


AI 提效报表困难SQL开发?不好说,但SPL肯定可以
报表开发离不开 SQL。简单 SQL 更多,但通常只需片刻即可完成;真正耗时的,是那些逻辑繁琐、步骤繁多的 SQL,数量虽相对少,却往往成为报表开发中效率最低的瓶颈,让报表开发人员倍感吃力。
令人欣慰的是,近几年出现了多才多艺的 AI 大模型——能画图、能作曲,当然也能写 SQL。或许,AI 能为报表开发中最费时的环节,换上一台时代的发动机。
然而,现实有时挺骨感。
AI对复杂 SQL 无能为力
AI 大模型是模仿逻辑,简单 SQL 问题当然容易模仿,一旦遇上逻辑繁琐、步骤繁多的复杂 SQL 就容易出错,解题能力显著下降。
stackoverflow.com 上 SQL 问题数量的变化也佐证了上述观点:ChatGPT 3 发布后,简单 SQL 的问题数量立即锐减了 90%,但复杂 SQL 问题减少却不明显,占比反而还增大了。
分析一个具体例子更容易看清:根据账户的变更历史和当前状态生成连续记录(链接)。这题的难点是生成连续的日期区间,把每个账户展开到每天,补上缺失的状态。ChatGPT 5 给出的 SQL 如下:
(太长了,懒得看可以直接翻过去,下面还有类似情况,都可以跳过)
WITH RECURSIVE date_series AS (
SELECT DATE('2024-03-01') AS dt
UNION ALL
SELECT DATE_ADD(dt, INTERVAL 1 DAY)
FROM date_series
WHERE dt < '2024-03-15'
),
status_union AS (
SELECT
o.user_id,
o.organisation_id,
o.status_id,
o.stopped_reason_id,
o.dossier_created AS ts
FROM organisation_user_link o
UNION ALL
SELECT
h.user_id,
h.organisation_id,
h.status_id,
h.stopped_reason_id,
h.timestamp
FROM organisation_user_link_status_history h
),
status_ranked AS (
SELECT
d.dt,
o.user_id,
o.organisation_id,
o.dossier_created,
su.status_id,
su.stopped_reason_id,
ROW_NUMBER() OVER (
PARTITION BY d.dt, o.user_id, o.organisation_id
ORDER BY su.ts DESC
) AS rn
FROM date_series d
JOIN organisation_user_link o
ON d.dt >= DATE(o.dossier_created)
JOIN status_union su
ON su.user_id = o.user_id
AND su.organisation_id = o.organisation_id
AND su.ts <= d.dt + INTERVAL 1 DAY - INTERVAL 1 SECOND
)
SELECT
sr.dt AS date,
sr.user_id,
sr.organisation_id,
sr.status_id,
sr.stopped_reason_id,
sr.dossier_created
FROM status_ranked sr
WHERE sr.rn = 1
ORDER BY sr.dt DESC, sr.user_id ASC;
这句 SQL 漏洞百出,补上缺失的状态这部分几乎全错,因为这部分业务逻辑太复杂,尤其是把今天到最近的变更日期补成今天的,把最近的变更日期到次近的变更日期也补成最近的。
再看一例:多字段混合去重后编号(链接)。这里的难点在于传递记录之间的关系,通常要用递归或遍历来实现无向图。DeepSeek R1 给出的 SQL 如下:
WITH RecursiveCTE AS (
SELECT
RegisterId,
Name,
Phone,
Email,
RegisterId AS RootId
FROM Registers
UNION ALL
SELECT
r.RegisterId,
r.Name,
r.Phone,
r.Email,
rc.RootId
FROM Registers r
INNER JOIN RecursiveCTE rc
ON (
(r.Name IS NOT NULL AND r.Name = rc.Name) OR
(r.Phone IS NOT NULL AND r.Phone = rc.Phone) OR
(r.Email IS NOT NULL AND r.Email = rc.Email)
)
WHERE r.RegisterId <> rc.RegisterId
AND rc.RootId < r.RegisterId
),
GroupRoots AS (
SELECT
RegisterId,
MIN(RootId) AS GroupRootId
FROM RecursiveCTE
GROUP BY RegisterId
),
RankedGroups AS (
SELECT
GroupRootId,
DENSE_RANK() OVER (ORDER BY GroupRootId) AS no
FROM (SELECT DISTINCT GroupRootId FROM GroupRoots) AS DistinctRoots
)
SELECT
r.RegisterId,
r.Name,
r.Phone,
r.Email,
rg.no
FROM Registers r
INNER JOIN GroupRoots gr ON r.RegisterId = gr.RegisterId
INNER JOIN RankedGroups rg ON gr.GroupRootId = rg.GroupRootId
ORDER BY rg.no, r.RegisterId;
大模型的确使用了递归语法,但因为业务逻辑复杂,只能胡乱套用语法,与实际的题意根本对应不上,结果自然也不对。
复杂 SQL 之所以难写,根源在于 SQL 本身。SQL 是一种声明式语言,擅长描述“要得到什么”,却不擅长表达“如何一步步得到”。它缺乏过程性,不支持像传统编程语言那样的多步骤计算、循环与分支结构。当一个计算逻辑需要分阶段处理、逐步聚合或依赖中间结果时,开发者往往无法直接用顺序逻辑来描述,只能借助嵌套子查询、窗口函数、复杂的多表关联等手段,曲折地实现这些过程,导致代码晦涩难懂结构复杂,极易产生逻辑错误,经验丰富的数据库程序员也要费一些功夫,依靠概率作答的大模型无力应对,胡言语也就不奇怪了。
那难度低一些的 SQL 呢?
AI对新问题的表现不佳
用 stackoverflow 上的 SQL 问题对 AI 提问,会发现一个似乎是意料之外的现象:对于有一定年头的旧题通常能给出较满意的答复,但对新出现的问题往往会乱答一气,问题越新,答案就越乱,很多问题难度并不高,AI 给出的答案也不对。
其实这个现象在情理之中:用旧题提问时,虽然要素变化多端,但 AI 已经用相关的题目训练过,获得正确答案的概率要大得多。有些旧题有多个回答者,有比较明确的正确答案,有答者和提问者的多次沟通和澄清,问题的描述也经过多次细化和纠偏,经过这些知识的训练,AI 对历史问题的答案经常令人较为满意。
但新问题的情况就不同了。因为大模型并不会真正地思考,只是模仿,就难以正确回答没训练过的新问题。只能降低匹配概率,用其实无关的旧知识来编造答案,也就是幻觉,即使难度低,回答的结果也不尽人意。比如下面两个 stackoverflow 上的问题。
找出各组字符串中大写字母较多或更靠前的一条(链接)
按到店和离店日期将一条住宿记录扩展成多条(链接)
这两个问题的难度比前面的例子已经明显降低,但因为比较新(距离写文章的日期较近),ChatGPT 5 和 DeepSeek R1 都无法正确回答,甚至连番报错。
程序员确认成本很高
概率机制决定了 AI 总会有幻觉,成功率既使很高,但也不是百分之百,总归还是需要程序员来确认,而这个过程也非常痛苦。
比如这么个问题,计算每支股票最长的连续上涨天数,ChatGPT 5 给出的 SQL 如下:
WITH diff AS (
SELECT CODE,DT,CL,
CASE WHEN CL > LAG(CL) OVER (PARTITION BY CODE ORDER BY DT)
THEN 0 ELSE 1 END AS grp_break
FROM stock
),
grp AS (
SELECT CODE, DT, CL,
SUM(grp_break) OVER (PARTITION BY CODE ORDER BY DT
ROWS UNBOUNDED PRECEDING) AS grp_id
FROM diff
),
calc AS (
SELECT CODE, grp_id, COUNT(*) AS streak_len
FROM grp
WHERE grp_id IS NOT NULL
GROUP BY CODE, grp_id
)
SELECT CODE, MAX(streak_len) AS LONGEST_UP_DAYS
FROM calc
GROUP BY CODE
ORDER BY CODE;
看着晕吧,它确实是对的!但要是不读懂它,也没办法确认它的正确性。
再比如,求每 7 天中连续 3 天活跃的用户数:
WITH all_dates AS (
SELECT DISTINCT TRUNC(ts) AS login_date
FROM login_data),
user_login_counts AS (
SELECT userid, TRUNC(ts) AS login_date,
(CASE WHEN COUNT(*)>=1 THEN 1 ELSE 0 END) AS login_count
FROM login_data
GROUP BY userid, TRUNC(ts)),
whether_login AS (
SELECT u.userid, ad.login_date, NVL(ulc.login_count, 0) AS login_count
FROM all_dates ad
CROSS JOIN (
SELECT DISTINCT userid
FROM login_data) u
LEFT JOIN user_login_counts ulc
ON u.userid = ulc.userid
AND ad.login_date = ulc.login_date
ORDER BY u.userid, ad.login_date),
whether_login_rn AS (
SELECT userid,login_date,login_count,ROWNUM AS rn
FROM whether_login),
whether_eq AS(
SELECT userid,login_date,login_count,rn,
(CASE WHEN LAG(login_count,1) OVER (ORDER BY rn)= login_count
AND login_count =1 AND LAG(userid,1) OVER (ORDER BY rn)=userid
THEN 0
ELSE 1
END) AS wether_e
FROM whether_login_rn),
numbered_sequence AS (
SELECT userid,login_date,login_count,rn, wether_e,
SUM(wether_e) OVER (ORDER BY rn) AS lab
FROM whether_eq),
consecutive_logins_num AS (
SELECT userid,login_date,login_count,rn, wether_e,lab,
(SELECT (CASE WHEN max(COUNT(*))<3 THEN 0 ELSE 1 END)
FROM numbered_sequence b
WHERE b.rn BETWEEN a.rn - 6 AND a.rn
AND b.userid=a.userid
GROUP BY b. lab) AS cnt
FROM numbered_sequence a)
SELECT login_date,SUM(cnt) AS cont3_num
FROM consecutive_logins_num
WHERE login_date>=(SELECT MIN(login_date) FROM all_dates)+6
GROUP BY login_date
ORDER BY login_date;
这句更晕更长的 SQL 也没有错,它用了多个嵌套子查询,解读确认的成本更高。
SQL 难以解读,还是 SQL 本身的原因,不符合自然思维,缺乏过程性,通常要用多层的嵌套结构,需要积累多年的 "秘密小技巧",编码思路与现代编程语言格格不入,也比现代编程语言更难解读。很多程序员有这样的感受:读懂别人的 SQL,经常比自己写一遍要更花时间,复杂的 SQL 更是难如天书。
还有其它兼容性问题
AI 写 SQL,程序员解读,这里的核心可以是 AI,但遇到代码兼容性问题时,核心也必须是程序员。
AI 的解题能力强烈依赖训练素材的丰富程度,对 Oracle、SQL Server、MySQL 等常见的数据库,更容易写出正确的 SQL,一旦遇上 Kingbase、Tibero 等不太常见的数据库,就很难正确解题了。即使 Mysql 这种常见的数据库,如果遇到 5.1 这种老版本,或 SQL Server 的 2005 版,AI 也往往“以为自己懂”,生成的 SQL 实际却跑不通,也必须由程序员再去改造甚至重写。
这是因为 SQL 存在千奇百怪的方言,不同种类的数据库 SQL 不统一,同一种数据库因为版本不同,SQL 也不通用。不难设想,如果要改变数据库种类或版本,SQL 和 AI 都会很难受。
看来,报表中的复杂 SQL 也不能全指望 AI 了,那还能咋办?
转向 SPL 是个可行的选择
SPL 是专业的结构化数据计算语言,可以实现报表中的各类计算难题,无论新题旧题,这一点与 SQL 相似。与 SQL 的不同之处在于,SPL 是过程性语言,直接支持多步骤计算、循环与分支结构,擅长表达复杂的业务逻辑。SPL 符合自然的思维习惯,提供了多种方便易用的语法,内置大量功能强大的函数,可以简化复杂的有序运算、集合运算、分布计算、关联计算,可以直观快速地编写代码解读代码,编写 SPL 经常比解读 SQL 都快。
前面提到过的难以解读的 SQL,如果用符合自然思维的 SPL 编写,就简单直观多了。比如,计算每支股票最长连涨天数:
A |
|
1 |
…//加载数据并按日期排序 |
3 |
=A1.group(CODE;~.group@i(CL<CL[-1]).max(~.len()):maxDays) |
再比如:求每 7 天中连续 3 天活跃的用户数。
A |
|
1 |
…//加载数据 |
2 |
=periods(date(A1.ts),date(A1.m(-1).ts)) |
3 |
=A1.group(userid).(~.align(A2,date(ts)).(if(#<7,null,(cnt=~[-6:0].group@i(!~).max(count(~)),if(cnt>=3,1,0))))) |
4 |
=msum(A3).~.new(A2(#):dt,int(~):cont3_num).to(7,) |
这些代码都很短,本来也就是按自然思维写出来的,掌握SPL语法的程序员也很容易确认其正确性。
开头提到的 AI 无法解决的 SQL 难题,改用 SPL 也会容易很多。
根据账户的变更历史和当前状态生成连续记录。
SQL 要用递归子查询造出日期序列,结构复杂,使用多层嵌套查询和窗口函数在状态变更时打标记,再用 join 语句填充空白日期的数据,不符合自然思维习惯,代码很繁琐。
SPL 对账户分组后可以不汇总,而是对分组子集继续计算,而且 SPL 提供了生成日期序列的函数、按日期序列生成记录的函数,简单易用,符合自然思维习惯。
A |
|
1 |
=db.query("select date('2024-03-14') as date,user_id,organisation_id,status_id,stopped_reason_id,dossier_created from organisation_user_link") |
2 |
=db.query("select timestamp as date,user_id,organisation_id,status_id,stopped_reason_id,null as dossier_created from organisation_user_link_status_history order by date desc") |
3 |
=(A1|A2).group(user_id) |
4 |
=A3.conj(~.news(periods@x(~.date,ifn(~[1].date,date("2024-02-29")),-1);date(~):date,user_id,organisation_id,status_id,stopped_reason_id,A3.dossier_created)) |
5 |
=A4.sort(-date,user_id) |
先加载数据。当前状态表追加了 data 字段,值为今天的日期。历史状态表追加了账户创建日期,值为空。然后合并当前状态和历史状态,按账户分组但不汇总。最后按自然思维处理每组数据,生成连续的日期区间,把每个账户展开到每天,补上缺失的状态。
多字段混合去重后编号
这道题是比较典型的“传递闭包 + 分组” 需求,某两条记录如果通过 Name / Phone / Email 任意字段能关联上,就要认定为同一个人;而且这种关联是传递的(A= B,B= C,则 A= C)。在 SQL Server 中没有直接的“传递闭包”语法,要换个思路,用递归 CTE 或者借助 UNION + 递归查询来实现,实现过程不符合自然思维习惯,代码很难写。
SPL 简单很多。
A |
|
1 |
=mssql.query("select * from tb") |
2 |
=T=A1.derive(#:no) |
3 |
for T.count(T[1:].count( if(no!=T.no && ( (Name && T.Name && Name==T.Name) || (Phone && T.Phone && Phone==T.Phone) || (Email && T.Email && Email==T.Email)), T.no=no=min(no,T.no) ))>0)>0 |
4 |
return T |
先新增编号列 no,再用死循环遍历记录,按约定规则调整 no 列,如果某次遍历后有 no 被调整的情况,则重新遍历,直到所有 no 都不再调整为止。
如今,简易的 SPL 已经内置于润乾报表,充当报表的数据准备层。从数据源获取原始数据,计算成目标数据,再输出给报表呈现。
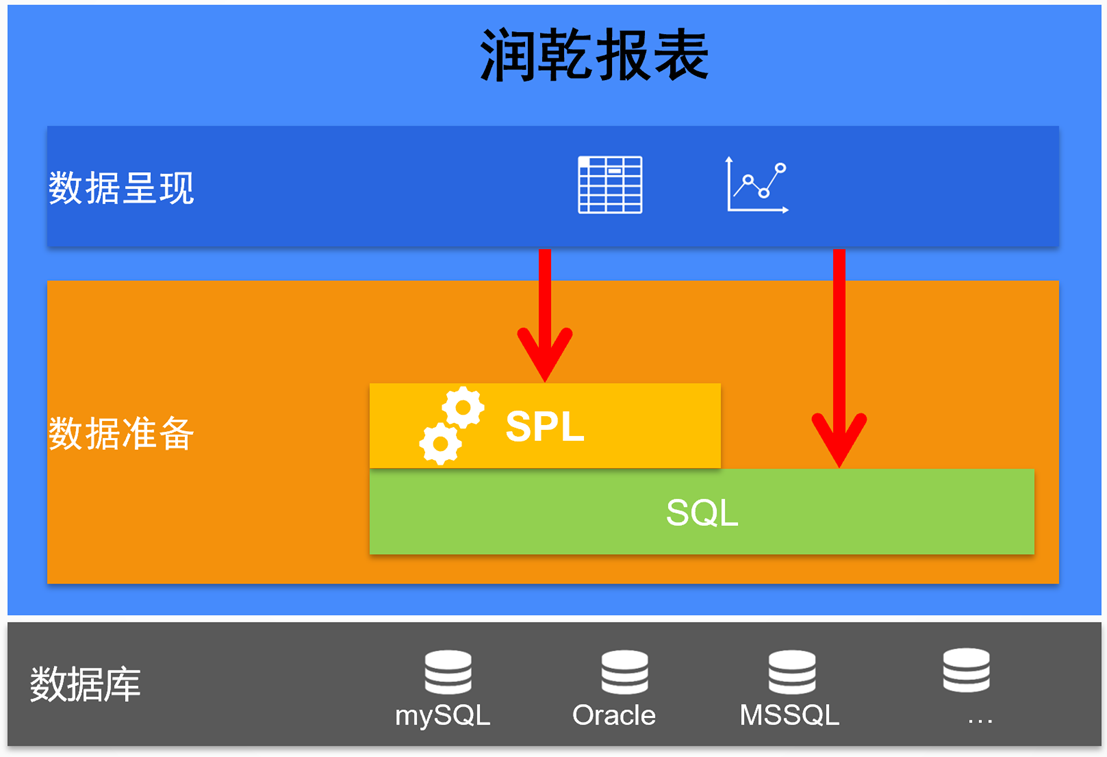
润乾报表同时提供 SPL 和 SQL 两种取数机制,SPL 也支持执行 SQL 取数,这两者并不矛盾。简单计算任务可以继续使用 SQL,也包括用 AI 生成的 SQL。对于难题以及新题,更有效的做法是用简单的 SQL 取数,再用 SPL 实现业务逻辑。在 SPL 和 AI 的配合之下,可以彻底解决报表的中的各类 SQL 难题。
SPL 还有代码独立于数据、不依赖具体数据库的优点,可以解决数据库类型切换、跨库计算、多源混算等场景。在没有数据库的场景下,SPL 也可以直接计算 csv/xls 文件或 RESTful、WebService。
SPL 更简单,更符合自然思维,更易写也易懂,但作为一门新编程语言还是有些学习门槛,这时候也可以利用 AI 来跨过门槛。比如计算每支股票最长的连续上涨天数,DeepSeek R1 给出的 SPL 代码大概如下:
A |
|
1 |
…//加载数据并按日期排序 |
2 |
=A1.group(CODE) |
3 |
=A3.new(CODE, ~.group@i(CL<CL[-1]).max(~.len())-1:LONGEST_UP_DAYS) |
4 |
=A4.select(LONGEST_UP_DAYS>0).sort(CODE) |
这个代码还有精简的余地,但大体是正确的,程序员可以据此快速熟悉 SPL 语法。
当然,和 SQL 一样,更深入更复杂的问题,AI 给出的 SPL 代码就不一定对了,这时候还有 SPL 的官方论坛乾学院(c.raqsoft.com.cn)了,资料非常丰富,响应速度也很快。这样几招下来,SPL 的使用门槛就低得多了。

