


AI 时代,这款能听懂人话的自助报表值得集成
在企业软件项目中,“报表需求”是个绕不开的话题,也常常是消耗项目利润的主要部分。客户业务不断变化,分析视角也随之调整,今天想看按地区的汇总,明天可能要按产品线细分,后天又需要对比同期数据。这些看似合理的需求,落到软件厂商的开发团队身上,就是一次次的数据查询、接口开发和界面调整。
为此,许多厂商考虑引入自助报表或 BI 工具来应对。但常见的 BI 类自助报表方案通常作为独立的重型系统,需要复杂的数据同步和用户体系对接,集成繁琐而且成本高昂。而且,这些工具的操作逻辑对用户而言仍有学习门槛,应用不太方便。
有没有更务实的办法?
润乾报表的思路:提供能轻松嵌入业务系统的自助报表模块,并在此基础上加入自然语言交互能力,让自助报表像对话一样简单,真正将报表任务交付给最终用户。这套能力正是润乾 ChatBI 的重要组成部分,包含自然语言查询(NLQ)和自然语言报表分析(NLR),形成从“取数”到“分析”的完整闭环。
为应用集成而生的自助报表
润乾报表的优势之一在于良好的集成性。它并非一个独立部署、单独访问的庞大系统,而是可以作为一个轻量的“报表能力引擎”,通过组件形式,被深度嵌入到 CRM、ERP、OA 等业务系统内部。
用户无需跳出熟悉的业务界面,即可在某个功能模块旁直接发起报表设计与查看。与业务流一体的体验解决了“不好集成”的痛点,让自助报表能被自然用起来。
汉语对话,扫清使用障碍
第一步:筛选关键数据
筛选订单金额大于 2000 的大订单,输入如下命令:
过滤 订单金额大于 2000
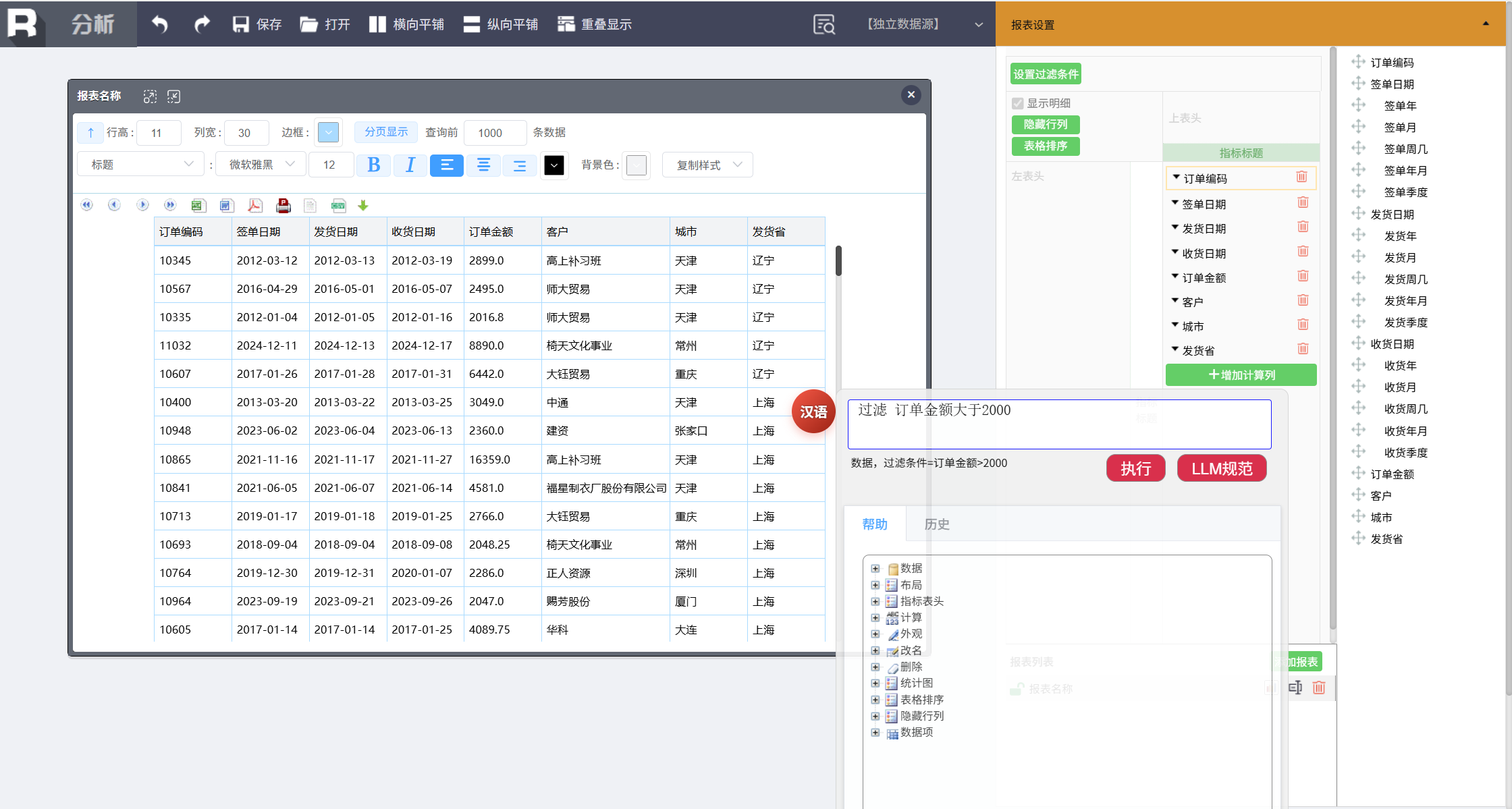
第二步:分组汇总
按照省份和年份汇总大订单金额。先分组,输入:
表头 发货省 签单年
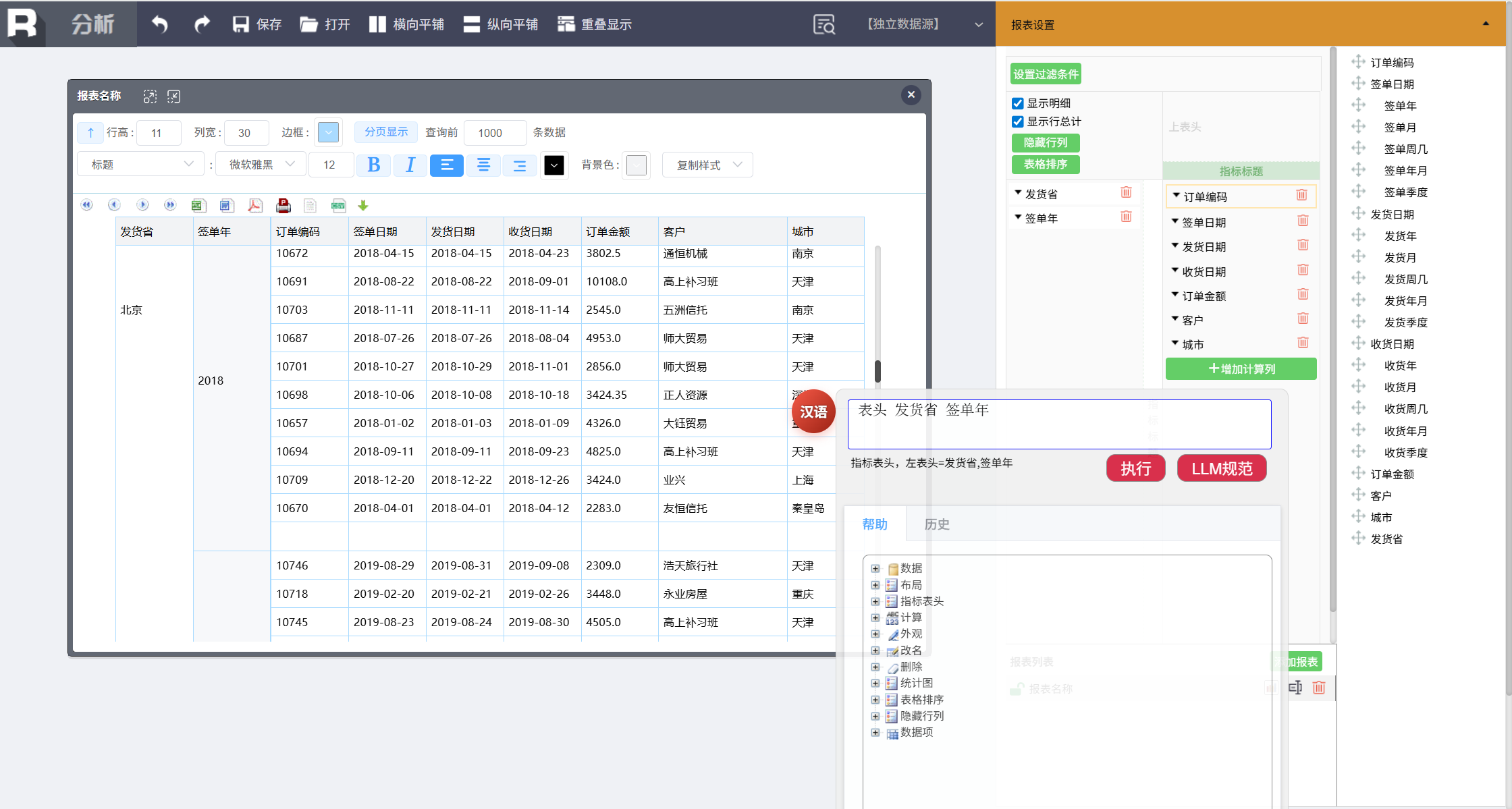
去掉多余列:
删除订单编码 签单日期 发货日期 收货日期 客户 城市
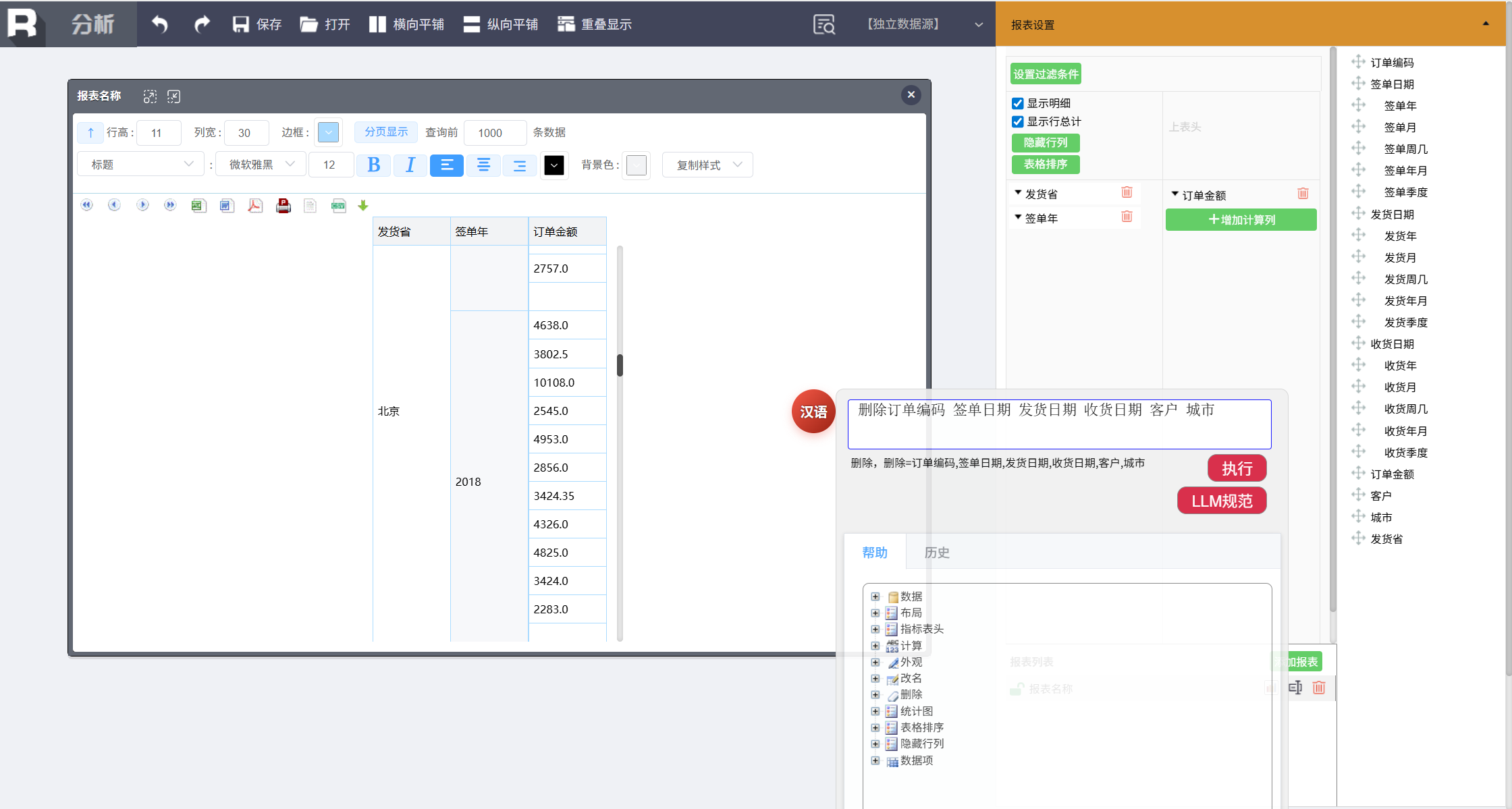
添加汇总指标项:
订单金额求和
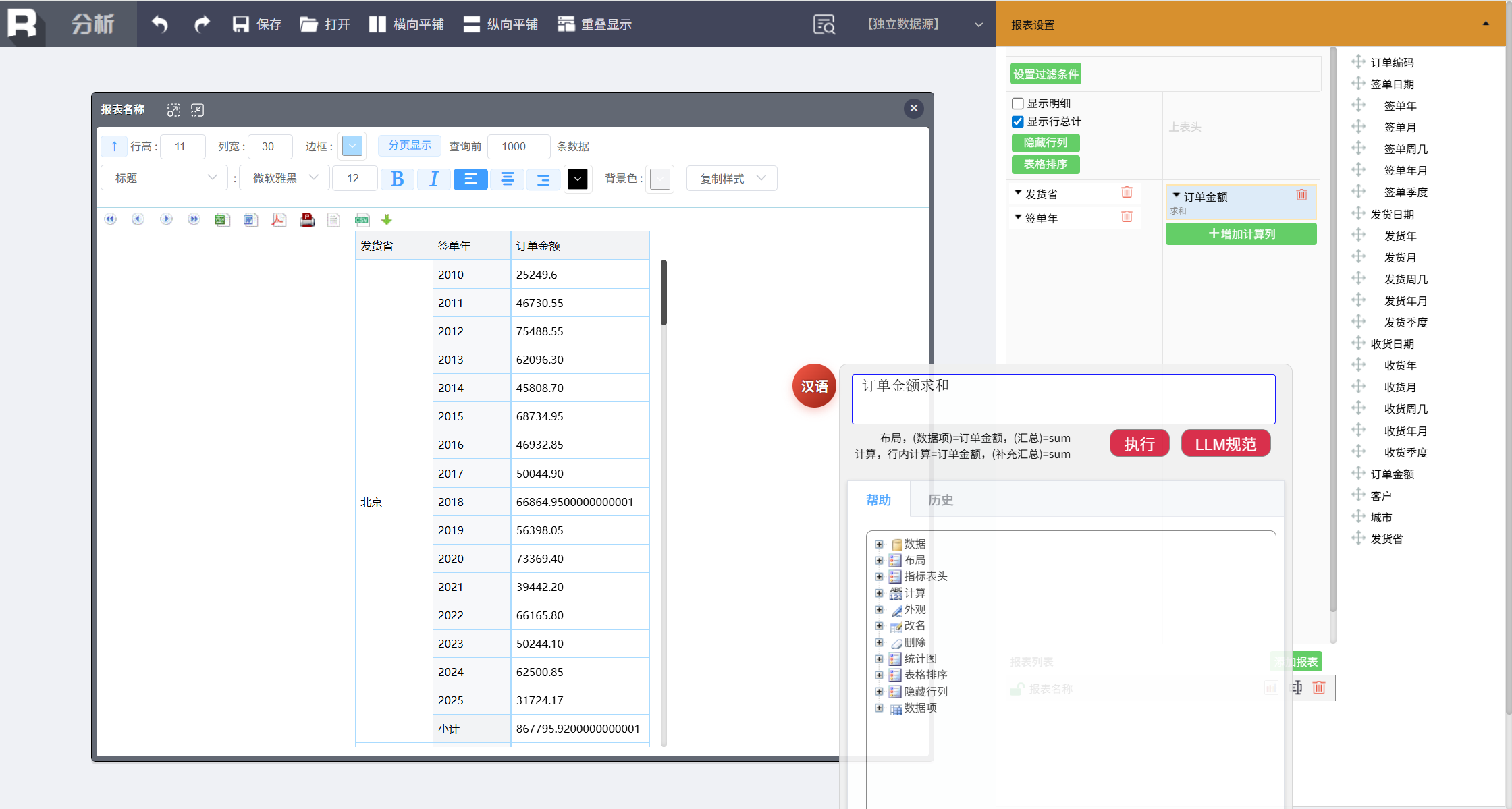
第三步,计算关键指标
计算每个省每年的订单金额环比增长率,输入命令:
在发货省范围内 计算订单金额比例环比 命名为订单环比
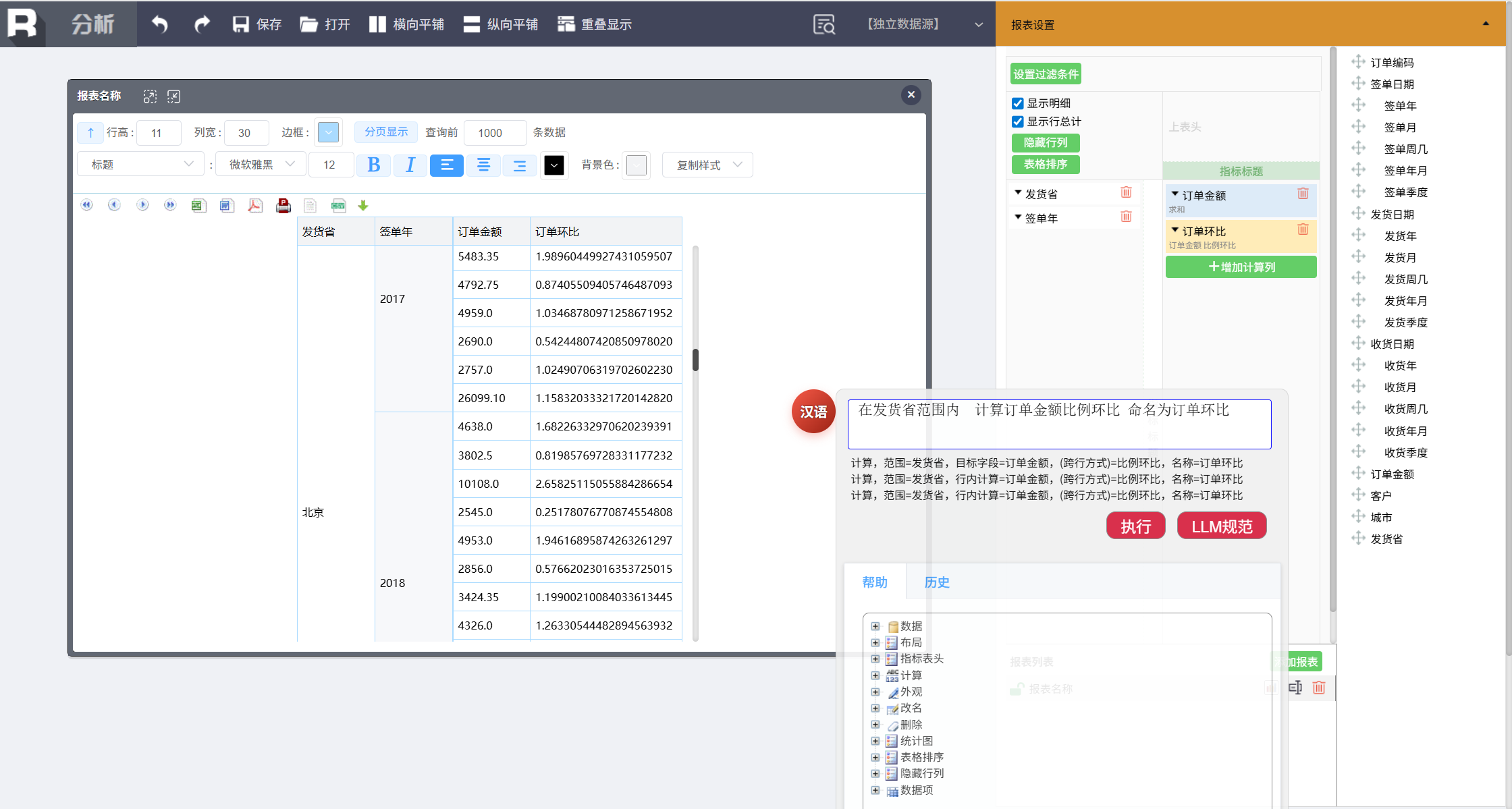
设置环比显示格式:
位置订单环比,显示为 "#0.00%"
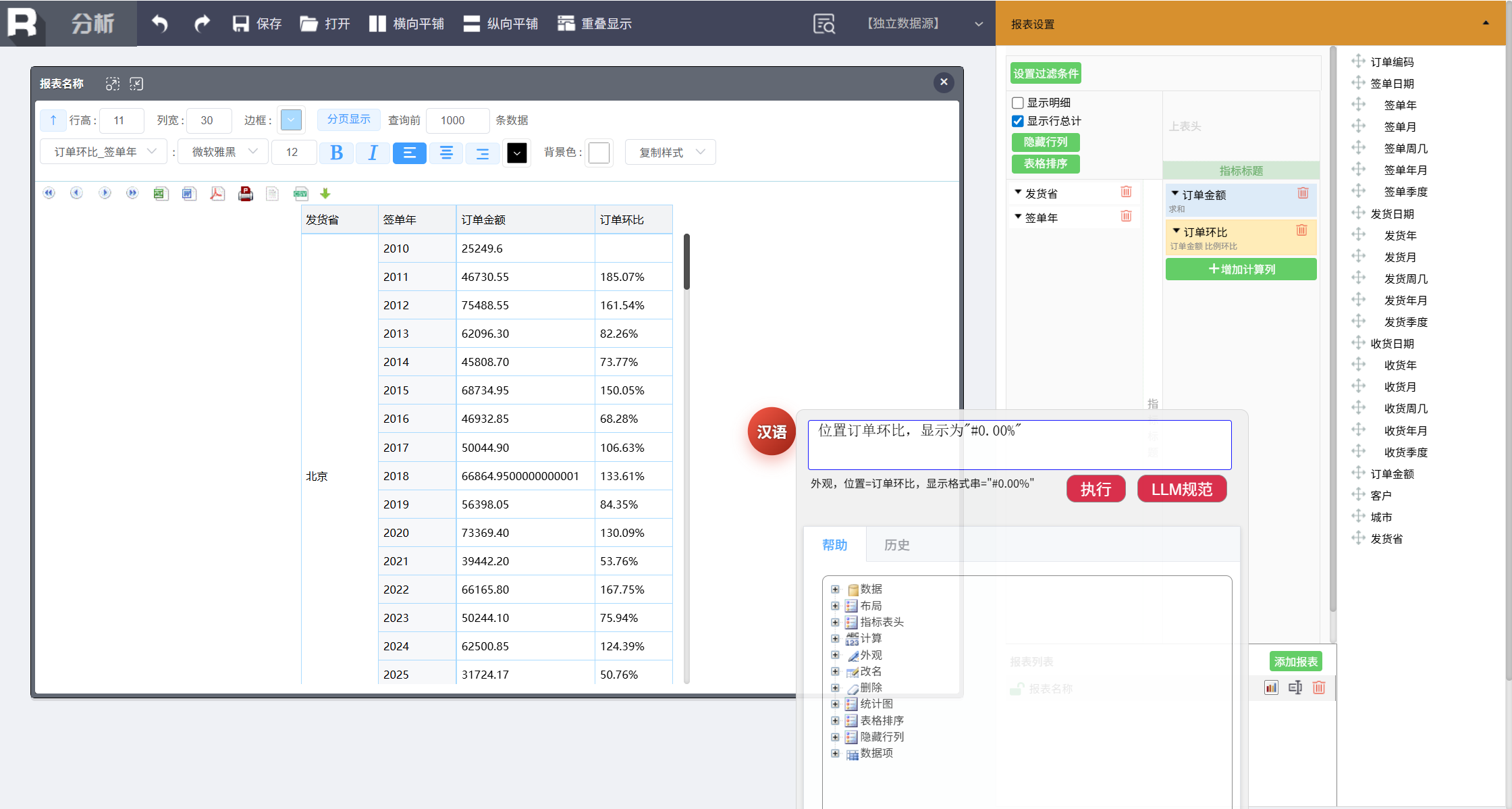
第四步,突出特殊数据
将增长率超过 100% 的订单环比突出显示,输入:
位置订单环比 _ 签单年,大于 1 红色加粗
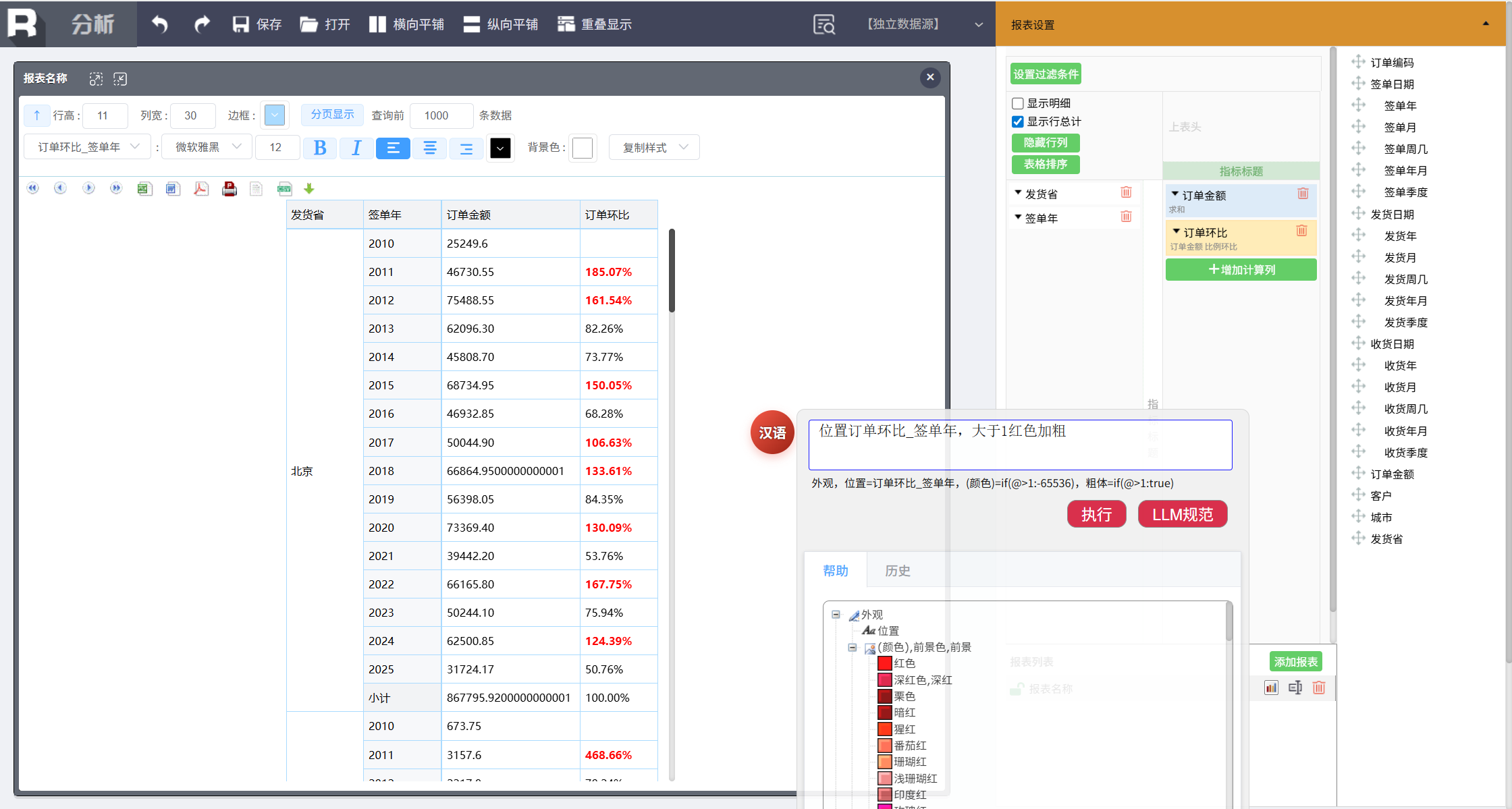
这里还可以点击要设置的列,如订单环比(某个格子),然后直接用命令设置,这时只需要输入:
大于 1 红色加粗
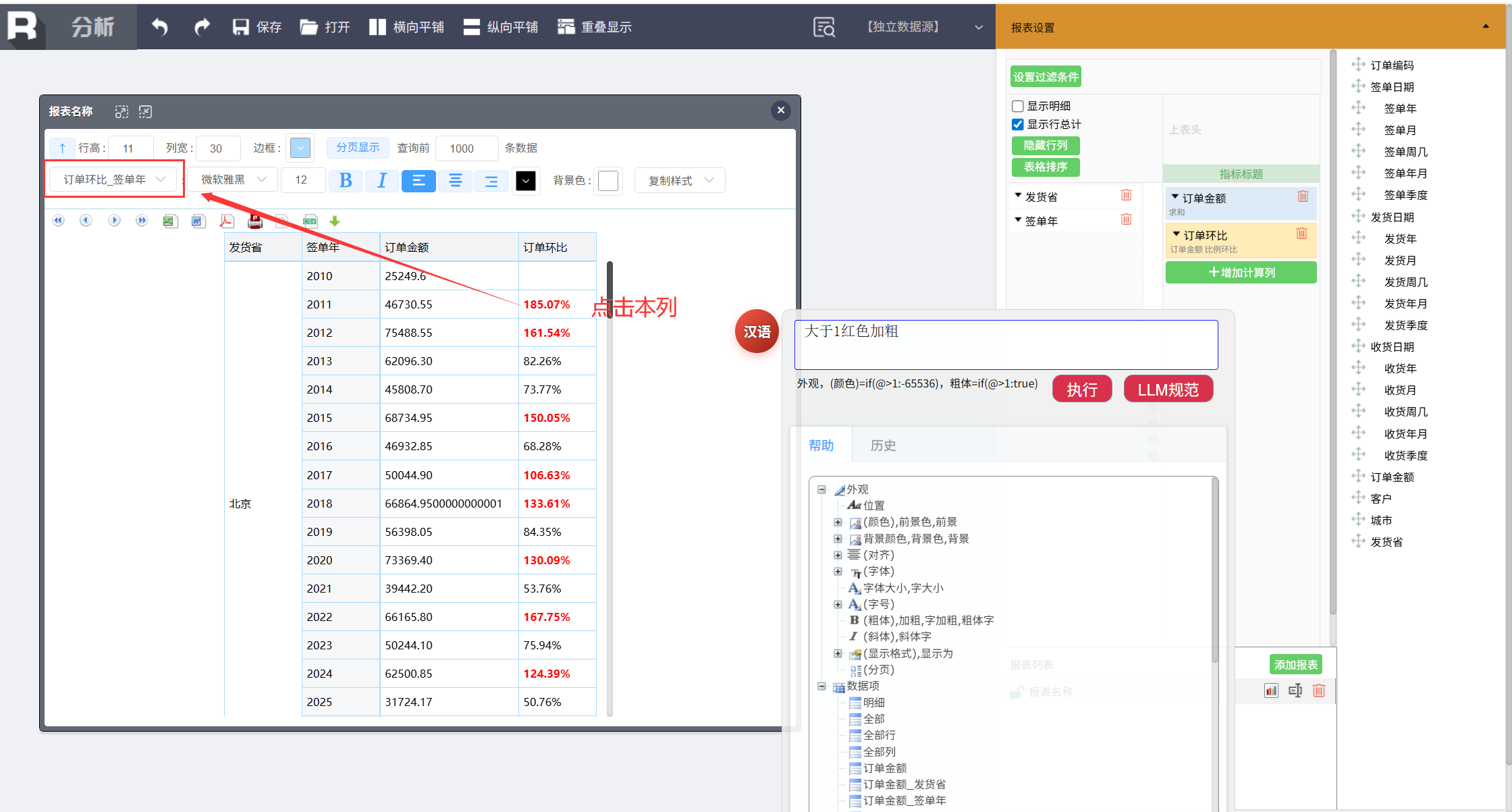
至此,一张针对销售数据的分析报表就已经完成了。这时还想在报表中添加各个地区的销售额统计图。
第五步,添加图表
添加一个各个省份销售情况的统计图,以便从更宏观的角度观察数据。输入:
柱形图 分类 发货省 系列值 订单金额
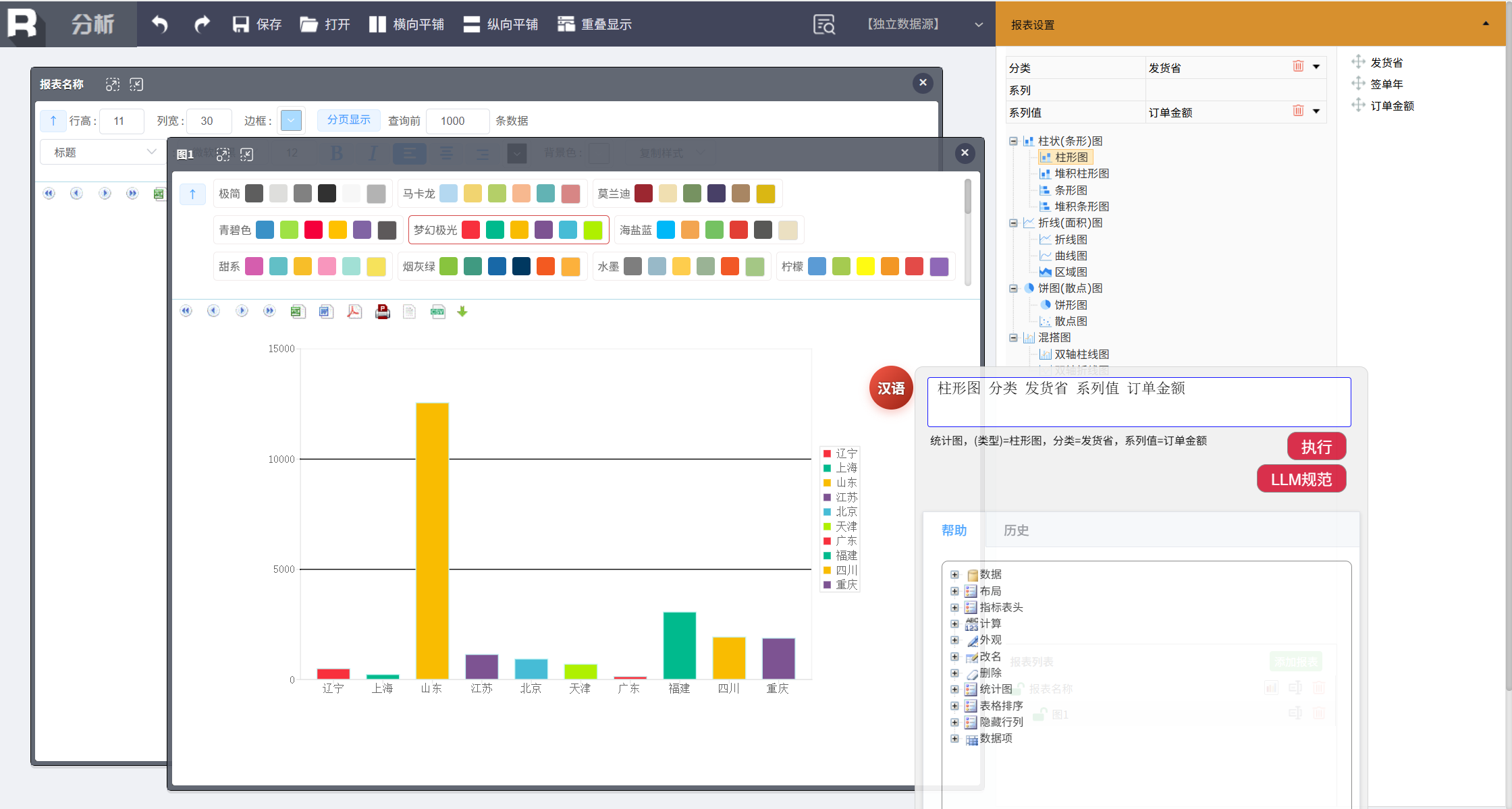
整个流程通过几句简单的自然语言指令,驱动系统完成了从数据筛选、计算、到图表生成的报表制作全过程,简化了传统报表工具中繁琐的配置操作。
除了上述能力,NLR 还可以完成下面这些自助报表中的常见操作:
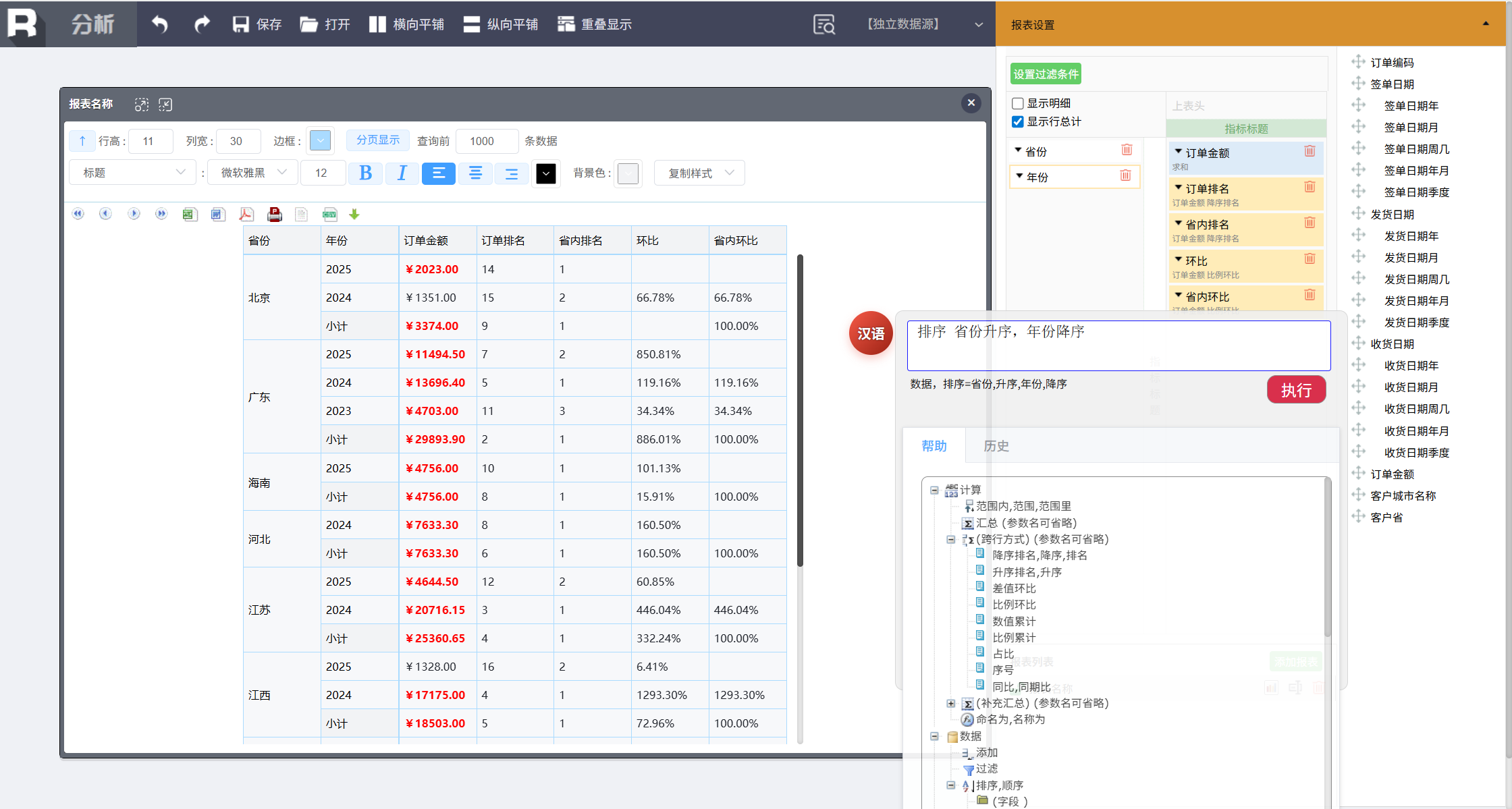
排序
针对多字段排序:
排序 省份升序,年份降序
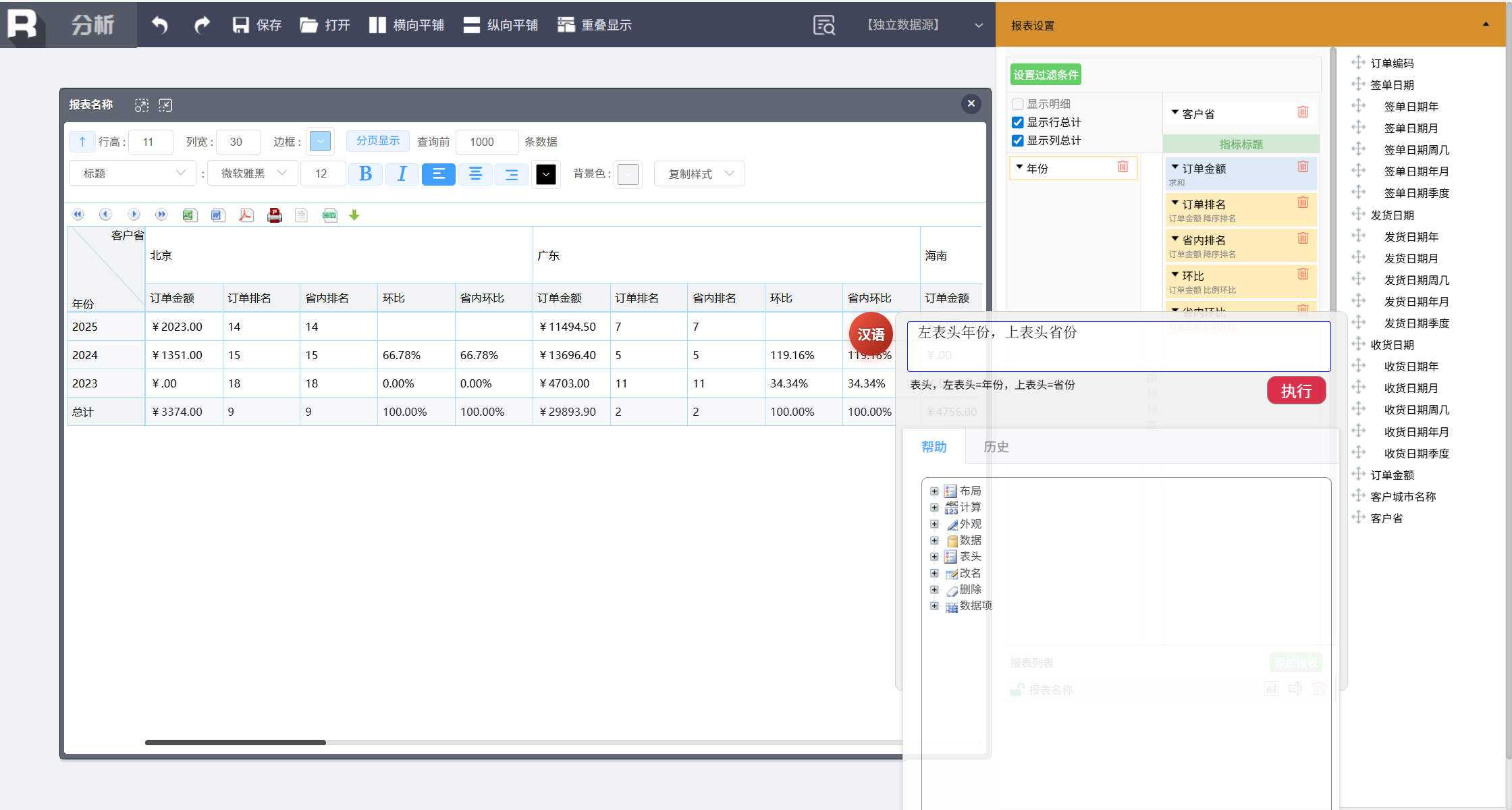
行列转换
做行列互换:
左表头年份,上表头省份
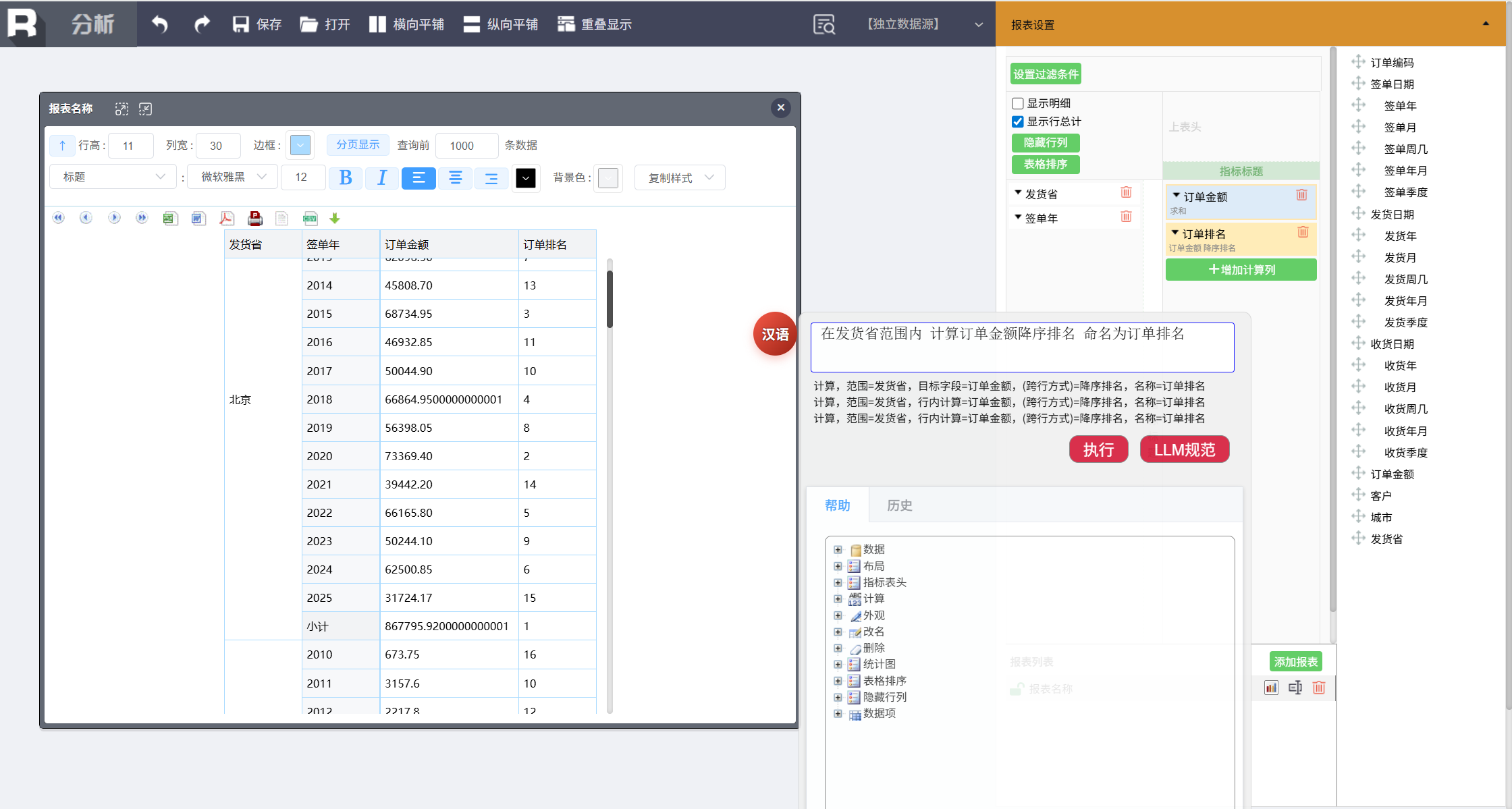
跨行组运算
除了环比,还可以完成排名、累积、占比等多种跨行组运算。比如要针对订单数量做排名:
在发货省范围内 计算订单金额降序排名 命名为订单排名
NLR 的汉语对话能力与润乾报表原有的自助报表模块一样,保持了极高的可集成性。不需要额外独立对接的复杂 AI 服务,而是作为报表模块的内置功能,可以像集成普通报表组件一样,被无缝对接到业务系统中。
智能帮助,让“对话”更易上手
使用这些汉语命令需要遵循一定规则,对于刚开始不太熟悉具体命令的用户,润乾报表内置了智能帮助体系。在输入框中键入时,系统会进行实时关键词过滤,动态联想并展示最相关的命令范例和完整参数提示,引导用户快速形成有效指令。
比如当输入到 “降序排名” 时会出现跨行运算提示,以及该命令需要的后续参数(命名为、数据项)。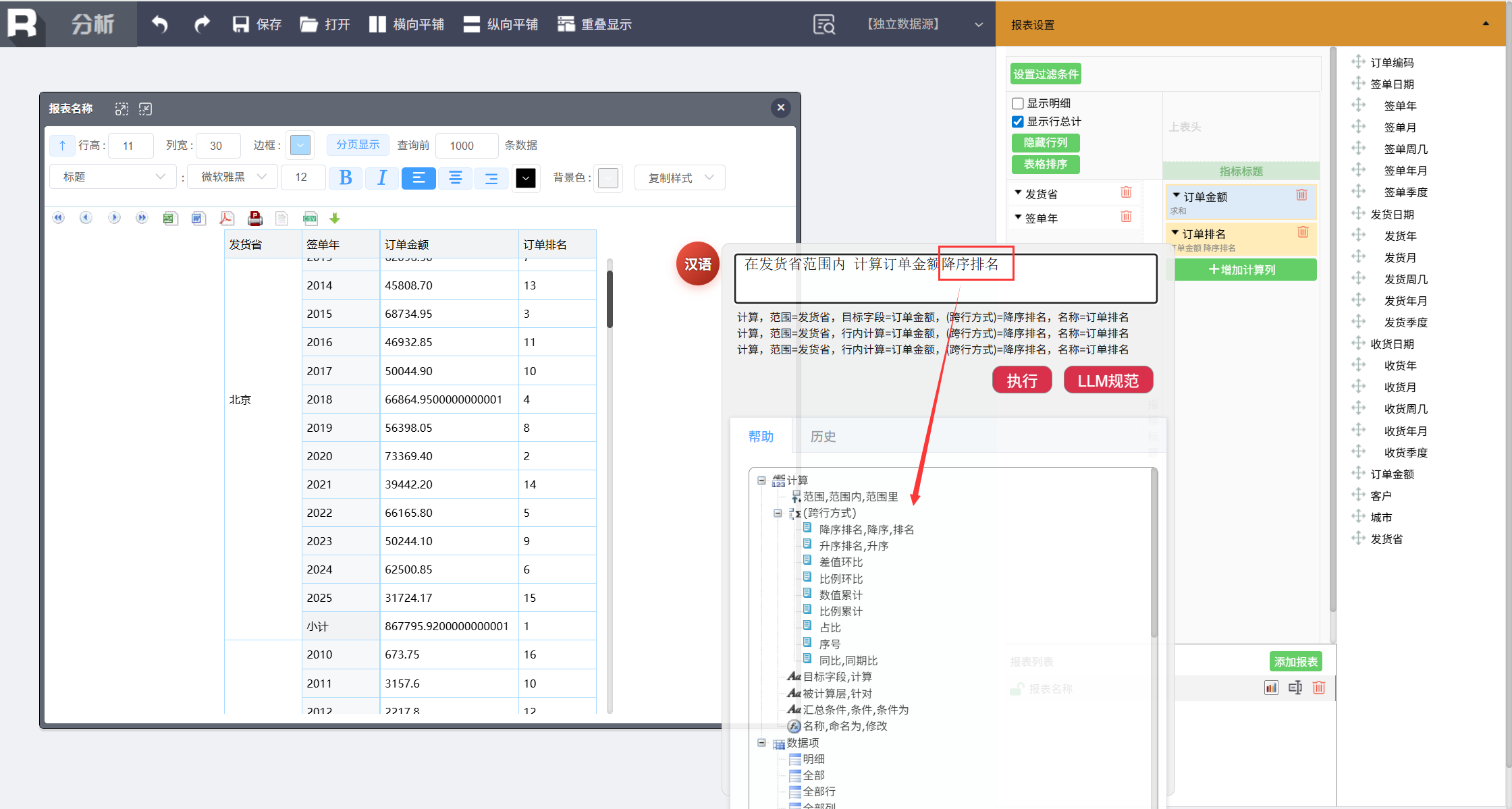
再比如输入“表头”,则会直接出现可以使用的数据项。
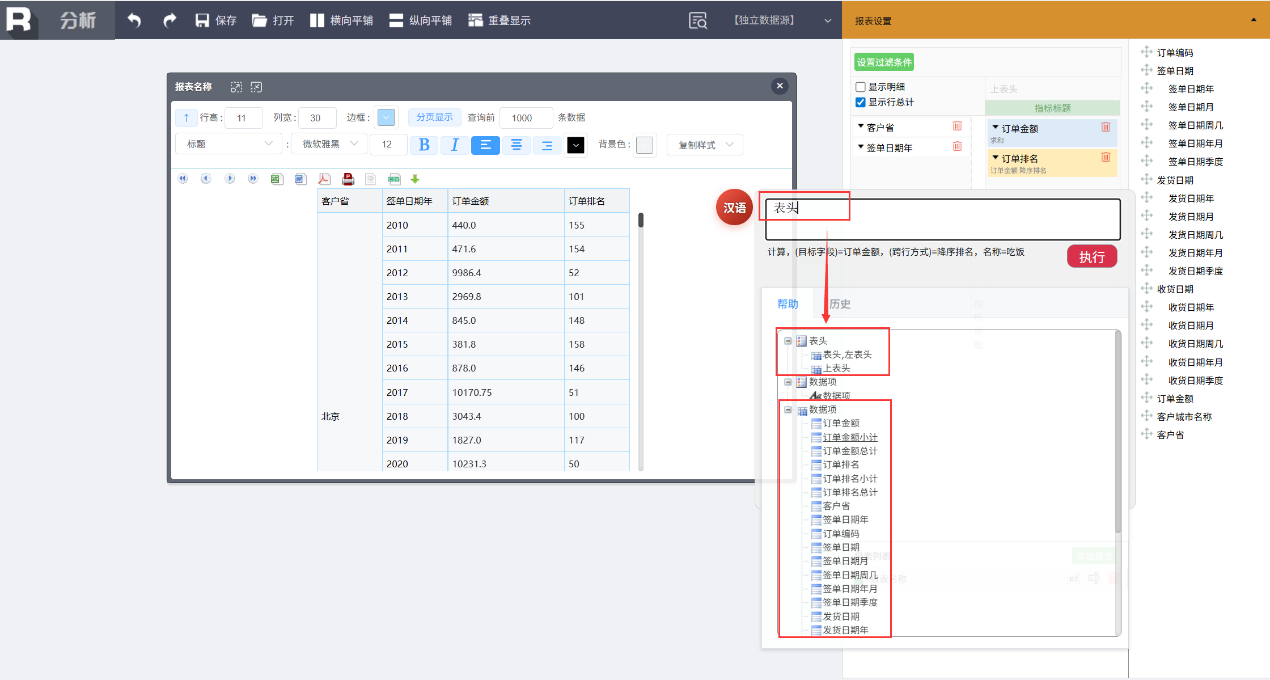
这意味着,无需记忆复杂语法,通过提示和参考,可以快速掌握“如何说”,从而将分析意图转化为有效的指令。对于熟悉业务的用户而言,这一过程非常直观自然。
扩展能力:从自由数据查询(NLQ)开始
上述 NLR 能力,让用户能对一份“已有”的数据集制作报表。而有时候,做表的第一步需求是准备数据,这份数据可能并不存在于任何预制的数据集或报表中。为此,润乾报表提供了与之无缝衔接的NLQ(自然语言查询)能力。
NLQ 允许用户在其被授权的数据范围内,用汉语向数据库发起查询获得数据。例如要制作一份《大额订单报表》,报表人员可以直接用自然语言进行查询:“订单金额超过 2000 的订单信息、明细数、客户名称和城市”。系统会自动理解“订单金额”“订单信息”“明细数”“客户名称”“城市”这些业务术语,并智能地关联多张数据表,精确筛选出符合条件的记录,计算出每个订单包含的明细条目数,最终生成一份结构清晰、可直接用于制作报表的数据列表。
这背后依赖于一套预先配置的“业务词典”。词典将业务术语与数据库中具体的表、字段和计算逻辑进行精确映射,确保系统在理解用户意图时,是在可控、已知的业务语义范围内进行,从机制上避免了通用大模型可能产生的“幻觉”。同时,所有查询操作和结果都严格受限于用户自身的数据库访问权限,保障了数据安全。
通过 NLQ 查询获得的数据集,可以立即作为新报表的起点。报表人员无需复杂操作,即可直接使用前述的 NLR 能力进行进一步加工,例如快速“按城市对订单金额进行求和汇总”,或者“统计每个客户的大额订单数量”,并一键生成图表。这构成了从“自由取数”到“灵活制表”的完整、高效的自然语言报表解决方案。
硬核优势:又稳又省,私有安全
润乾报表这套基于规则引擎的自然语言处理能力(涵盖 NLQ 与 NLR),给软件厂商和最终用户带来了实实在在的好处:
稳定可靠,告别“幻觉”:规则引擎的每一步输出都是确定的。词典中定义了明确的业务术语和计算逻辑,如果用户指令中出现未定义的词,系统会明确提示“无法识别”,而不是像 LLM 那样编造一个似是而非的结果。当业务逻辑变化时(如“销售额”的计算规则需要扣除运费),管理员只需在指标词典中修改公式,整个过程像修改配置文档一样清晰可控。这意味着整个转换路径是可解释、可完善的。
私有化部署,数据安全:整个方案可以完全部署在企业内部服务器上,数据无需出域,彻底满足金融、政府、大型企业对数据安全与隐私合规的严苛要求。而云端 LLM 方案不可避免地存在数据外传的风险。
成本低,部署简单:规则引擎计算开销很小,普通 CPU 服务器即可流畅运行多个并发任务。由于不依赖 LLM,没有 Token 费用,用户无需担心使用成本。相比之下,大模型方案通常需要昂贵的 GPU 集群和复杂的 RAG 等配套技术栈,显得笨重而复杂。
低延迟,体验流畅:基于本地规则引擎的解析与计算,通常在毫秒级响应,用户从输入指令到获得结果都能获得即问即答的流畅体验。
当然,纯规则方案有其局限——它需要相对规范的语言,无法理解“帮我瞅瞅上个月卖得最火的是啥?”这种过于口语化的表达。如果有条件引入 LLM,可以让它作为“智能前台”,将用户随意的口语“翻译”成规范指令(如“查询上月销量前十的产品”),再由规则引擎精准执行。这种做法的妙处在于:LLM 输出的规范指令是“人话”,用户能看懂并确认,发现不对可以立即纠正——这比让 LLM 直接生成难以验证的 JSON 或 SQL 要可靠得多。而且这种“文字规范化”的任务足够简单,用私有化部署的小参数模型就能胜任,成本也低。
对于应用软件厂商而言,集成这样一套既能深度嵌入、又具备自然语言交互能力的报表模块,带来的价值是具体且可量化的:
实现真正的任务转移,降低成本
传统模式下,散碎且持续的报表需求是开发团队的“成本出血点”。引入普通自助报表工具,常因使用门槛导致转移不彻底。而“易集成 + 自然语言交互”的组合,大大增加了用户自助解决问题的意愿和能力。易集成降低了部署阻力,NLR 对话式分析则扫清了使用障碍。这意味着,项目交付后,来自客户的大量临时性数据需求,可以更有效地由最终用户自行完成,从而将开发团队从重复劳动中解放出来,大幅降低项目的长期维护和支持成本。提升产品竞争力与客户满意度
在同质化竞争的市场中,软件系统如果能让客户感觉“更智能、更好用”,便构成了坚实的竞争壁垒。当竞争对手的客户还在为导出数据、手动制表而烦恼时,我们的用户已经可以通过简单的对话,在系统内即时获得可视化分析结果,让系统从“流程记录”工具升级为“业务洞察”助手。这种体验上的代差,能直接提升客户满意度和黏性,使产品在项目竞争中赢得优势。
报表需求的持续产生,是业务动态发展的自然结果。软件厂商的关键任务,不是试图消除需求,而是通过有效的工具,将这些需求的满足成本优化到最低。
润乾报表所提供的,正是这样一套务实的工具组合:它首先以优异的集成性,确保能力可以低成本、无缝嵌入现有产品中;进而以听得懂人话的交互方式,确保能力能够被业务用户使用起来。这两者结合,才能真正将开发团队从“报表开发循环”中解放,将自助报表的能力有效地、彻底地交还给用户方。
在 AI 技术喧嚣的当下,这种聚焦于解决具体问题、降低综合成本、提升产品可销售性的务实路径,或许正是广大软件厂商在竞争中构建自身护城河所需要的。

