


人人都能实施的智能问数,中小用户也能用得起的 ChatBI
AI 时代,到处都在说“智能问数”,用大白话直接问,数据就给你整得明明白白。理想很美好,可真要一探究竟,大家心里就打了鼓:这玩意儿是不是得养个 AI 科学家团队?是不是得买几十上百万的 GPU 服务器?查出来的数要是不准,谁敢拿来做决策?
别急,润乾 ChatBI 带来了一条不同的路——一条让中小企业、普通开发团队都能轻松上车、用得安心、花得明白的路。不依赖“黑盒”大模型去猜,而是用一套清晰的“规则翻译官”,把业务问题精准无误地转换成数据库能听懂的指令,还能进一步指挥报表完成深度分析。
把业务知识,变成机器的“说明书”
大模型(LLM)像是个天赋异禀但偶尔会跑偏的“实习生”,能力很强,但产出不稳定,关键是你还看不懂他的工作过程,没法有效复核。
其实思路可以更直接:企业的数据分析需求,绝大部分都有规律可循。无论是“上季度华北区销售 TOP10”、“库存低于安全线的产品”,还是“回款周期超过 60 天的客户”,其核心无非是找什么对象(表)、看哪些方面(字段)、按什么条件筛选(过滤)、怎么分组计算(聚合)。而分析阶段的动作,比如“按省份排名”、“计算环比”、“生成趋势图”,同样可以抽象为固定的操作模式。
润乾 ChatBI 的核心,就是把这套业务逻辑和分析动作,预先编制成一套机器能严格执行的“业务词典”和“分析指令集”。当用户提出自然语言请求时,系统会像查字典一样,精准匹配:
查询阶段,如“去年北京发往青岛的订单”,系统会匹配“去年”(时间计算逻辑)、“北京 / 青岛”(城市常数)、“发往”(动词关联发货 / 收货字段)、“订单”(主表),生成精准的 SQL。
分析阶段,如“按产品类别分组,计算销售额占比”,系统会匹配“产品类别”(维度)、“销售额”(指标)、“占比”(分析函数),立即对查询结果执行分组和占比计算。
整个过程没有猜测,只有匹配和执行,从根本上杜绝了“一本正经胡说八道”的数据幻觉。
不止于查询:让分析也能“说人话”
获取数据只是第一步,真正的分析往往才刚刚开始。传统 BI 工具需要拖拽、点选、编写公式,操作繁琐,很多用户望而却步。而润乾 ChatBI 将同样的规则引擎延伸至分析阶段,提供了NLR(自然语言报表)能力:用户可以基于查询得到的数据集,继续用简洁的汉语指令驱动报表完成各种分析动作。
来看一个完整的例子:
先查询:用户输入“去年北京发往青岛的订单 订单金额,客户,产品,产品类别,供应商”,系统返回一份包含订单金额、客户、产品、类别、供应商的明细数据。
再分析:
想看看不同产品类别的表现,输入“表头 产品类别,订单金额求和”,系统立即按类别汇总。
想知道每个类别的占比,输入“金额 计算占比 命名为 类别占比”,系统新增占比列。
想了解每个类别下哪些供应商贡献最大,输入“在产品类别范围内 订单金额 降序排名 命名为供应商排名”,系统在各类别内对供应商排名。
想筛选出大额订单,输入“过滤 订单金额大于 10000”。
想生成可视化图表,输入“饼图 分类 产品类别 系列 订单金额”。
整个过程无需拖拽、无需写公式,所有指令在数秒内精准响应。无论是分组汇总、排名占比、数据筛选,还是图表生成,用户只需像与助手对话一样,逐步深入,就能从原始数据中提炼出有价值的业务洞察。
算笔明白账:你的成本,到底省在哪?
这是 ChatBI 最能打动人的地方,我们掰开揉碎了说。
1. 硬件与运算成本:从“养超跑”到“开家用车”
大模型方案:若私有化部署,高端 GPU 服务器是基础门槛,购置费、运维成本高昂;若用公有云 API,数据必须出域,存在安全风险,且按 Token 计费,随着使用量增长账单可能失控。尤其是生成复杂 SQL 和 JSON,消耗的 Token 数量巨大。
润乾 ChatBI 方案:核心是高效的规则匹配与翻译引擎,计算开销极低。普通 CPU 服务器即可流畅运行,支撑数十人并发查询。没有 GPU 成本,没有 Token 费用,单次查询的资源成本可能仅为大模型方案的百分之一甚至更低。私有化部署门槛大幅降低,长期持有成本透明亲民。
2. 技术与人力成本:从“组建火箭队”到“培训导游”
大模型方案:要让模型懂业务,需要做微调、搭 RAG、调提示词,需要 AI 专家团队,人力成本高昂,项目周期漫长。
润乾 ChatBI 方案:核心实施工作是配置业务词典和分析指令集。谁干最合适?最懂业务的数据分析师或 IT 工程师。通过可视化工具,把“销售额”、“毛利率”等概念,一一对应到数据库表和字段,设定好计算规则。这更像是在绘制一份“业务地图”,而不是研发“AI 大脑”。普通应用开发团队完全能胜任,无需引入稀缺的 AI 专家。
3. 维护与信任成本:从“开盲盒”到“透明工厂”
大模型方案:结果出错时,调试像破案。是提示词不对?训练数据有偏?还是模型又幻觉了?定位难,修复贵。
润乾 ChatBI 方案:一切基于规则。如果报错或结果不对,可以像调试普通软件一样,快速清晰地定位问题:是“华东区”没录入词典?还是“毛利率”公式配错了?修复就是修改配置,点击保存,立刻生效。系统可控、可预期、可优化,IT 和业务部门都安心。
能力不妥协:能干的活,超乎你想象
规则引擎的能力边界在哪?用一组实例说话。只要用相对规范的语言提问,润乾 ChatBI 足以覆盖绝大多数数据分析需求。
查询能力(NLQ)
明细查询:“列出雇员姓名”、“商品编码、名称、重量、类别、库存量”
附带计算:“雇员姓名、身高、体重、BMI 指数”(BMI 公式预定义)
智能消歧:“订单编码,发货 城市 日期,收货 城市 日期”——通过“发货”“收货”簇词自动区分字段
多表关联:“订单编码,产品名称,供应商名称和城市”——自动关联订单、产品、供应商
复杂过滤:“年龄 45 到 50 岁之间,且籍贯是北京的雇员”、“已售罄的商品信息”
动词关联过滤:“北京发往青岛的订单”——自动绑定发货城市和收货城市
时间智能:“去年第 3 季度的订单”、“上周一的会话记录”
聚合分析:“各城市发货的总金额”、“每月订单数”
聚合后筛选:“总订单数超过 20 的客户”、“平均售价超过 500 元的海鲜商品”
嵌套聚合:“订单金额总和大于 20 万元的女员工”
多源对齐:“各省的员工数、产品数和订单数”——分别从三张表计数后按省份对齐
复杂指标:“月连涨天数大于 5 天的股票”——通过内置 SPL 计算引擎处理
分析能力(NLR)
分组汇总:“表头 产品类别,订单金额求和”
占比计算:“订单金额 计算占比 命名为‘占比’”
排名:“在产品类别范围内 订单金额 降序排名 命名为‘排名’”、“订单金额 降序排名 命名为‘客户排名’”
环比 / 同比:“订单金额 比例环比 命名为‘环比’”、“在省份范围内 订单金额 比例同比 命名为‘省内同比’”
累计:“订单金额 累计求和 命名为‘累计’”
格式调整:“订单金额显示为货币格式”、“占比显示为‘#0.00%’”
条件格式:“大于 2000 红色加粗”
数据筛选:“过滤 订单金额大于 10000”、“过滤 产品类别 =‘电子产品’且 订单金额 >5000”
排序:“排序 产品类别升序,订单金额降序”
行列转换:“左表头 产品类别,上表头 供应商”
图表生成:“柱形图 分类 产品类别 系列 订单金额”、“饼图 分类 产品类别”、“折线图 分类 签单月 系列 订单金额”
配色切换:“梦幻极光”、“科技蓝”
这些例子展示了从简单查询到复杂分析的全覆盖。所有分析动作均由规则引擎精准执行,结果确定、可解释。
坦诚相告:“边界”在哪里?
当然,世上没有完美方案,润乾 ChatBI 同样也有局限性:
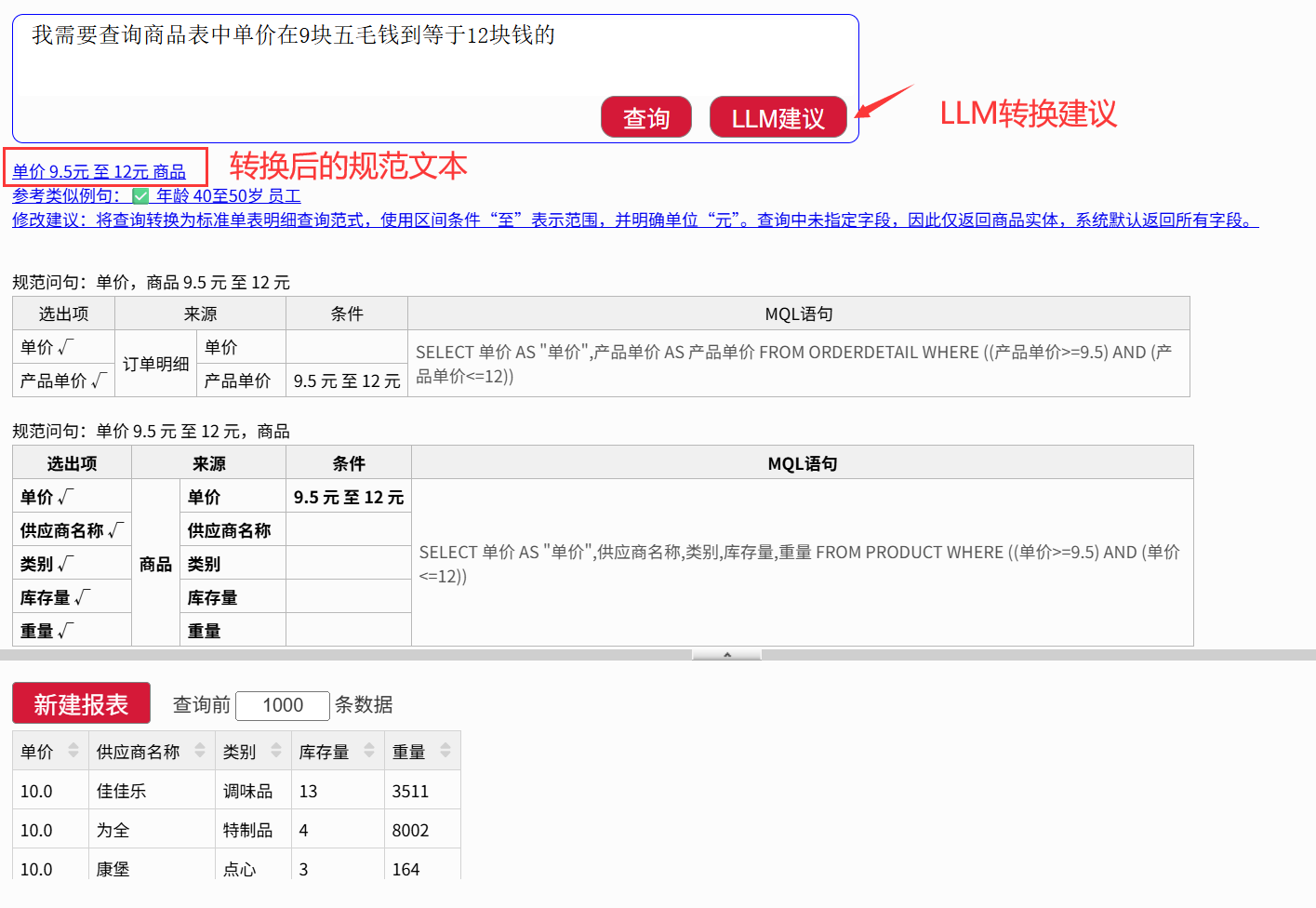
灵活性有门槛:需要相对规范的表达。对于过于口语化或模糊的描述(比如“我需要查询商品表中单价在 9 块五毛钱到等于 12 块钱的”或“南京的客户,或者任意直辖市的”),需要先转化为规范的查询语句。它极度依赖那份预先配置好的“业务词典”和“分析指令集”,词典之外的新说法,它暂时无能为力。
知识更新需手动:不会自学。当公司新增一个“用户互动热度”指标,或需要新的分析动作(如“帕累托分析”)时,必须由管理员在词典中明确定义其规则,才能被调用。
但是,这恰恰引向了它的最佳使用场景:对于业务流程稳定、分析需求规范的企业内部 BI 系统,它是可靠的核心引擎。而对于那些灵活多变的口语化需求,我们也有应对之策。
“双打”:用 LLM 弥补灵活性
既然 LLM 长于“灵活理解”,规则引擎善于“精准执行”,那么让它们组队就是最佳选择。
一个理想的架构是:LLM 作为“智能前台”,负责与用户进行多轮、随意的口语对话,理解其核心意图,并将其“翻译”成润乾 ChatBI 所能识别的、相对规范的自然语言指令(包括查询指令和分析指令,如“按产品类别分组,计算销售额占比,并生成饼图”)。
这里的优势在于:
中间结果是“人话”,可确认可修改:LLM 的任务是从“随意口语”到“规范书面语”的转换,这远比让它直接生成某种结构化的 JSON 或 SQL 要简单。转换后的文字(如“查询去年北京发往青岛的订单,返回订单金额、客户、产品、产品类别、供应商”)业务用户能看懂并确认,发现不对可以立即纠正。而直接生成 JSON 或 SQL 则难以由不懂技术的业务人员验证。确认后的规范指令再由规则引擎(NLQ/NLR)精准执行,确保最终结果准确无误。
“人话”降低了幻觉风险:自然语言是 LLM 的训练母语,将其从口语转为规范书面语是它的“舒适区”,不易产生幻觉。相比之下,要求 LLM 直接生成 JSON 或 SQL 这类结构化数据,相当于让它用外语写作,更容易出现语法错误或逻辑偏差。而且规范的自然语言指令本身就是可读的,用户可直观验证,进一步降低了因误解导致的风险。
成本极低:LLM 的任务被简化为“文字规范化”,只需要理解自然语言并重新组织成规范的问句,无需理解复杂的数据库 Schema 或业务逻辑。这种相对简单的任务,私有化部署的小参数模型就能胜任,既享受了 LLM 的交互友好性,又保证了极低的部署和运行成本,同时数据始终留在企业内部。
这种组合方案,相比当前主流的要求 LLM 直接生成 JSON 或 SQL 的做法,在成本、可控性和准确性上都具有显著优势。
未来一步生成查询 + 报表的综合能力
在即将推出的下一版本中,我们将更进一步,实现真正的“综合能力”。届时,系统不仅能处理规范的查询和分析指令,还能应对更模糊的任务指令。例如,用户可以说“分析一下上个月的销售情况”,系统将自动分解任务:
首先,利用 LLM 理解意图,生成规范的自然语言查询(如“查询上个月的订单数据,返回订单金额、产品类别、省份”),由 NLQ 执行获取基础数据。
然后,基于预定义的规则或简单的指令理解,自动匹配合适的分析动作和图表类型(如按产品类别分组汇总、生成趋势图、计算环比),由 NLR 完成分析并呈现。
这种能力的核心优势,依然建立在我们当前方案的基础上:中间环节的可读性和可干预性。无论是 LLM 对模糊任务的分解,还是系统推荐的报表动作,其过程和中间结果都可以被用户理解和调整。用户可以看到系统打算做什么,并在必要时修正,确保最终结果符合预期。这进一步放大了我们方案的优势——在拥抱 AI 灵活性的同时,牢牢把握住决策的“可解释”和“可控”的底线。
如何上手:比你想象得更简单
润乾 ChatBI 已经作为智能模块,内置在润乾报表产品中。这意味着,使用或集成润乾报表,你就自然获得了这项 ChatBI 的能力。
实施过程非常务实:由熟悉业务的同事,通过可视化界面,将日常分析中常用的业务术语(如“新订单”、“直辖市”、“已售罄”)、字段组合(如“发货 城市 日期”)、计算指标(如“BMI 指数”)等,配置到系统的“业务词典”中。一旦配置完成,用户就可以用规范的语言直接提问和分析,立即获得准确结果。
例如,配置好“新订单”对应本年订单的过滤条件后,用户只需输入“新订单总数”,系统就能自动统计出今年的订单数量。而分析词典系统已经内置(无需配置),用户输入“订单金额 环比”,系统就能正确计算。
如果要搭配 LLM 解决灵活性,在润乾的官方技术社区(乾学院)上已经分享了使用大模型辅助生成规范查询语句的提示词(Prompts)。可以利用分享的提示词,用某个公开的 LLM 转换后再查询,从而获得更强的灵活性。

比如这个非常口语化的查询“我需要查询商品表中单价在 9 块五毛钱到等于 12 块钱的”,直接查询是不行的。

但被 LLM 转换后就可以了。
在追逐技术浪潮时,有时最实用的方案,未必是最炫酷的那一个。润乾 ChatBI 选择了一条务实之路:不追求万能的理解,而追求在核心业务查询与分析场景下的百分百准确、极低成本与完全可控。
它让“让数据说话”这件事,从一项昂贵且不确定的技术冒险,变成了一个可规划、可实施、可管理的标准化项目。对于广大的中小企业、务实的技术团队和追求稳定产出的业务部门而言,这或许才是当下更值得拥有的“真智能”。

