


另辟蹊径做 ChatBI,不用大模型也能实现智能问数分析
随着 AI 大模型的技术突破,用自然语言与数据进行对话的 ChatBI 概念也变得火热起来,人们普遍认为这件事终于具备了可行性。于是,业界很自然地沿着大模型(LLM)这条技术路线进行探索,期待它能理解业务人员的随意提问,既能返回数据查询结果,也能根据指令执行进一步的分析动作。
然而,理想很丰满,现实却有点骨感:LLM 方案始终存在 "幻觉" 问题,而且成本高昂、部署与调优过程也相当复杂。
我们注意到,在 BI 这个特定场景下,业务人员用于查询和分析数据的自然语言,其实并没有日常对话那么随意和复杂。诸如 "上月销售额"、"销量最高的产品"、"北京地区的客户销售额" 这类问题,其语义模式大体上是可抽象、可结构化的。
润乾 ChatBI 方案正是基于这一洞察,绕开了以大模型为核心的技术路线,通过一套精密的 "规则词典" 实现自然语言到规范查询的转换,再配合其强大的多源计算能力,同样实现了高效、可靠、低成本的智能数据问答与报表分析。
不是 "大脑",而是 "交通指挥塔"
你可以把大模型想象成一个博览群书、反应迅捷的 "天才",但它有时会 "自由发挥"。而润乾 ChatBI 的 NLQ(自然语言查询)组件,则像一个一丝不苟、精通所有交规和地图的 "交通指挥塔"。它的工作,不靠灵感,靠的是一套预先录入的、极其详尽的 "城市交通手册"——也就是它的词典,即领域知识库。
这套词典是 ChatBI 的灵魂,当然远不止是几个同义词那么简单,而是一个结构化的知识库,包含数据元数据词典、业务语义词典(维词、指标、常数词)和查询逻辑词典(比较词、聚合词、无效词等)。正是基于这套词典,NLQ 能够将相对规范的自然语言查询,转换为结构化的MQL(Metrics Query Language)语句,最终生成精准的 SQL 到数据库执行。
例如,"40岁以上雇员姓名、年龄、城市和省 "这样的单表明细查询,NLQ 能够精准识别年龄过滤条件并返回所需字段;而"每月订单数 "这样的单表聚合分析,MQL 会自动按月份分组并完成计数计算。面对"订单编码,商品名称,供应商名称和城市 "这样的多表关联查询,NLQ 能够自动解析表间关系,准确关联三张表中的信息;对于"订单金额总和大于 20 万元的女员工 "这样的子表聚合条件查询,NLQ 也会先在订单表中按员工聚合金额,再将结果作为条件过滤员工信息。
不止于查询:自然语言驱动的自助报表分析
获取数据只是第一步,真正的分析往往才刚刚开始。如何对查询结果进行分组汇总、计算排名环比、调整格式、生成图表?传统 BI 工具需要拖拽、点选、编写公式,操作繁琐。而润乾 ChatBI 将同样的规则引擎延伸至分析阶段,提供了NLR(自然语言报表)能力:用户可以基于查询得到的数据集,用简洁的汉语指令直接驱动报表完成各种分析动作。
无论是筛选、分组、汇总,还是复杂的跨行组运算(排名、环比、占比),乃至格式调整和图表生成,NLR 都能通过一套预先定义的“分析词典”精准理解用户意图,并立即执行。整个过程无需离开分析界面,就像与一位数据分析师对话一样自然流畅。
更重要的是,NLQ 与 NLR 无缝衔接:通过 NLQ 获得的数据集,可以一键进入 NLR 分析模式,所有后续操作都基于同一份数据,构成了从“取数”到“分析”的完整闭环。
示例:从“去年北京发往青岛的订单”到产品类别深度分析
第一步:NLQ 查询数据
用户输入:
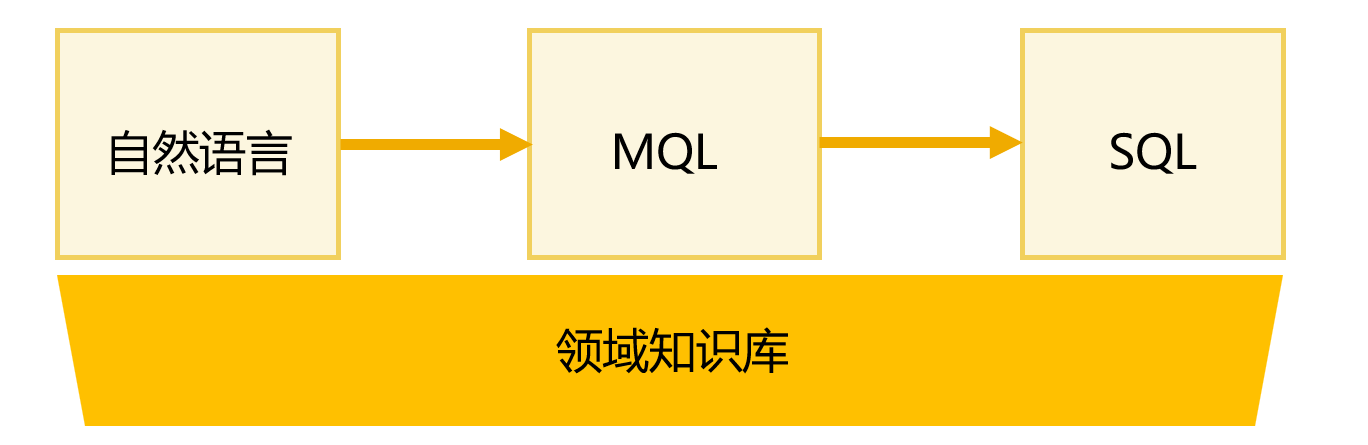
去年北京发往青岛的订单 订单金额,客户,产品,产品类别,供应商
系统启动 NLQ 精密解析流程:
词汇切分与过滤:将句子拆解为“去年”、“北京”、“发往”、“青岛”、“订单”、“订单金额”、“客户”、“产品”、“产品类别”、“供应商”等关键令牌,过滤掉“的”等无效词。
词典匹配与语义关联:
去年→ 匹配到“年”维词,表达式自动计算为 year(ADDYEARS(now(),-1)),转化为时间过滤条件。
北京 / 青岛→ 匹配到“城市”维的常数词,系统知道“北京”“青岛”是具体城市 ID。
发往→ 识别为关键动词,关联到“发货”字段簇(包含发货城市、收货城市等)。系统据此理解“北京”对应发货城市,“青岛”对应收货城市。
订单→ 匹配到“订单”实体,确定主查询表为订单表。
订单金额→ 匹配到指标“订单金额”,可能绑定计算公式(如单价×数量),确定为查询的数值字段。
匹配客户、产品、供应商等维词。
MQL 生成:系统将所有匹配结果组装成一条结构化的 MQL 语句,描述查询逻辑:从订单表出发,关联客户表、产品表、供应商表,筛选出发货城市 =‘北京’、收货城市 =‘青岛’、订单年份 = 去年的记录。
执行与返回:MQL 引擎将逻辑转换为底层数据库可高效执行的 SQL(涉及多表连接),最终返回一份包含以下字段的订单明细数据。
第二步:NLR 自助报表分析
业务人员获得上述订单明细后,希望从产品类别角度分析这些订单的构成,找出关键类别、供应商和客户。他们在报表界面通过以下自然语言指令,逐步完成分析。
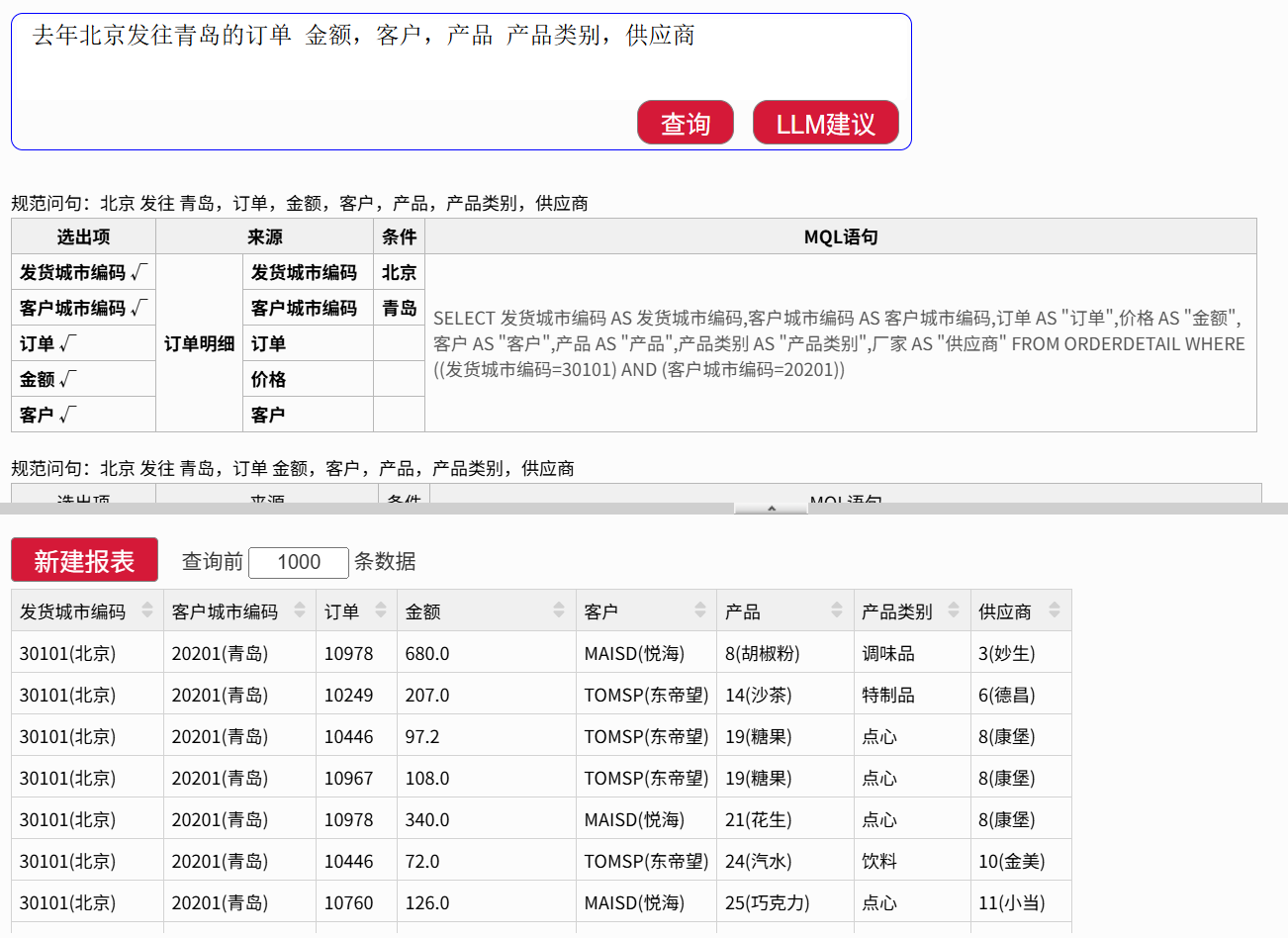
按产品类别分组汇总
输入命令:
表头 产品类别
订单金额求和
系统就会按产品类别分组,计算每个类别的订单金额总和,生成一张汇总表,展示各类别的总销售额。
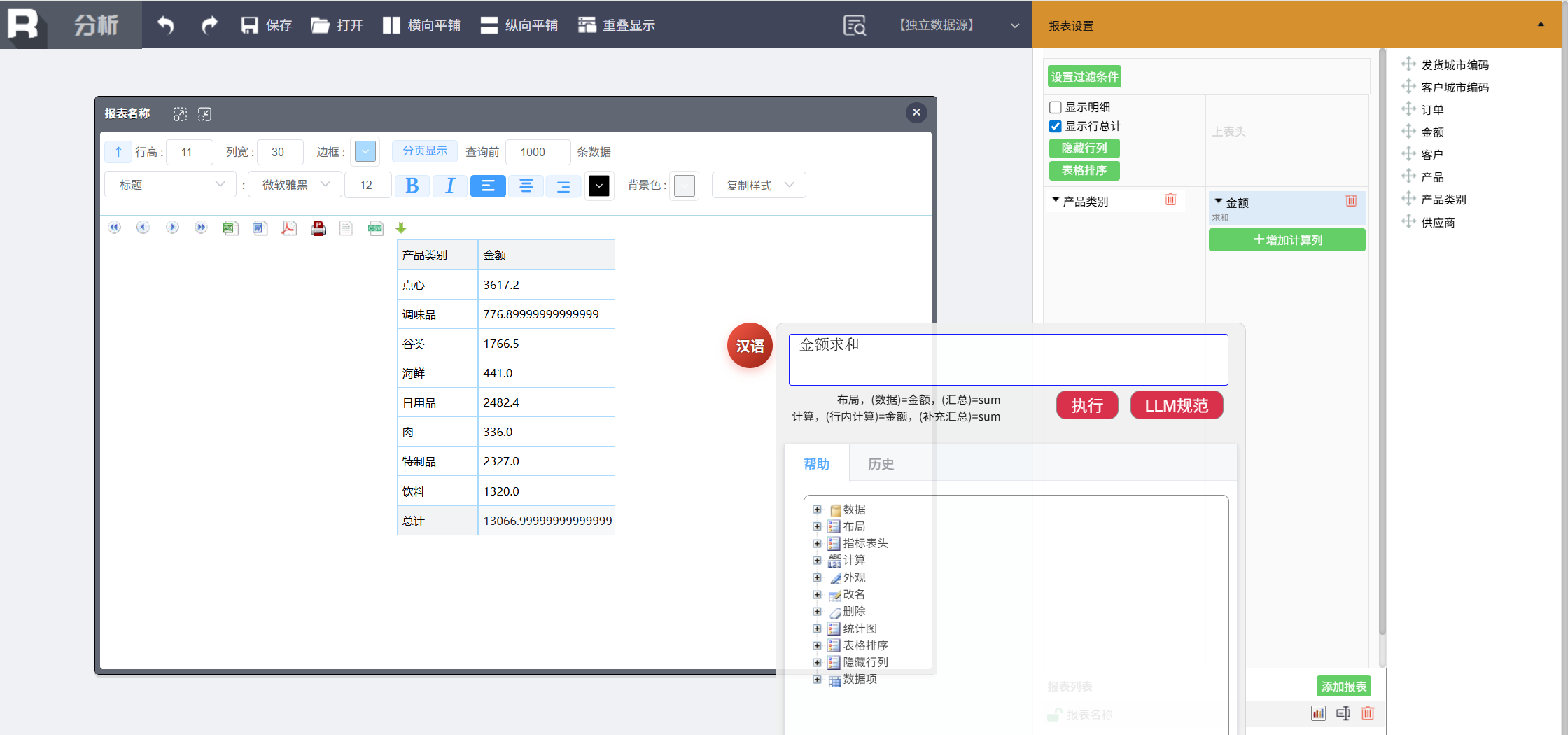
计算类别占比
输入命令:
金额 计算占比 命名为类别占比
系统为每个类别新增“类别占比”列,显示该类别销售额占所有类别总和的百分比。例如“点心”占 27%,“海鲜”占 3%,“饮料”占 20%。业务人员可以直观看到各类别的相对重要性。
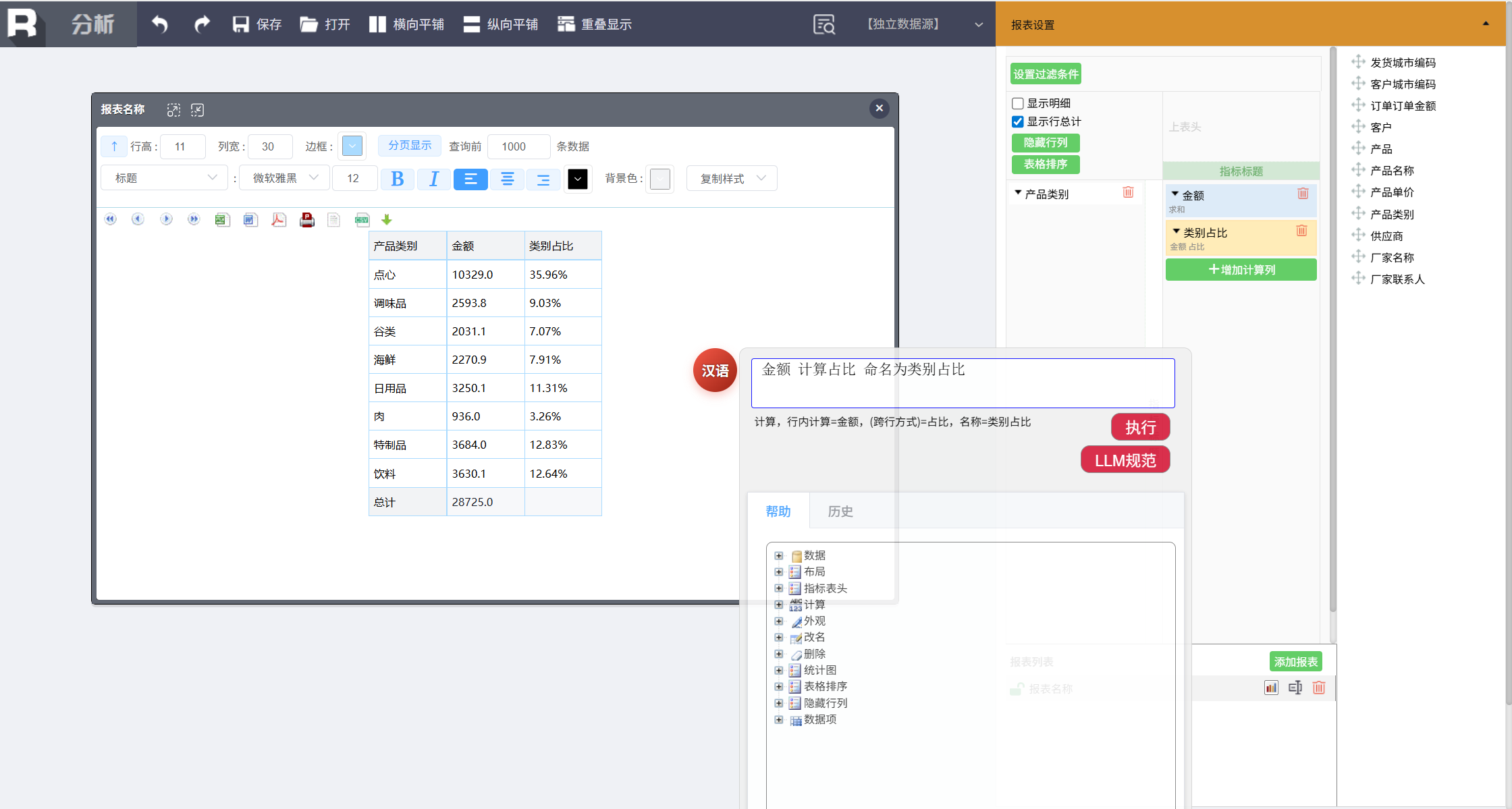
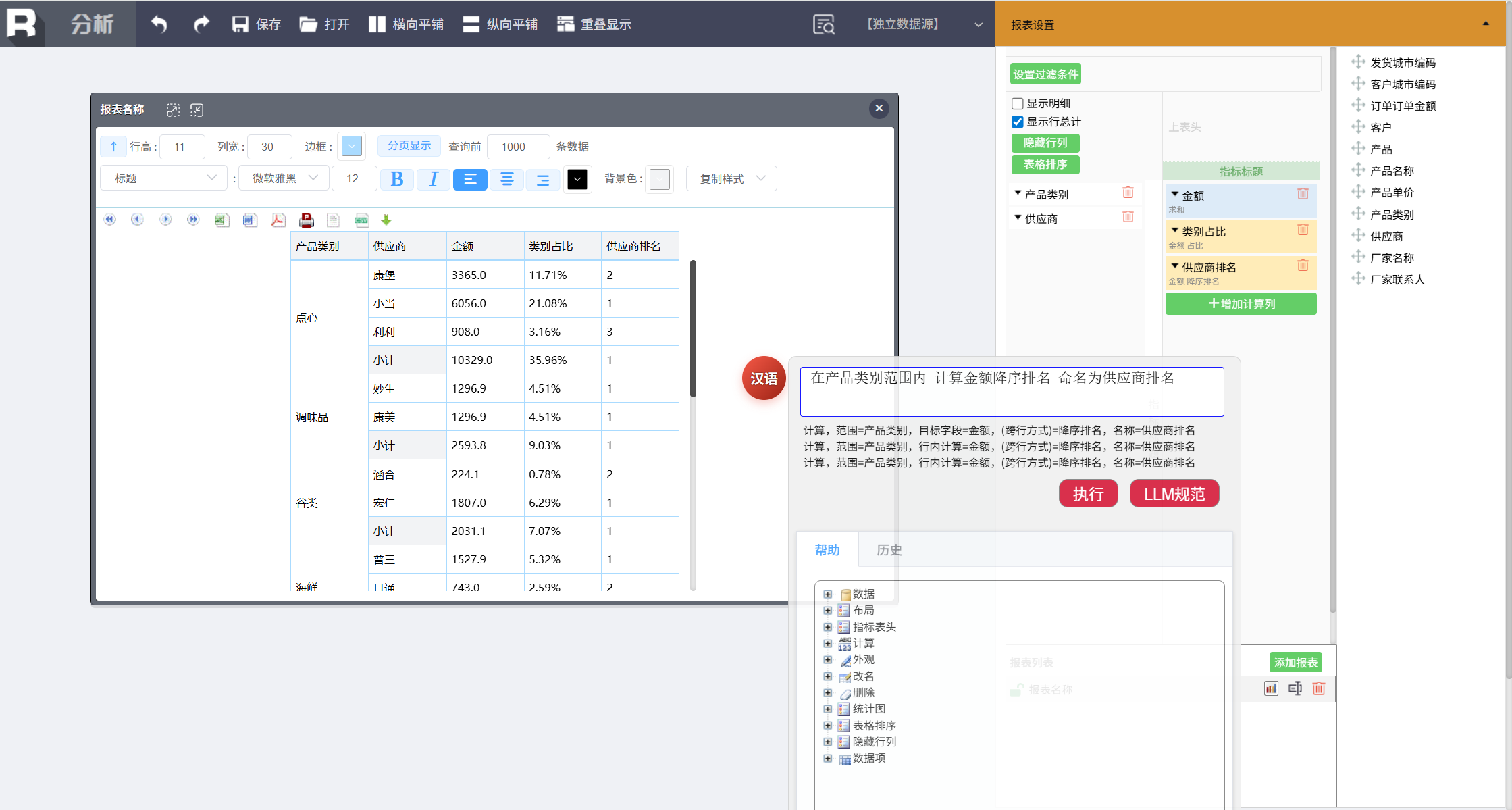
类别内部按供应商排名
在产品类别范围内 订单金额 降序排名 命名为供应商排名
在每个产品类别内部,按供应商对订单金额进行汇总并排名,新增“供应商排名”列。例如在点心类别下,供应商 A 的订单总额最高(排名 1),供应商 B 次之(排名 2)。这有助于识别各类别中的核心供应商。
按客户贡献排名
订单金额 计算降序排名 命名为客户贡献排名
对所有订单按客户汇总金额并排名,新增“客户贡献排名”列,显示哪些客户是这些订单中的大客户。例如“客户 X”订单总额最高,排名 1。业务人员可据此重点关注高价值客户。
交叉分析:产品类别与供应商
左表头 产品类别,上表头 供应商
将表格转换为以产品类别为行、供应商为列的交叉表,单元格内显示对应类别和供应商的订单总额。这能快速呈现各供应商在不同产品类别中的表现,发现强势或薄弱领域。
筛选高价值订单
过滤 订单金额大于 10000
只显示订单金额超过 1 万元的大额订单,帮助业务人员聚焦高价值交易,分析这些大额订单集中在哪些产品类别、供应商和客户。
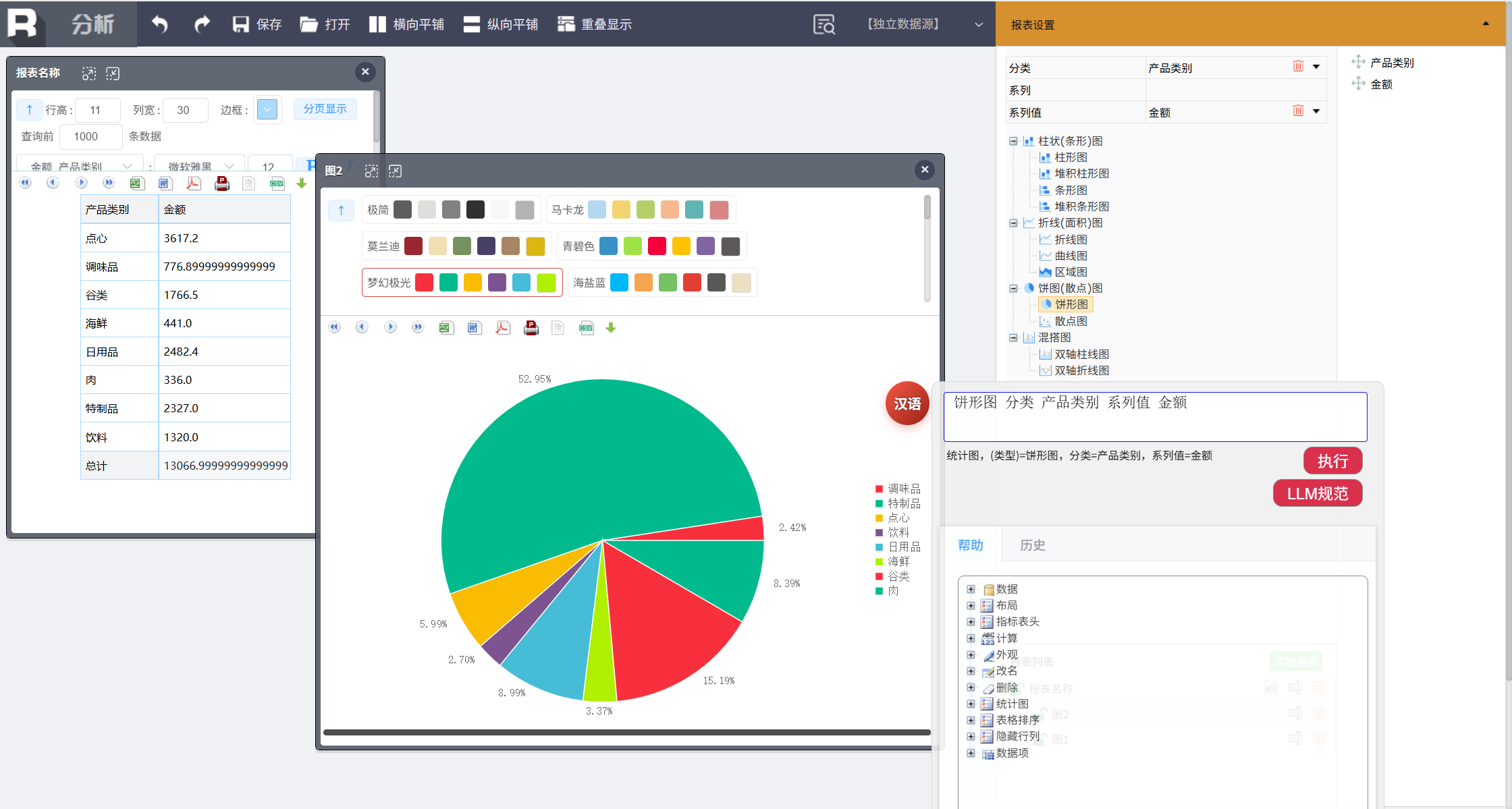
可视化:类别占比饼图
饼图 分类 产品类别 系列 订单金额
生成饼图,直观展示各产品类别的销售额占比,便于使用。
业务意义总结
通过以上分析,业务人员可以快速回答以下问题:
去年北京发往青岛的订单中,哪些产品类别销售额最高?占比如何?
每个产品类别下,哪些供应商贡献最大?
哪些客户是订单中的大客户?(客户 X 排名第一)
大额订单主要集中在哪些类别和供应商?(可筛选后查看)
供应商在不同类别中的表现差异?(交叉表一目了然)
整个过程都可以自然语言驱动,无需编写公式或拖拽控件,且所有计算基于规则引擎,结果精确、可解释。业务人员只需像与助手对话一样,逐步深入,就能从原始订单数据中提炼出有价值的业务洞察。
硬核优势:在 ChatBI 战场上又稳又省
这套基于规则的自然语言处理能力,在企业 BI 场景下带来了实实在在的好处:
稳定可靠,告别 "幻觉":无论是自然语言查询还是报表分析,规则引擎的每一步输出都是确定的。词典中定义了明确的业务术语和计算逻辑,如果用户指令中出现未定义的词(如“用户活跃度”),系统会明确提示“无法识别”,而不是像 LLM 那样编造一个似是而非的结果。当业务逻辑变化时(如“销售额”的计算规则需要扣除运费),管理员只需在指标词典中修改公式,整个过程像修改配置文档一样清晰可控。这意味着整个转换路径是可解释、可完善的,而 LLM 方案则需要重新收集数据、微调模型,过程是黑盒且成本高昂。
私有化部署,数据安全:整个方案可以完全部署在企业内部服务器上,数据无需出域,彻底满足金融、政府、大型企业对数据安全与隐私合规的严苛要求。而云端 LLM 方案不可避免地存在数据外传的风险。
成本极低,部署简单:规则引擎计算开销很小,普通 CPU 服务器即可流畅运行多个并发任务。由于不依赖 LLM,没有 Token 费用,无需担心使用成本。相比之下,大模型方案通常需要昂贵的 GPU 集群和复杂的 RAG 等配套技术栈,显得笨重而复杂。
低延迟,体验流畅:基于本地规则引擎的解析与计算,通常在毫秒级响应,无需等待 LLM 的流式输出或网络延迟,可以获得即问即答的流畅体验。
"双打":用 LLM 弥补灵活性,但保持核心优势
当然,纯规则方案有其局限,灵活性不足:它无法理解 "卖得最火的几个货" 这种随意的口语。它需要相对规范的语言,比如 "销量前十名的产品"。润乾 ChatBI 的强大建立在 "词典" 的完备性上,对于词典之外的 "新词" 和 "新说法" 确实 "无能为力"。
既然 LLM 长于 "灵活理解",NLQ 善于 "精准执行",那么为何不让它们组队呢?
一个更理想的架构是:LLM 作为 "智能前台",负责与用户进行多轮、随意的口语对话,理解其核心意图,并将其 "翻译" 成润乾 ChatBI 所能识别的、相对规范的自然语言指令。
这里的优势在于:
中间结果可确认可修改:LLM 的任务是从“随意口语”到“规范书面语”的转换,这远比让它直接生成某种结构化的 JSON 或 SQL 要简单。转换后的文字(如“查询去年北京发往青岛的订单,并返回订单金额、客户、产品、产品类别、供应商”)业务用户能看懂并确认,发现不对可以立即纠正。而直接生成 JSON 或 SQL 则难以由不懂技术的业务人员验证。确认后的规范指令再由规则引擎(NLQ/NLR)精准执行,确保最终结果准确无误。
“人话”极大降低了幻觉风险,自然语言是 LLM 的训练母语,将其从口语转为规范书面语是它的“舒适区”,不易产生幻觉。相比之下,要求 LLM 直接生成 JSON 或 SQL 这类结构化数据,相当于让它用外语写作,更容易出现语法错误或逻辑偏差。而且规范的自然语言指令本身就是可读的,进一步降低了因误解导致的风险。
成本低:LLM 的任务被简化为 "文字规范化",只需要理解自然语言并重新组织成规范的问句,无需理解复杂的数据库 Schema 或业务逻辑,也就是只要摆位。这种相对简单的任务,私有化部署的小参数模型都能胜任,既享受了 LLM 的交互友好性,又保证了极低的部署和运行成本。
这种组合方案,相比当前主流的要求 LLM 直接生成 JSON 或 SQL 的做法,在成本、可控性和准确性上都具有显著优势。
未来展望:一步生成查询 + 报表的综合能力
在即将推出的下一版本中,我们将更进一步,实现真正的 "综合能力"。届时,系统不仅能处理规范的查询,还能应对更模糊的任务指令。例如,用户可以说 "分析一下上个月的销售情况",系统将自动分解任务:首先,利用 LLM 理解意图并调用 NLQ 组件生成基础数据查询;然后,基于预定义的规则或简单的指令理解,自动匹配合适的图表类型(如趋势图、排行榜)。
这种能力的核心优势,依然建立在我们当前方案的基础上:中间环节的可读性和可干预性。无论是 LLM 对模糊任务的分解,还是系统推荐的报表动作,其过程和中间结果都可以被用户理解和调整。这进一步放大了我们方案的优势——在拥抱 AI 灵活性的同时,牢牢把握住决策的 "可解释" 和 "可控" 的底线。
当 ChatBI 的探索大多集中于大模型这一虽然广阔但充满不确定性的 "主航道" 时,润乾以其独特的 "规则引擎 + 强大计算引擎" 另辟蹊径,并进一步探索与 LLM 的高效协作模式,为我们提供了另一种经过实践验证的、务实的可靠选择。它或许没有纯大模型方案那般 "万能的想象力",但在 BI 这个需要确定性、可靠性、成本可控,并且天然存在多源数据、复杂计算需求的领域,这种专注于 "解决特定问题" 的路径,无疑是一条值得重视的、能够真正落地并创造价值的方向。

