


SPL 查询与报表计算实战指南 - 9 分组后的集合运算
9 分组后的集合运算
这类任务是指分组后的交集、并集、差集、合集等集合运算。SQL不支持显式集合,只适合处理简单场景下的集合计算,复杂的场景下代码会很难写,尤其是分组内或分组间的集合计算。
例1:找出每个月都能保持前3的销售员
数据源:(订单表9/Orders_TopnByMonth.txt)2022年每月每个销售员的销售额
目标: 按月份分组,计算出各组销售额前3的销售员的集合,再对各集合求交集。
SPL代码:
A |
|
1 |
$select month(OrderDate) as Month,SellerId,sum(Amount) as Amount from 9/Orders_TopnByMonth.txt where year(OrderDate)=2022 group by month(OrderDate),SellerId |
2 |
=A1.group(Month) |
3 |
=A2.(~.top(-3; Amount).(SellerId)) |
4 |
=A3.isect() |
A1:加载数据。
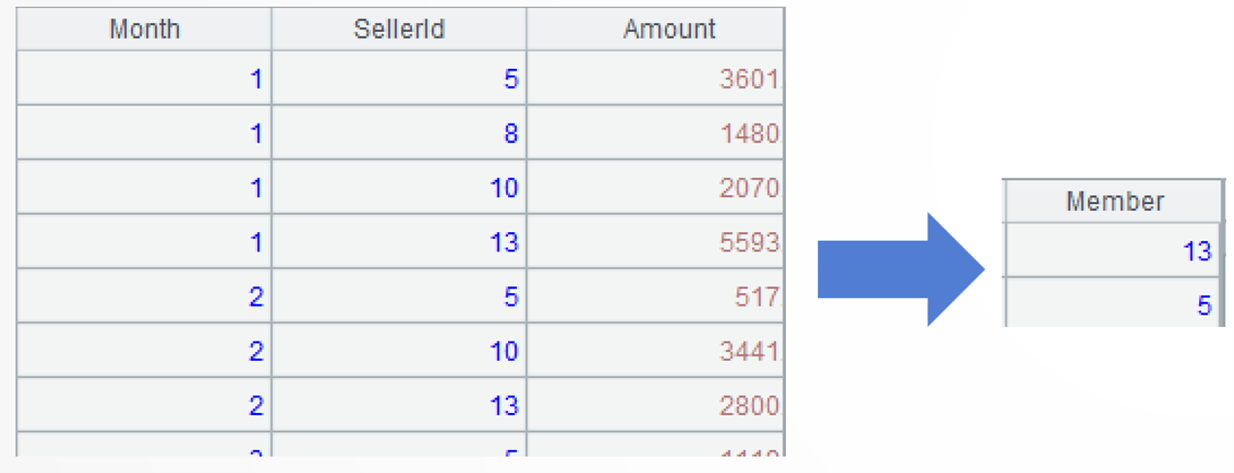
A2:按月份分组,每组是一个集合。前2个月如图:
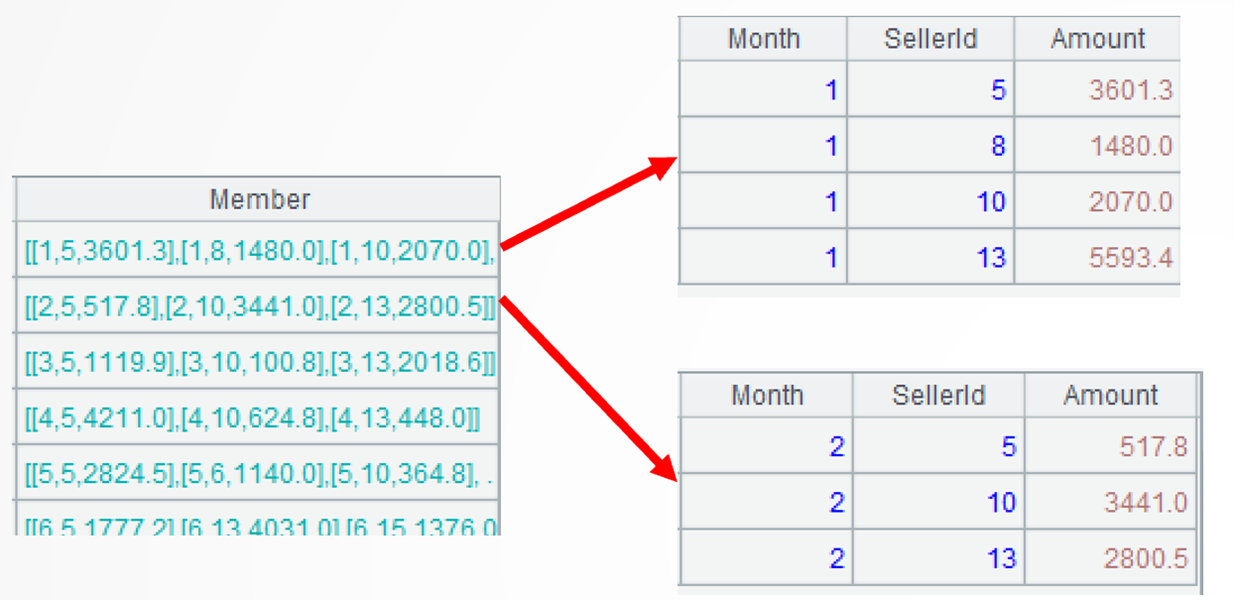
A3=A2.(~.top(-3; Amount)…) 处理 A2 的每组数据,先用 top 函数计算出各组销售额前 3 的记录,~ 表示当前组。前 2 个月如图:
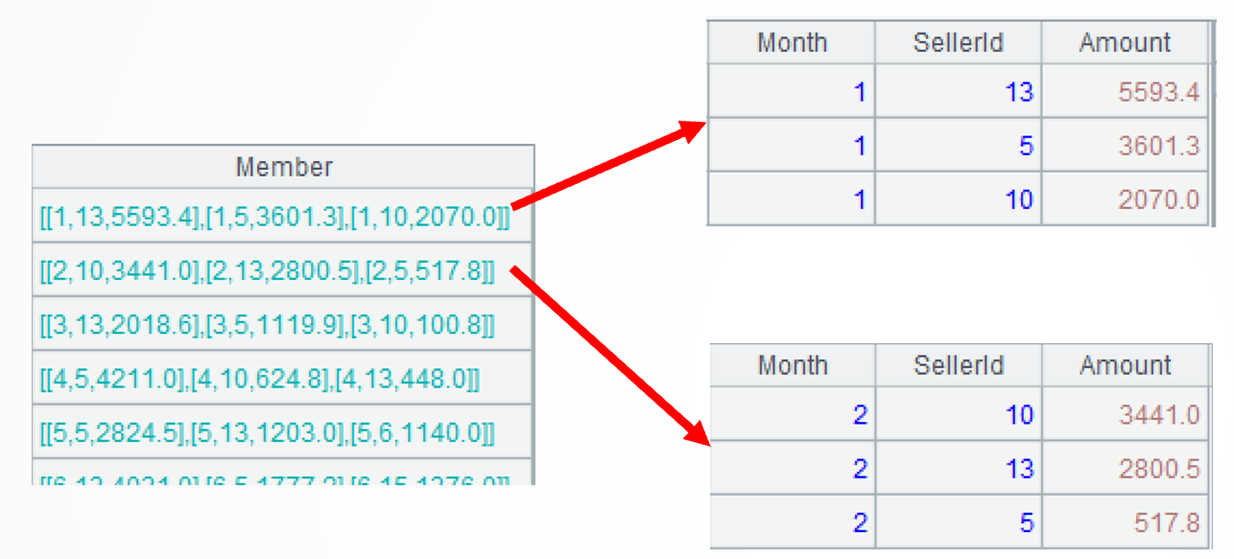
…(SellerId) 再取各组记录的 SellerId 字段,即销售员的集合。前 2 个月如图:
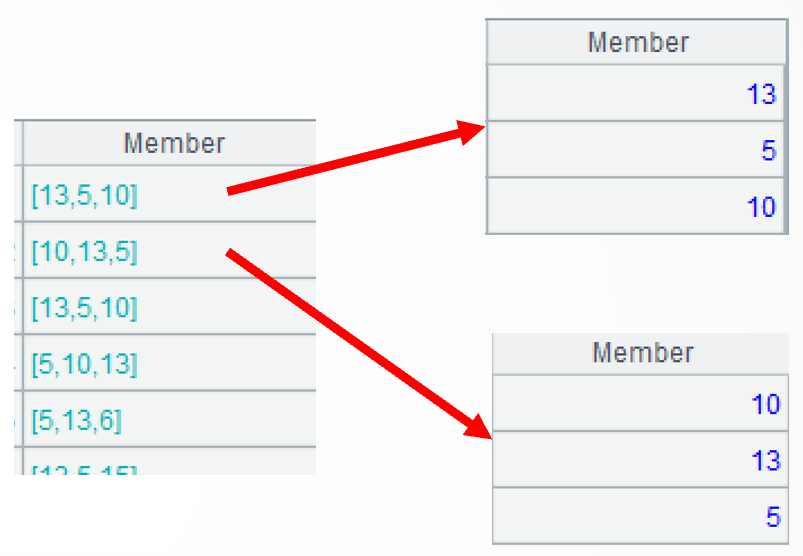
A4:计算 A3 中各成员的交集。函数 isect 用于求某集合里子集之间的交集,类似的函数还有并集 union、差集 diff、合集 conj。
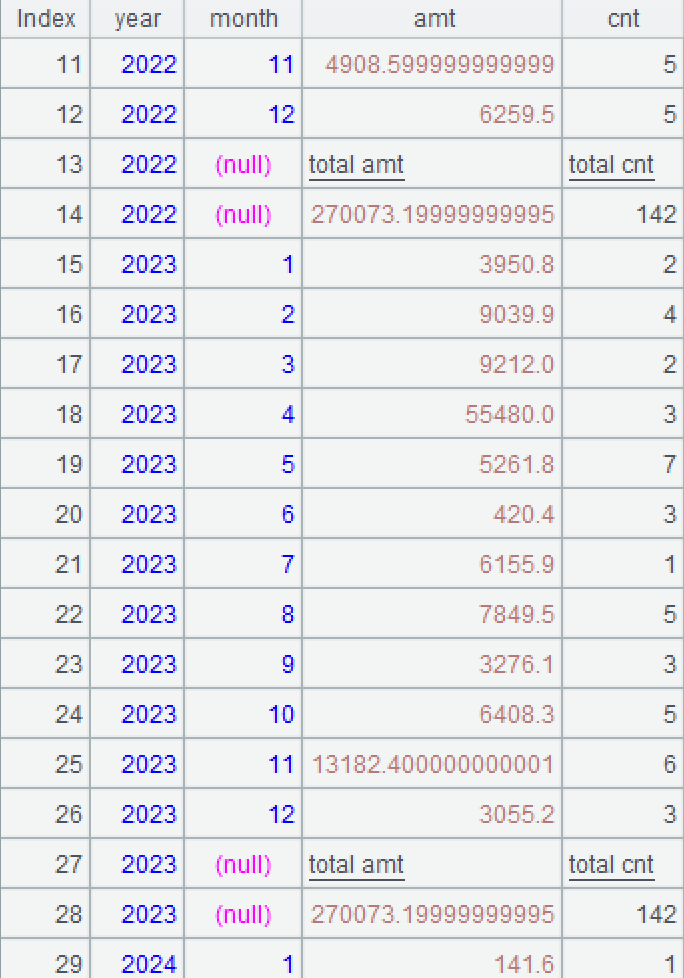
例2:将同一张表的订单总计记录复制到每年的小计记录之后
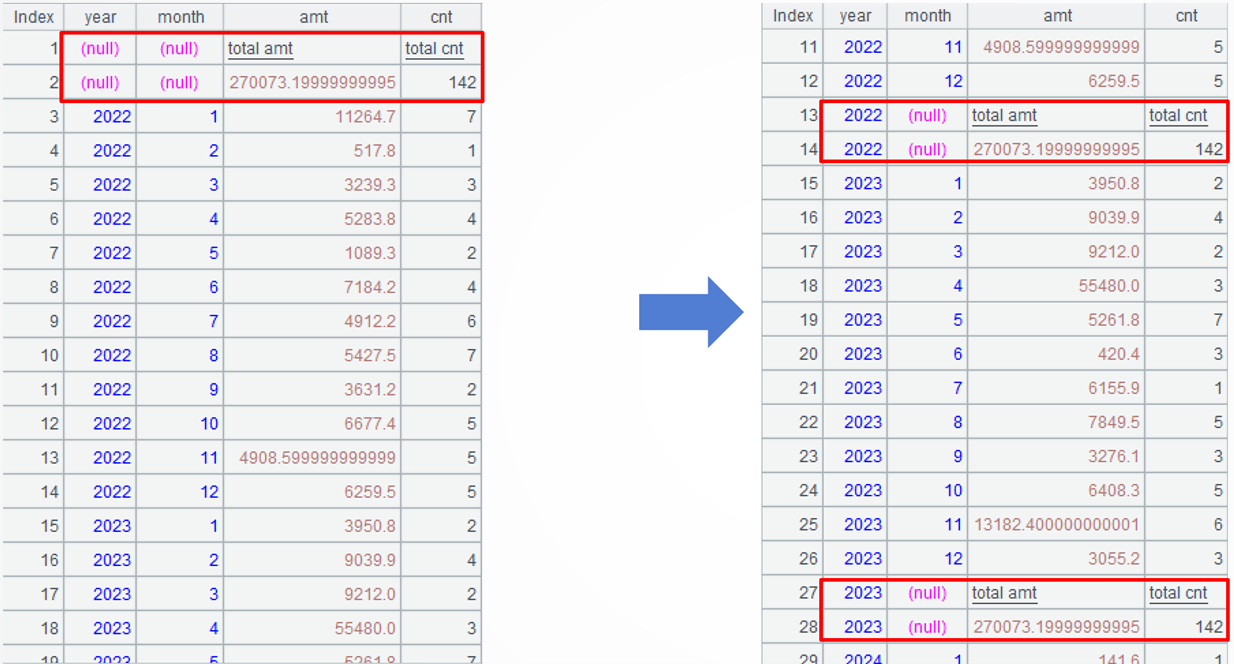
数据源:(基于订单表)每年每月的小计记录和总计记录合并而成的二维表,其中,总计记录的年、月字段为空,记录数不定。
目标:生成报表需要的数据,保持小计记录的顺序不变,将总计记录分别复制到每年的小计记录之后,并将总计记录的年改成小计对应的年。
SPL代码:
A |
|
1 |
$ with detail as (select year(OrderDate) year, month(OrderDate) month,sum(Amount) amt, count(1) cnt from Orders.txt group by year(OrderDate) , month(OrderDate) ) select * from {create(year,month,amt,cnt).record([null,null,"total amt","total cnt"])} union select null as year, null as month,sum(amt) amt, sum(cnt) cnt from detail union select * from detail |
2 |
=A1.select(!year) |
3 |
=(A1\A2).group@u(year) |
4 |
=A3.conj(~|A2.new(A3.year,month,amt,cnt)) |
A1:加载数据。
A2:过滤出总计记录集。函数select的过滤条件!year等价于year==null。

A3:先用差集计算出明细记录,再在保持顺序不变的情况下,对明细记录按年分组。函数 group 的选项 @u 表示分组时成员保持原顺序。第 1 组数据如图:
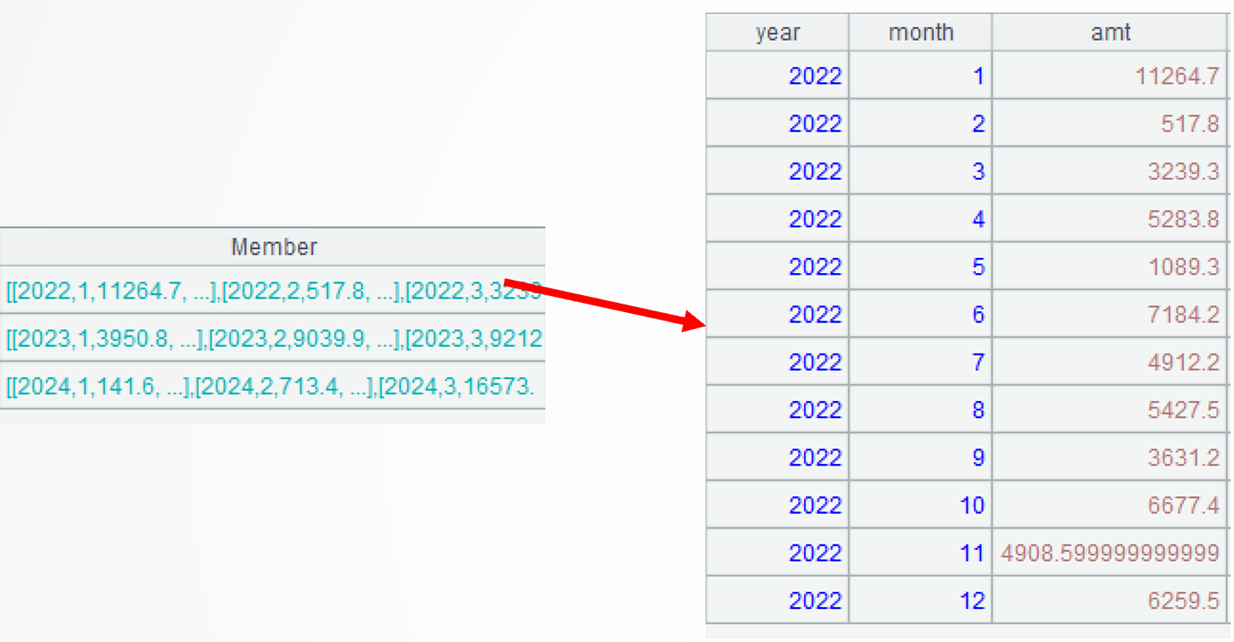
A1\A2表示求记录集合A1和A2的差集。类似的运算符还有^交集,&并集,|合集。函数diff也可以求差集,A3可以改写成=[A1,A2].diff().group@u(year)
l 知识点:集合运算符和集合运算函数
运算符和函数都可以进行集合运算,区别在于集合运算符的运算对象只能是2个集合,而集合函数的运算对象更广,可以是2个集合,还可以是多个集合,以及含有子集的大集合。
A4=A3.(~|A2.new(A3.year,month,amt,cnt)) 处理A3的每组(每年)数据,先用总计记录集A2生成新序表,并与当前组进行合集运算。注意,新序表的year字段会改成当前组的year,运算符|表示求合集,可以用conj函数代替。第一组数据如图:
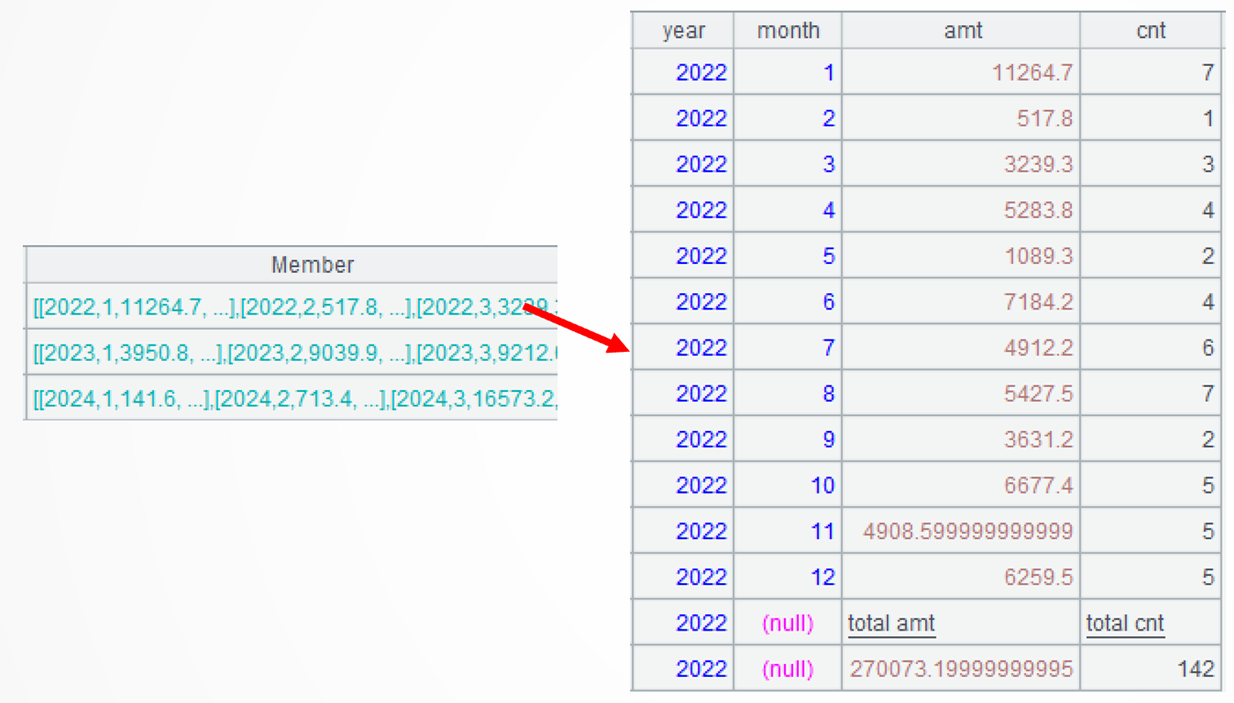
A3.conj(…) 合并各组成员,函数 conj 用于计算 A3 的子集间的合集,也就是把子集的成员按顺序拼起来。
例3:根据批量入库表和批量出库表计算现库存
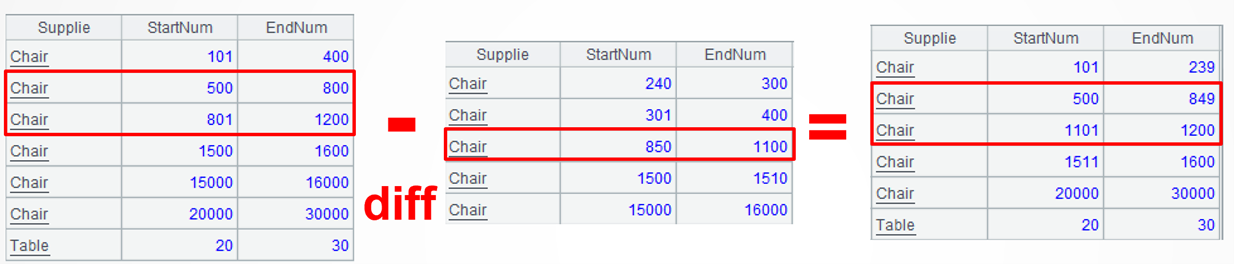
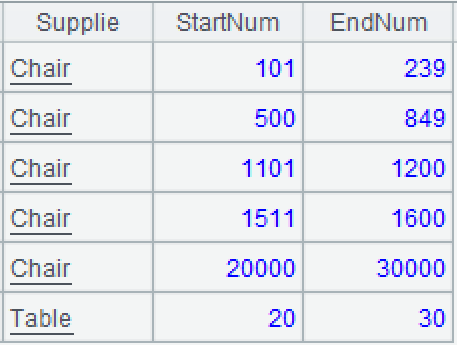
数据源:批量入库表或原库存表9/Stock_BatchIn.txt,存储多种物资的多批次入库情况,每批次都记录该物资的连续区间的起止编号,比如第3条记录表示入库的椅子的起止区间是[801:1200],共399个。批量出库表或消耗表9/Stock_BatchOut.txt,存储多种物资的多批次出库情况,字段意义类似批量入库表,每批次都记录出库物资的连续区间的起止编号,比如第3条记录表示(从原库存区间[801:1200])出库的椅子的起止区间是[850:1100]。
目标: 根据批量入库表和批量出库表计算现库存,同样用物资、当前库存的连续区间的起止编号来表示。注意,入库表的区间可能被消耗成不连续的多段区间,这种情况下要自然生成多条记录,每条记录对应一个连续区间,比如原库存区间[801:1200]中的 [850:1100]出库后变成了现库存的 2 个连续区间 [500:849] 和[1101:1200]
SPL代码:
A |
B |
|
1 |
$select * from 9/Stock_BatchIn.txt |
$select * from 9/Stock_BatchOut.txt |
2 |
=A1.group(Supplie; ~.conj(to(StartNum,EndNum)):ini) |
=B1.group(Supplie; ~.conj(to(StartNum,EndNum)):used) |
3 |
=A2.join(Supplie,B2,used) |
|
4 |
=A3.derive([ini, used].merge@d().group@i(~!=~[-1]+1):current) |
|
5 |
=A4.news(current; Supplie, ~1:StartNum, ~.m(-1):EndNum) |
|
A1A2:加载数据。
A2:用 group 函数对原库存按物资分类,但不汇总,将组内的每个区间转为一个连续序列的小集合,再合并为一个有序但不连续的大集合。~ 表示当前组,函数 to 可按起止序号生成连续序列,函数conj表示对集合的各个子集做合集运算。
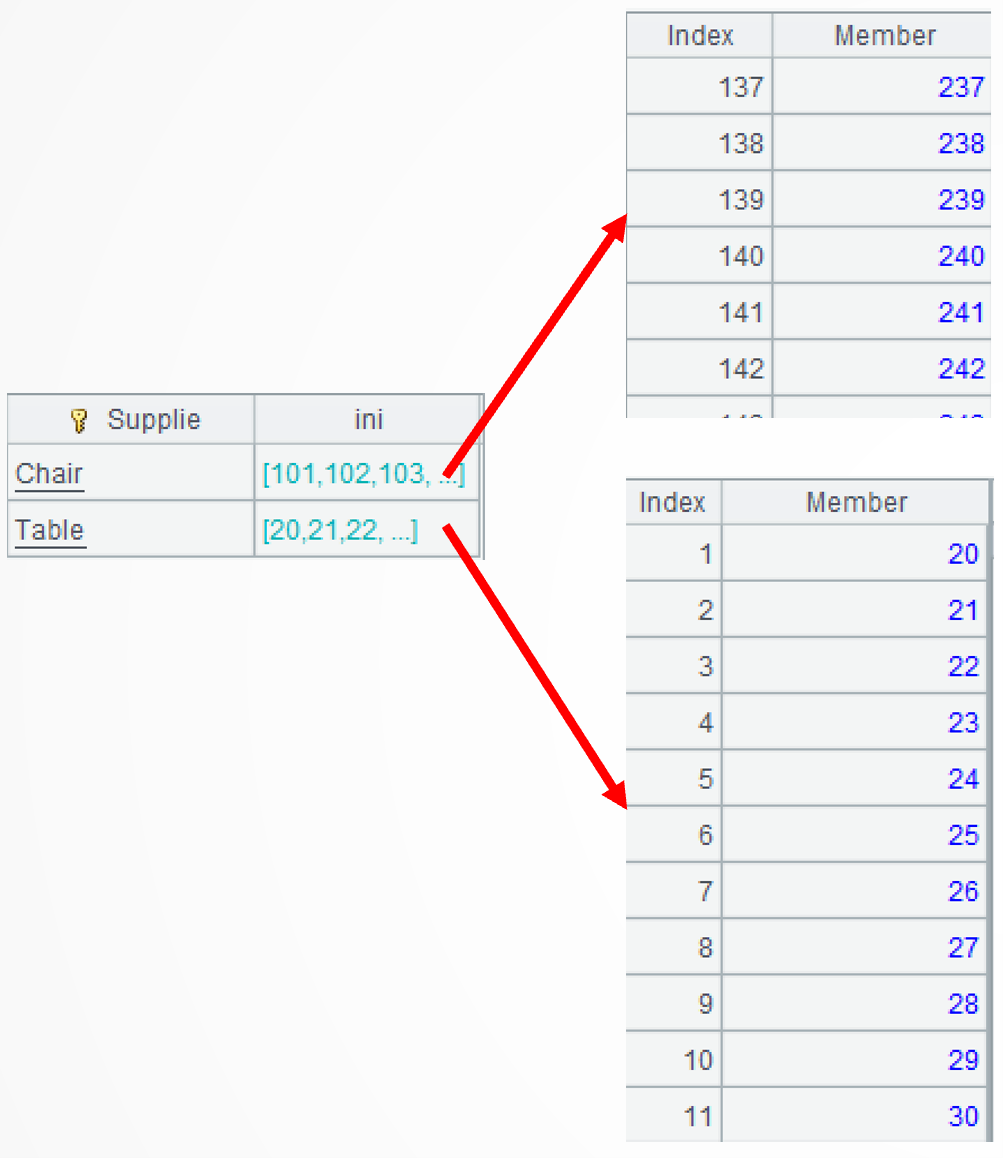
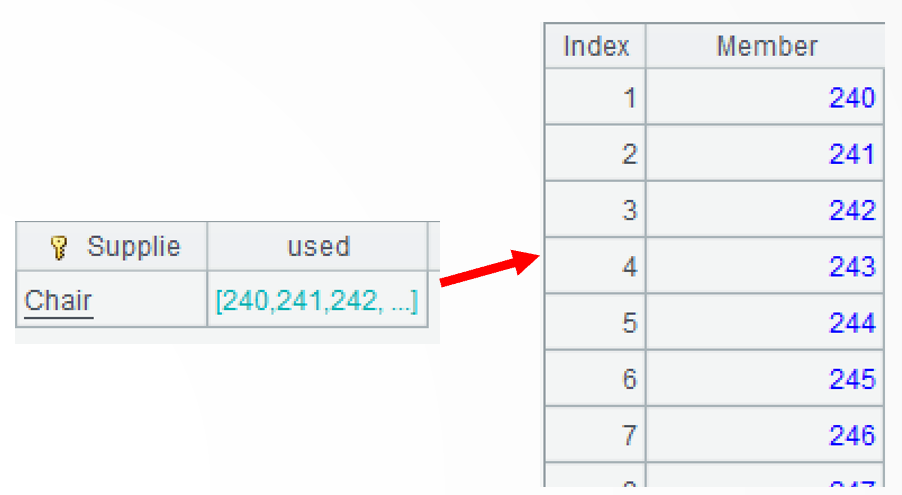
B2:对出库表做同样的计算。
A3:用 join 函数将入库表和出库表按物资进行左关联。
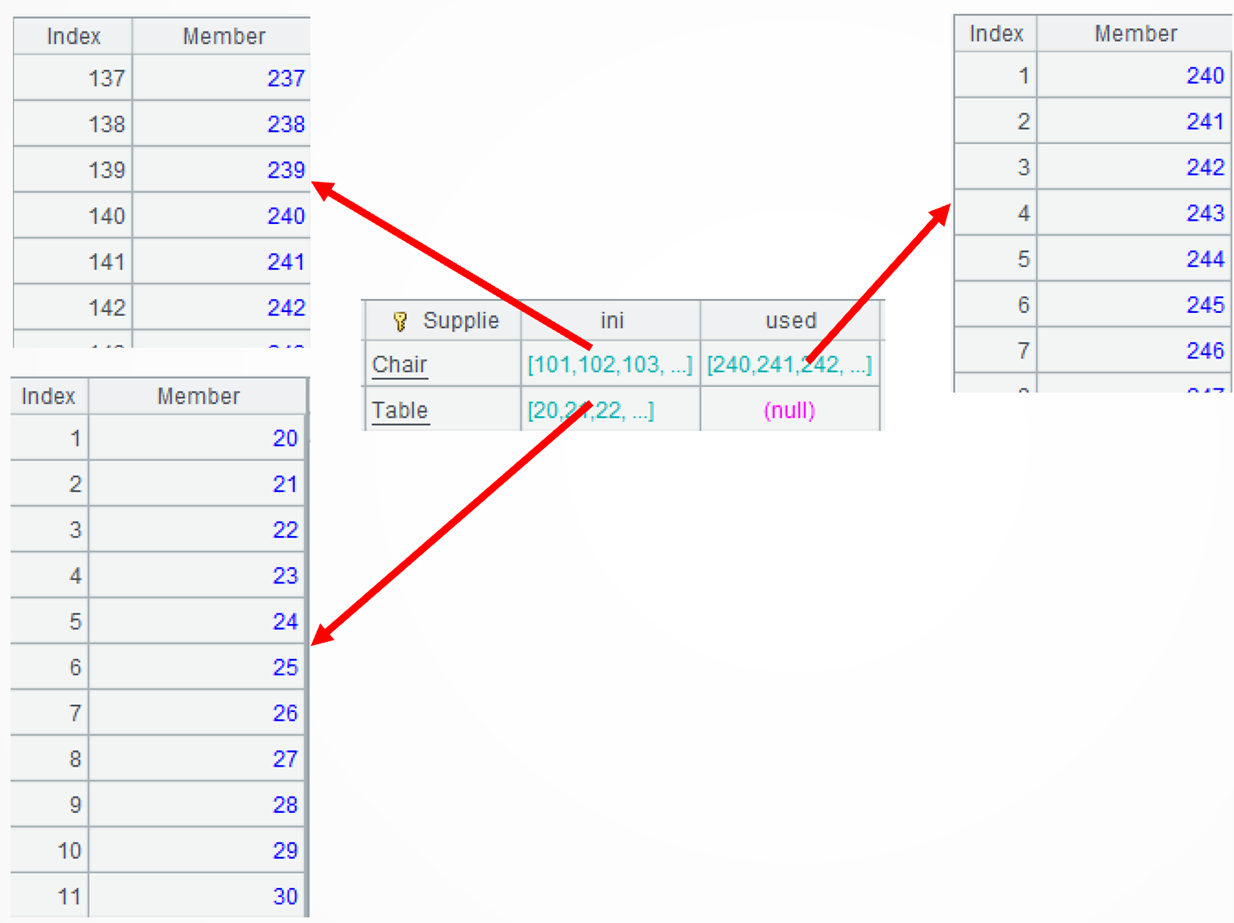
A4=A3.derive([ini, used].merge@d()…) 新增计算列,先将每种物资的入库集合和出库集合进行差集计算。函数 merge 对有序集合进行归并,结果仍然有序,@d 表示归并时计算差集,属于差集的优化函数。注意差集后的序列有序但不连续,比如原库存连续序列[…238,239,240,241…]出库后成为[…238,239,500,501…]
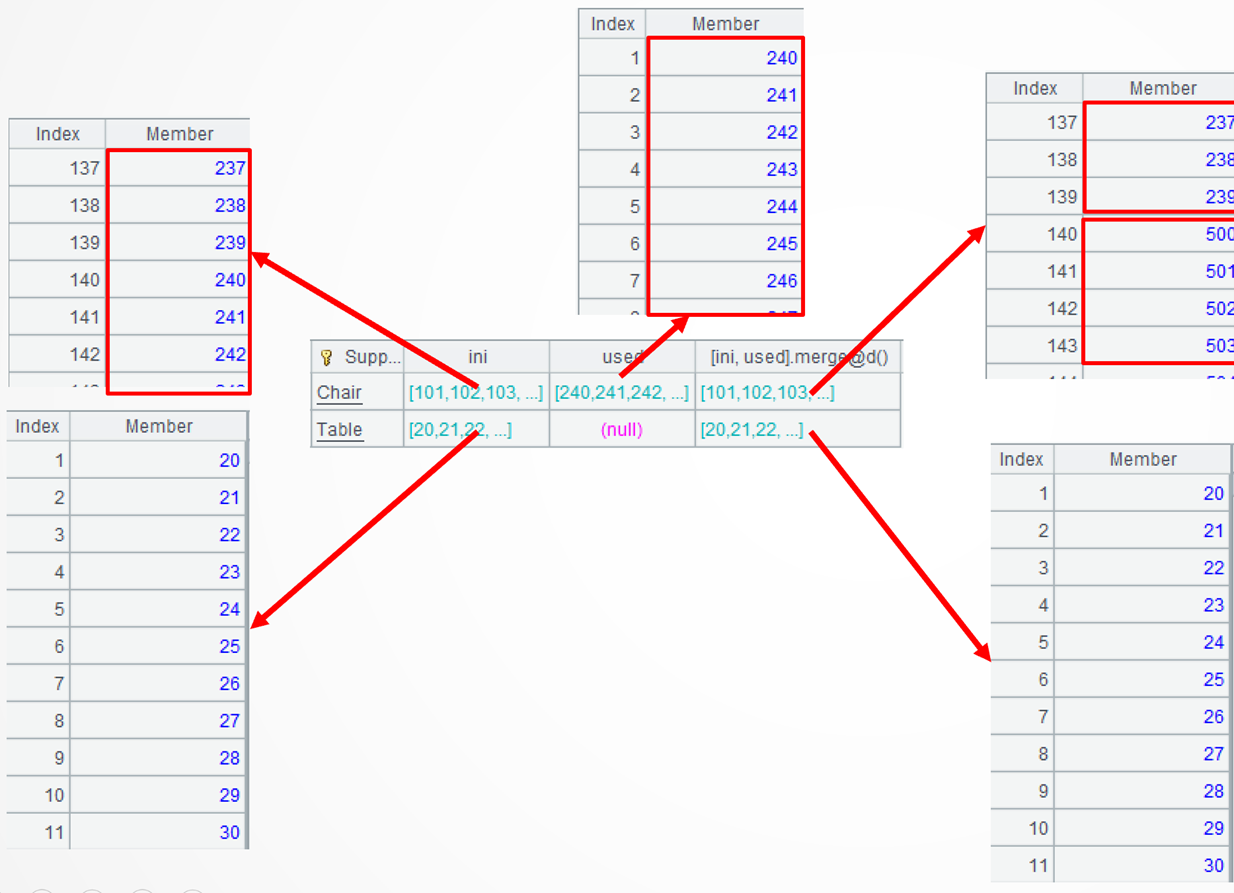
…group@i(!=[-1]+1):current 再对每个差集进行条件分组,将连续的序列分到同一小组,比如 […238,239]、[500,501..] 分别分到了第 1 和第 2 小 组。函数 group 用于分组,默认按等值分组,@i 表示按条件分组,~[-1] 表示上一个成员。
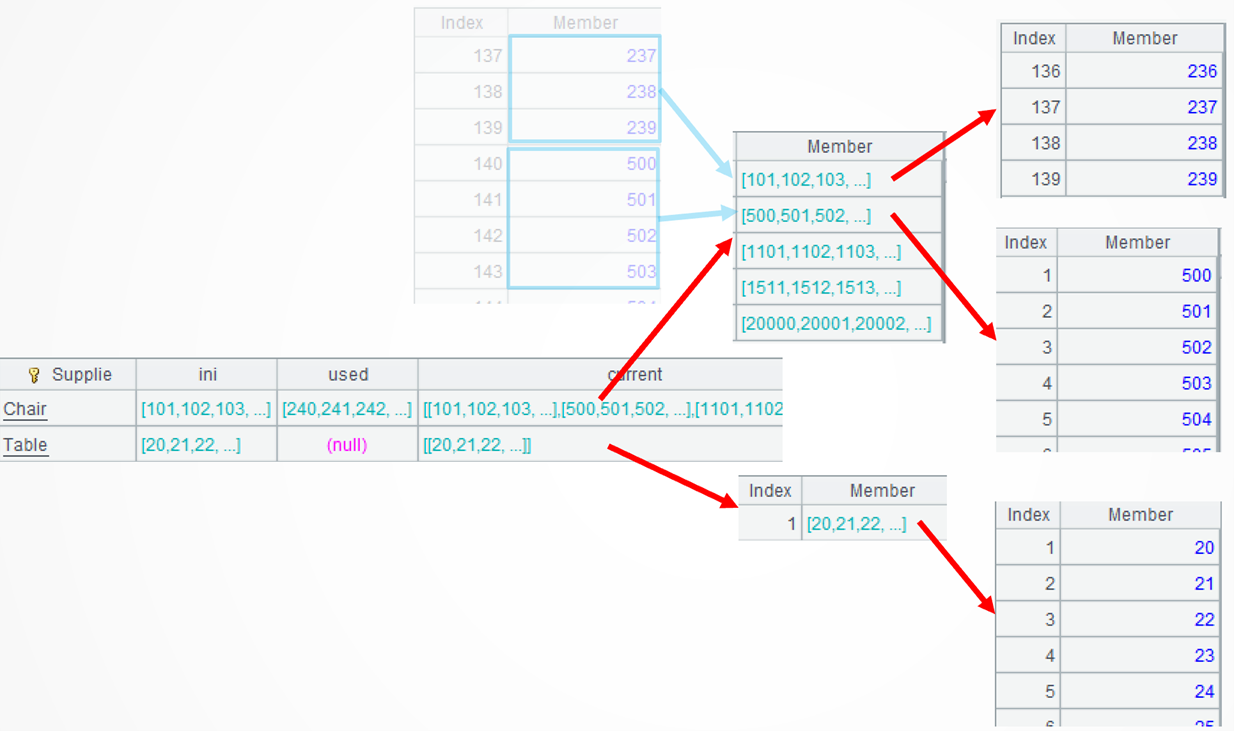
A5:用 A4 的每条记录的 current 字段里的每个序列,生成一条新记录,其中,新区间的起止序号取自每个序列的头尾。函数 news 可将集合的每个成员扩展成一条记录。.m(-1) 表示 ~ 里的倒数第 1 个成员,.m(1) 表示正数第 1 个成员,简写做 ~1。
扩展阅读
(https://c.raqsoft.com.cn/article/1743554223665)
(https://c.raqsoft.com.cn/article/1739949646293)
(https://c.raqsoft.com.cn/article/1734599942113)
(https://c.raqsoft.com.cn/article/1733535533319)

