


从‘数据库思维’到‘对象思维’:DQL 重新定义关联查询
还记得被多表 JOIN 支配的恐惧吗?当你在 SQL 中写下第 5 个 LEFT JOIN 时,是否曾怀疑过人生:"我只是想分析一下销售数据,为什么要记住这么多表结构?" 今天,我们要聊的 DQL(Dimensional Query Language)正在悄然改变这场游戏规则。
关联查询的 "进化论"
在传统的数据库思维里,我们像是 "表关系工程师",必须清楚每张表的关联关系,用 JOIN 精确地编织数据网络。典型的 SQL 查询往往长这样:
-- 传统的SQL方式:哪些美国籍员工有一个中国籍经理?
SELECT A.*
FROM employee A
JOIN department B ON A.department=B.id
JOIN employee C ON B.manager=C.id
WHERE A.nationality='USA' AND C.nationality='CHN'
而用 DQL,同样的查询变成了:
-- DQL的对象式查询
SELECT * FROM employee
WHERE nationality='USA' AND department.manager.nationality='CHN'
看出差别了吗?DQL 让我们的关注点从 "表如何连接" 转向 "想要什么数据"。
DQL 的核心原理
外键属性化:用 "点" 操作符替代复杂 JOIN
DQL 重新梳理了表间关联,比如外键关联是指: 表 A(事实表)的某个字段和表 B)(维表)的主键字段关联。这种多对一的关系是业务中最常见的关联类型。
传统 SQL 思维:我需要记住员工表通过 department 字段连接部门表,部门表又通过 manager 字段连接员工表,还要处理表别名。
DQL 对象思维:我直接访问 department.manager.nationality--"所属部门的经理的国籍"。外键关系被抽象为对象属性。部门. 经理. 国籍这样的语法,不仅更符合业务人员的思维习惯,还大幅减少了代码量。
这种对象式理解方式之所以可行,是因为 DQL 约定了外键关联时维表中关联键必须是主键。这意味着 employee 表中每一条记录的 department 字段唯一关联一条 department 表中的记录,department 表中每一条记录的 manager 字段也唯一关联一条 employee 表中的记录。
这种转变看似简单,实则是思维模式的根本性跨越。我们不再需要关心底层是几个表、通过什么字段连接,只需按照业务逻辑 "点" 下去。这样既消除了复杂的表别名,又能有效避免意外的笛卡尔积,使得查询逻辑更符合业务思维。
按维对齐:各自为政的 "联合国" 模式
按维对齐是 DQL 中更加革命性的概念。它允许不同的表按照共同的维度进行聚合,而无需关心表之间的直接关联关系。
传统 SQL 的困境:
假设我们要统计每一天的合同额、回款额和发票额,SQL 写法极其复杂:
-- SQL:需要多重子查询和JOIN
SELECT COALESCE(A.date, B.date, C.date) as stat_date,
A.contract_amount, B.payment_amount, C.invoice_amount
FROM (
SELECT date, SUM(price) as contract_amount
FROM Contract GROUP BY date
) A
FULL JOIN (
SELECT date, SUM(amount) as payment_amount
FROM Payment GROUP BY date
) B ON A.date = B.date
FULL JOIN (
SELECT date, SUM(amount) as invoice_amount
FROM Invoice GROUP BY date
) C ON COALESCE(A.date, B.date) = C.date
DQL 的优雅解决方案:
-- DQL:按维对齐,各表独立计算后自动对齐
SELECT Contract.SUM(price), Payment.SUM(amount), Invoice.SUM(amount) ON date
FROM Contract BY date UNION Payment BY date UNION Invoice BY date
按维对齐的核心思想:
每个表都是独立的 "对象",各自进行聚合计算
所有表向共同的基准维度(如 date)对齐
不需要关心表之间的关联关系,只需要指定对齐维度
更复杂的业务场景:
统计每个地区的销售员数量及合同额:
-- DQL:混合使用外键属性化和按维对齐
SELECT Sales.COUNT(1), Contract.SUM(price) ON area
FROM Sales BY area UNION Contract BY customer.area
这里 customer.area 体现了外键属性化的优势,直接通过合同表的客户外键访问客户所在地区。
DQL 的核心突破在于彻底改变了我们对 "关联" 的理解:
传统 SQL 思维下,表之间必须通过 JOIN 建立直接联系,形成紧密的关联网络。
而 DQL 对象思维:
每个表都是独立的数据对象
通过外键属性化处理层级关系
通过按维对齐处理并行关系
查询时只需关注 "要什么",不用关心 "怎么连"
这种思维转变让复杂的数据分析变得异常简单。无论是处理星型 schema、雪花 schema,还是更加复杂的多事实表场景,DQL 都能提供统一的解决方案。
思维转变:从 "表关系工程师" 到 "数据对象设计师"
这种转变的核心在于:DQL 把关联逻辑从运行时(SQL 执行时)提前到了元数据设计时。
在数据库思维模式下,每次查询都要重新定义表间关系,像是每次都要重新 "布线"。查询者需要了解:
哪些表需要连接
通过什么字段连接
使用什么连接类型
如何避免笛卡尔积
而在 DQL 的对象思维下,数据之间的关系已经在数据模型层面定义好,查询时直接使用即可。我们只需要关心:
需要什么数据
满足什么条件
这让我们从繁琐的技术细节中解放出来,更加关注业务逻辑本身。
应用场景:DQL 在 BI 领域的天然优势
DQL 的这些特性使其特别适用于 BI 领域,让 BI 实时关联查询成为可能。
比如查询 "从北京打往上海的通话记录",基于 DQL 就很容易做出这样的界面:
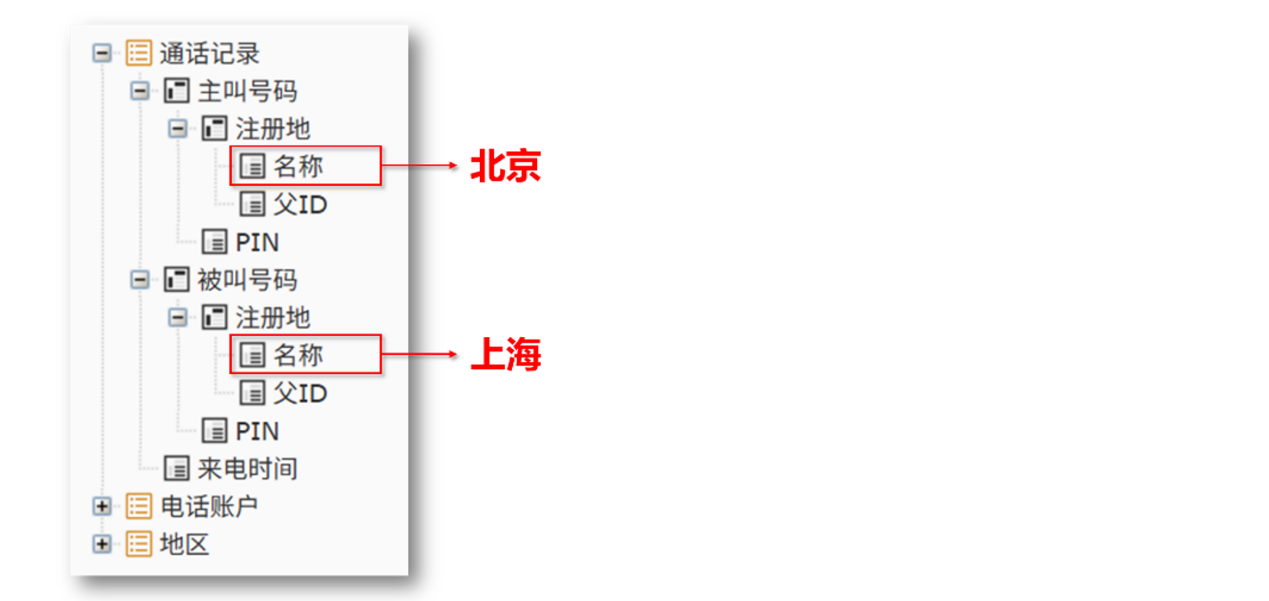
用户无需理解表间关系,用户操作流程极其简单:
选择 "通话记录" 作为查询主体;
然后勾选需要的字段:主叫用户. 所在城市. 城市名称、被叫用户. 所在城市. 城市名称、通话时长、资费方案. 资费金额;
最后设置过滤条件:主叫用户. 所在城市. 城市名称 ='北京' AND 被叫用户. 所在城市. 城市名称 ='上海'
整个过程无需处理复杂的多表 JOIN 逻辑,也不用理解底层表关联关系,更不用怕写错关联条件。DQL 自动处理所有底层细节,你只需要关心你想要什么数据。
看到这里,你可能会问:这么方便的 DQL,在实际工作中如何落地使用呢?
这正是 DQL 最具吸引力的地方——它不仅仅是一个理论概念,更是一个经过工程验证的成熟解决方案。在技术实现层面,润乾报表已经成功将 DQL 理念工程化实现。润乾 DQL 引擎将把 DQL 语句翻译成各种数据库的原生 SQL(如 Oracle、MySQL、SQL Server 等),这意味着 DQL 可以在现有的数据库环境上直接工作,只需要配置润乾报表即可。这种实现既保留了 DQL 的简洁性和易用性,又充分利用了底层数据库的性能优势,让传统数据库用户能够平滑过渡到更加高效的查询方式。
DQL 可以免费使用,已经集成到润乾的开源 BI 中,开箱即可体验 DQL 为数据查询和分析带来的革命性改变。
DQL 不是要完全取代 SQL,而是为关联查询提供了一种更符合人类思维的方式。它基于一个深刻的洞察:业务中的关联关系本质上就是外键、按维对齐这些模式。
对于数据库从业人员来说,掌握 DQL 意味着:
为业务用户提供更友好的数据查询接口
减少复杂查询的开发维护成本
提高数据分析的效率和准确性
关联查询的进化之路,其实就是让技术更好地服务于业务思考的过程。而 DQL,正沿着这条路坚定地向前迈进。

