


SPL 查询与报表计算实战指南 - 基本常规运算
基本常规运算
这类任务是指查询、排序、关联、分组汇总等基本运算,可以以此了解SPL的基础知识,供初次接触SPL的用户快速入门,已经了解过SPL的用户可以跳过这部分。
例1:列出所有不重复的部门
数据源:员工表
目标:对部门字段值去除重复,只保留唯一值。
SPL代码:
A |
|
1 |
$select * from Employee.txt |
2 |
=A1.id(Dept) |
A1:加载数据。用简单SQL查询Employee.txt,生成SPL序表。

l 知识点:序表
序表是SPL的基础数据结构,类似SQL结果集,也是多条记录组成的记录集合,主要区别在于SQL结果集是无序的,记录没有天然序号;序表是有序的,记录有天然序号。不引起误会的情况下,序表经常被简称为表,比如把A1叫做员工序表或员工表是一个意思。
上图A1的Index是序号列,代码中用#表示,A1.(#)可以获取序号列(序号组成的集合):[1,2,3,….]
A1.(Name)可以获取Name列:["Ashley","Rachel","Emily",…]
序表容易实现序号相关的计算,简单的比如按序号取记录,SPL写作(N),类似SQL中的rownum=N语法。比如用A1(2)获取第2条员工记录。

再比如取前 N 条记录,SPL 写作 to(N),类似 SQL 中的 Top 函数。比如用 A1.to(3) 获取前 3 条记录。

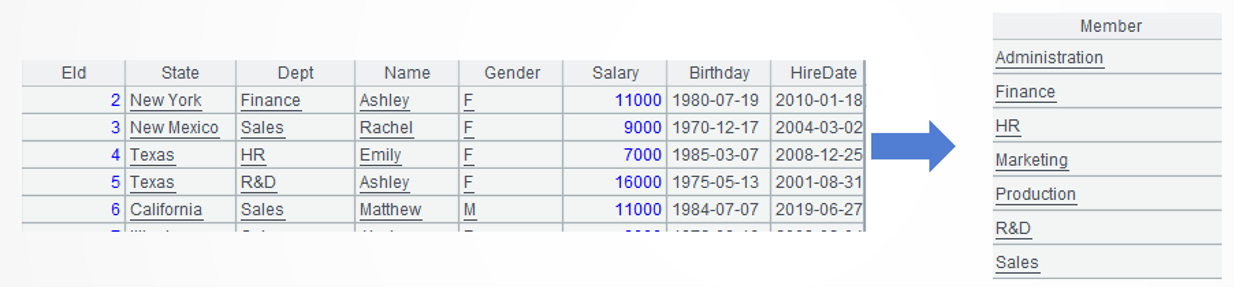
A2:用函数 id 对部门字段去重。
l 知识点:去重
SPL提供了id函数,可以去重字段值的重复,类似SQL的distinct语法。如同SQL的group by可以实现去重,SPL的分组汇总函数groups也可以去重,所以A2还可以写作A1.groups(Dept)。
按照双字段部门和州去重,写作A1.groups(Dept,State)
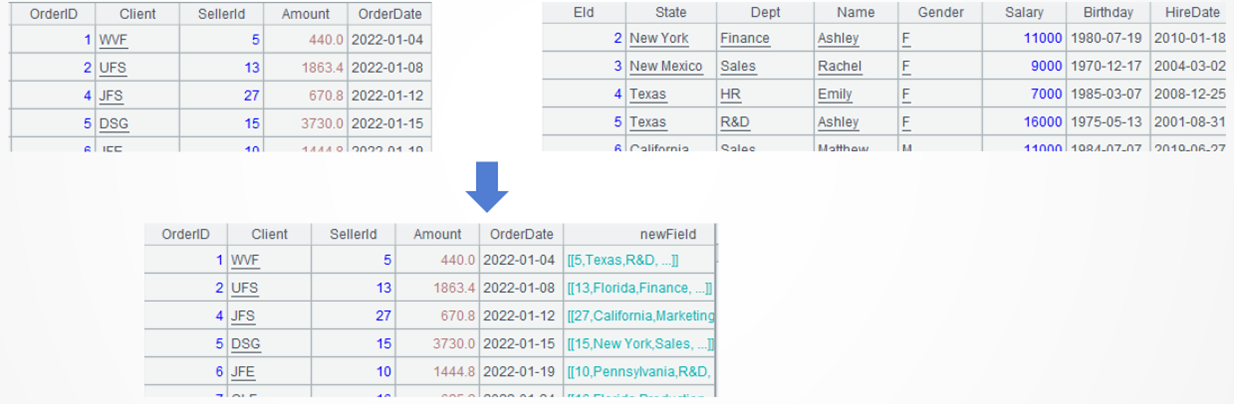
例2:订单表增加计算列指向员工记录
数据源:订单表、员工表。
目标:给订单表增加新字段newField,值为员工表对应的记录。
SPL代码:
A |
|
1 |
$select * from Orders.txt |
2 |
$select * from Employee.txt |
3 |
=A1.derive(A2.select(EId==SellerId):newField) |
A1,A2:加载数据。
A3:给订单表增加计算列newField。遍历每条订单,选出SellerId对应的员工记录,作为当前计算列的值。函数select用于过滤,函数derive用于增加计算列,结果是新序表。
应当注意到,序表A3的字段值可以是记录(引用),这与SQL结果集。
l 知识点:序表的字段值是泛型的
序表的字段值是泛型的,可以是简单类型,也可以引用另一个序表或记录,预先建立表之间的关联关系,从而复用关联关系,或简化复杂的关联计算。作为对比,SQL结果集的字段值只能是简单类型,不能是另一个结果集或记录。
比如,利用A3的关联关系继续计算,统计每个部门每个客户的订单数量和订单金额:
=A3.groups(newField.Dept, Client; sum(Amount), count(1))
应当注意到,可以通过变量名A1引用订单序表,通过A2引用员工序表,这与SQL结果集不同。
l 知识点:序表是显式集合
序表是显式集合,可以用变量直接引用,可以简化多步骤的复杂计算。作为对比,SQL结果集不是显式集合,不能用变量直接引用,只能作为临时表用from语句引用。
例3:过滤订单并将金额增加10%
数据源:订单表
目标:找出2022年3月份的订单,将订单金额增加10%,不要影响其他订单

SPL代码
A |
|
1 |
$select * from Orders.txt |
2 |
=A1.select(string(OrderDate,"yyyy-MM")=="2022-03") |
3 |
=A2.run(Amount=Amount*1.1) |
A1:加载数据。
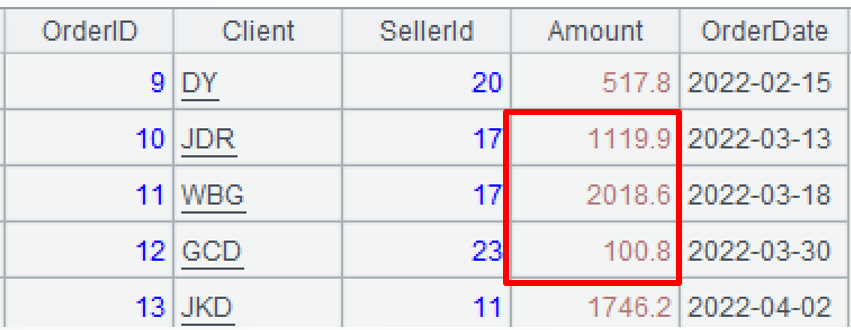
A2:选出指定月份的数据。函数 select 用于过滤数据。
l 知识点:过滤
函数select用于条件过滤,基本功能覆盖了SQL的where语句,其中,逻辑运算符是&&(与)、||(或)、!(非)等,比较运算符中的相等符号是==。
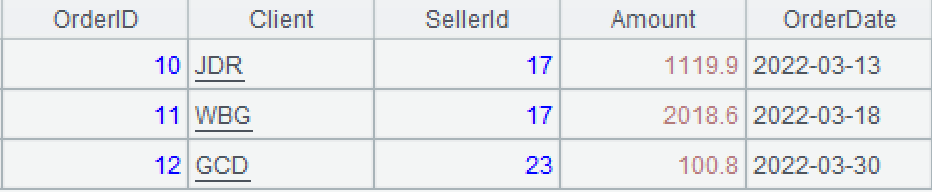
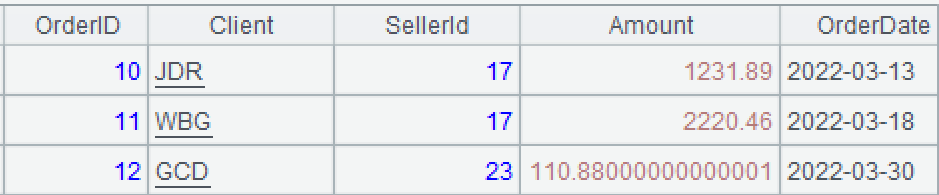
A3:修改A2,将订单金额增加10%。函数run用于修改并返回修改后的数据。修改后A2和A3如下图。
此时再观察 A1,会发现只有指定月份的订单被修改了。
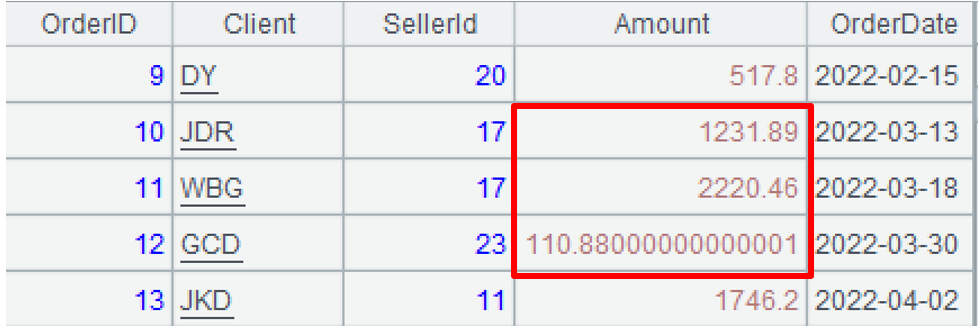
修改A2后,A1里的部分记录发生了变化,这说明A2和A1有某种关系。A1是前面介绍过的序表,A2是A1里记录的引用,称作排列。
l 知识点:排列
对序表的一般计算,比如排序sort、过滤select、分组group、关联join等,通常不会生成新序表,而是派生出原序表的记录引用的子集,这就是排列。为了简化文字,一般会把排列的记录引用简称为记录,会把排列简称为序表的子集。作为对比,改变序表或排列的结构的计算,则通常会生成新的序表,比如生成新序表create、追加字段或计算列derive、分组汇总groups。
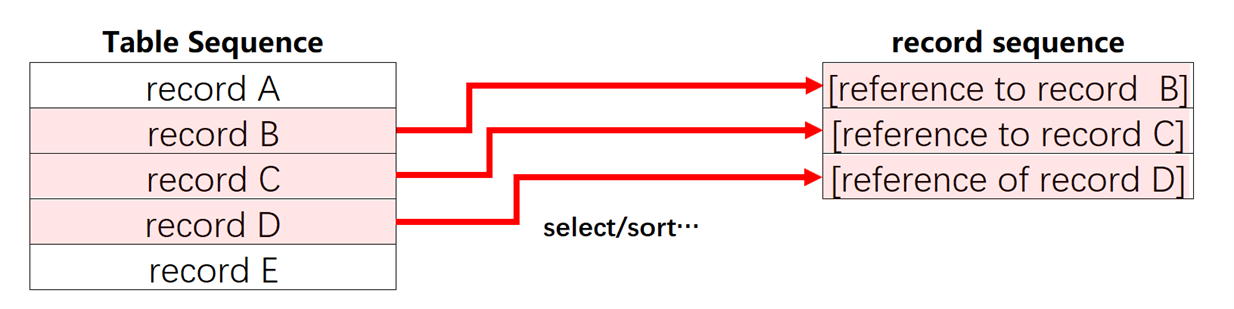
修改排列时,实际修改的是序表的子集,如A1中OrderID=[10,11,12]的记录,相应的,子集的补集不会被修改。
例4:统计每年每个部门的订单金额和订单数量
数据源:订单表、员工表
目标:关联订单表和员工表,按年份和部门分组,统计每组记录的订单金额和订单数量,再按年份的升序和订单金额的降序排序。部分订单没有指定销售员(部门),也要参与统计。
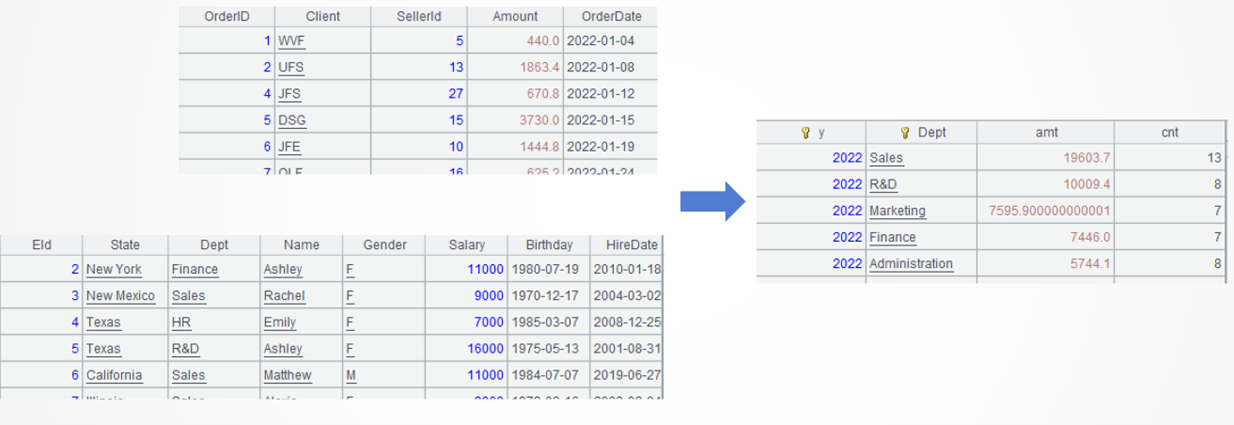
SPL代码
A |
B |
|
1 |
$select * from Orders.txt |
$select * from Employee.txt |
2 |
=join@1(A1:ord,SellerId; B1:emp,EId) |
|
3 |
=A2.groups(year(ord.OrderDate):y,emp.Dept;sum(ord.Amount):amt, count(1):cnt) |
|
4 |
=A3.sort(y,amt:-1) |
|
A1:加载数据。
A2:用join函数左关联订单表和员工表。计算结果是2个字段的新序表,字段值是订单记录和员工记录的引用,其中两条记录如图。

l 知识点:关联/连接
函数join用于建立关联,类似SQL的join语句,默认内关联,@是函数选项符号,后面的符号或数字表示不同的扩展功能,@1表示左关联。
A3:按年份和部门分组,统计每组记录的订单金额和订单数量。
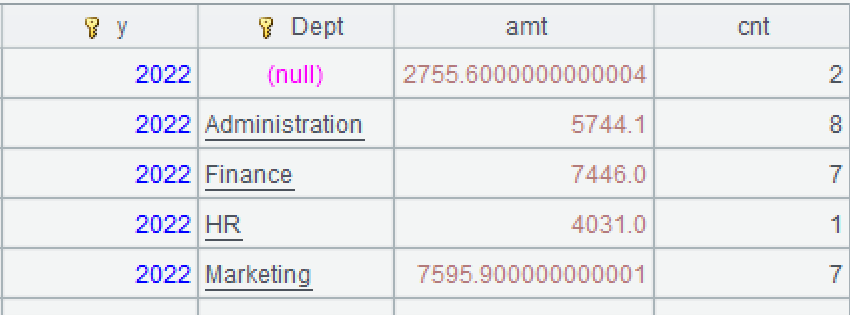
l 知识点:分组汇总
SPL提供了groups函数,用于分组汇总,计算结果是序表。函数groups类似SQL的group by语法。
A4:用sort函数按年份的升序和销售额的降序排序。
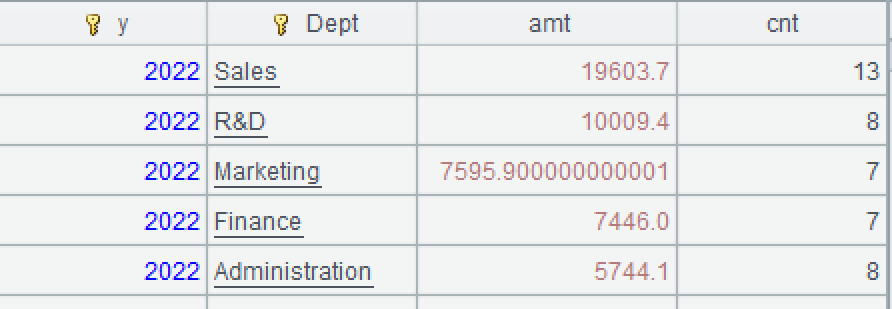
l 知识点:排序
SPL提供了函数sort,用于排序,类似SQL的order by语法。缺省升序,":-1"表示降序。不考虑空值的话,对字段值取负值再排序等同于降序,所以还可以写成=A3.sort(y,-amt)。
例5:分别观察指定州的员工、指定薪资范围的员工、前两者交集的员工。
数据源:员工表
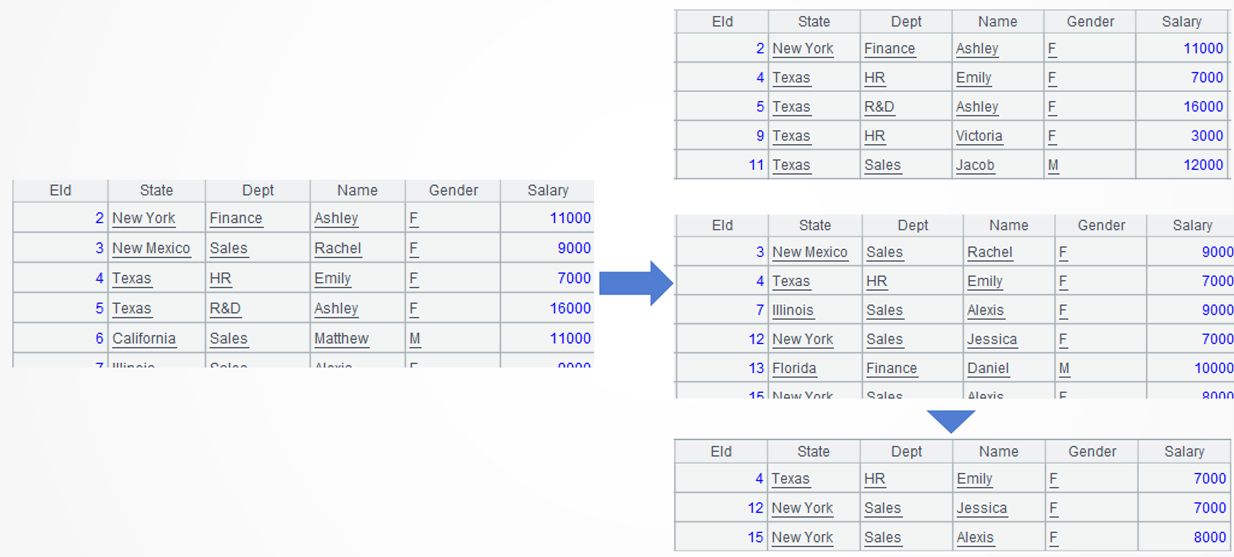
SPL代码
A |
|
1 |
$select * from Employee.txt |
2 |
=A1.select(State=="New York" || State=="Texas") |
3 |
=A1.select(Salary>=5000 && Salary<=10000) |
4 |
=A2 ^ A3 |
A1:加载数据。
A2:找出属于New York和Texas的员工。进行多值匹配的时候,还可以使用SPL的contain函数,A1.select(["New York","Texas"].contain(State))。
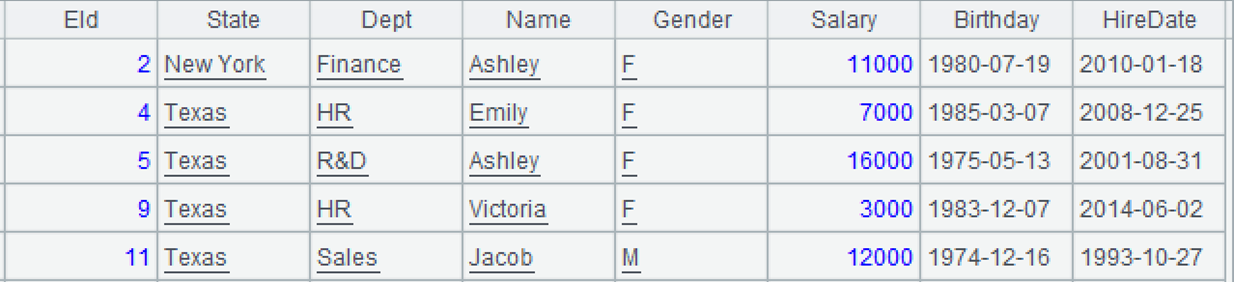
A3:找出薪资范围是 5000-10000 的员工。进行范围匹配的时候,还可以使用 SPL 的 betwen 函数,A1.select(between(Salary ,5000 :10000))
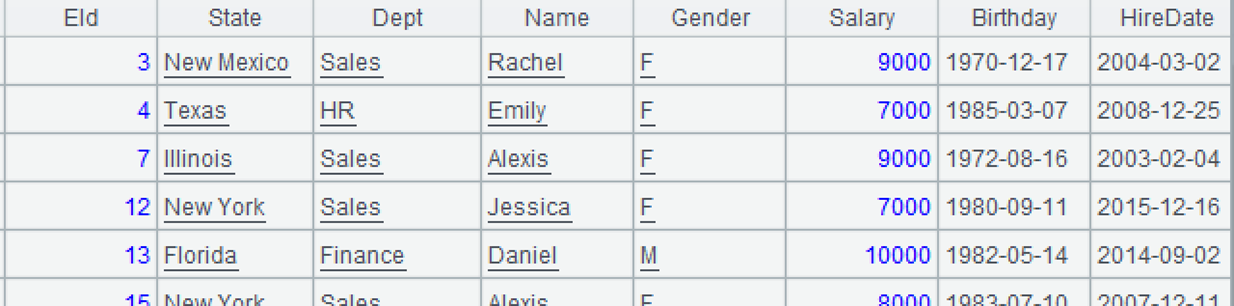
A4:计算 A2 和 A3 的交集。

l 知识点:集合运算
SPL提供了集合运算符,有^交集,&并集,\差集、|合集,对应的函数是isect、union、diff、conj。因为SPL序表支持显式集合,所以集合运算时不必把已经算过的集合再算一遍,这是与SQL不同的地方。

