


求助: 流式输出大型 Excel 文件
不好意思,我问题比较多,见谅🙏 不过,这也说明我是真的很认真的在使用集算器😄
前几天求助了流式读大型 Excel 文件,这次是关于流式输出大型 Excel 的问题,这里说的大型是指大几万行以上,二三十列的那种。没办法,这种低效存储格式毒害表哥表妹 40 年早已遍布各种办公场景,已经不可回避。
当前,集算器流式输出 Excel 格式有两种方法,我在使用时发现了一些问题:
第一种:file().xlsexport@act()
注意此时是 "文件. 输出 @c",当该文件不存在时会自动新建,如果存在文件时可以通过 @a 选项进行追加式输出。先读了一个 9 万多行 24 列的文件成游标,然后输出成 Excel 格式,为了测试需要,先不管操作流程是否合理,以下语句用追加输出的方式执行 3 次,

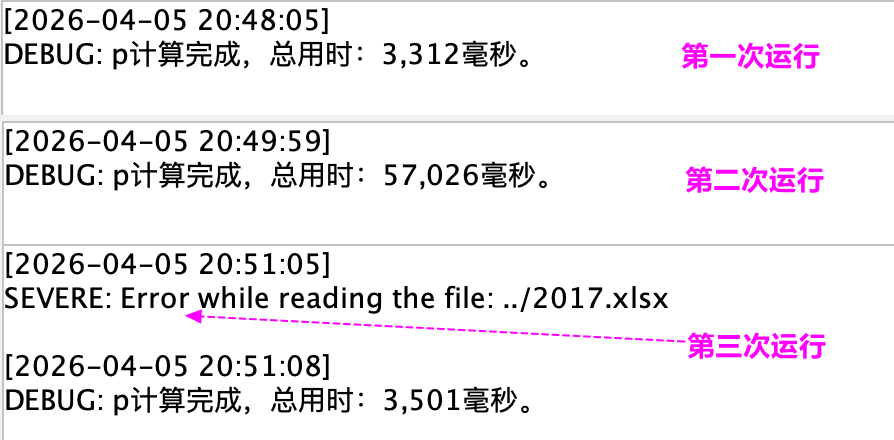
第一次执行时,因为没有 2017.xlsx 这个文件,语句自动新建并输出到了结果表,耗时也符合预期;
当执行第二次时,耗时陡增,追加同样的 9 万多行,耗时一下子变成 50 秒左右,但结果依然符合预期;
当执行第三次时,报错了,文件读取错误,但依然会输出一个文件,但这个文件的结果是不一样的,连指定的表名称也变了,行数就是游标的 9 万多行,并没有追加,看样子是重新生成了另一个文件。
三次运行的耗时如下所示:
第三次运行报错后输出的文件如下:

我在想,追加的时候是不是要先打开这个文件,所以第二次运行的时候,因为要打开那个 9 万多行的文件所以一下子耗时就增加了,当运行第三次时,因为文件已有 18 多万行,太大了,打开的时候报错了。
那像这种情况,干脆让程序直接报错后中断运行,就说文件太大,此方法不合适,别再生成新文件了,这样行不行?
文档里也说了”使用流式写出大文件,当文件 f 存在时,文件 f 需要支持被写入,且不能过大“,其实我是有心理准备的,但不知道到底多大是大,什么样的是不过于大,所以干脆报错中断,省了麻烦。
第二种:XO@w.xlsexport
这里的 XO 是指一个 Excel 文件以流式方法写的 open 对象,要用 file.xlsopen@w() 先打开。这个方法非常好,在某些情形下还可以多线程写出,比如当前工作簿中输出至不同的工作表,就可以并行,能节省老多时间。
但有一个问题,file.xlsopen@w 每一次都是重新生成一个 file,写的时候不管是不是追加的模式,只要是 @w 的方式,原先存在的文件也会被抹掉,我不知道有没有弄错,比如以下语句:

第一次运行时不存在要写出的 2017.xlsx 文件,运行后,会生成 5 个工作表,结果符合预期:
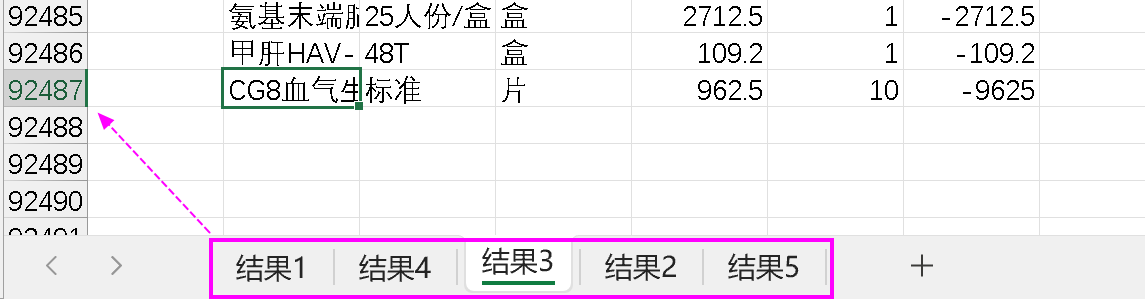
然后,再执行上述同样的语句,此时 2017.xlsx 这个文件已经存在,我预想的是 @a 会追加数据,但运行后并没有追加,应该是重新写了一个新的。
所以,xlsopen@w()是生成新的 excel 写入对象,那如果要往一个已有的大型 excel 文件上追加数据要如何操作?file.xlsexport@ac() 这个方法有限制,所以,xlsopen@w 能不能把已有文件打开成写入模式且不抹除数据?
暂时就想到这么多,有其他的我再补充。恳请大佬们帮忙看看,给予指导🙏
再说个题外的😄
无意中发现了一个 Apache 软件基金会孵化器项目 Apache Fesod 2.0
https://fesod.apache.org
说是专门为 Java 生态提供高性能 Excel 处理能力的开源库,原型是阿里巴巴开发的 EasyExcel,今年年初捐给了 Apache 软件基金会,成为了孵化器项目,看介绍也是依赖于 POI 5.5.1,但比 POI 更高效。我没别的意思哈,只是觉得 POI 也是 20 年的老项目了,性能也是中等稍偏上,依赖于集算器的多线程并行能力,读入和写出才像样一些。想着如果能进一步提高对 excel 文件的处理效率,也是一件好事。当然这还是个孵化器项目,还不是那种像 POI 已经定型的 Top-Level-Project,对产品稳定性可能有风险,哈哈,只是一个题外话,莫怪🙏


这些桌面业务不挣钱,就是顺便弄出来,能用到啥程度算啥程度,忙了就没精力去折腾了,有空了再补。
其实整个 Excel 有关的事都找不到商业机会。
完全理解。
Excel 虽然用户庞大,但老表们的学习意愿很低,基本上都是守着自己会的那一点东西混日子,正经大佬们也不会去玩 excel。
习惯固化了,包括很多玩 SQL 的,还不是守着 50 年没什么变化描述能力一般的查询语句,说是学习成本高。
你们 "顺便弄出来的" 也是很好用的,是集算器多源混算功能的重要一部分,给用户提供方便,也会提升用户黏性。
在我这里,集算器就是当今最牛的结构化计算引擎。VBA 裹脚布;JSA 也就数组循环比 VBA 强;Power Query 顶多混个混合多源,算力太弱;DAX 性能可以,但语法反人类;Python 膏药 pandas 语法晦涩性能一般,polars、ibis 略强但跟 pandas 语法类似不友好;sql 虽然名字统一但语法五花八门,总不能光靠一个 select * from 混日子…其它还有什么,我不知道的就是更不好用的,哈哈 (轻狂了😄)…
多宣传宣传😄