


关于大数据文件的内存问题优化咨询
图一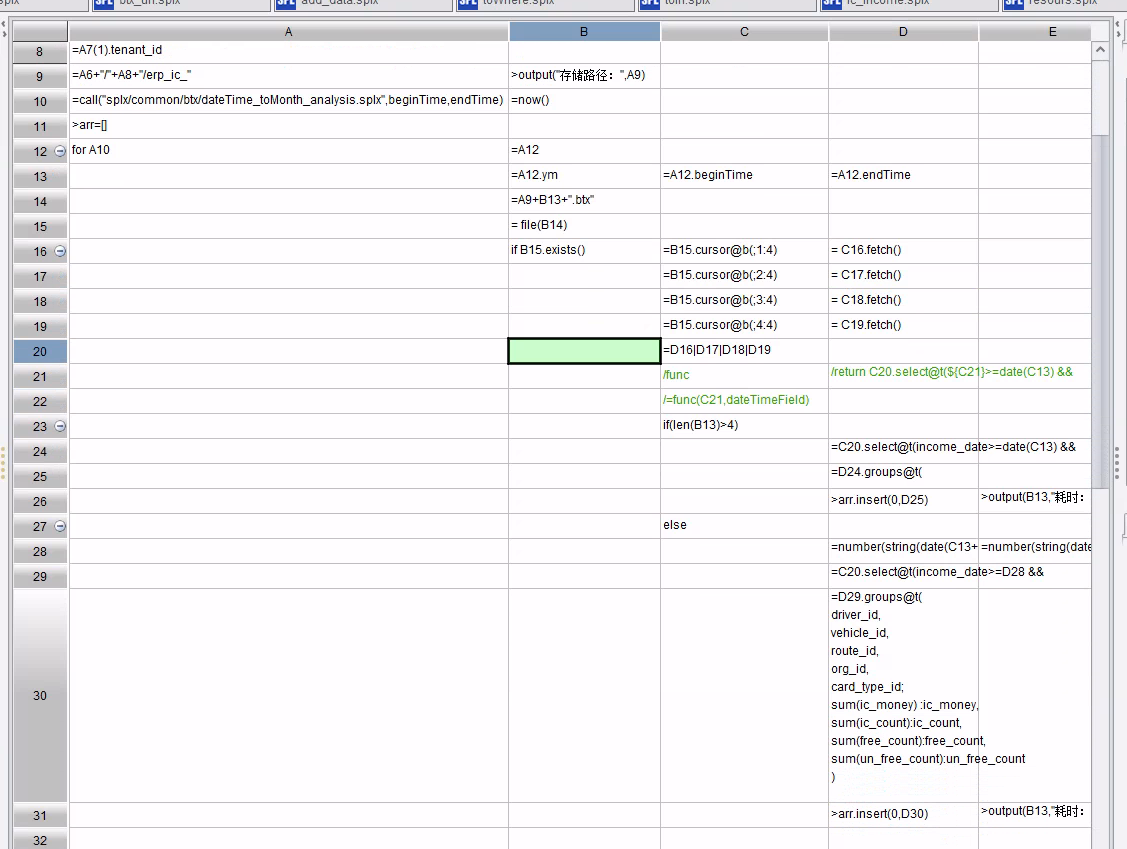
图二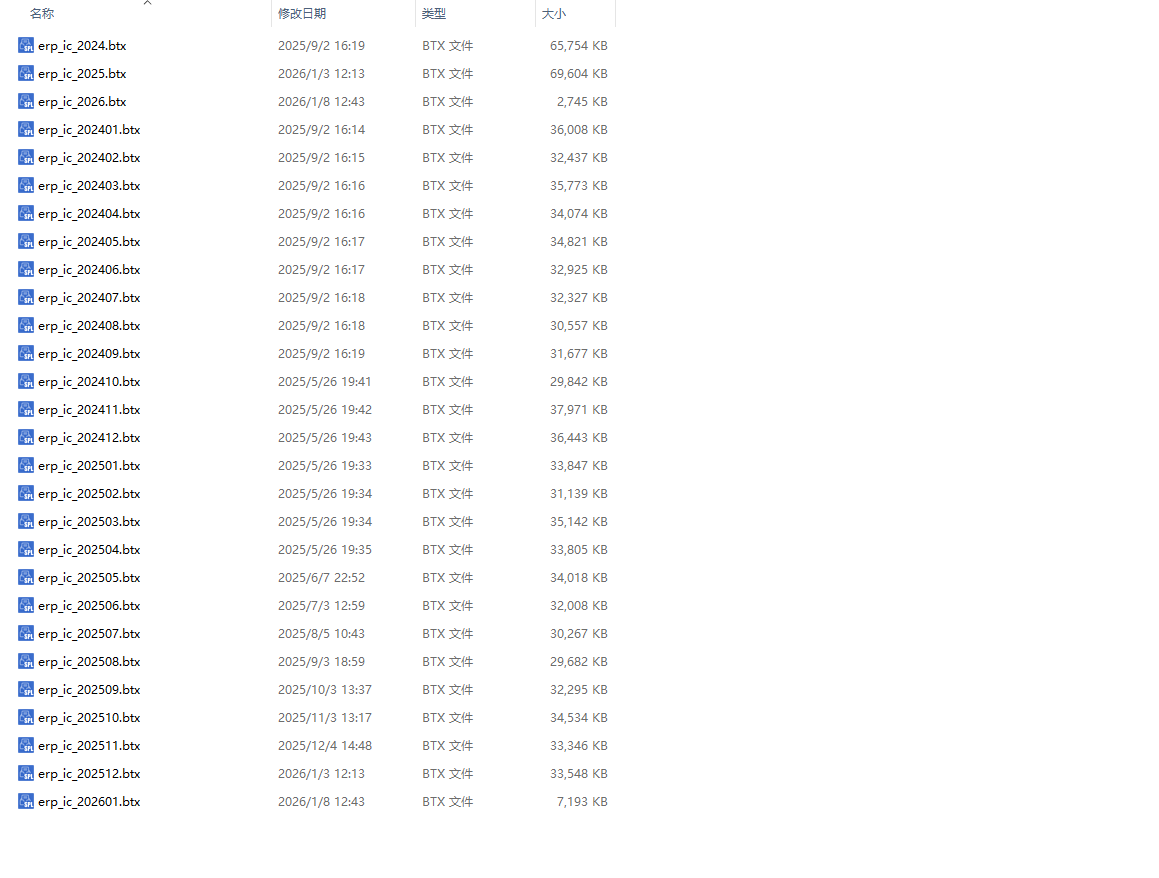
场景:公交每天的建议数据,由于比较大所以先在已经从库追加到每天的 btx 里面,因为客户可以任意天去查询,所以目前分三段,
第一段按年进行统计出了每辆车的数据到文件中,以便查询跨越一整年的
第二段按月进行统计出了每辆车的数据到文件中, 以便查询跨越一整月的
第三段按天进行统计出了每辆车的数据到文件中, 以便查询到任意天
其中每个文件大小如上同二
目前实现框架是润乾报表 + 集算器 +springboot+docker 进实现的
目前问题经常内存爆棚,导致 docker 容器重启
实现叫脚本如图一和附件,是分析出一个集算器加载了比较多的数据,可能会导致内存过大,帮看看是否有改进方案


1、C20 后续动作是 select.groups,那么这里不需要把数据先从文件中全部拿到内存后再计算。
SPL 的游标不仅有读数功能,还可以在上面附加运算。
游标上的运算函数可以分为两大类,一类称为延迟计算,执行此类函数时仅仅是做个标记,并不会实质性地遍历游标。另一类称为立即计算,会实质地遍历游标并计算出结果。
2、若数据量较大,需要并行满足性能要求,建议使用组表,而不是集文件
对 B15 的读取和过滤,如果 income_date 字段天然有序的话,btx 也可以使用 iselect@b 外存二分查找法,也返回游标,不用马上 fetch 出来。
后续再用游标 cs.groups 计算出结果。伪代码如下:
具体使用请参考以下文章:
1、 【性能优化】3.1 [外存查找] 二分法
2、 https://d.raqsoft.com.cn:6443/esproc/func/iselect.html
上述观察不一定对,仅供参考。
请以集算器大佬们的回复为准。