


(已解决) 多线程计算 excel 文件结果不稳定
大佬们,早上好😄
能否帮忙看看以下代码问题出在哪里?多线程运行的结果不稳定。
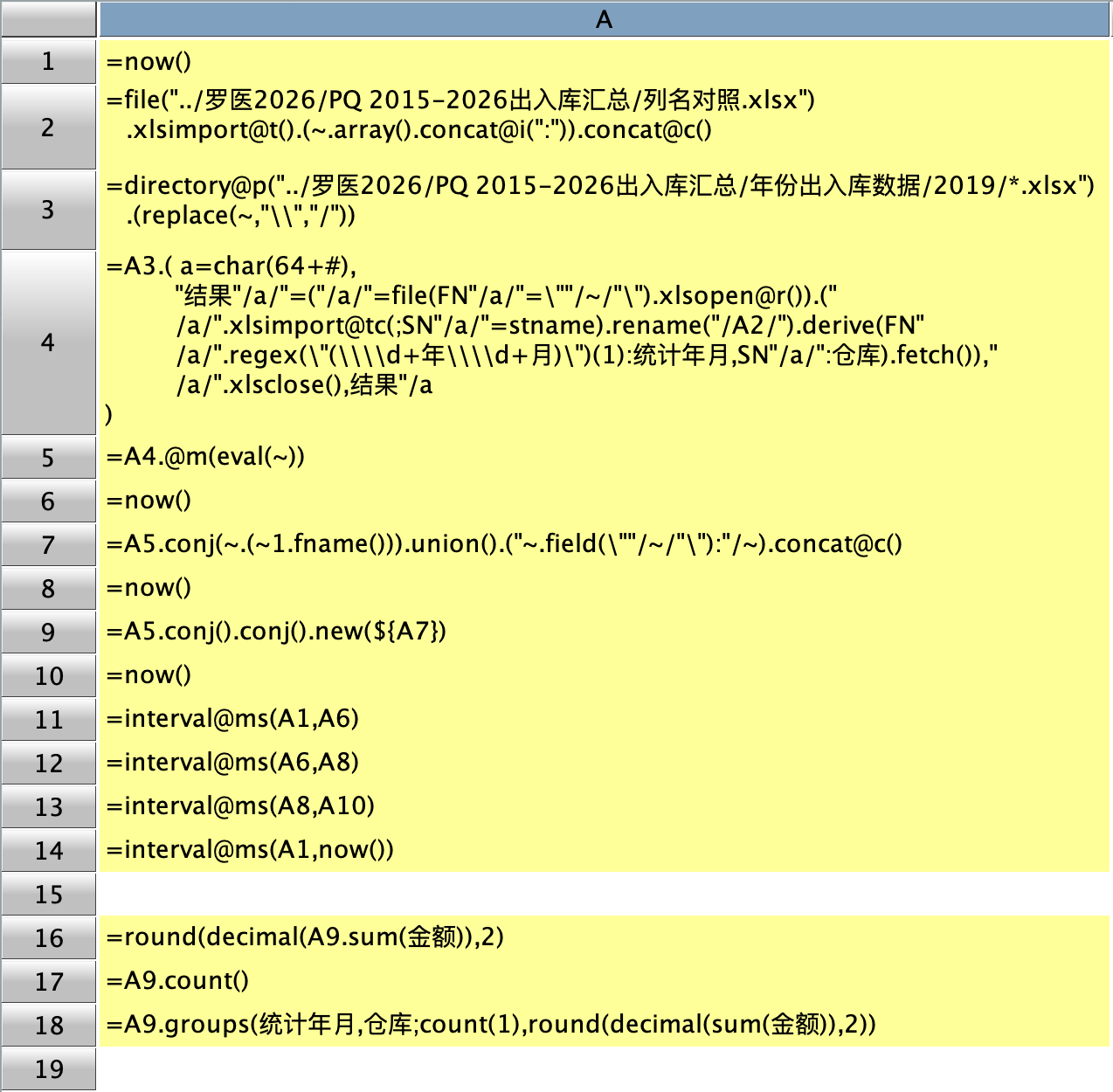
代码有点长还嵌套了,需要点耐心看完,解释如下:
A2: 读取只有两列的表,拼接成字符串 "旧列名: 新列名,…" 的形式,用于后续 rename 的参数;
A3: 获取文件路径,其中的 replace 是替换符号,为了 Win 系统下的路径符号问题,替换后 Mac 和 Win 都能用;
A4: 也是拼接成字符串,只是把包含了函数,形式如下所示。因为用 xlsopen@r 流式打开之后,必须要 xlsclose,想着把不同 xlsopen 对象区分开来命名成 A,B,C,…,把不同的文件对象命名成 FNA,FNB,…, 把每一个 excel 对象解析后的结果命名成结果 A, 结果 B,…,目的是多线程运行的时候可以正确处理不同的对象(不知道对不对?)中间一大堆文字就是 A2 的 rename 列名。

A5: 多线程解析字符串,用 @m、fork 也行;
后面的几个步骤是序表的字段对齐,就不解释了。
主要的问题是 A5 多线程运行后,结果行数飘忽,有时候是对的,有时候会少,刚打开 IDE,首次运行时结果行数经常会少,但再次运行后结果会正确,这是在 Mac 版集算器里的现象,如果在 WIN 桌面版集算器里运行该代码,结果没有一次是正确的。但不用多线程时,把 A5 中的 @m 去掉,代码会返回正确的行数。
所以恳请大佬们帮忙看看问题出在哪里?结果的形式符合预期,但行数飘忽不定。
这里用多线程处理 excel 文件是不是用错了(A4 和 A5),我自己觉得思路没问题,不同的线程处理不同的对象,且不同的对象都有不同的命名,都是有针对性的操作,不至于存在误杀。xlsclose 有没有被正确关闭?是不是一定要关闭 xlsopen 对象?
涉及的文件因为是实例且文件较大,我就不公开上传了,有测试需要时再传。


经测试在新版本中已经修复,暂时可以先把选项 @m 去掉使用。
多谢大佬🙏
我太特么的需要这个并行处理 excel 文件了,至少可以省一半时间。
这周都在折腾这个 excel 合并的事情,疯癫的审计佬要 10 年的数据抽查样本😂
大佬,我刚把集算器更新到了官网上的版本,重新卸载安装后,多线程读取 excel 文件游标依然不稳定。
情况如下,这些都是针对求助帖子中的多线程写法而言的:
1、xlsimport@tc().fetch(),读成游标后 fetch() 时而正常,时而不正常。首次打开 IDE 运行,读数都不对,连续运行两三次后,读数会正常;
2、不用多线程时 xlsimport@tc().fetch() 这个稳定正常读数。
3、xlsimport@t() 直接读成序表,多线程时正常,但运行非常缓慢,稍大的 excel 文件就会 GC;
4、上述是 MAC 版里的现象,WIN 桌面版情况也一样,读数不稳定。
我把涉及到的 excel 文件里的表都转成了 btx 格式后,用同样的方法处理,结果行数是稳定正常的。
所以我想着会不会是 xlsimport@tc() 读成游标时在多线程的情况下没有正常发挥,恳请大佬有空时再测试一下🙏
xlsimport@tc 游标多线程问题解决了😄 谢谢吴楠大佬和 leavedy 大佬🙏 🙏
不碰到这些糟心的 excel 就学不到折腾烂事的本事😂 ,学到不少东西:
1、多序表字段对齐可以用 [序表 1,…].conj().new(~.#字段 1,~.# 字段 2,…),速度很快。
老贼没教这个用法之前,我一直用 json@t(json([ 序表 1,…].conj)),这个 json 操作开销很大,只适合小规模数据;
2、~.field(“字段名”) 这个写法的语法糖:~.# 字段名,但字段名里如果有特殊符号就不能用语法糖,只能用 field 函数;
3、以前很少涉及对大量 excel 工作簿的操作,这次实战之后,对 xlsopen@r 和 xlsimport@tc 多线程流式操作有了认识,速度可以的。
感谢老贼,感谢 spl,感谢大佬们🙏