


(已解决)substr 函数与第 n 个分隔符前 (后) 的字符串
有一个用符号 "-“分隔的字符串,想返回第 n 个分隔符”-" 之前 (后) 的字符串,如下:
应收股利-应收理财产品红利-可供出售金融资产-信托-场外-XX信托-XX信托计划
这是一个会计科目,用分隔符隔开从左到右描述的是层级关系,类似这样的还有描述行政区划关系的,比如:
XX省-XX市-XX区-XX街道-XX居委会
目前,集算器用于返回某个字符串前后的字符串最直接的函数是 substr:
=substr(字符串,分隔符) 返回分隔符右侧的字符串
=substr@l(字符串,分隔符) 返回分隔符左侧的字符串
但 substr 只能返回第一个分隔符前后的字符串。
如果要获取第 n 个分隔符前 (后) 的字符串,需要另寻他法:
1、用 split 按分隔符拆分成序列,然后用序列方法获取位置 n 前后的序列,再合并成文本。
=字符串.split(分隔符).m(:n).concat(分隔符) 返回第n个分隔符之前的字符串
=字符串.split(分隔符).m(n+1:).concat(分隔符) 返回第n个分隔符之后的字符串
2、写正则表达式,比如:
以下捕获的是第3个分隔符"-"之前的字符串,此时正则表达式中的量词要写成n-1:
=字符串.regex($[^((?:[^-]*-){2}[^-]*)(?=-|$)])
以下捕获的是第3个分隔符"-"之后的字符串,此时量词正常写:
=?.regex($[^(?:[^-]*-){3}(.*)$])
以上两种方法都可以用但不够直接。
市面上也有直接支持获取第 n 个分隔符前后字符串的方法,比如,
1、数据库 MySQL 有操作文本的函数 SUBSTRING_INDEX(s, delimiter, number)
返回从字符串 s 的第 number 个出现的 delimiter 之后的子串。如果 number 是正数,返回第 number 个字符左边的字符串。如果 number 是负数,返回第 (number 的绝对值(从右边数)) 个字符右边的字符串。
2、EXCEL/WPS 的 TEXTBEFORE 和 TEXTAFTER 函数也支持第 n 个分隔符。

3、Power Query 有 Text.BeforeDelimiter、Text.AfterDelimiter、Text.BetweenDelimiters 也支持第 n 个分隔符。
具体到实战,除了经常碰到的会计科目层级,昨天还碰到一个按层级拼接行政区划的,如下:
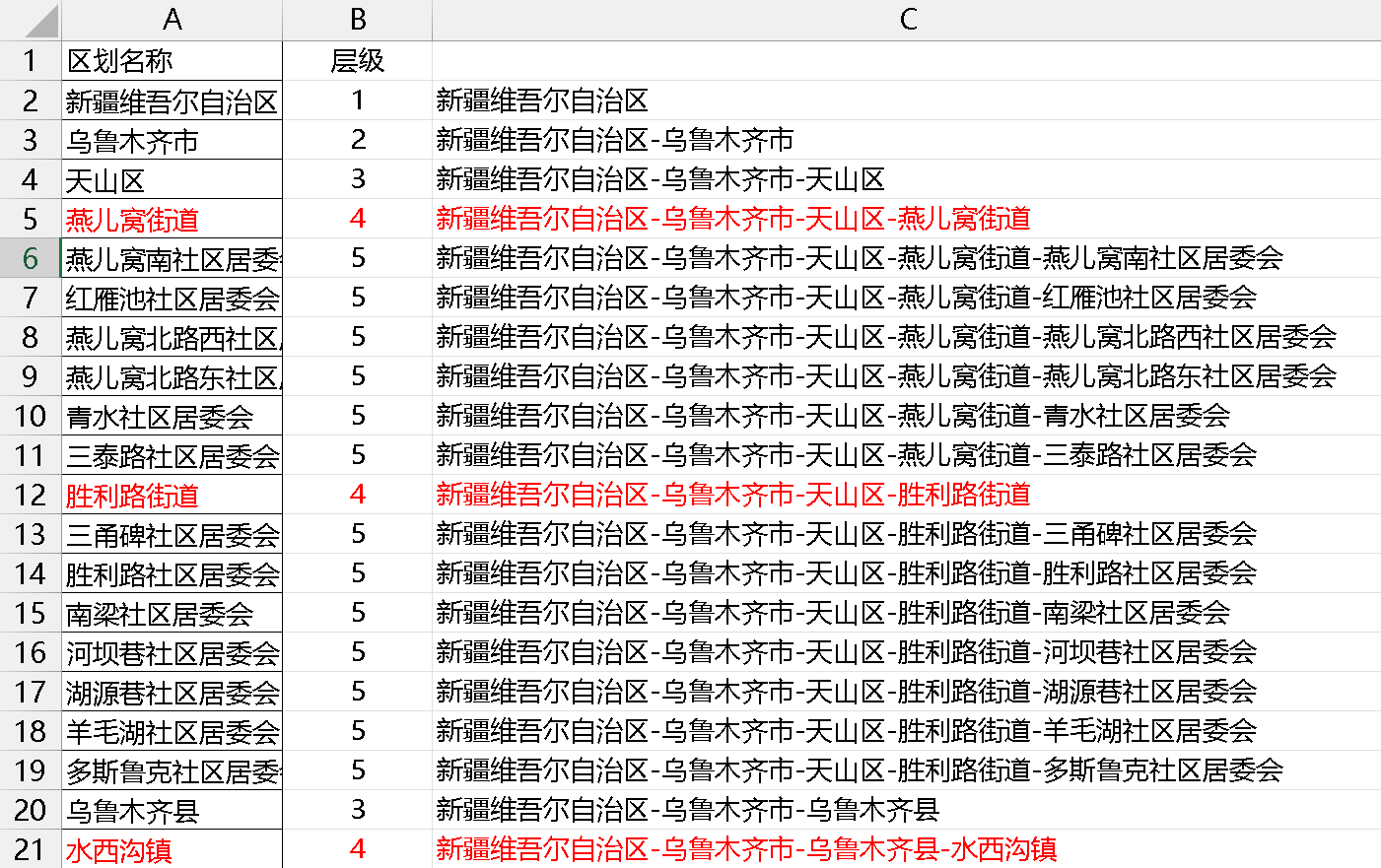
需要根据 B 列所示的层级号,把 A 列中的值拼接成 C 列所示的样子,按层级顺序显示。
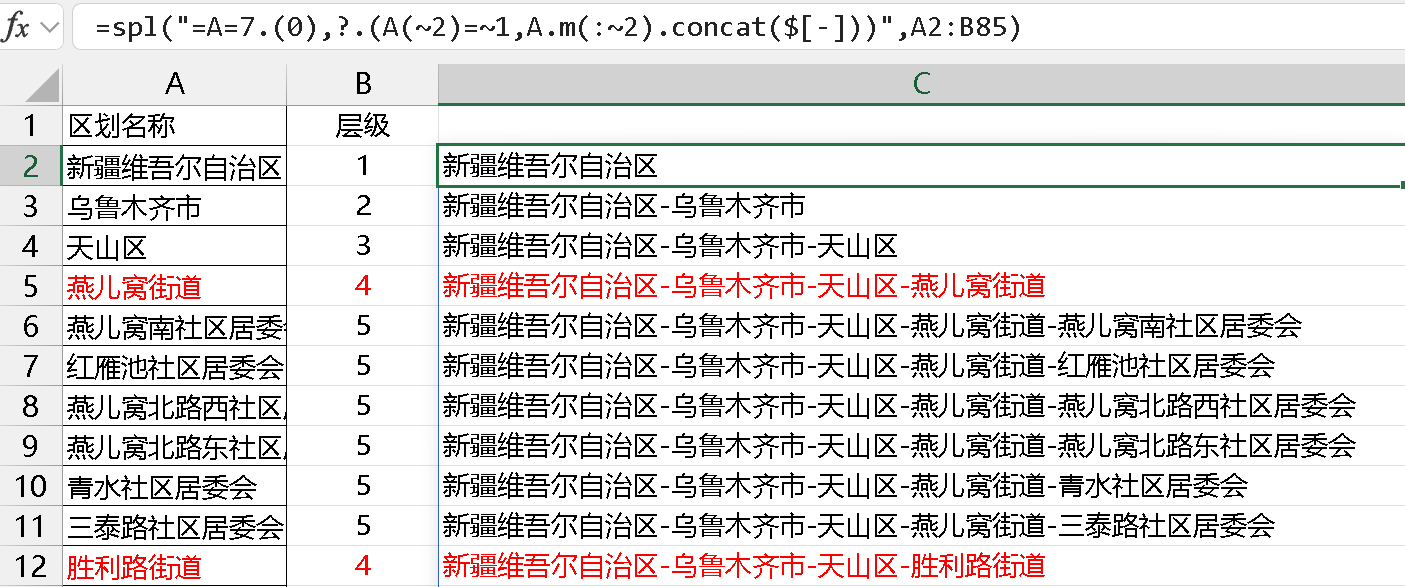
要解决这个问题,集算器有简洁高效的写法,也用不上拆分子串,如下,维护一个全局变量序列 A 用于描述层级,然后根据层级号赋值切片就行。
或者用 iterate@a 始终对生成的上一个结果进行操作:
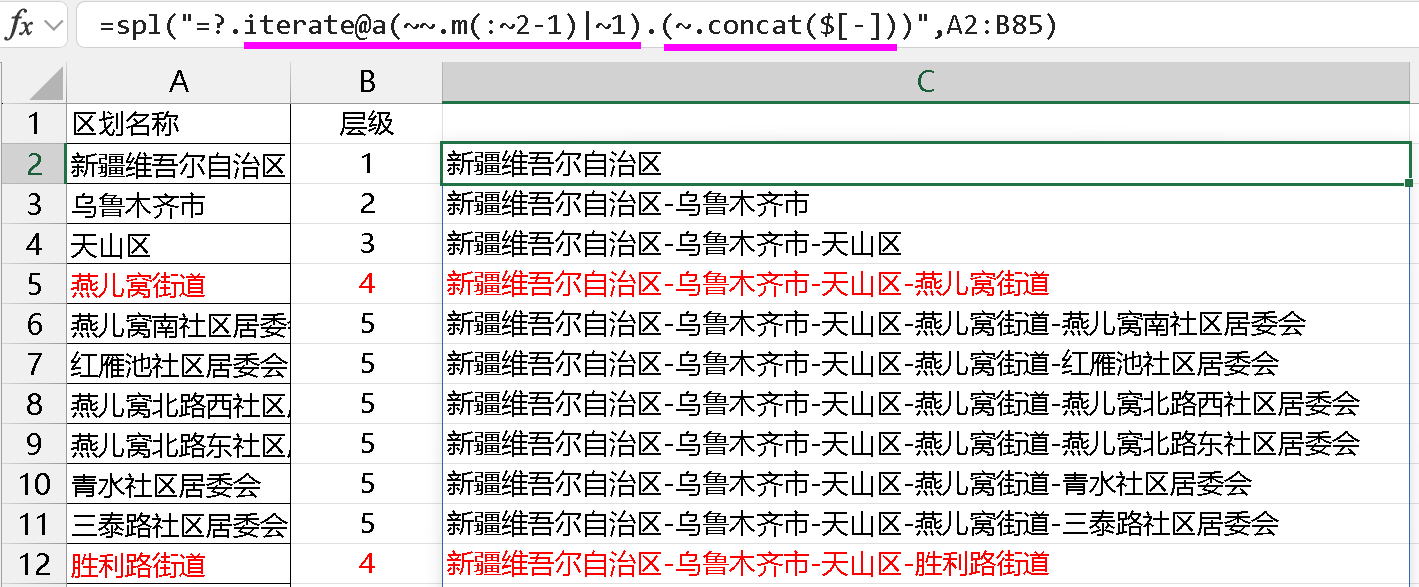
可以看到,在 iterate 的过程中操作的也是序列,完事后再循环用 concat。如果此时 iterate 操作的对象是文本,且能支持第 n 个分隔符的获取,那 iterate 就能直接出结果了,以下是伪代码:
=spl("=?.iterate@a(substr(~~,$[-],~2-1)/$[-]/~1)",A2:B85)
所以,我想着咱集算器函数 substr 可不可以支持一下这个参数功能😄 比如:
=substr(s,d,n) 返回第n个d之后的字符串
=substr@l(s,d,n) 返回第n个d之前的字符串
n支持整数,负数表示倒着数,没有字符串可返回时默认为空。
恳请大佬们得闲时看看,万分感谢🙏 😄


非常感谢提供宝贵的建议!
为 substr 增加了 n 参数和 @z 选项,n 从 1 开始计数,z 表示从后往前找,代码已上传 git,更新 jar 包后就可以用了
谢谢老贼,谢谢大佬,给你们添乱添麻烦了🙏
快下班回家吧…周末愉快😄 🙏
问题已解决,请到集算器 (SPL) 最新版发布啦『发布日期 20250801』,下载最新的 esproc-bin.jar 并使用
谢谢,相当好用👍 👍
大佬,关于 substr 新增的 n 参数,我还有一点想法,当 n 越界时的处理,也就是当 n=-1(0-based indexing)、n=0 和 n> 分隔符数量时的情形。
当前的设计毫无疑问是正确的,方法应该对无效参数立即抛出异常,不返回可能被误解的值,这是程序可靠的表现。
出于易用性考虑,我想着能否支持更宽松的容错策略,把整个字符串的开始和结尾默认为是任何分隔符,相当于正则中的零宽位置 ^ 和 $。
我觉得这样的容错策略在处理格式不完全规范的数据时是有用的,可以避免冗长繁杂的 if 判断和错误处理。
当 n=-1、n=0、n> 分隔符数量、或者找不到分隔符时,把整个字符串的开始位置和结尾位置当成分隔符来处理,比如:
以上想法恳请大佬得闲时看看🙏
越界的倒是可以当做结尾或开头来处理,参数值等于 0 就没什么实际意义了
字符串函数里有好几个函数有类似的情况,等空闲时再统一一下
好,这个不着急,大佬先忙正事🙏
参数是 0 和 -1 时别报错就行,而 -2,-3 可以让他报错。😂
为什么呢,因为有些层级号是从 0 开始的,把 0 设计成了顶级,而有些是从 1 开始的,认为 1 是顶级。
当在处理当前层级的上一级时,0-1=-1,1-1=0,所以想着当 n=0,n=-1 时可以放宽一些容错策略,会易用一些。
一个是实战中确实有这些情况存在,不容错时会写多几个 if 判断,冗长;
二个是市面上有些应用确实有这样的容错处理,比如 Excel 的公式会有 matchend 选项,此时认为首尾零宽位置也是分隔符,当不选 matchend 时,无效参数会抛出错误,而 power query 中类似的处理,会把位置 -1 认为是有效位置(PQ 是 0-based indexing),其余的 -n 就抛出错误了。
恳请大佬得空时再看看,哈哈😄 🙏