


另辟蹊径的 Text2SQL,不用大模型也能搞 chatBI
随着 AI 大模型的技术突破,用自然语言与数据进行对话的 ChatBI 概念也变得火热起来,人们普遍认为这件事终于具备了可行性。于是,业界很自然地沿着大模型(LLM)这条技术路线进行探索,期待它能理解业务人员的随意提问并直接返回数据结果。
然而,理想很丰满,现实却有点骨感:LLM 方案始终存在“幻觉”问题,而且成本高昂、部署与调优过程也相当复杂。
我们注意到,在 BI 这个特定场景下,业务人员用于查询数据的自然语言,其实并没有日常对话那么随意和复杂。诸如“上月销售额”、“销量最高的产品”、“北京地区的客户销售额”这类问题,其语义模式实际上是可抽象、可结构化的。润乾报表 NLQ 组件正是基于这一洞察,绕开了大模型的技术路线,通过一套精密的“规则词典”,同样实现了高效、可靠的自然语言查询。
核心机制:它不是“大脑”,而是“交通指挥塔”
你可以把大模型想象成一个博览群书、反应迅捷的“天才”,但它有时会“自由发挥”。而润乾 NLQ,则像一个一丝不苟、精通所有交规和地图的“交通指挥塔”。它的工作,不靠灵感,靠的是一套预先录入的、极其详尽的“城市交通手册”——也就是它的词典,也就是领域知识库。
承载领域知识的词典
这套词典是 NLQ 的灵魂,远不止是几个同义词那么简单,而是一个结构化的知识库:
数据元数据词典:明确定义了有哪些表(如订单表)、哪些字段(如客户名称、订单金额),以及它们的数据类型(文本、数字、日期)。这是最基础的“地图”。
业务语义词典:这是让 NLQ“懂业务”的关键。
维词:定义了像年、月、省份、产品类别这样的分析维度。NLQ 知道“月”是从日期字段里提取出来的一个层次。
指标:定义了像销售额、月活数这样的业务指标。关键是,指标可以绑定计算公式!比如“销售额”可能就是“单价 × 数量”,而“毛利率”则有更复杂的计算逻辑。这杜绝了 LLM 胡编乱造公式的可能。
常数词:枚举出的维度值,比如看见“北京”就知道要对应“城市”维下的具体 ID。
……
查询逻辑词典:这是理解用户意图的“语法手册”。
比较词:如大于、不超过、在... 之间。每个词都对应一个表达式,比如“大于”对应?1 > ?2,其中?1 是字段,?2 是值。
聚合词:如总和、平均数、最多,对应 SQL 中的 SUM,AVG,MAX 等函数。
无效词:如请帮我查一下、那个,这些在分析时会被过滤掉,提高语句解析的准确率。
……
从自然语言到 MQL 的标准化转换
在 BI 场景中,绝大多数查询都可以归纳为对维度、指标、条件的不同组合,这正是模式化查询的基础。润乾 NLQ 定义了专用的MQL(Metrics Query Language)作为中间查询语言,专门用于描述这种模式化的 BI 查询需求。
用户输入的相对规范的自然语言,会首先被转换成结构化的 MQL 语句,再转换成 SQL 到数据库查询并返回结果。
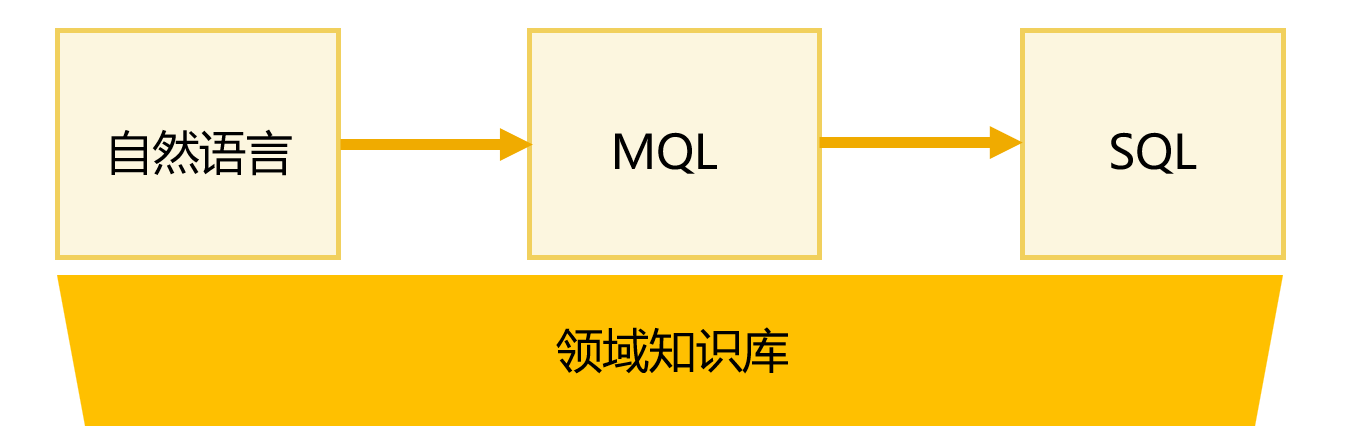
事实上,大多数 Text2SQL 技术都会采用某种中间查询语言来解决自然语言到 SQL 转换的精确性问题。这样可以将不确定性限制在自然语言到中间语言的转换环节,而确保从中间语言到 SQL 的生成是精确的。润乾 NLQ 也是同样机制,不同之处在于,其专用的 MQL 采用了类 SQL 的语法而不是常见的 json 结构,而且在查询覆盖范围要远比大多数 Text2SQL 更为广泛。
例如,"40 岁以上雇员姓名、年龄、城市和省"这样的单表明细查询,NLQ 能够精准识别年龄过滤条件并返回所需字段;而"每月订单数 "这样的单表聚合分析,MQL 会自动按月份分组并完成计数计算。
在处理复杂业务逻辑时,MQL 同样表现出色。面对"订单编码,商品名称,供应商名称和城市 "这样的多表关联查询,NLQ 能够自动解析表间关系,准确关联三张表中的信息;而对于"每年的付款数和总销售金额 "这类多表对齐分析,MQL 也可以实现不同事实表在同一时间维度下的指标对齐计算。
更复杂的是,MQL 还能应对"订单金额总和大于 20 万元的女员工 "这样的子表聚合条件查询,NLQ 会先在订单表中按员工聚合金额,再将结果作为条件过滤员工信息。即使是"月连涨天数大于 5 天 "这样的复杂指标计算,MQL 也能通过内置函数准确实现业务逻辑。
一个具体的查询过程
当用户输入“去年北京发往青岛的订单”时,NLQ 会启动一套精密的解析流程:
词汇切分与过滤:NLQ 首先将句子拆解为“去年”、“北京”、“发往”、“青岛”、“订单”等关键令牌,并过滤掉“的”等无实际查询意义的虚词。
词典匹配与语义关联:
去年→ 匹配到“年”维词,其表达式自动计算为 year(ADDYEARS(now(),-1))。
北京 / 青岛→ 匹配到“城市”维的常数词,看到“北京”“青岛”,NLQ 知道它对应“城市”维下的一个具体 ID,自动完成语义映射。
发往→ 识别为关键动词,该动词关联到“发货”字段簇。字段簇是 NLQ 的核心特色:这里的动词 "发往" 关联的 "发货" 字段簇,实际上是一个预定义的语义包,其中包含了发货城市、收货城市、发货时间等多个相关字段。NLQ 据此智能理解 "北京" 应对应发货城市,"青岛" 应对应收货城市。通过“发往”这个动词,就知道了涉及“发货地”和“收货地”两个地址的匹配,从而精准构建查询条件。
订单→ 匹配到“订单”实体,确定了查询的主表及需要返回的默认字段集。
MQL 生成:将所有匹配结果组装成一条结构化的 MQL 语句。该语句清晰地描述了查询逻辑:从订单表,筛选出“发货城市为北京、收货城市为青岛、订单年份为去年”的所有记录,并返回预设的订单核心信息。
执行与返回:MQL 引擎将逻辑转换为底层数据库可高效执行的 SQL,最终将精准的查询结果返回给用户。
硬核优势:在 BI 战场上“稳、省、简”
这套基于规则的设计,在企业 BI 场景下带来了实实在在的好处:
稳定可靠,告别“幻觉”:NLQ 的词典是“知之为知之,不知为不知”。如果用户的查询中有一个词(比如“用户活跃度”)没有在词典中定义,NLQ 会明确告诉你“无法识别”,请求换种说法。它不会像 LLM 那样,为了给出一个答案而编造一个看似合理实则错误的结果。这样不仅解决了中间语言到 SQL 的精确性问题,同时也依靠词典实现了从自然语言到中间语言的精确,从而保证整个流程都是精确的。这种精确性对于依赖数据决策的 BI 场景至关重要。
成本极低,部署简单:规则引擎计算开销很小,普通 CPU 服务器即可流畅运行多个并发任务,实现私有化部署的成本可比大模型方案降低一两个数量级。相比之下,大模型方案通常需要昂贵的 GPU 集群和复杂的 RAG 等配套技术栈,显得笨重而复杂。
知识透明,可调试、可维护:当业务逻辑变化时,比如“销售额”的计算规则需要扣除运费,管理员只需要在指标词典里修改一下公式。整个过程像修改配置文档一样清晰、可控。而 LLM 方案则需要重新收集数据、微调模型,过程是个黑盒,且成本高昂。
其实不止于 SQL:它自带了一个“计算引擎”
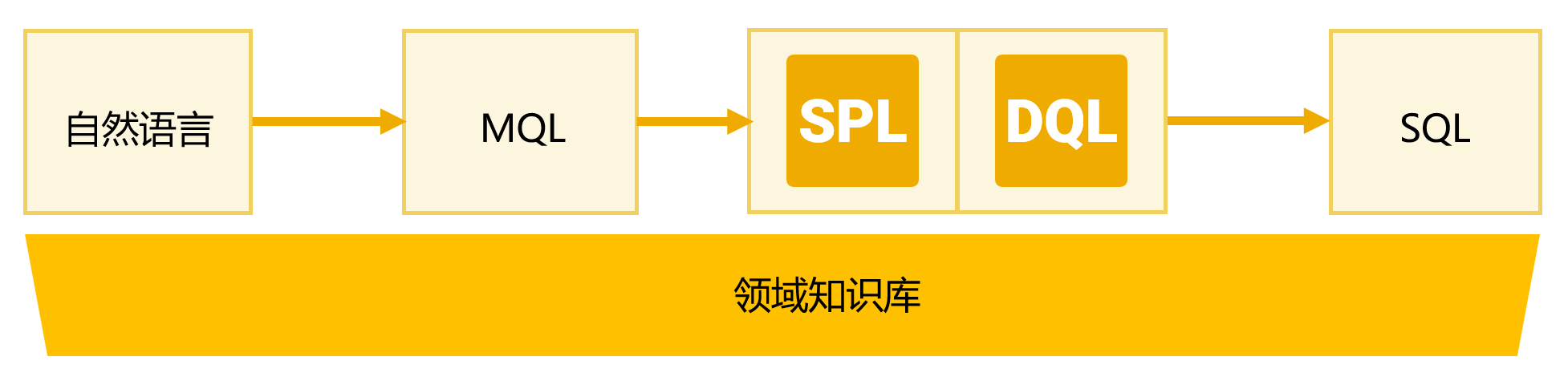
事实上,MQL 生成的执行逻辑并不完全是 SQL,它背后站着 DQL 和 SPL 两大“护法”。
DQL(Dimensional Query Language):负责把复杂的多表关联查询,在语义层简化成逻辑上的单表查询。用户问“上海的客户买了哪些北京生产的产品”,这种涉及客户表、订单表、产品表的多层关联,DQL 在背后默默搞定,让 NLQ 可以像查询单表一样轻松。
SPL(Structured Process Language):当遇到 SQL 写起来都头疼的复杂计算时,SPL 就登场了。比如计算“移动平均”、“客户留存率”、以及“月活数量”等。NLQ 可以调用封装好的 SPL 脚本进行后计算,对于 BI 场景,它能实现的查询功能,要比传统 Text2SQL 的范围更为丰富。
前面流程图中所示的“MQL->SQL”过程实际上是简化的表述。在实际执行过程中,MQL 会根据查询的复杂程度,智能地选择执行路径:简单的查询由 DQL 直接生成 SQL 到数据库执行;涉及复杂计算时,则会分解为SPL+DQL的组合,其中 DQL 负责将多表关联逻辑转换为 SQL 查询,而 SPL 则处理那些 SQL 难以表达的复杂计算逻辑。
客观吐槽:“边界”也很清晰
当然,NLQ 并非完美,它的局限性同样源于其设计:
灵活性是硬伤:它无法理解“卖得最火的几个货”这种随意的口语。它需要相对规范的语言,比如“销量前十名的产品”。它的强大建立在“词典”的完备性上,对于词典之外的“新词”和“新说法”,它是真的“无能为力”。
知识更新需要人工:NLQ 不具备举一反三的学习能力。一个新的业务指标上线,必须由管理员手动添加到词典中,它才能被查询。
“双打”或许是最佳组合
既然 LLM 长于“灵活理解”,NLQ 善于“精准执行”,那么为何不让它们组队呢?
一个非常理想的架构是:LLM 作为“智能前台”,负责与用户进行多轮、随意的口语对话,理解其核心意图,并将其“翻译”成 NLQ 所能识别的、相对规范的自然语言指令。
这里的妙处在于:让 LLM 完成从“随意文字”到“规范文字”的转换,这远比让它直接生成某种结构化的 MQL 要简单。而且,转换后的文字业务用户能看懂,而直接生成 MQL 或 SQL 则难以由不懂技术的 BI 用户确认正确性。经过确认后,再由 NLQ 这个“可靠后台”精准执行,最终得到一个既符合用户意图、又准确的结果。
这样,既享受了 LLM 的交互友好性,又保证了 NLQ 的查询准确性和低成本,可谓鱼与熊掌兼得。
当 ChatBI 的探索大多集中于大模型这一虽然广阔但充满不确性的“主航道”时,润乾 NLQ 以其独特的“规则引擎”别辟蹊径,为我们提供了另一种经过实践验证的可靠选择。它或许没有大模型那般“万能的想象力”,但在 BI 这个需要确定性、可靠性与成本控制的领域,这种专注于“解决特定问题”的另辟蹊径,无疑是一条值得重视的务实之路。

