


软件竞争力 += 润乾 ChatBI,当竞品还在用传统 BI,你已经赢了
现在的软件市场,早已过了“拼功能清单”的时代。你有的报表,我也有;你能拖拽,我也能;你的图表库,我也能拿出差不多的。最后大家陷入同质化泥潭,客户比来比去只能压价,利润越压越薄。
出路在哪里?必须给产品增加新的、能打动人心的竞争力。AI 时代最能提升用户体验、制造产品差异化的,就是ChatBI,让用户用最自然的大白话,直接问数据、做报表,摆脱对技术人员的依赖。
当竞品还在让客户拖拽点选、为一张新报表等上几天时,你的产品已经能“听懂人话”,秒级响应。这种体验上的代差,就是最硬的竞争力。
但现实是,很多软件开发商对 ChatBI 望而却步:大模型方案太贵、太复杂、幻觉问题无解、集成更是噩梦。
有没有既能快速提升竞争力,又不用砸钱砸人、还能保证结果准确的方案?
有。润乾 ChatBI。
润乾 ChatBI:让报表“听懂人话”,体验拉满
润乾 ChatBI 的核心,是让业务人员用最自然的方式——说话,就能完成从数据查询到报表制作的全过程。
NLR:用大白话做报表,这才是真智能
过去,业务人员想做一张新报表,路径只有两条:要么找开发排队,等上几天甚至几周;要么自己研究复杂的 BI 拖拽功能,被各种菜单、选项、公式搞得晕头转向。结果往往是,开发团队被没完没了的报表需求淹没,业务人员的分析灵感也消磨殆尽。
润乾 NLR 改变了这一切,它把报表制作的门槛降到了“会说人话就行”。用户在输入框里像发消息一样打字,系统就能立即响应,完成一系列复杂操作。
我们来看一个完整的例子:业务人员想分析销售情况。
第一步:筛选关键数据
筛选订单金额大于 2000 的大订单,输入如下命令:
过滤 订单金额大于 2000
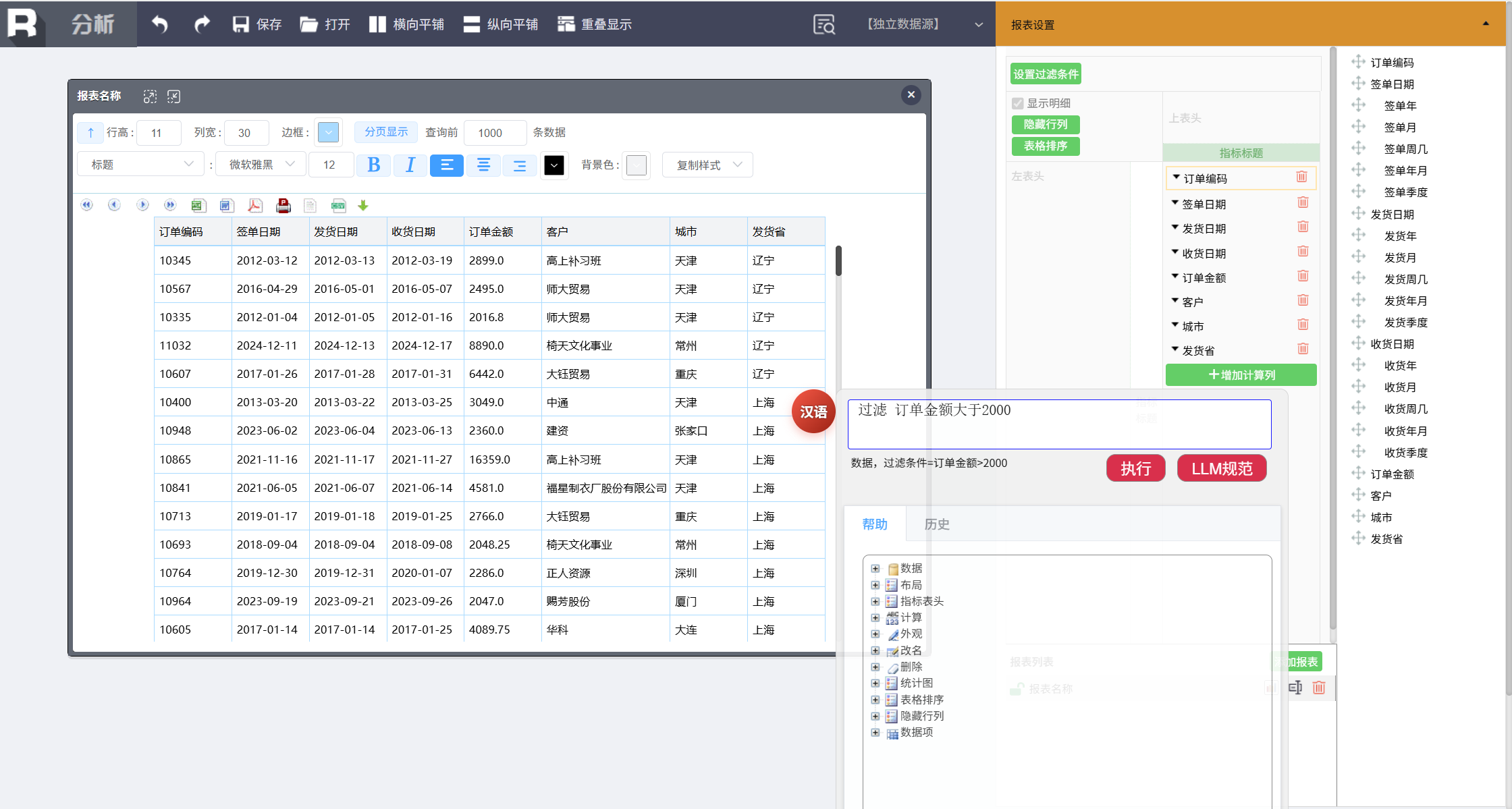
第二步:分组汇总
按照省份和年份汇总大订单金额。先分组,输入:
表头 发货省 签单年
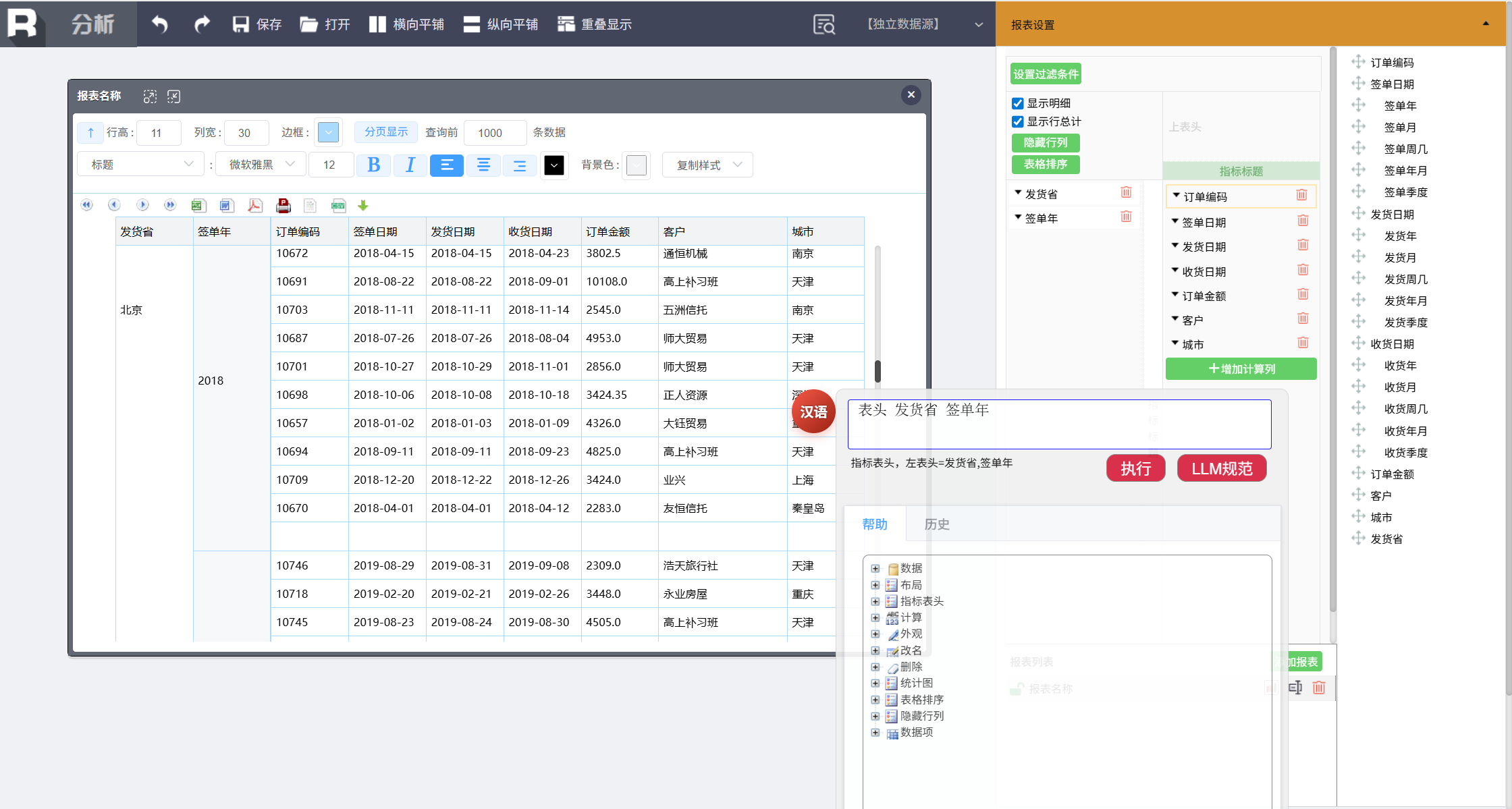
去掉多余列:
删除订单编码 签单日期 发货日期 收货日期 客户 城市
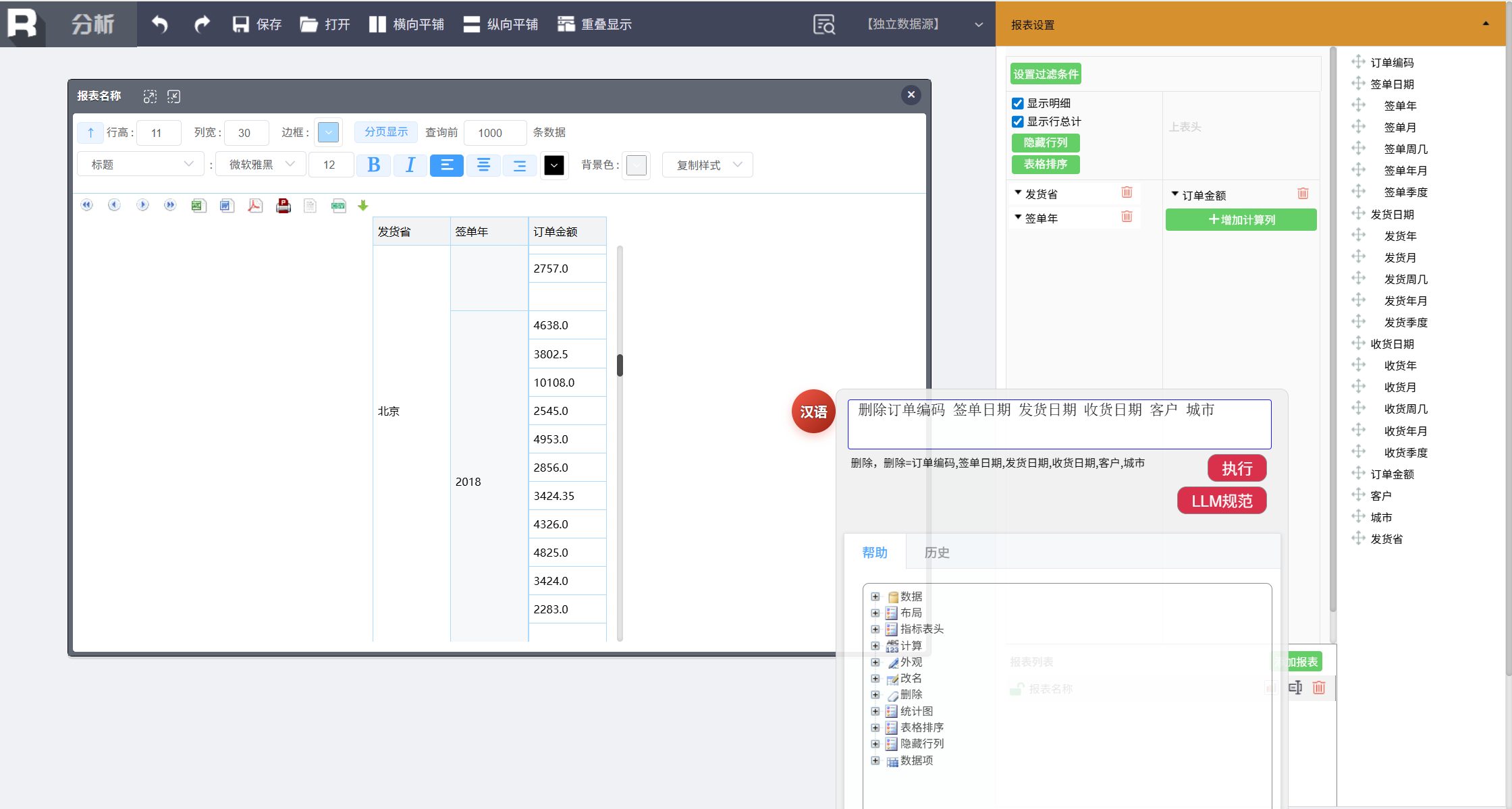
添加汇总指标项:
订单金额求和
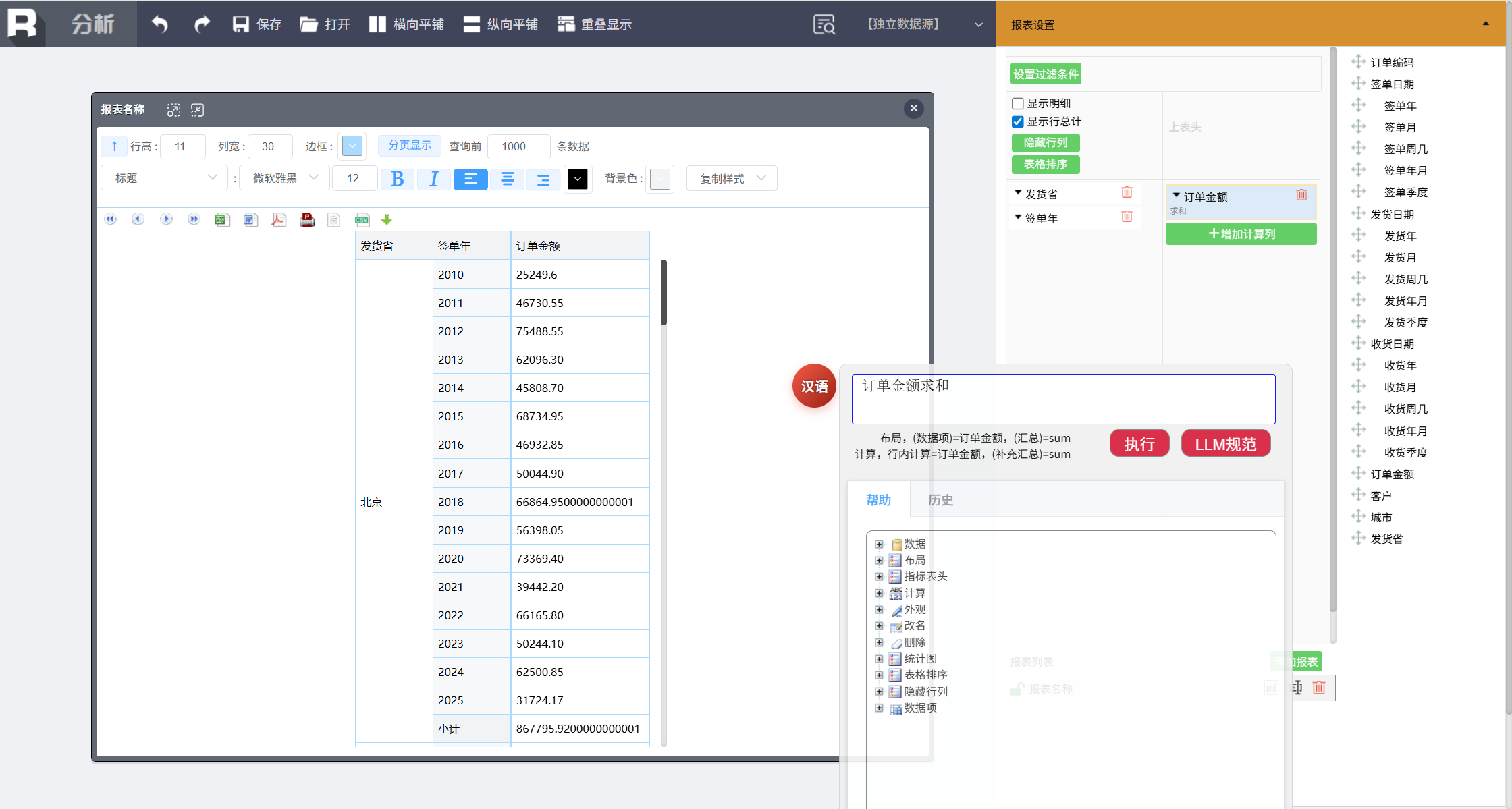
第三步,计算关键指标
计算每个省每年的订单金额环比增长率,输入命令:
在发货省范围内 计算订单金额比例环比 命名为订单环比
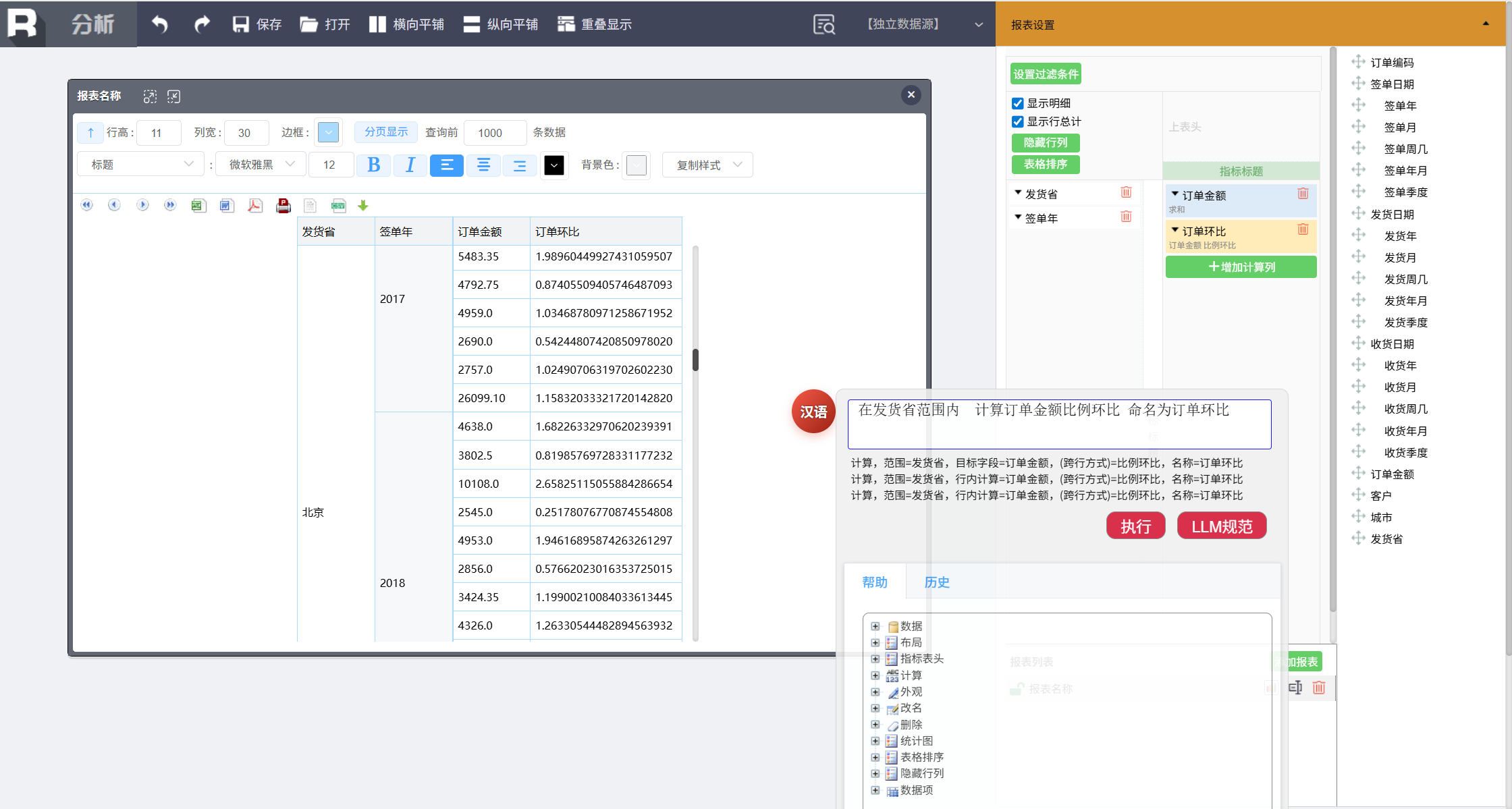
设置环比显示格式:
位置订单环比,显示为 "#0.00%"
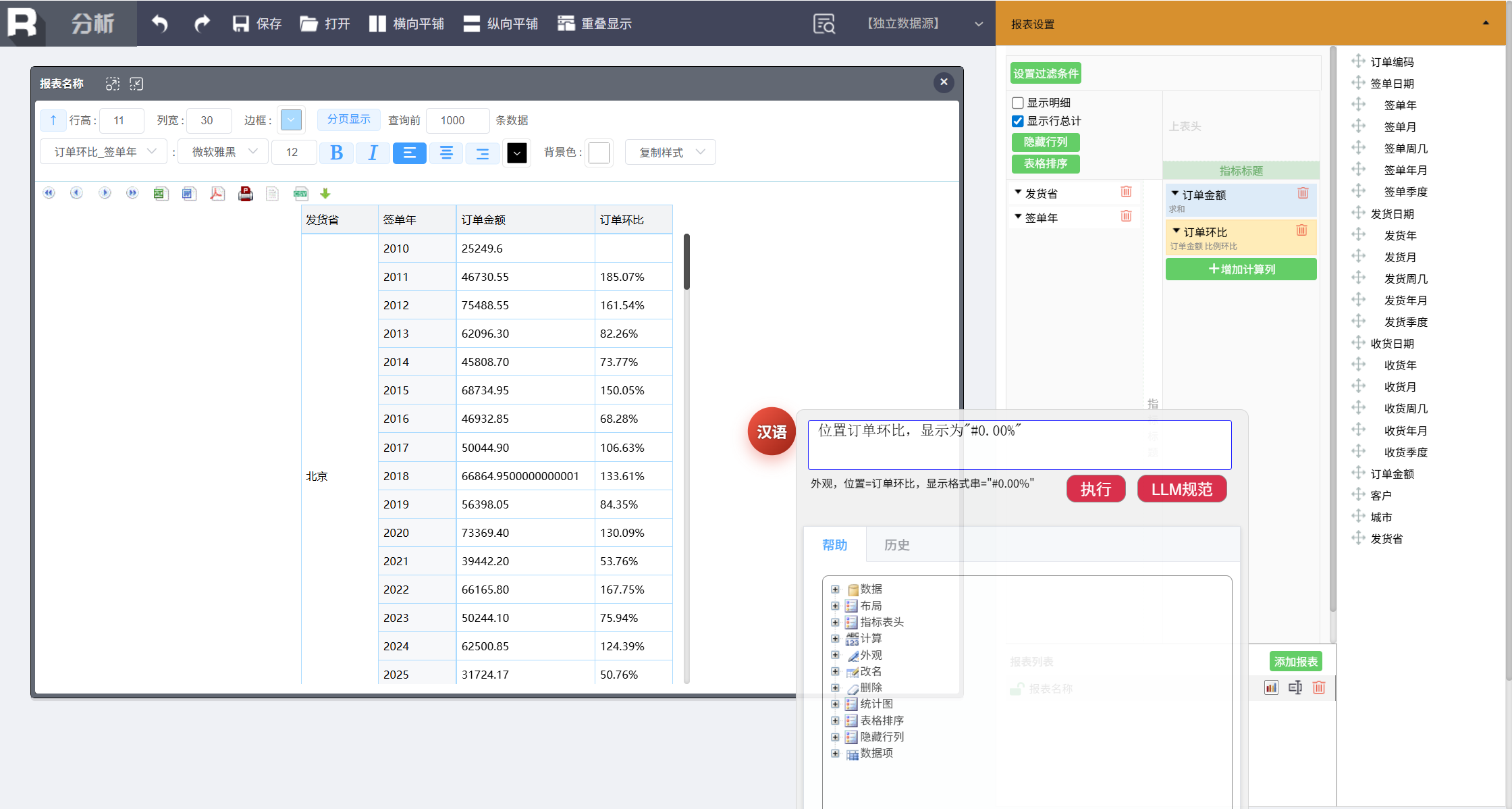
第四步,突出特殊数据
将增长率超过 100% 的订单环比突出显示,输入:
位置订单环比 _ 签单年,大于 1 红色加粗
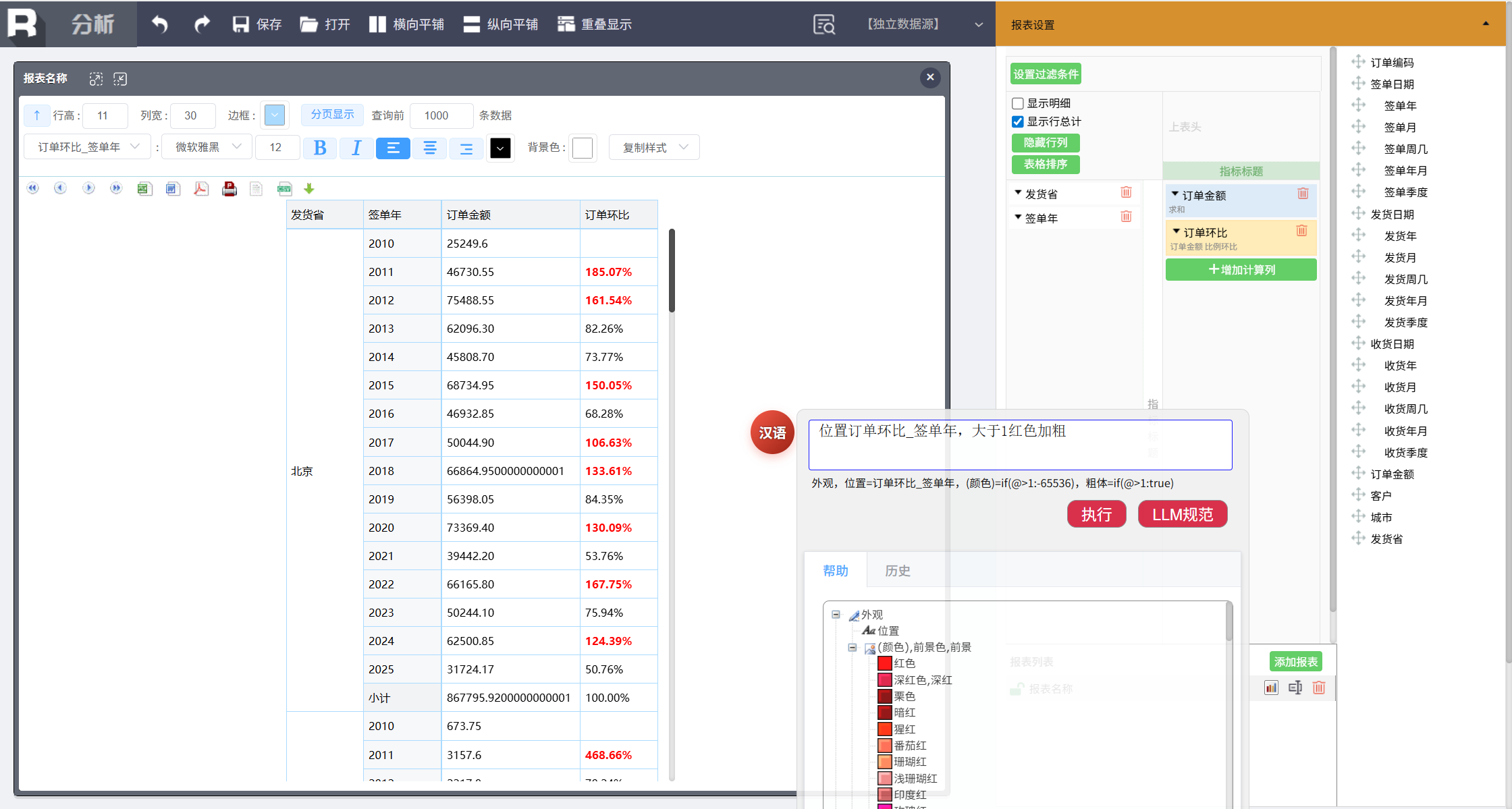
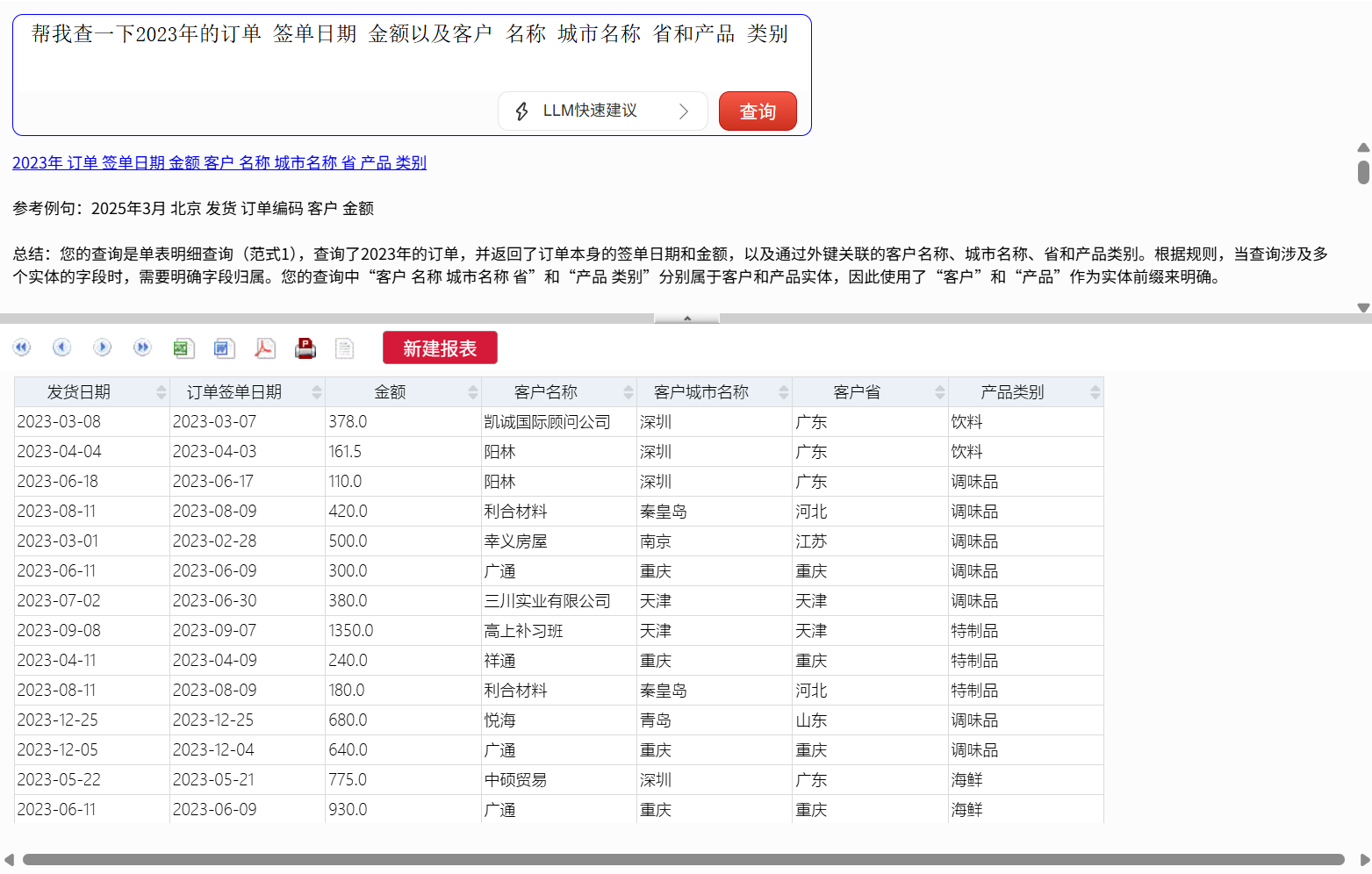
至此,一张针对销售数据的分析报表就已经完成了。这时还想在报表中添加各个地区的销售额统计图。
第五步,添加图表
添加一个各个省份销售情况的统计图,以便从更宏观的角度观察数据。输入:
柱形图 分类 发货省 系列值 订单金额
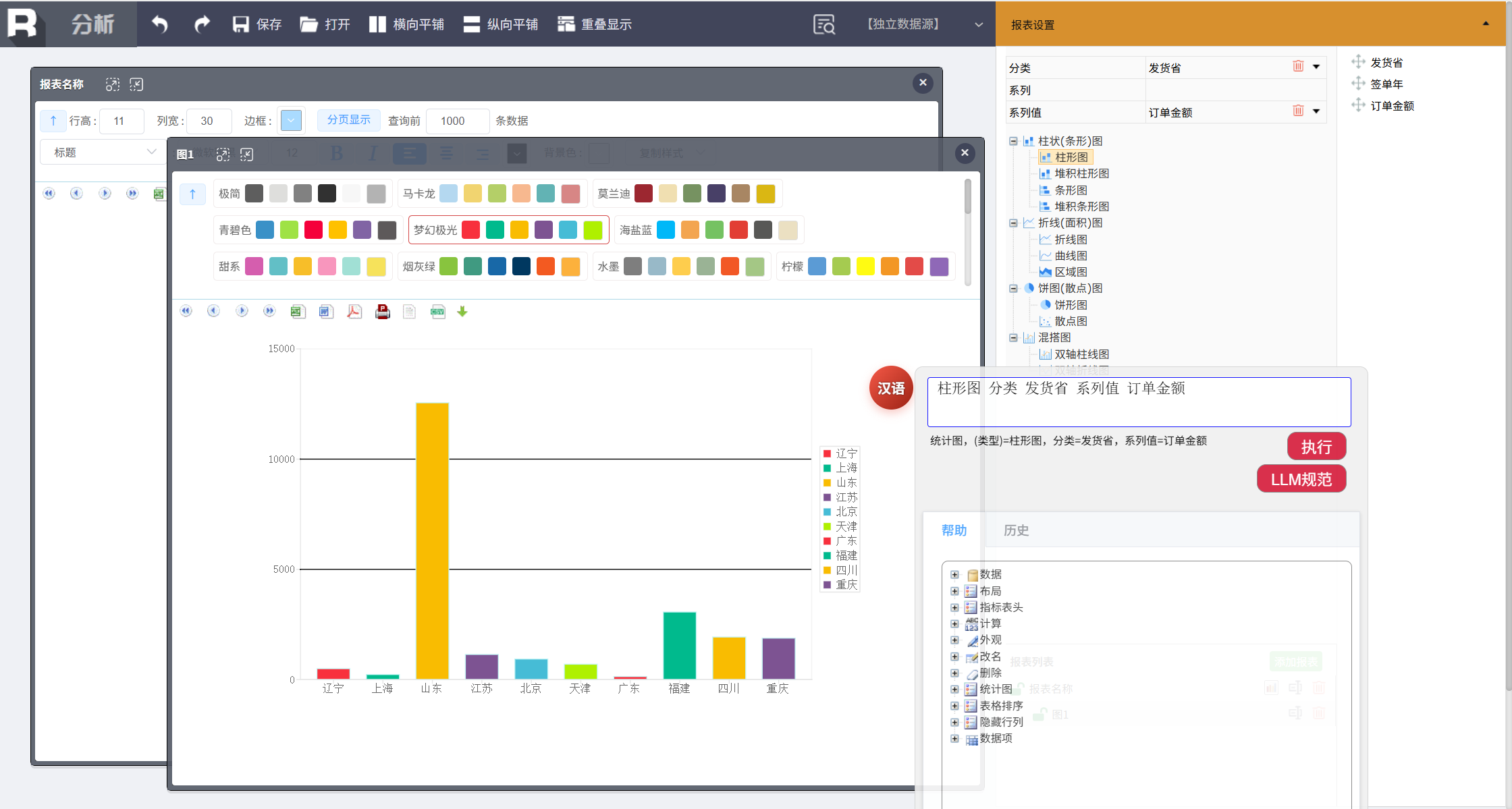
整个过程就像指挥 AI 助手:你说一步,它做一步,随时响应,随时调整。业务人员再也不需要学习复杂的菜单、记忆函数公式,甚至不需要熟悉界面——只需要知道自己想要什么,然后说出来。
这种体验带来的价值是巨大的:
开发团队:从没完没了的报表定制中彻底解放,专注于核心业务开发。
业务人员:可以随时、随地、随心所欲地探索数据,报表需求不再被技术门槛卡住。
当你的产品能让客户自己“说话就能做表”,他们对软件的依赖感和满意度会直线上升。续费率提升 50% 以上,绝不是一句空话。
NLQ:还是大白话,查数据也一句话
做报表之前,往往需要先获取数据。NLQ 让这一步也变得极其简单。用户可以直接用大白话查询数据库,系统自动解析意图,生成精确的 SQL 并返回结果。
例如:
“去年北京地区的订单”
“订单编码、产品名称、供应商名称”
“订单金额总和大于 20 万元的女员工”
无论涉及多表关联、时间条件、聚合计算,NLQ 都能准确理解,秒级响应。它为 NLR 提供了源源不断的“数据原料”,两者无缝衔接,构成了从“查”到“做”的完整闭环。
NLQ 能处理各种复杂场景:
多表关联:用户问“订单编码、产品名称、供应商名称”,系统自动关联订单、订单明细、产品、供应商四张表,生成带多个 JOIN 的 SQL。
嵌套聚合:用户问“订单金额总和大于 20 万元的女员工”,系统先按员工汇总订单金额,再用结果过滤员工表,生成含子查询的复杂 SQL。
多源对齐:用户问“各省的员工数、产品数和订单数”,系统分别从三张表计数后按省份对齐,生成多路 FULL JOIN 的查询。
这些能力都来自后台预先配置的“业务词典”,而非大模型的概率生成,因此结果 100% 准确。
为什么润乾 ChatBI 能让你“稳赢”
很多开发商不是没想过上 ChatBI,但被大模型方案的“三座大山”压得喘不过气:成本高、集成难、结果不靠谱。润乾 ChatBI 用完全不同的技术路径,把这三大难题一一化解。
规则引擎,结果 100% 准确,没有幻觉
大模型的“幻觉”是致命伤。数据一旦出错,客户对产品的信任瞬间崩塌。
润乾 ChatBI 的背后不是黑盒的大模型,而是一套开发商自己就能配置的“业务词典”和规则引擎。你只需要把自己熟悉的业务术语(如“订单”“销售额”“环比”)通过可视化界面映射到数据库,系统就能像查字典一样精准理解问题。
词典里没有的词,它会明确提示“无法识别”,绝不胡猜。每一步转换都可追溯,出了问题能快速定位修复。当业务逻辑变化时(比如“销售额”的计算规则需要扣除运费),管理员只需在词典里修改公式,整个过程非常简单。结果 100% 准确,客户敢信、愿用,最终形成依赖。
极致成本,硬件、软件、人员全省钱
硬件:规则引擎跑在普通 CPU 上,无需昂贵的 GPU,也没有 Token 费用。一套大模型方案,GPU 服务器月费可能上万,而润乾 ChatBI 的硬件投入几乎为零。
软件:具备 ChatBI 功能的版本仅需三万一年,且不限使用数量。相比同行动辄几十万的报价,省下的都是纯利润。
人员:业务词典配置由现有报表开发人员完成,半天上手,不需要高薪聘请 AI 工程师。一个懂业务的产品经理就能搞定,无需组建专门的 AI 团队。
私有化部署,数据安全无忧
对于企业客户来说,数据安全是红线。金融、政府、国企都有严格的合规要求,数据绝不能出内网。大模型方案走云端 API 方式面临数据外传风险,想要私有化部署成本高到离谱。
润乾 ChatBI 天生支持私有化部署。规则引擎、业务词典都可以完全部署在客户内网,与外界物理隔离。数据无需出域,没有外传风险。对于安全敏感型客户,这是“能不能用”的先决条件,润乾 ChatBI 从一开始就满足。
天生可集成,半天搞定
润乾 ChatBI 与报表引擎一体设计,纯 Java 组件,通过 jar 包引入、tag-lib 调用,就能直接嵌入现有系统页面。用户打开熟悉的界面,报表就在手边,感觉不到“用了另一个软件”。权限沿用原系统,数据安全无缝继承。
一个普通 Java 工程师半天就能完成集成,无需做复杂的单点登录、两套权限体系融合。这种“无感集成”,让 ChatBI 能力真正成为你产品的一部分,而不是一个需要额外维护的独立系统。
不止 Chat:传统功能一样不差,还有独门绝技
有了润乾 ChatBI,你的产品已经能在体验上领先一个身位。但这还不是全部——在传统 BI 功能上,润乾一样不差,也更有特色。
该有的都有,而且更细致
润乾在报表领域深耕二十多年,客户需要的功能全都有:
复杂报表:支持各种中国式复杂报表格式。
拖拽操作:所见即所得的报表设计界面。
多维分析:切片、钻取、旋转等操作一应俱全。
复杂计算:同比、环比、排名、占比等跨行组运算。
丰富图表:内置 Echarts 各种统计图,满足可视化需求。
而且细节到位,比如很多 BI 工具不支持合并单元格,润乾却考虑到了那些有格式需求的场景,可以轻松实现。这些细节,正是产品“好用”的体现。
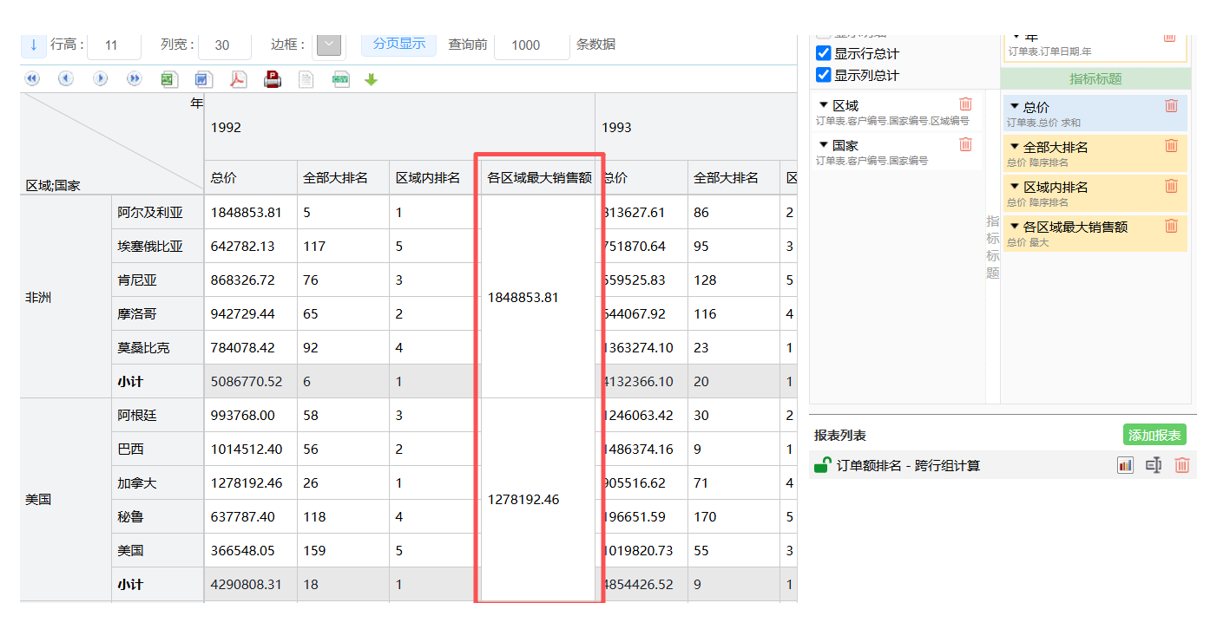
独有 DQL,让复杂关联像查单表一样简单
传统 BI 遇到复杂多表关联(比如六七个 JOIN),要么提前做宽表建模,业务一变化就得等开发;要么性能崩掉,根本无法实时响应。
比如要查询“北京打往上海的通话记录,需要主叫姓名、被叫姓名、通话时长、资费情况”。这个查询涉及的 SQL 需要六七个 JOIN,技术人员看着都头晕。传统 BI 根本没法让业务人员自己拖拽实现,只能让开发做宽表,等上几天。
润乾独创的 DQL(维度查询语言)引擎,通过“外键属性化”让多表关联变得像查单表一样简单。用户在界面上选择“通话记录”作为主体,勾选“主叫用户. 所在城市. 城市名称”“被叫用户. 所在城市. 城市名称”等字段,设置过滤条件,系统自动生成复杂 SQL。
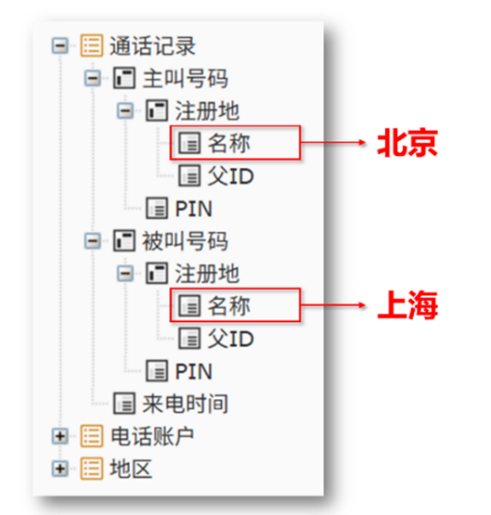
业务人员自己就能随时完成这种复杂制表,再也不用排队等开发。当竞品还在用宽表建模、业务需求变化时只能等待 IT 时,你的产品已经能实时响应任何复杂查询。这种“技术代差”,是竞品怎么也模仿不来的核心竞争力。
润乾 ChatBI 用最务实的方式,规则引擎保准确、私有化部署保安全、极致成本降门槛、天生集成易落地、NLR 体验拉满、DQL 技术筑壁垒,帮你的软件装上“智能翅膀”,让产品从“功能堆砌”升级为“懂你的助手”,让客户从“能用”变成“爱用”。
当竞品还在为“选哪个大模型”“怎么解决幻觉”“怎么承担 GPU 账单”而头疼时,你已经用润乾 ChatBI 快速落地,让客户亲身体验到“说话就能做报表”的畅快。
当竞品还在用宽表建模、业务需求变化时只能让客户等待时,你的产品已经能实时响应任何复杂查询,业务人员自己就能搞定。
当竞品还在同质化功能里拼价格时,你已经用润乾的极致成本,把省下的每一分钱都变成了利润空间。
软件竞争力 += 润乾 ChatBI,这不是加法,而是乘法。当竞品还在传统 BI 里内卷时,你已经赢了。

