


人人都能实施的智能问数,中小用户也能玩得转的 Text2SQL
AI 时代,到处都在说“智能问数”,用大白话直接问,数据就给你整得明明白白。理想很美好,可真要一探究竟,大家心里就打了鼓:这玩意儿是不是得养个 AI 科学家团队?是不是得买几十上百万的 GPU 服务器?查出来的数要是不准,谁敢拿来做决策?
别急,润乾 NLQ 带来了一条不同的路——一条让中小企业、普通开发团队都能轻松上车、用得安心、花得明白的路。不依赖“黑盒”大模型去猜,而是用一套清晰的“规则翻译官”,把业务问题,精准无误地转换成数据库能听懂的指令。
把业务知识,变成机器的“说明书”
大模型(LLM)像是个天赋异禀但偶尔会跑偏的“实习生”,能力很强,但产出不稳定,关键是你还看不懂他的工作过程(生成的 SQL 或中间 DSL/MQL),没法有效复核。
其实思路可以更直接:企业的数据分析需求,绝大部分都有规律可循。无论是“上季度华北区销售 TOP10”、“库存低于安全线的产品”,还是“回款周期超过 60 天的客户”,其核心无非是找什么对象(表)、看哪些方面(字段)、按什么条件筛选(过滤)、怎么分组计算(聚合)。
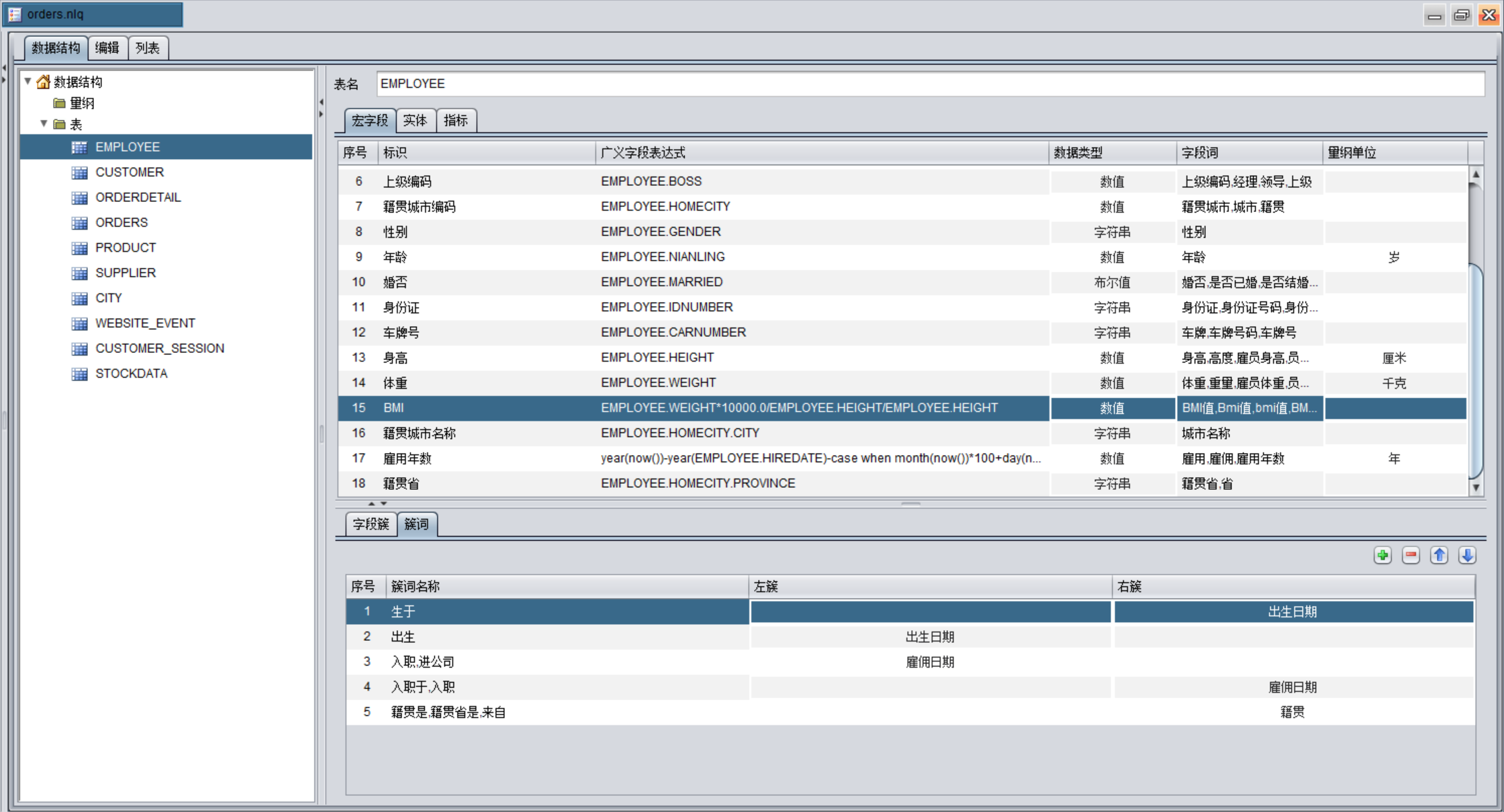
润乾 NLQ 的核心,就是把这套业务逻辑,预先编制成一套机器能严格执行的“业务词典”和“查询规则”。当问“去年北京发往青岛的订单”时,系统会像查字典一样,精准匹配:
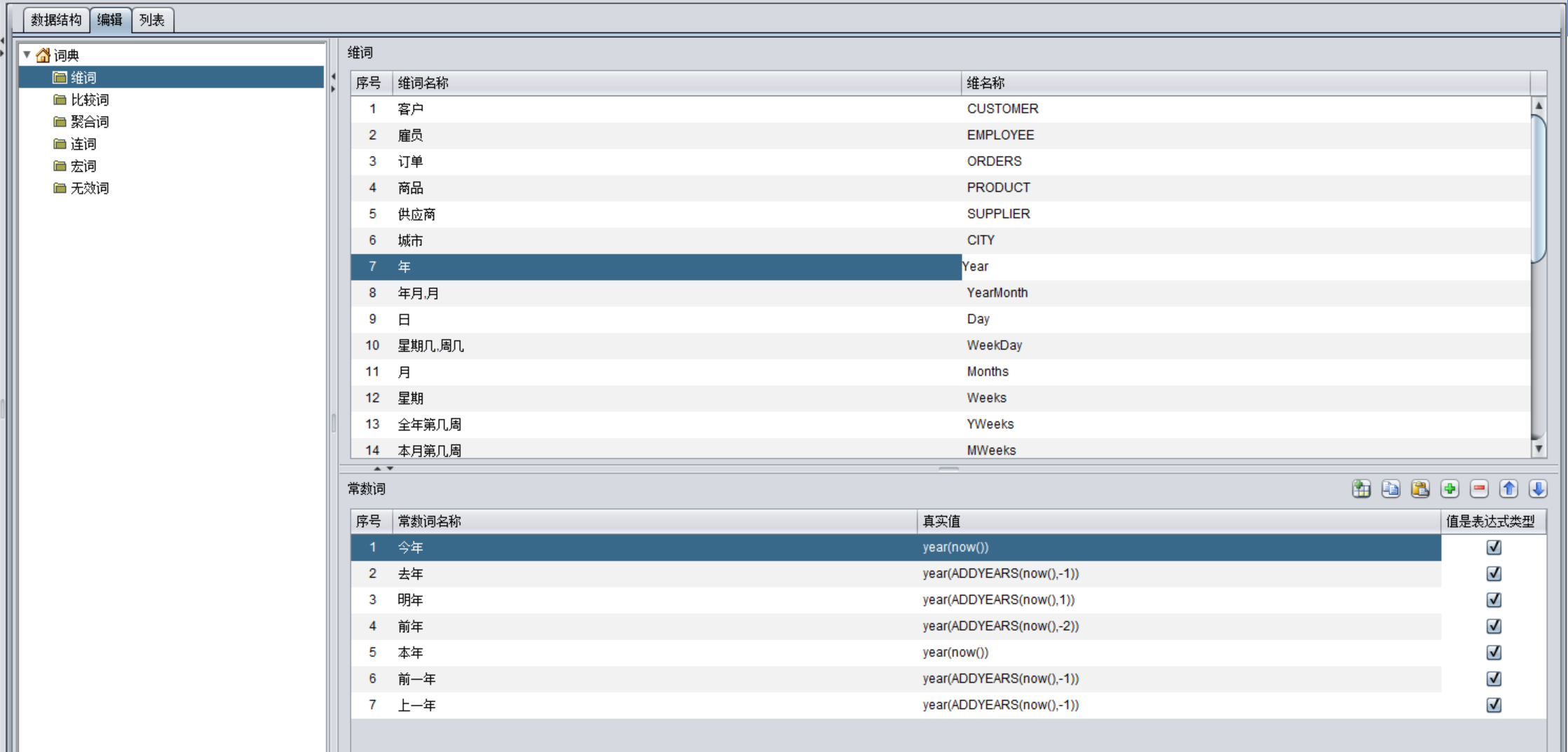
“去年” → 对应时间计算逻辑:year(ADDYEARS(now(),-1))
“北京”、“青岛” → 对应“城市”维度下的具体编码
“发往” → 这是一个关键动词,自动关联到“发货”和“收货”两个字段簇
“订单” → 确定核心查询主体是订单表
然后,用一套确定的规则,将这些元素组装成准确的查询语句:
select 发货日期 #Year as 发货日期 _Year, 发货城市 as 发货城市, 客户城市 as 客户城市, 订单编码, 签单日期, 发货日期, 收货日期, 订单金额 from ORDERS where (发货日期 #Year=year(ADDYEARS(now(),-1)))AND ( 发货城市 =30101) AND (客户城市 =20201)
整个过程没有猜测,只有匹配和执行,从根本上杜绝了“一本正经胡说八道”的数据幻觉。
算笔明白账:你的成本,到底省在哪?
这是 NLQ 最能打动人的地方,我们掰开揉碎了说。
硬件与运算成本:从“养超跑”到“开家用车”
大模型方案:如同拥有了一台“性能猛兽”,但其开销令人咋舌。若选择私有化部署,高端 GPU 服务器是基础门槛,随之而来的高额购置费、运维成本让很多企业望而却步。若采用公有云 API 按次付费,虽然看似灵活,却要面临数据必须离境,将内部业务数据发送至外部接口,存在安全与合规风险;同时随着使用量的增长,账单可能悄然失控。尤其是直接生成复杂的 SQL 语句,消耗的 Token 数量巨大,长期累积的成本不容小觑。
NLQ 方案:其核心是一个高效的规则匹配与翻译引擎,计算开销极低。不依赖任何 GPU 算力,在普通 CPU 服务器上即可流畅运行,轻松支撑数十人乃至上百人的并发查询。由于它仅需将规范的自然语言“翻译”为内部指令(而非消耗大量算力去“推理”生成 SQL),其单次查询的算力与资源成本,可能仅为大模型方案的百分之一甚至更低。这使得私有化部署的门槛大幅降低,长期持有的总成本变得极为透明和亲民。
技术与人力成本:从“组建火箭队”到“培训导游”
大模型方案:要让它真正懂你的业务,仅靠简单的“提示工程”是远远不够的,通常需要再收集整理数据做“微调模型”、利用 RAG 技术构建“知识库”等等,这需要深谙 AI 算法的专家团队,人力成本高昂,项目周期漫长,技术风险集中。
NLQ 方案:核心实施工作叫做“配置业务词典”。这活儿谁干最合适?就是最懂公司业务的数据分析师、IT 工程师或关键业务人员。你需要做的,是把“销售额”、“毛利润”、“VIP 客户”这些公司内部概念,通过可视化工具,一一对应到数据库里的表和字段,并设定好计算规则。这更像是在绘制一份给机器用的“业务地图”,而不是研发一颗“AI 大脑”。熟悉数据库的普通应用开发团队完全能够胜任,无需引入稀缺且昂贵的 AI 专家。
维护与信任成本:从“开盲盒”到“透明工厂”
大模型方案:结果出错时,调试像破案。是提示词不对?训练数据有偏?还是模型又“幻觉”了?定位难,修复更贵(可能需重新训练),且效果难保证。
NLQ 方案:一切基于规则。如果查询报错或结果不对,你可以像调试普通软件一样,快速、清晰地定位问题:是“华东区”这个词没录入词典?还是“毛利率”的计算公式配置有误?修复方法就是修改配置,点击保存,立刻生效。系统可控、可预期、可优化,这会让 IT 部门和业务部门都无比安心。
能力不妥协:能干的活,超乎你想象
规则引擎的能力边界究竟在哪?让我们用一组查询实例来回答。只要用相对规范的业务语言提问,润乾 NLQ 的解析能力足以覆盖绝大多数数据分析需求。
1. 明细查询:想要什么数据,直接列出来
简单列举:“列出雇员姓名”、“商品编码、名称、重量、类别、库存量”。就像点菜一样,说出字段名,数据即刻呈现。
附带计算:“雇员姓名、身高、体重、BMI 指数”。即使像“BMI 指数”这样的计算字段,只要预先定义好公式,查询时就能自动算出。
智能消歧:“订单编码,发货 城市 日期,收货 城市 日期”。系统能通过“发货”、“收货”等簇词,自动区分出“发货日期”和“收货日期”,准确返回四列数据,无需人工指定表头。
跨表关联:“订单编码,产品名称,供应商名称和城市”。无需了解数据库 JOIN 逻辑,NLQ 自动关联订单、产品、供应商多张表,返回整合信息。
2. 复杂过滤:条件再刁钻,也能精确定位
多条件组合:“年龄 45 到 50 岁之间,且籍贯是北京的雇员”。支持“且”、“或”逻辑,进行精确筛选。
业务术语过滤:“已售罄的商品信息”。只需将“已售罄”定义为宏词(对应逻辑:库存量 <=0),即可用业务语言直接查询。
动词关联过滤:“北京发往青岛的订单”。通过“发往”这个动词,系统能自动将“北京”绑定到发货城市,“青岛”绑定到收货城市,构建复杂关联条件。
时间智能处理:“去年第 3 季度的订单”、“上周一的会话记录”。系统能理解“去年”、“上周”等相对时间,并自动转换为准确的日期范围进行查询。
3. 聚合分析:不只查看,更要洞察
基础汇总:“各城市发货的总金额”、“每月订单数”。轻松完成分组统计。
聚合后筛选:“总订单数超过 20 的客户”、“平均售价超过 500 元的海鲜商品”。先计算,再筛选,直达关键群体。
嵌套聚合:“订单金额总和大于 20 万元的女员工”。这需要先按员工汇总订单金额,再用结果过滤员工表,NLQ 可以一气呵成。
4. 混合关联与复杂指标:应对综合业务场景
多源数据对齐:“各省的员工数、产品数和订单数”。这句查询需要分别从员工表、产品表、订单表中计数,再按“省份”维度对齐结果,NLQ 可以准确执行。
跨事实表分析:“各商品的浏览数、下单数和付款数”。浏览、下单、付款数据可能存储在不同的事实表中,NLQ 能按商品维度进行关联汇总。
复杂指标计算:“月连涨天数大于 5 天的股票”。对于“连涨天数”这类 SQL 难以直接计算的高级指标,NLQ 可通过内置的SPL 计算引擎专门处理,扩展了传统 SQL 的分析边界。
这些例子仅仅展示了能力的一角。从简单的数据检索到涉及多表关联、条件过滤、分层聚合的复杂业务分析,润乾 NLQ 通过其结构化的规则体系,提供了一条确定、可靠且覆盖全面的自然语言查询路径。
坦诚相告: “边界”在哪里?
当然,世上没有完美方案,NLQ 的局限性也同样明显:
灵活性有门槛:需要相对规范的表达。对于过于口语化或模糊的描述(比如“我需要查询商品表中单价在 9 块五毛钱到等于 12 块钱的”或“南京的客户,或者任意直辖市的”),需要先转化为规范的查询语句。它极度依赖那份预先配置好的“业务词典”,词典之外的新说法,它暂时无能为力。
知识更新需手动:不会自学。当公司新增一个“用户互动热度”指标时,必须由管理员在词典中明确定义其计算规则,才能被查询。这需要一些初始的建设和持续的维护投入。
但是,这恰恰引向了它的最佳使用场景:对于业务流程稳定、分析需求规范的企业内部 BI 系统,它是可靠的核心引擎。
当然,NLQ 也可以和 LLM 配合使用。对于那些非常口语化的表达,一个绝佳的搭配是:用大模型(LLM)作为“前端翻译”,把随意的口语转换成 NLQ 能听懂的规范问题,再由 NLQ 这位“老会计”精准执行。这时候 LLM 只要将汉语转换成另一种汉语,难度低得多,准确率也高得多,相应的 token 成本也低得多,而且,更重要的是,转换结果可读可确认,彻底避免幻觉出错。NLQ+LLM= 灵活 + 可靠。
如何上手:比你想象得更简单
最直接的方式,润乾 NLQ 已经作为智能模块,内置在润乾报表产品中。这意味着,使用或集成润乾报表,你就自然获得了这项“智能问数”的能力。
这个实施过程非常务实:由熟悉业务的同事,通过可视化界面,将日常分析中常用的业务术语(如“新订单”、“直辖市”、“已售罄”)、字段组合(如“发货 城市 日期”)、计算指标(如“BMI 指数”)等,配置到系统的“业务词典”中。一旦配置完成,用户就可以用规范的语言直接提问,立即获得准确数据。
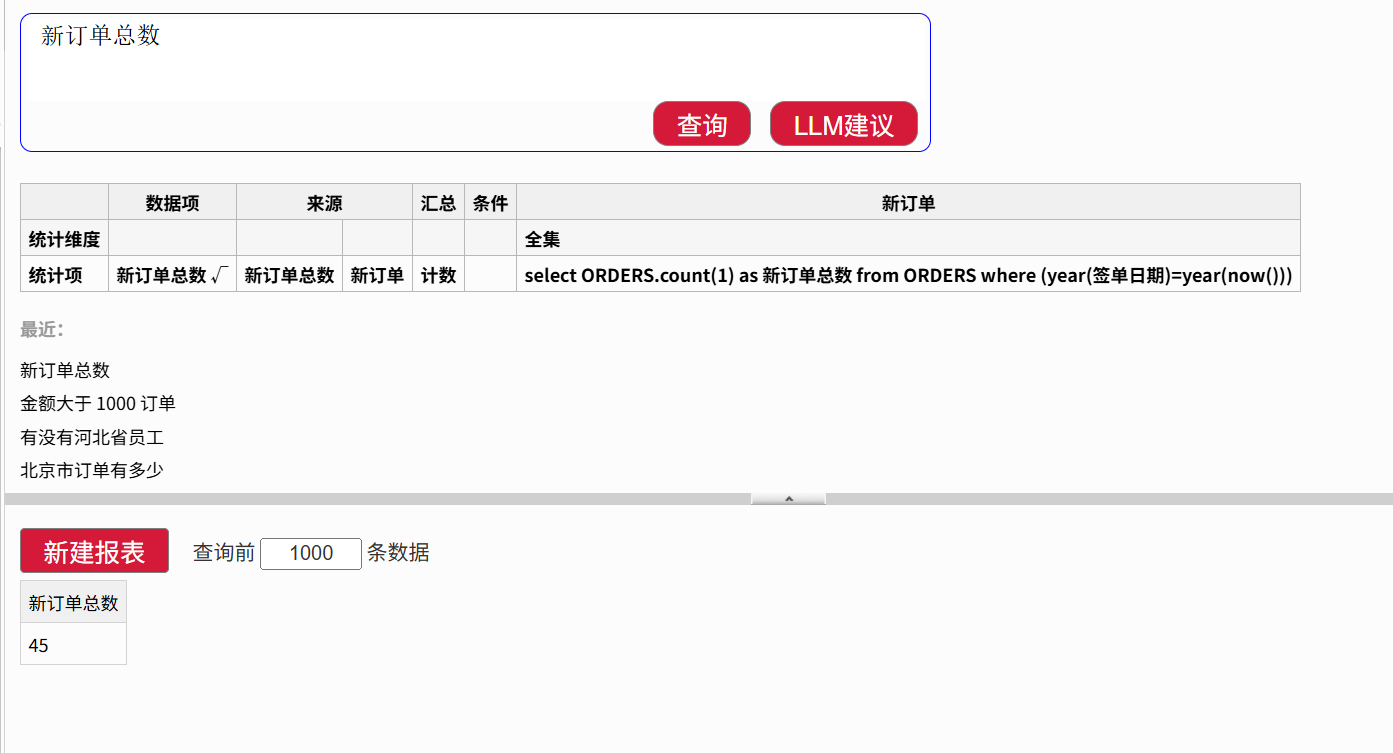
例如,配置好“新订单”对应本年订单的过滤条件后,用户只需输入“新订单总数”,系统就能自动统计出今年的订单数量,无需编写任何 SQL。
如果要搭配 LLM 解决灵活性,在润乾的官方技术社区(乾学院)上已经分享了使用大模型辅助生成 NLQ 查询语句的提示词(Prompts)。

(部分提示词示例)
可以利用这段分享的提示词,再用某个公开的 LLM 转换后再查询,从而获得更强的灵活性。
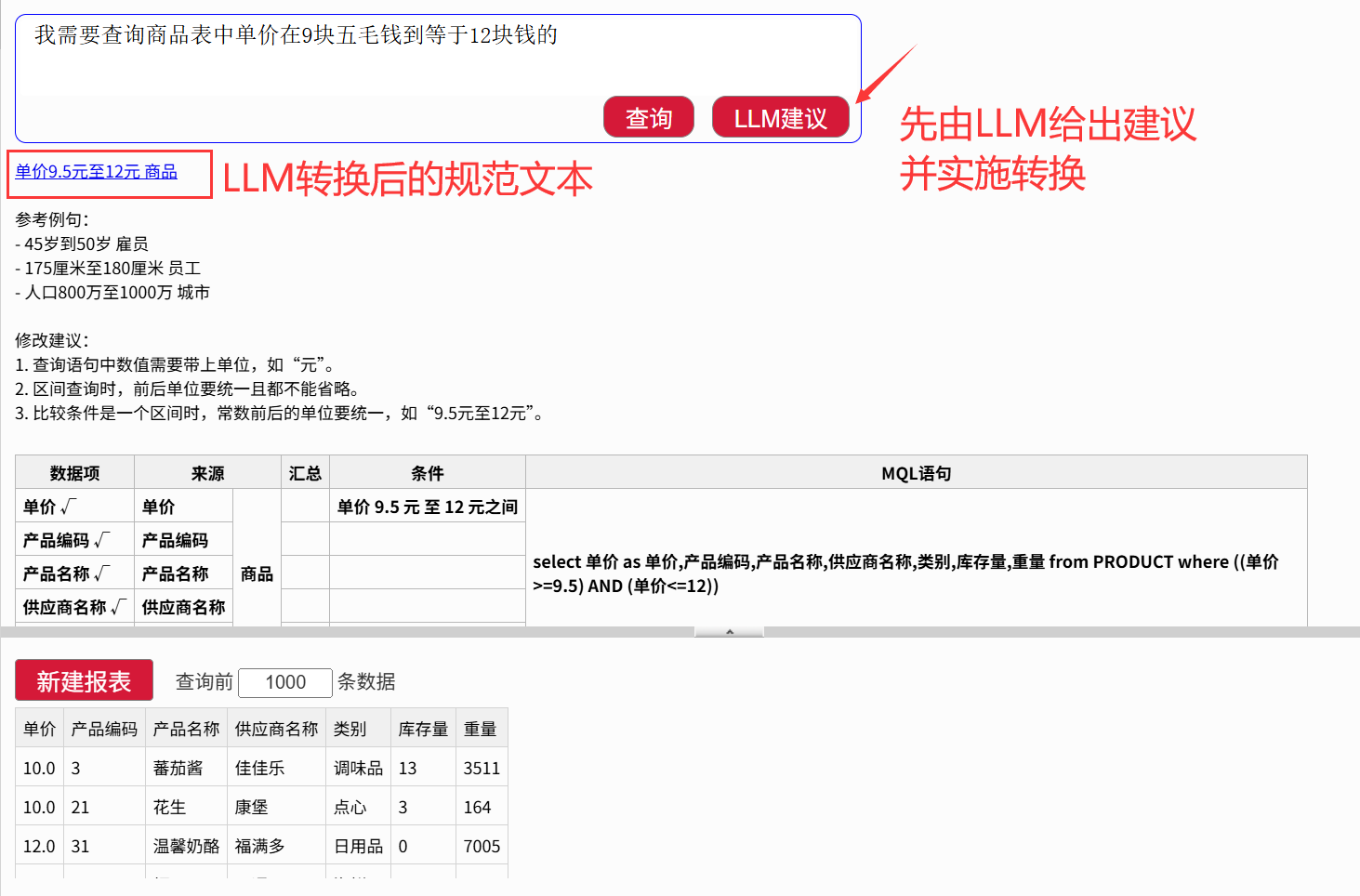
比如这个非常口语化的查询“我需要查询商品表中单价在 9 块五毛钱到等于 12 块钱的”,直接查询是不行的:
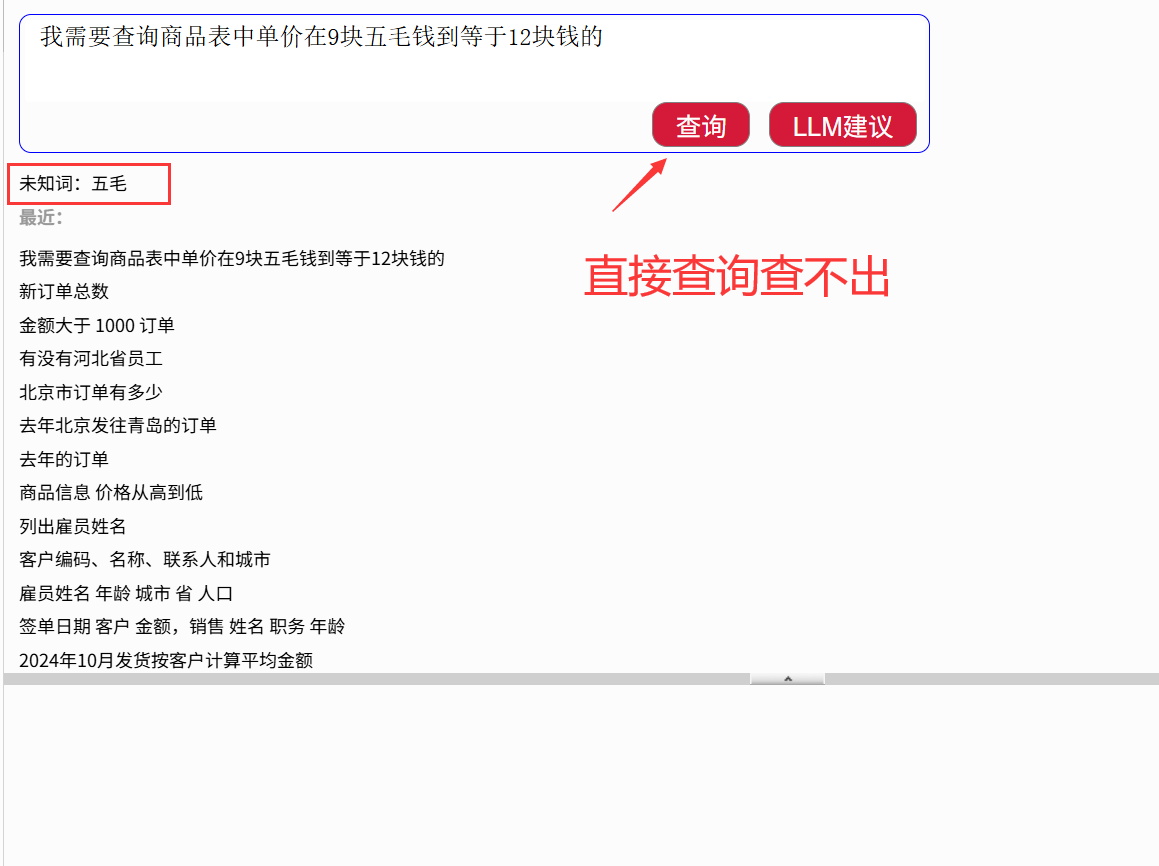
被 LLM 转换后就可以了:
在追逐技术浪潮时,有时最实用的方案,未必是最炫酷的那一个。润乾 NLQ 选择了一条务实之路:不追求万能的理解,而追求在核心业务查询场景下的百分百准确、极低成本与完全可控。
它让“让数据说话”这件事,从一项昂贵且不确定的技术冒险,变成了一个可规划、可实施、可管理的标准化项目。对于广大的中小企业、务实的技术团队和追求稳定产出的业务部门而言,这或许才是当下更值得拥有的“真智能”。

