


没有 GPU 不用 LLM 能把 ChatBI 做到什么程度?
在这个言必称“大模型”的时代,当几乎所有智能问数方案都在比拼谁的模型更大、谁用的 GPU 更多时,我们却要提出一个“离经叛道”的问题:
如果抛开大语言模型(LLM)和昂贵的 GPU 算力,仅凭一套精心设计的规则体系,我们能把 ChatBI(也就是自然语言驱动的数据查询与自助分析)做到什么程度?
答案是:比你想象中更强大、更可靠,且已经足以解决一个确定领域内大部分的实际问题。
润乾 ChatBI 正是这条技术路径的实践者。它不依赖于概率生成,不进行“黑箱”推理,而是通过构建一个深度结构化、可解释的“领域专用语言理解系统”,实现了在商业智能(BI)场景下,从自然语言查询(NLQ)到自然语言报表分析(NLR)的全流程高准确率转换。
为什么可以不用 LLM?领域语言的“收敛性”是关键
要理解这条路径的可行性,首先要打破一个迷思:并非所有自然语言都是天马行空、无限自由的。
在特定的专业领域,比如企业的商业智能分析,人们用于查询和分析数据的语言,存在着极强的模式和规律。它更像是“行业黑话”或“专业术语”,而非随意的日常聊天。
试想这些业务场景:
“查一下上月华东区的销售 TOP10。”
“对比一下 A 产品和 B 产品本季度的毛利率。”
“列出回款周期超过 90 天且合同金额大于 100 万的客户。”
“按产品类别分组,计算销售额占比,并生成饼图。”
“计算各省的订单环比增长率,用红色标出下降的省份。”
这些语句虽由自然词汇构成,但其语义结构高度收敛:
意图明确:无非是“查明细”、“做聚合”、“搞对比”、“分组汇总”、“计算指标”、“生成图表”。
对象固定:围绕“销售”、“产品”、“客户”、“订单”等有限的业务实体。
逻辑模式化:条件(过滤)、分组(维度)、计算(指标)的组合方式是可枚举的;分析动作(排名、环比、占比、图表)也是固定的。
这就像下围棋,虽然棋盘上的可能性近乎无限,但高手们的“棋谱”和“定式”却是有限的、可学习的。润乾 ChatBI 要做的,不是学会人类的全部语言,而是精通BI 查询与分析这门“方言”的典型“定式”。
核心引擎:一本可无限扩展的“业务词典”与“语法手册”
当然,让机器精通这门“方言”也不容易。润乾 ChatBI 的解决方案是构建一个结构化的领域知识库,它由两部分构成:
业务词典:将每个词汇锚定到数据世界
词典是一个多层次、关系化的映射网络:
实体与字段:“订单”对应哪张表?“销售额”对应哪个字段,其计算公式是什么?
维度与成员:“城市”是一个分析维度,“北京”、“上海”是其成员,映射到数据库中的编码 30101、30102。
动词与关系:“发往”这个动词,定义了其左侧参数应匹配“发货”字段簇(如发货城市),右侧参数应匹配“收货”字段簇(如收货城市)。
量词与转换:“万元”是一个量词,定义其换算系数为 10000,使“大于 20 万元”能被自动转换为 > 20*10000。
分析动作:“排名”、“环比”、“饼图”等,每个动作对应一套预先定义的计算逻辑和图表生成规则。
语法手册:定义词汇如何组成合法查询与分析指令
这套规则定义了如何解析一个查询或分析句子的结构:
组合规则:“发货 城市 日期”应被识别为一个整体(字段簇),返回“发货城市”和“发货日期”两个字段。
消除歧义:当“日期”单独出现时,默认指向“签单日期”;但在“发货 日期”上下文中,则明确指向“发货日期”。
逻辑连接:“且”、“或”定义了多个过滤条件之间的布尔关系。
分析指令格式:“表头 产品类别,订单金额求和”表示分组汇总;“订单金额 降序排名 命名为排名”表示计算排名;“柱形图 分类 省份 系列 订单金额”表示生成图表。
这个“词典”加“语法”的体系,构成了一个确定性的、可解释的编译系统。它的工作方式不是“生成”,而是“匹配”与“转换”。
从自然语言到数据查询:一场精准的“编译”之旅
当用户输入一句查询,系统会启动如下流程,这更像一个编程语言的编译过程:
第 1 步:分词与词法分析
输入:“去年北京发往青岛的订单”
→ 分词:【去年】【北京】【发往】【青岛】【订单】
→ 过滤无效词(如“的”)。
第 2 步:语义标注与匹配
【去年】→ 识别为时间维词,计算为 year(ADDYEARS(now(),-1))。
【北京】→ 匹配“城市”维的常数词,值 =30101。
【发往】→ 识别为动词,触发规则:左参绑定“发货城市”,右参绑定“收货城市”。
【青岛】→ 匹配“城市”常数词,值 =20201。
【订单】→ 识别为核心查询实体(订单表)。
第 3 步:语法树构建与中间语言生成
根据匹配结果和语法规则,构建出结构化的查询意图树,并将其转换为精确的中间查询语言(MQL):
SELECT 订单编码, 客户, 金额, ...
FROM 订单实体
WHERE (发货日期 #Year = year(ADDYEARS(now(),-1)))AND ( 发货城市 =30101) AND (客户城市 =20201)
第 4 步:编译与执行
MQL 会被进一步编译为针对底层数据引擎的可执行指令。对于相对简单的查询,直接生成 DQL(消除表间关联)后转换成 SQL 查询数据;对于涉及复杂计算(如“连涨天数”)的查询,则会在取数后调度专门SPL引擎再处理。
上面这个例子最后执行的 SQL:
SELECT
YEAR(T_1_1.SHIPDATE) AS "发货日期_Year",
T_1_1.SHIPCITY AS "发货城市",
T_1_2.CITYCODE AS "客户城市",
T_1_1.ORDERID AS "订单编码",
T_1_1.SIGNDATE AS "签单日期",
T_1_1.SHIPDATE AS "发货日期",
T_1_1.RECEIVEDATE AS "收货日期",
T_1_1.AMOUNT AS "订单金额"
FROM ORDERS T_1_1
LEFT JOIN CUSTOMER T_1_2 ON T_1_1.CUSTOMERID = T_1_2.CUSTID
WHERE
(YEAR(T_1_1.SHIPDATE) = YEAR(DATEADD('yy', -1, NOW())))
AND (T_1_1.SHIPCITY = 30101)
AND (T_1_2.CITYCODE = 20201)
看看 SQL 中这些表的别名,明显不是人写的。这里已经有了令很多单纯基于大模型方案生畏的 JOIN,不过这还算是最简单的。
整个过程,没有猜测,只有映射;没有幻觉,只有逻辑。其可靠性的根源,在于将自然语言中不确定的部分,通过“业务词典”的映射,转化为机器世界中完全确定的数据操作。
从查询到分析:自然语言驱动的自助报表
获取数据只是第一步,真正的分析往往才刚刚开始。润乾 ChatBI 将同样的规则引擎延伸至分析阶段,提供了NLR(自然语言报表)能力:用户可以基于查询得到的数据集,继续用简洁的汉语指令驱动报表完成各种分析动作。
再来看一个完整的例子
先查询:用户输入“去年北京发往青岛的订单 订单金额,客户,产品,产品类别,供应商”,系统返回一份包含订单金额、客户、产品、类别、供应商的明细数据。
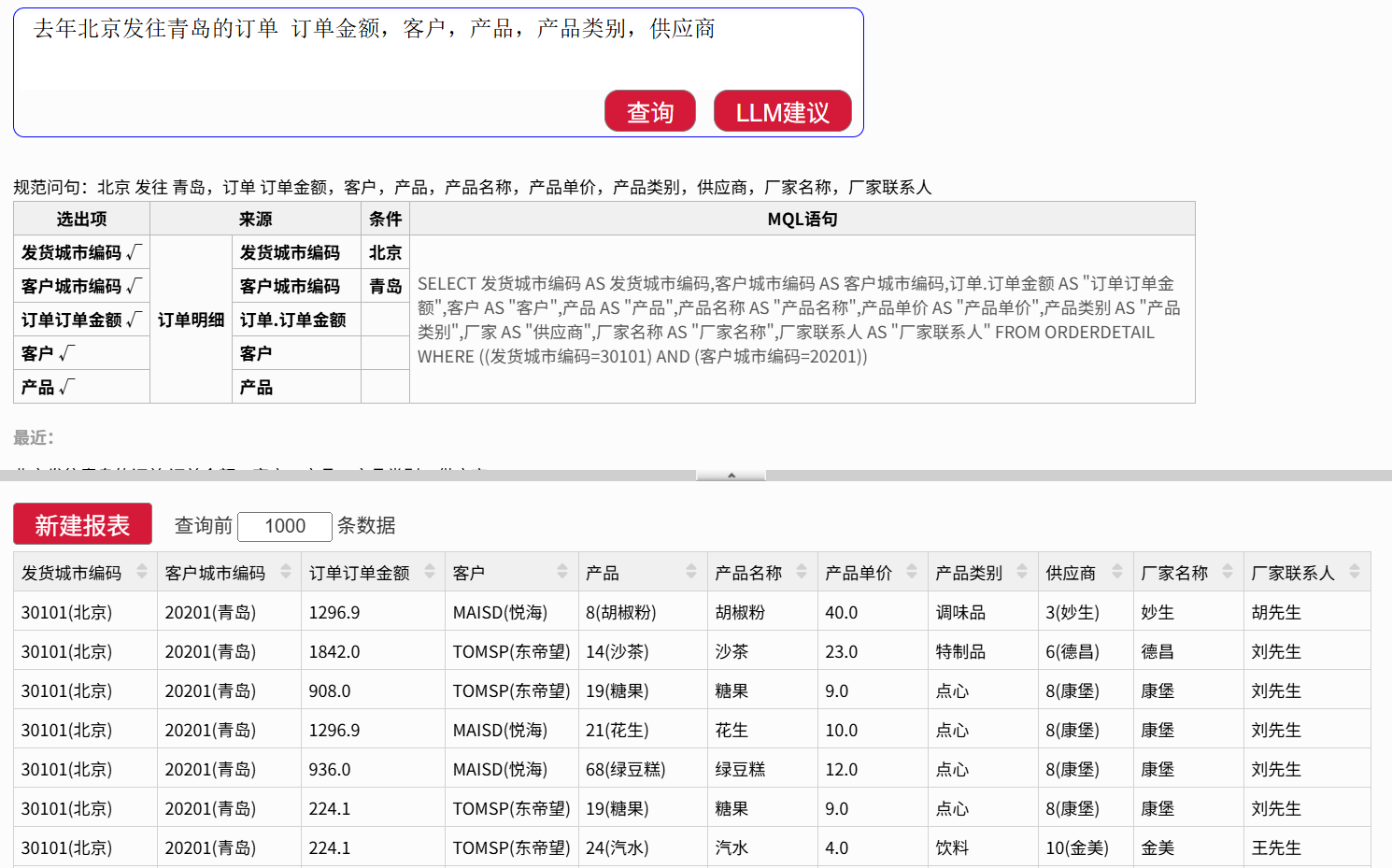
再分析:
按产品类别分组汇总:输入“表头 产品类别,订单金额求和”,系统立即按类别汇总。
计算占比:输入“金额 计算占比 命名为类别占比”,系统新增占比列,显示每类占比。
类别内供应商排名:输入“在产品类别范围内 订单金额 降序排名 命名为供应商排名”,系统在各类别内对供应商按金额排名。
筛选大额订单:输入“过滤 订单金额大于 10000”,只显示大额订单。
生成饼图:输入“饼图 分类 产品类别 系列 订单金额”,系统生成占比饼图。
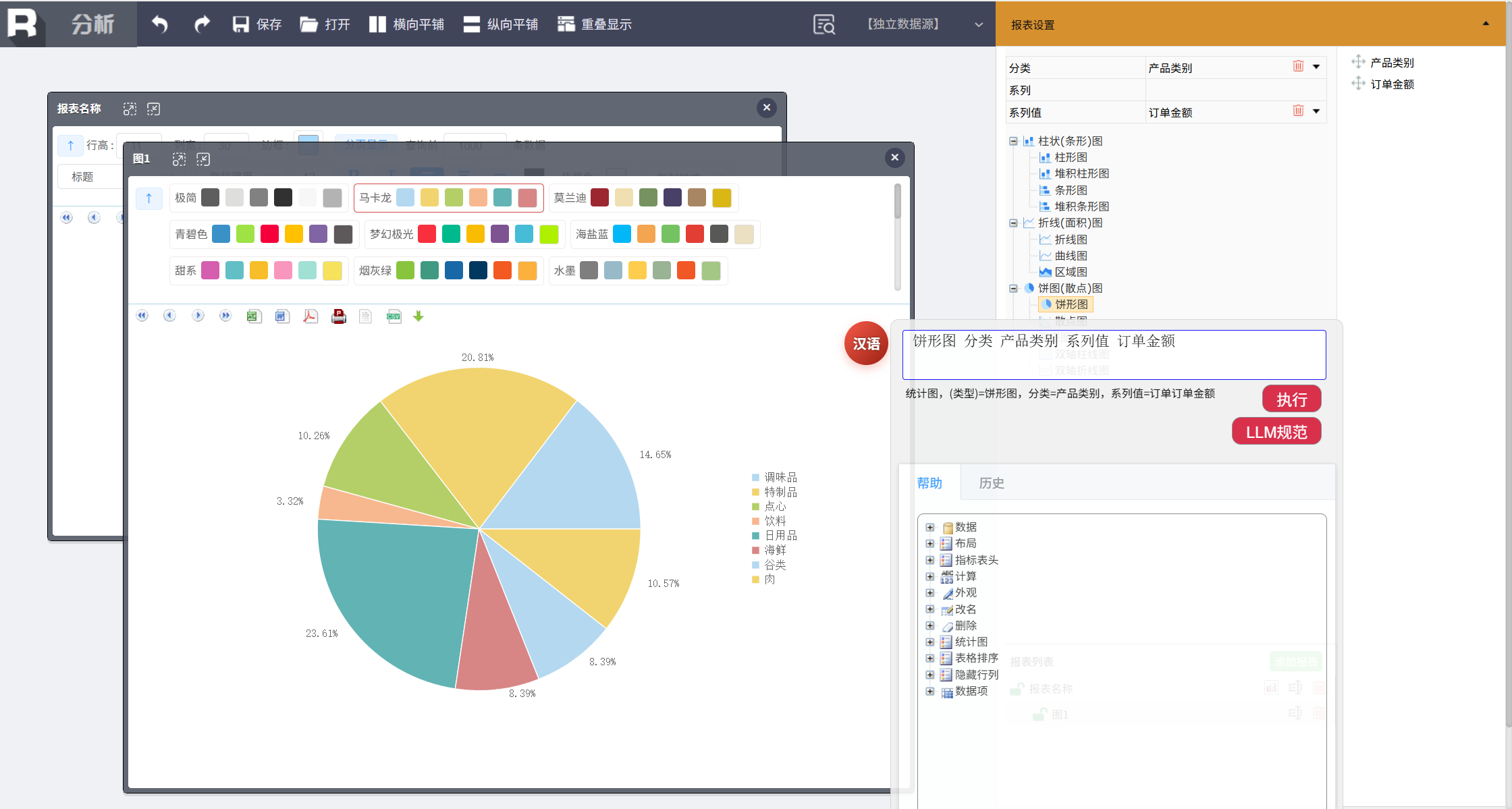
整个过程无需拖拽、无需写公式,所有指令在数秒内精准响应。无论是分组汇总、排名占比、数据筛选,还是图表生成,用户只需像与助手对话一样,逐步深入,就能从原始数据中提炼出有价值的业务洞察。
分析能力覆盖范围
NLR 支持的分析动作包括但不限于:
分组汇总:表头 产品类别,订单金额求和、表头 省份 年份
占比计算:订单金额 计算占比 命名为‘占比’
排名:订单金额 降序排名 命名为‘排名’、在产品类别范围内 订单金额 降序排名
环比 / 同比:订单金额 计算比例环比 命名为环比、在省份范围内 订单金额 计算同比
累计:订单金额 计算累计求和
格式调整:订单金额显示为货币格式、占比显示为‘#0.00%’
条件格式:大于 2000 红色加粗
数据筛选:过滤 订单金额大于 10000、过滤 产品类别 =‘电子产品’
排序:排序 产品类别升序,订单金额降序
行列转换:左表头 产品类别,上表头 供应商
图表生成:柱形图 分类 产品类别 系列 订单金额、折线图 分类 签单月 系列 订单金额
配色切换:梦幻极光、科技蓝
所有分析指令均由规则引擎精准执行,结果确定、可解释,与查询阶段无缝衔接。
能力边界实测:究竟能应对多复杂的场景?
脱离 LLM 的规则引擎,能力天花板在哪里?让我们通过一组查询实例,不同类型和复杂度来具体展示。润乾 ChatBI 的解析能力足以覆盖绝大多数数据分析需求。
明细查询:想要什么数据,直接列出来
从最基础的字段查看到智能的跨表组合,NLQ 都能精准应对。
简单列举:
“列出雇员姓名”
“商品编码、名称、重量、类别、库存量”
像点菜一样说出字段名,数据即刻呈现。
附带计算:
“雇员姓名、身高、体重、BMI 指数”
即使像“BMI 指数”这样的计算字段,只要预先定义好公式(如:体重 / 身高²),查询时就能自动算出。
智能消歧与组合:
“订单编码,发货 城市 日期,收货 城市 日期”
系统通过“发货”、“收货”等簇词,自动区分并返回“发货城市”、“发货日期”、“收货城市”、“收货日期”四列数据,无需人工指定复杂表头,完美消除歧义。
跨表关联(多表关联示例):
查询语句:“订单编码,订单日期,产品名称,供应商名称和城市”
查询意图:用户想看到订单号、对应的产品名、该产品的供应商名及供应商所在城市。这需要自动关联订单、订单明细、产品、供应商至少四张表。
NLQ 生成的 MQL(清晰简洁):
SELECT 订单 AS 订单编码,订单.发货日期 as 订单日期,产品.产品名称 AS 产品名称,厂家.供应商名称 AS 供应商名称,厂家.供应商城市编码 AS 供应商城市
FROM orderdetail
编译后执行的 SQL:
SELECT T_1_1.ORDERID "订单编码",T_1_2.SHIPDATE "订单日期",T_1_3.PRODUCTNAME "产品名称",T_1_4.NAME "供应商名称",T_1_4.CITY "供应商城市"
FROM ORDERDETAIL T_1_1
LEFT JOIN ORDERS T_1_2 ON T_1_1.ORDERID=T_1_2.ORDERID
LEFT JOIN PRODUCT T_1_3 ON T_1_1.PRODUCTID=T_1_3.PRODUCTID
LEFT JOIN SUPPLIER T_1_4 ON T_1_3.SUPPLIERID=T_1_4.SUPPLIERID
这句 SQL 有了三个 LEFT JOIN,需要清晰理解四张表关联关系才能写出的这样的语句。
复杂过滤:条件再刁钻,也能精确定位
NLQ 能够理解并处理各类业务场景下的复杂筛选逻辑。
多条件与逻辑组合:
“年龄 45 到 50 岁之间,且籍贯是北京的雇员”
“单价大于 100 或小于 10 的订单明细”
完美支持“且”、“或”、“在... 之间”等逻辑,进行精确筛选。
业务术语过滤(宏词):
“已售罄的商品信息”
只需将“已售罄”定义为宏词(对应逻辑:库存量 <= 0),即可用最直观的业务语言直接查询。
动词关联过滤:
“北京发往青岛的订单”
通过“发往”这个动词,系统能自动将“北京”绑定到发货城市,“青岛”绑定到收货城市,构建出发货城市 ='北京' AND 收货城市 ='青岛' 的关联条件。
时间智能处理:
“去年第 3 季度的订单”
“上周一的会话记录”
系统能理解“去年”、“上周”、“第 N 季度”等丰富的相对时间描述,并自动转换为数据库可执行的准确日期范围。
聚合分析:不只查看,更要洞察
从基础汇总到嵌套的聚合后过滤,NLQ 让数据分析师的工作更高效。
基础汇总:
“各城市发货的总金额”
“每月订单数”
轻松完成按维度分组和求和、计数等聚合计算。
聚合后筛选:
“总订单数超过 20 的客户”
“平均售价超过 500 元的海鲜商品”
先按业务逻辑完成聚合计算(如:每个客户的订单总数),再对聚合结果进行筛选(HAVING 子句逻辑),直达关键群体。
嵌套聚合(子表聚合条件查询示例):
查询语句:“订单金额总和大于 20 万元的女员工”
查询意图:先按员工汇总其所有订单的总金额,再筛选出总金额 >20 万且性别为女的员工。这涉及对子表(订单)的聚合,并用聚合结果过滤主表(员工)。
NLQ 生成的 MQL(逻辑分明):
SELECT 性别 AS 性别,雇员编码,姓名,职务,出生日期,年龄,ORDERS.sum(订单金额) AS 订单金额总和
FROM EMPLOYEE
WHERE (性别='女')
JOIN ORDERS
HAVING (ORDERS.sum(订单金额)>20*10000)
编译后执行的 SQL(展现多层逻辑):
SELECT e.Name AS 员工姓名,e.Gender AS 性别, SUM(o.Amount) AS 订单金额
FROM Employees e
INNER JOIN Orders o ON e.EmployeeID = o.SalesPersonID
WHERE e.Gender = '女'
GROUP BY e.EmployeeID, e.Name, e.Gender
HAVING SUM(o.Amount) > 200000
将需要深刻理解 SQL 中 WHERE、GROUP BY、HAVING 子句区别及执行顺序的复杂查询,简化为一句平实的业务描述。
混合关联与复杂指标:应对综合业务场景
面对跨主题域整合和高级计算需求,NLQ 借助分层架构同样能够胜任。
多数据表汇总对齐:
查询语句:“各省的员工数、产品数和订单数”
查询意图:需要分别从员工表、产品表、订单表中计数,再按“省份”维度对齐结果。
技术核心:这类查询的难点在于多表关联时的维度对齐。传统 Text2SQL 方案在此极易出错,生成错误的 JOIN 逻辑。润乾 NLQ 能自动识别“省”是三个表的公共分析维度,理解用户意图是进行“同维汇总与对齐”,而非简单的表连接。
NLQ 生成的 MQL(体现维度对齐逻辑):
SELECT EMPLOYEE.count(1) AS 员工数, PRODUCT.count(1) AS 产品数, ORDERS.count(1) AS 订单数
ON Province AS 省
FROM EMPLOYEE
BY 籍贯省
JOIN PRODUCT
BY 供应商省
JOIN ORDERS
BY 发货省
编译后执行的 SQL:
SELECT
COALESCE(T_1.F_1, T_2.F_1, T_3.F_1) AS "省",
T_1.F_2 AS "员工数",
T_2.F_2 AS "产品数",
T_3.F_2 AS "订单数"
FROM (
SELECT T_1_2.PROVINCE AS F_1, COUNT(1) AS F_2
FROM EMPLOYEE T_1_1
LEFT JOIN CITY T_1_2 ON T_1_1.HOMECITY = T_1_2.CITYCODE
GROUP BY T_1_2.PROVINCE
) T_1
FULL JOIN (
SELECT T_2_3.PROVINCE AS F_1, COUNT(1) AS F_2
FROM PRODUCT T_2_1
LEFT JOIN SUPPLIER T_2_2 ON T_2_1.SUPPLIERID = T_2_2.SUPPLIERID
LEFT JOIN CITY T_2_3 ON T_2_2.CITY = T_2_3.CITYCODE
GROUP BY T_2_3.PROVINCE
) T_2 ON T_1.F_1 = T_2.F_1
FULL JOIN (
SELECT T_3_2.PROVINCE AS F_1, COUNT(1) AS F_2
FROM ORDERS T_3_1
LEFT JOIN CITY T_3_2 ON T_3_1.SHIPCITY = T_3_2.CITYCODE
GROUP BY T_3_2.PROVINCE
) T_3 ON COALESCE(T_1.F_1, T_2.F_1) = T_3.F_1
这句 SQL 更是嵌套了带有分组汇总的子查询,已经相当复杂,对某些 Text2SQL 方案已经是噩梦般的存在,但在 NLQ 模型下仍然可以正确无误地生成。
通过这些例子可以看到,基于规则的润乾 NLQ 引擎并非只能处理简单查询。通过精心设计的MQL中间语言、DQL 维度关联机制以及 SPL 计算引擎(实现 SQL 不易完成的复杂指标计算)的协同,它能够理解复杂的业务语义,生成正确且高效的多表关联 SQL,处理嵌套的聚合条件,执行专业的数据分析计算。
其中,DQL层是解决多表关联难题的核心。它通过“外键属性化”机制,将传统 SQL 中复杂的 JOIN 关联,转换为类似“对象. 属性”的直观访问方式。例如,查询中涉及“收货城市”时,DQL 会将其表示为 customerid.citycode(即:外键字段. 目标表字段)。这使 NLQ 在 MQL 层面可以像操作单表一样编写查询,而 DQL 引擎则在底层自动、正确地转换为带 JOIN 的高效 SQL,避免了其它方案在复杂关联时常出现的逻辑混乱或错误关联问题。
坦诚对话:优势与代价,以及那个重要的“不知为不知”
这种基于规则的技术路径带来了独特的优势,但也要求我们坦诚面对其局限性。
无可替代的优势
可解释性与可控性:每一个查询结果都可以精确追溯——是哪条词典规则、哪个字段映射、哪步计算逻辑得出的。调试、优化、审计异常简单。分析动作同样可追溯。
企业级稳定与可靠:无随机性,相同问题永远返回相同逻辑的结果。这种确定性是企业生产系统的生命线。
极致的性能与成本:规则匹配的计算开销极低,毫秒级响应,普通服务器即可实现高并发,运营成本几乎可忽略不计。没有 GPU 依赖,没有 Token 费用。
私有化部署,数据安全:全栈可部署在内网,数据不出域,满足金融、政府等高合规要求。
确定的能力边界
润乾 ChatBI 的准确是建立在“已知世界”(即预置的业务词典和分析指令集)的完备性之上,对于超出其认知范畴的查询或指令,将无法理解或给出准确响应。比如:
无法识别未定义的业务新词:如果未在词典中配置“用户互动热度”及其计算规则,用户直接查询此指标将失败。
难以解析不规范的口语表达:面对如“我需要查询商品表中单价在 9 块五毛钱到等于 12 块钱的”或“南京的客户,或者任意直辖市的”这类包含口语化数字、非标准连词或逻辑的句子,需要先转化为规范的查询语句。
分析指令需要规范:如“把销售额最高的几个产品用红色标出来”需要转化为“销售额 降序排名 且 条件格式”等规范指令。
当碰到越过能力边界的问题时,系统会表现出“不知为不知”的可贵品质:这是与 LLM 最根本的区别之一。它会明确告诉你“无法识别”或“请换种说法”。它可能查不出来,但绝不会查错。在数据准确性生死攸关的企业决策场景,这种保守和诚实比“无论如何都给个答案”的勇气更有价值。
必须付出的代价
前期知识注入:需要将企业的数据模型、业务指标、分析维度系统地“翻译”并注入到词典和规则中。这是一个需要业务与 IT 紧密协作的知识工程过程。
迭代依赖人工:当业务逻辑发生变化或需要新增分析视角时,需要手动更新词典和规则。系统本身不具备从交互中自动学习或举一反三的能力。
用 LLM 弥补灵活性,与规则引擎“双打”
我们并非要否定 LLM 的宏大与神奇。通用大模型在理解开放性语言、进行创造性对话方面,是革命性的。正因清晰地认识到上述边界,润乾 ChatBI 与 LLM 的协作才显得尤为恰当与务实。
一个更理想的架构是:LLM 作为“智能前台”,负责与用户进行多轮、随意的口语对话,理解其核心意图,并将其“翻译”成润乾 ChatBI 所能识别的、相对规范的自然语言指令(包括查询指令和分析指令,如“按产品类别分组,计算销售额占比,并生成饼图”)。
这里的优势在于:
中间结果是“人话”,可确认可修改:LLM 的任务是从“随意口语”到“规范书面语”的转换,这远比让它直接生成某种结构化的 JSON 或 SQL 要简单。转换后的文字(如“查询去年北京发往青岛的订单,返回订单金额、客户、产品、产品类别、供应商”)业务用户能看懂并确认,发现不对可以立即纠正。而直接生成 JSON 或 SQL 则难以由不懂技术的业务人员验证。确认后的规范指令再由规则引擎(NLQ/NLR)精准执行,确保最终结果准确无误。
“人话”极大降低了幻觉风险:自然语言是 LLM 的训练母语,将其从口语转为规范书面语是它的“舒适区”,不易产生幻觉。相比之下,要求 LLM 直接生成 JSON 或 SQL 这类结构化数据,相当于让它用外语写作,更容易出现语法错误或逻辑偏差。而且规范的自然语言指令本身就是可读的,用户可直观验证,进一步降低了因误解导致的风险。
成本低:LLM 的任务被简化为“文字规范化”,只需要理解自然语言并重新组织成规范的问句,无需理解复杂的数据库 Schema 或业务逻辑。这种相对简单的任务,私有化部署的小参数模型就能胜任,既享受了 LLM 的交互友好性,又保证了极低的部署和运行成本,同时数据始终留在企业内部。
这种组合方案,相比当前主流的要求 LLM 直接生成 JSON 或 SQL 的做法,在成本、可控性和准确性上都具有显著优势。
未来一步生成查询 + 报表的综合能力
在即将推出的下一版本中,我们将更进一步,实现真正的“综合能力”。届时,系统不仅能处理规范的查询和分析指令,还能应对更模糊的任务指令。例如,用户可以说“分析一下上个月的销售情况”,系统将自动分解任务:
首先,利用 LLM 理解意图,生成规范的自然语言查询(如“查询上个月的订单数据,返回订单金额、产品类别、省份”),由 NLQ 执行获取基础数据。
然后,基于预定义的规则或简单的指令理解,自动匹配合适的分析动作和图表类型(如按产品类别分组汇总、生成趋势图、计算环比),由 NLR 完成分析并呈现。
这种能力的核心优势,依然建立在我们当前方案的基础上:中间环节的可读性和可干预性。无论是 LLM 对模糊任务的分解,还是系统推荐的报表动作,其过程和中间结果都可以被用户理解和调整。用户可以看到系统打算做什么,并在必要时修正,确保最终结果符合预期。这进一步放大了我们方案的优势——在拥抱 AI 灵活性的同时,牢牢把握住决策的“可解释”和“可控”的底线。
在企业核心数据分析领域,我们更需要的是一位值得完全信赖的“领域专家”,而非才华横溢但可能出错的“通才”。润乾 ChatBI 正是这样的专家——它深耕垂直领域,以深度结构化的知识系统,在不依赖 LLM 和庞大算力的情况下,打造出能力强大、结果精准、行为可控、成本低廉的自然语言查询与分析引擎。当您问“上个季度哪些区域的毛利率下滑超过预警阈值,并把下滑省份标红”时,它给出的答案值得百分之百信任。这是一种工程哲学的选择:用前期的确定性知识工程投入,换取生产环境中长期的确定性、高性能、低成本与全可控。技术的价值在于解决真实问题,当一条路被过度聚焦时,另一条路上或许已繁花似锦。欢迎访问演示环境http://query.raqsoft.com.cn:6999/nlq.html,无需注册,立即体验“精准问数”之旅。

