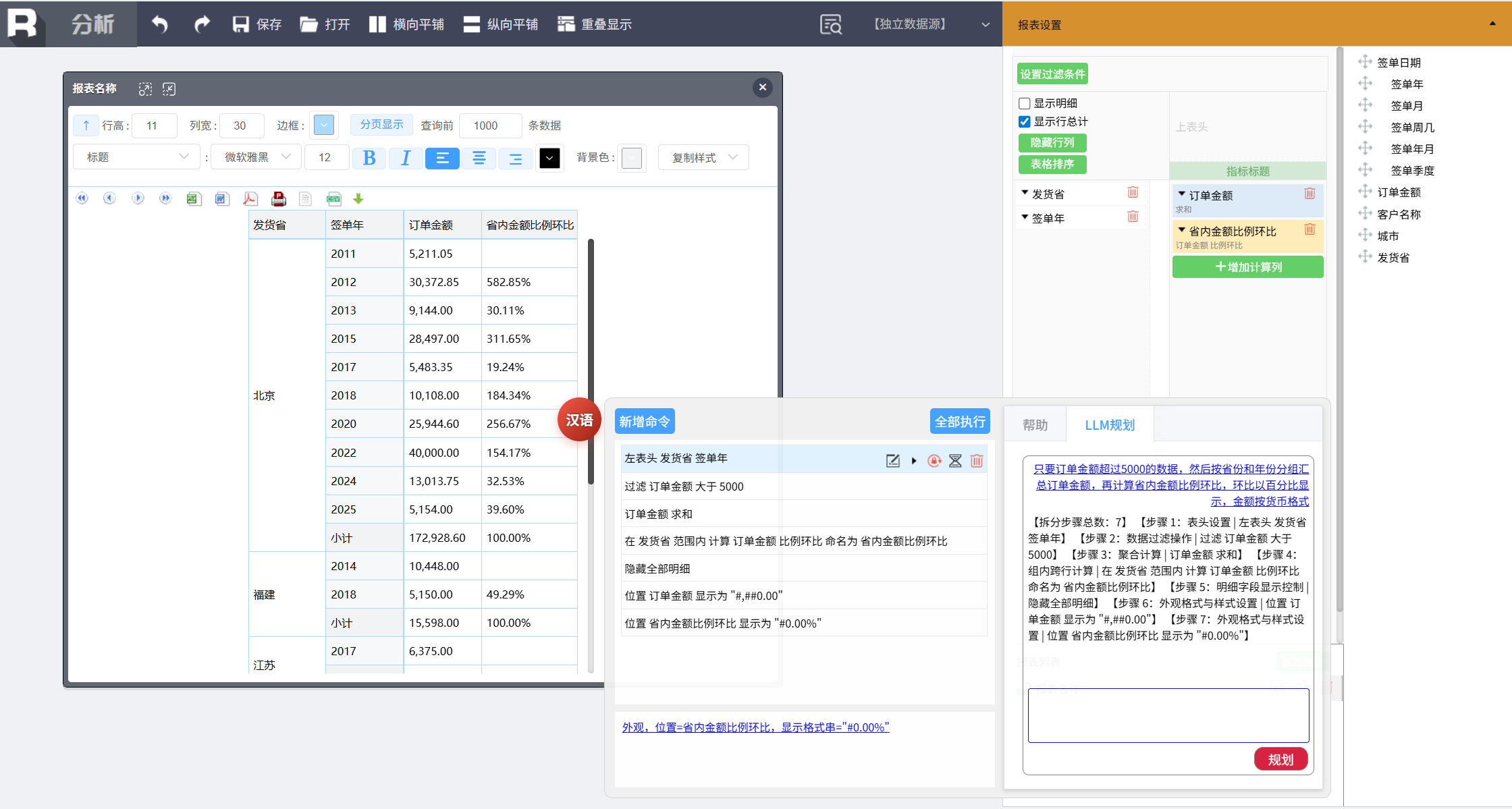
分组汇总、环比计算、显示格式都一次性算完设置好了。当然,如果不想全部执行,也可以逐条执行、观察中间结果,规划后的命令面板支持灵活控制。
规划可能不完美,但你可以轻松调整
AI 虽然强大,但并非 100% 准确,这就是所谓的“幻觉”问题。规划的步骤有时可能不符合预期:比如分组顺序不对、计算指标名称有偏差、过滤条件遗漏等。
不过没关系。润乾报表的规划结果是完全透明、可读、可编辑的。系统生成的每一条命令都是规范的“人话”,用户可以:
删除多余的步骤
修改某条命令的参数(比如把“大于 5000”改成“大于 10000”)
插入新的命令
调整命令的执行顺序
然后重新执行,或者继续用口语追加调整。例如,规划生成的报表已经出来了,但只想看 2025 年的数据,可以继续输入:
隐藏 2025 年以外的行
然后执行命令就可以了。
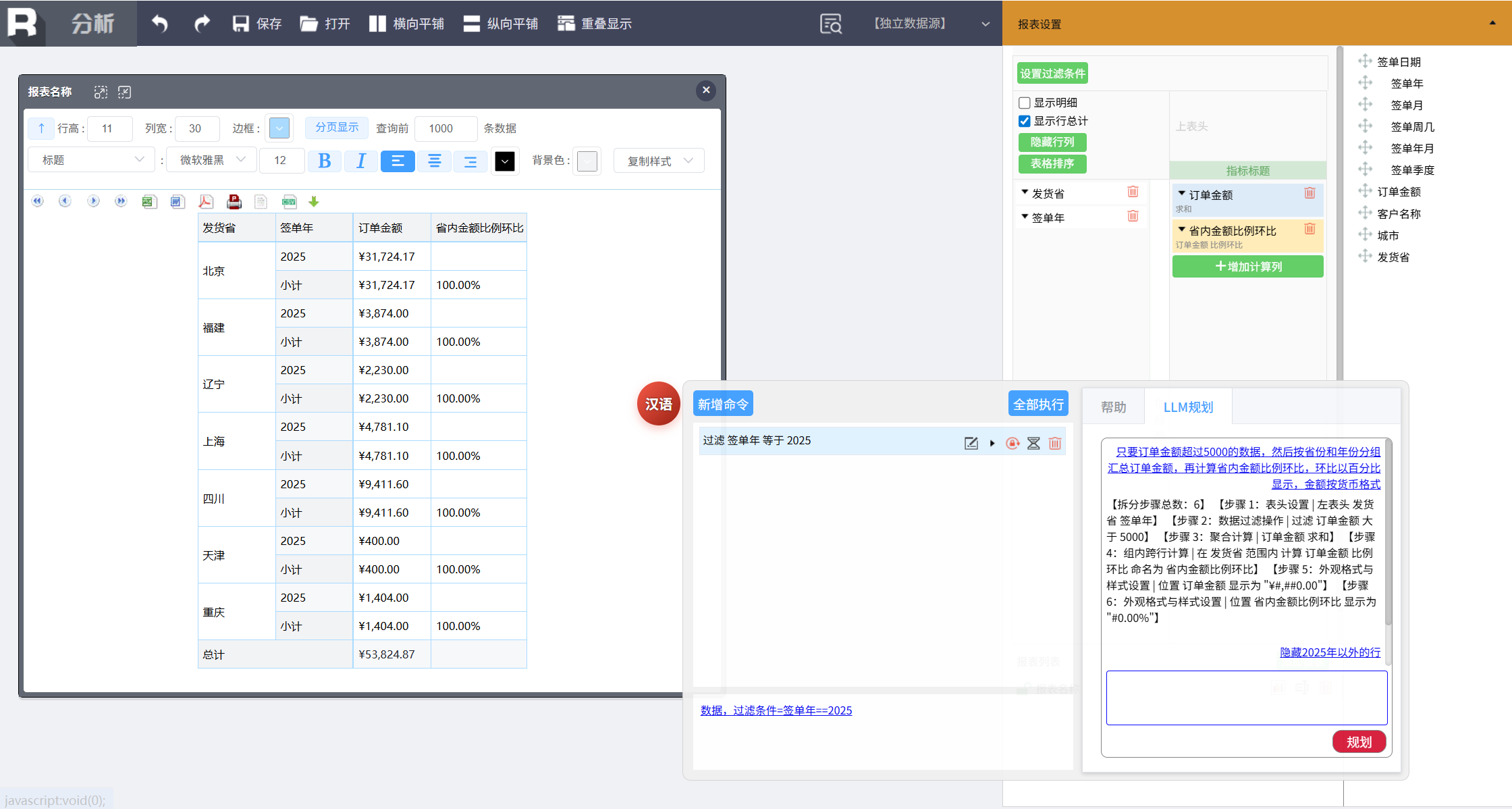
这种“AI 规划 + 人工调整”的模式,既发挥了 AI 的智能,又保留了人的控制权,比让 AI 直接生成黑盒的报表要可靠得多。
总结一下:
用 LLM 规划:一句话生成完整报表框架,再做微调即可。
不用 LLM 规划:熟手可以自己分步输入命令(配合 LLM 规范降低输入门槛),同样能完成复杂报表。
强烈推荐使用 LLM 规划,它能将报表制作效率提升一个新台阶。
扩展能力:从自由数据查询(NLQ)开始
上述 NLR 能力让用户能对“已有”的数据集制作报表。而有时,做表的第一步是准备数据——这份数据可能并不存在于任何预制数据集中。为此,润乾报表提供了与之无缝衔接的 NLQ(自然语言查询)能力。
NLQ 允许用户在其授权数据范围内,用汉语直接向数据库发起查询。例如:“订单金额超过 2000 的订单信息、明细数、客户名称和城市”。系统会基于预先配置的“业务词典”,自动理解业务术语、智能关联多表、精确筛选数据,并计算出每个订单的明细条目数,生成可直接用于制表的数据列表。
业务词典将业务术语与数据库表、字段和计算逻辑精确映射,从机制上避免了大模型的“幻觉”。同时,所有查询严格受限于用户权限,保障数据安全。
通过 NLQ 获得的数据集,可立即作为新报表的起点,直接使用前述 NLR 能力进行进一步加工(如分组汇总、计算环比等),形成从“自由取数”到“灵活制表”的完整自然语言报表解决方案。
硬核优势:可控、可靠、私域
· 完全透明,可审计:系统生成的每一步命令都是可读的“人话”(如“过滤 订单金额 大于 5000”),用户可查看、修改、删除、重排。不是黑盒,每一步都有据可查,满足企业审计要求。
· 低幻觉,结果可信:LLM 只负责口语翻译和任务拆解,核心计算由规则引擎执行,输出确定,词典映射清晰。你得到的不是“AI 猜的结果”,而是按明确逻辑算出来的数据。
· 易于私域部署,数据不出域:可部署在企业内网,满足严苛合规要求。NLR 支持不依赖 LLM 工作,熟手直接输命令,规则引擎跑在普通 CPU 上,零 Token 费用,无需 GPU;即使采用 LLM 规范或规划,所需模型能力也远低于通用大模型,私有化成本可控。
一句话:看得见、改得动、信得过。既有 AI 的便捷,又有工程的可控。私域安全,成本厚道。
对软件厂商的切实价值
集成润乾报表这套既能深度嵌入、又具备自然语言交互能力的模块,为软件厂商带来两大可量化的价值:
降低长期成本:易集成 + 对话式分析,让最终用户真正实现自助报表,开发团队从零散需求中彻底解放。
提升产品竞争力:当竞品还在“生拉硬拽”制表时,你的用户已经在系统内通过对话即时获得分析结果,体验的代差就是竞争壁垒。
报表需求的持续产生,是业务动态发展的自然结果。软件厂商的关键任务不是消除需求,而是将满足需求的成本降到最低。润乾报表正是这样一套务实的工具组合:以优异的集成性无缝嵌入现有产品,以听得懂人话的交互方式让业务用户真正用起来。
在 AI 技术喧嚣的当下,这种聚焦于解决具体问题、降低综合成本、提升产品可销售性的务实路径,或许正是广大软件厂商在竞争中构建自身护城河所需要的。
这么强悍的功能,是不是很贵?
恰恰相反!润乾报表三万元随便用的版本就已经完整包含了自然语言报表分析(NLR)能力。用一个几乎可以忽略的成本,就能换来开发团队的彻底解放、客户满意度的显著提升、以及产品竞争力的实质性跃升。这笔账,怎么算都太值了。

