


求助: 读取 parquet 文件的问题
集算器外部库 HdfsFileCli、HiveCli 可以读取本地或 hdfs 中 parquet 格式的数据,函数语法如下:

我发现了一些问题,当然也有可能是我操作不对,以下只对本地文件作了测试,恳请大佬们有空的时候看看。
1、当前的文件对象 f 能否支持远程 URL 文件的读取,也就是 httpfile().parquet()。
目前,集算器的 httpfile() 对常见的 csv、xlsx、json 都是支持的,如下所示,都能正常返回结果,可以复制到 IDE 运行,因为网络和服务器的关系,可能要稍微等一下才会出结果:
1、读取远程csv文件
=httpfile("https://csvbase.com/jeffcostr/airbnb.csv").import@tc()
2、读取远程xlsx文件
=httpfile("https://csvbase.com/jeffcostr/airbnb.xlsx").xlsimport@t()
3、读取远程jsonl文件,注意是jsonl,不是json,json可以用对应的json方法
=httpfile("https://csvbase.com/jeffcostr/airbnb.jsonl").read().import@w().conj()
=httpfile("https://csvbase.com/jeffcostr/airbnb.json").read()
所以,想着是否能实现对远程 parquet 的支持, 以下网址上的 parquet 文件是真实存在的:
=httpfile("https://csvbase.com/jeffcostr/airbnb.parquet").parquet()
2、对函数参数中的 filter 有些疑问,filter 谓词的书写受限很多。
疑问 1:这个 filter 是不是谓词下推,可以减少 IO 吗?使用该 filter 参数时,第一参数中的列筛选要么空着,默认选出所有列。如果要选出某些列,那 filter 里涉及到的列是否必须要包含在选出的列中?
我试了一下,如果选出的列里没有 filter 涉及的列,filter 会失效。比如,
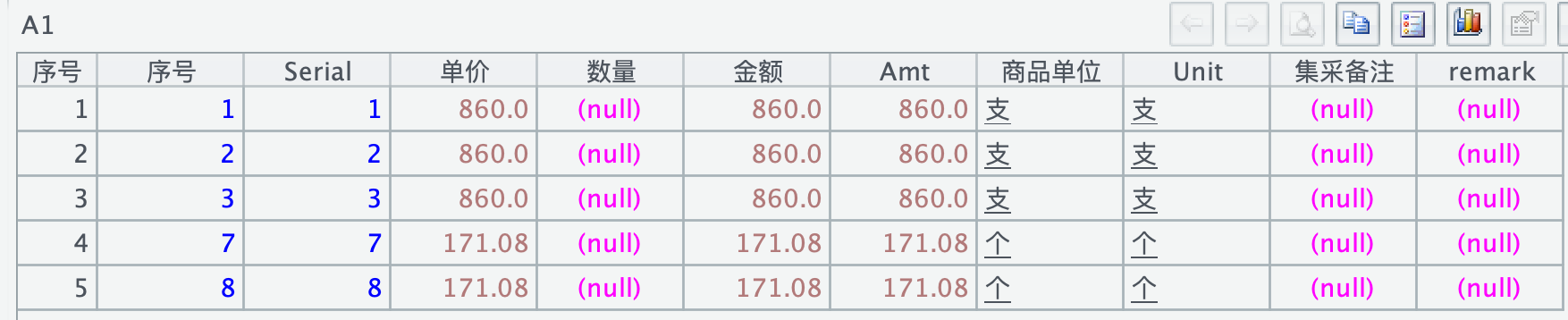
=file("/Applications/DbVisualizer.app/测试.parquet").parquet(;"Amt>=870";)
该语句是选出 Amt 列 >=870 的所有列,结果如下,返回 3 行:

但实际上不需要那么多列,比如,只要返回 Amt>=870 的序号列,此时 1 参的列只写 "序号",filter 谓词就失效了,返回了全部的序号。
=file("/Applications/DbVisualizer.app/测试.parquet").parquet("序号";"Amt>=870";)
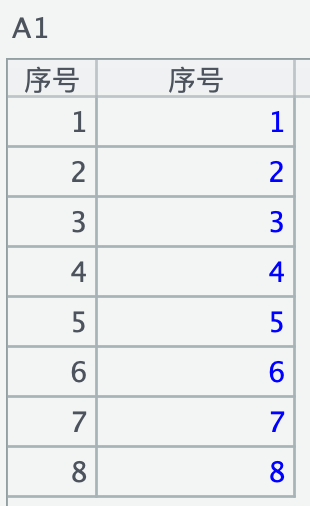
一参中的列投影必须包含 filter 谓词里的所有列,才能返回预期结果:
=file("/Applications/DbVisualizer.app/测试.parquet").parquet("序号","Amt";"Amt>=870";)
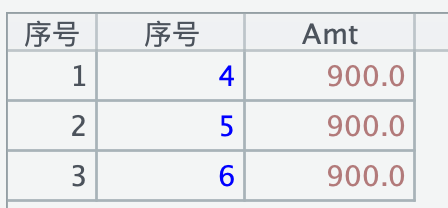
这个跟 SQL 里有点不一样,select 序号 from ‘测试.parquet’ where Amt>=870 这样是没问题的。
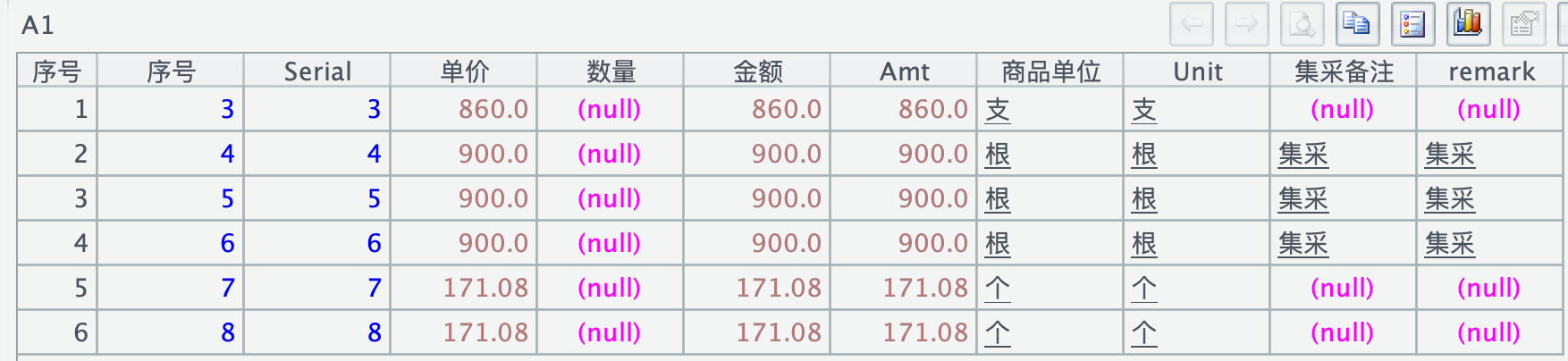
疑问 2:在使用 filter 时,filter 谓词不支持中文吗?中文字段名不能用于比较运算符 >=、<=,如下所示,筛选出序号字段 >=3 的记录,谓词失效了,返回了所有行:
=file("/Applications/DbVisualizer.app/测试.parquet").parquet(;"序号>=3";)
如果把 "序号" 换成英文字段 "Serial",结果符合预期:
=file("/Applications/DbVisualizer.app/测试.parquet").parquet(;"Serial>=3";)
应该是中文字段名支持不是很友好,虽然不能用于比较运算,但中文名字段支持 like 和 in:
=file("/Applications/DbVisualizer.app/测试.parquet").parquet(;"商品单位 like '个' ";)

用 in 时,支持类似元组的写法 "in (a,b,c)" 和 序列的写法 “in [a,b,c]”,都能返回预期结果。
=file("/Applications/DbVisualizer.app/测试.parquet").parquet(;"商品单位 in ( '个' ,'支') ";)
=file("/Applications/DbVisualizer.app/测试.parquet").parquet(;"商品单位 in [ '个' ,'支' ] ";)
疑问 3:说到 like 和 in,是不是不能直接与 >=, < 等比较运算符在同一个谓词下推条件中组合使用?
比如,写成 "字段 1 like xxx and 字段 2>=yyy",谓词下推就会失效,以下语不会报错,但返回空白,实际上是有符合条件的记录的:
=file("/Applications/DbVisualizer.app/测试.parquet").parquet(;"商品单位 like '支' and Serial>=2";)
而,in 和比较运算符的组合,返回的结果不是那么一回事:
=file("/Applications/DbVisualizer.app/测试.parquet").parquet(;"Unit in ('支','个') and Serial>2";)

疑问 4:读取 parquet 时,虽然能用相对地址,但使用了相对地址后,filter 谓词就会失效,必须写全路径,才能使用 filter。
这个 filter 真不好用,限制那么多,折腾了整整两天。
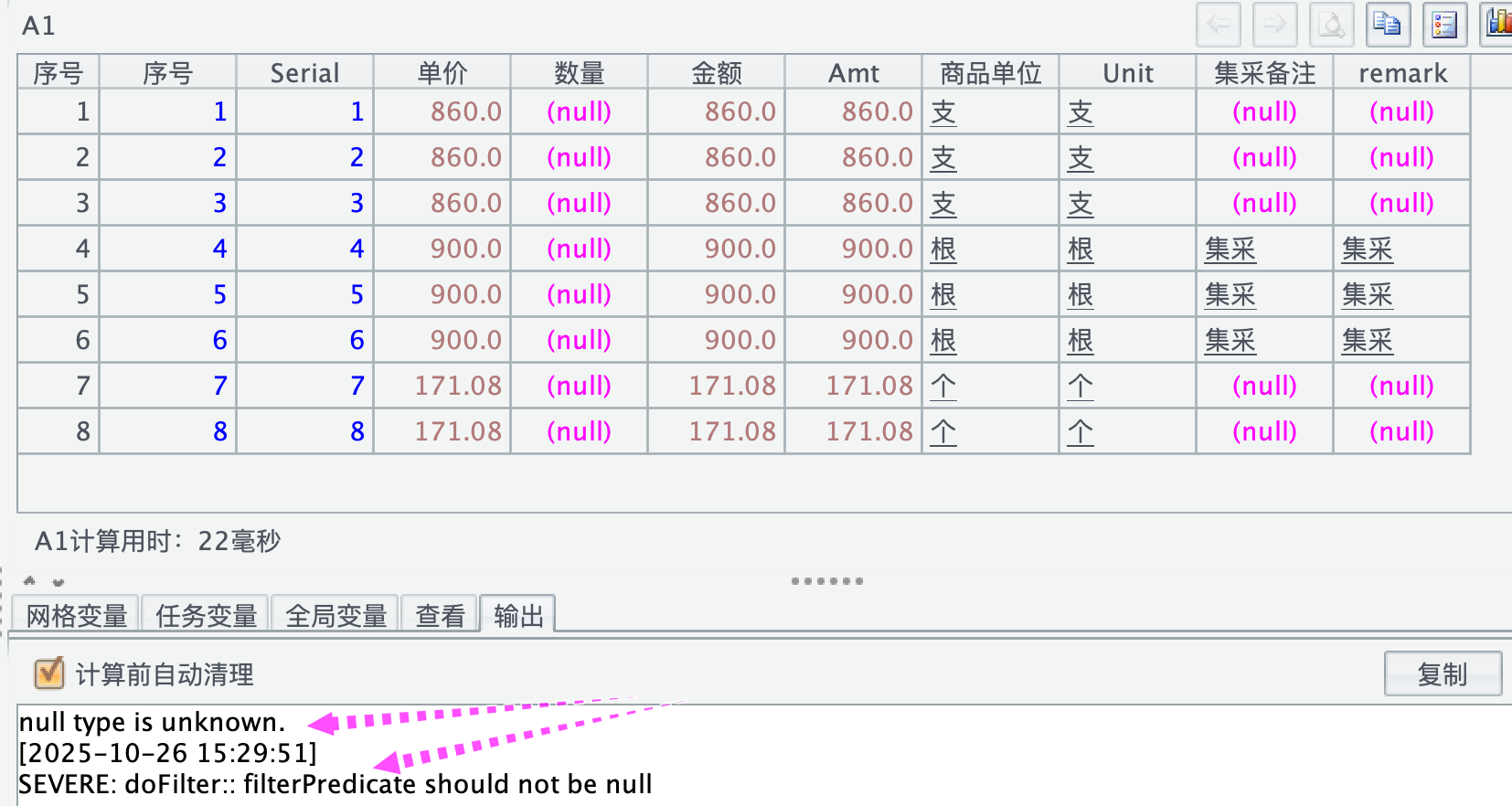
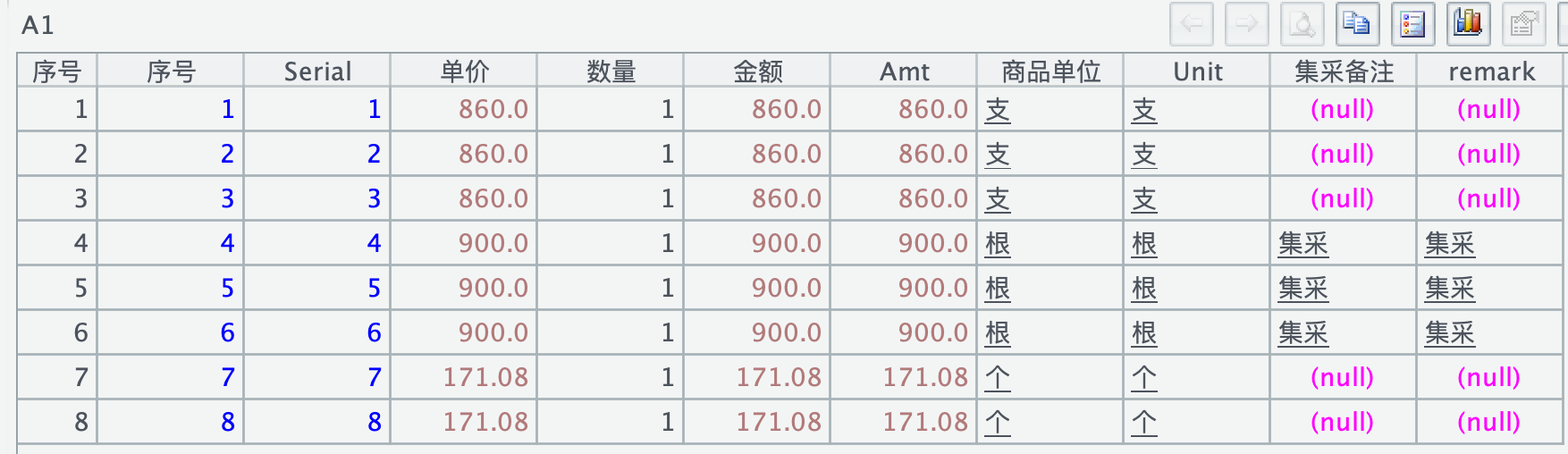
3、parquet 读数时数据类型的问题,上述举例中数量列都是 null,实际上是有数值的,但用 parquet 没显示出来,加上 @v 选项,数量列就显示有值了。我看了一下,这个数量列在其他程序中显示的 BIGINT,所以会不会是集算器不能识别 BIGINT,然后就显示 null 了,但加了 @v 又能显示出来,说明能读出来。
=file("/Applications/DbVisualizer.app/测试.parquet").parquet@v()
另外,集采备注和 remark 这两列本来就是有 null 值的,当用 parquet() 读取时,会输出对 null 值描述的信息,有几个 null 值,就会输出几条信息,输出的信息如下。这个信息要完全输出完后才会运行完毕,会严重影响读取效率。

还有一个,parquet 文件会有一些深度嵌套的列,比如以下情况,提示信息也是类型问题:
=file("/Applications/DbVisualizer.app/nested3.parquet").parquet()
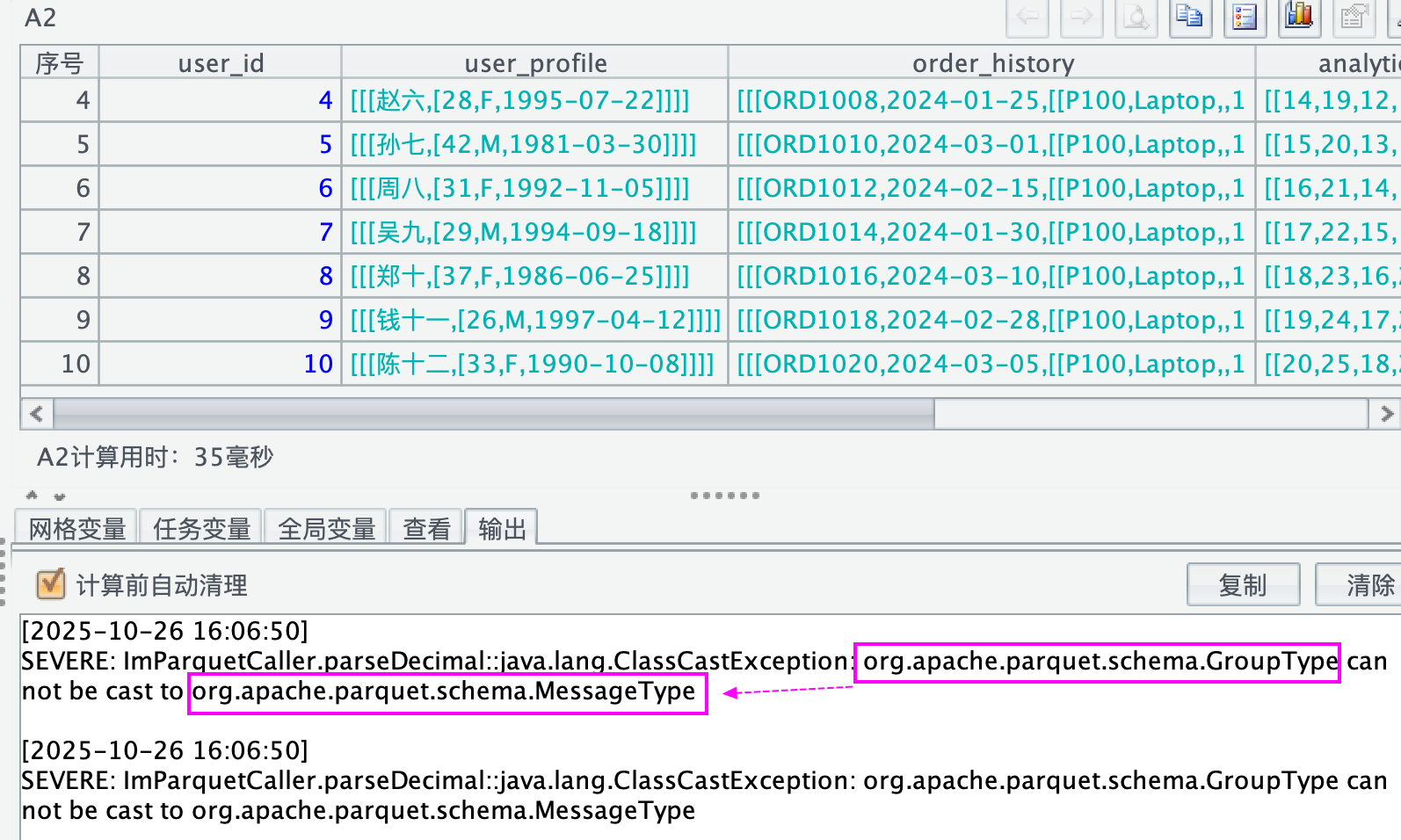
如果不借助外部库 parquet,集算器对这种深度嵌套的 STRUCT 结构会提示 "Unrecognized data type in SPL"。
4、当前外部库对 parquet 的读取是不是只支持 snappy,gzip 和 uncompressed 这 3 种压缩形式的文件,对 lz4、zstd 和 brotli 这 3 种压缩形式是不支持读取的?
5、能写出 parquet 格式吗?这个好像有点多问了😂 ,没有 btx、ctx 好用。个人感觉 parquet 格式很复杂,外国佬到处吹 parquet 格式,据说 wps 也在考虑用 parquet,小道消息不确切。
以上问题,恳请大佬们得闲时看看,特别是那个投影下推和谓词下推,是不是真的能下推,要如何书写组合条件,目前发现只能做一些极其简单的筛选,而且效率干不过 btx。
上述用到的测试文件如下↓:


😄 🙏 懂了,谢谢大神回复。
parquet 有点复杂,弄不好变成文件炸弹,看上去很小实际上解析后非常庞大。一般的小白估计玩不转,不适用日常办公。
最近有些群里讨论 parquet 的频率有点高,所以想到了集算器也能读 parquet,帖子中所说的问题老早就发现了,当时不想一个一个问,正好收集了一下。这也是一个学习过程,多少涨了点知识。
Thank u for yr time!🙏