第 3 章 复权数据
3.1 复权概念
复权是股票市场中用于调整历史价格数据的一种方法,主要目的是消除因公司分红、送股、配股等行为(即“除权除息”)导致的股价断层,使历史价格走势更连贯,便于分析和比较。
例如某支股票每股 10 元,持有 100 股,总资产 1000 元
发生拆股后,持有的 100 股变为 500 股,但是股价也会自动调整为原来的 1/5,变为 2 元,总资产还是 1000 元,并没有发生变化。
股价从 10 元变为 2 元,看似暴跌了 80%,但投资者的资产始终没变,因此股价的变化其实是 0。
为了避免这种价格“暴跌”的影响,需要对股票的价格进行修复,这一过程就叫做复权。
复权分为前复权和后复权。
前复权就是保持新时间点的价格不变,对历史时间点的价格进行调整,使得股价连续。而后复权正好相反,保持早期时间点价格不变,调整后续时间点的价格。
按上面例子,股价从 10 元变为 2 元,向前复权时,会维持今天的股价不变,而把昨天的股价由10元变成2元与当前价格保持一致,之前的股价也都一律按比例缩小,股价变为一条连续的曲线。
反之,向后复权就是保持昨天的价格10元不变,调整当前价格2元变10元,之后的股价也都按比例增大。
复权价的计算方法有多种,由于数据口径或计算方法的不同,得到的复权价格也会有所不同。这里我们采用的是涨跌幅复权法。
在日K线数据里,pfactor为复权因子。需要注意的是:该复权因子为当日复权因子,而不是累计复权因子,这样的好处是更方便随意指定一个时间区间计算出和该区间相关的复权价格。累计复权因子计算的是从头向后复权或从尾向前复权,这会导致距离太远的数会太大或太小,和实际的股票价格相差很大,有些软件还会算出负数。而当日复权因子则可以只计算所需区间的复权价格,计算量小,也不会和实际股票相差很多,用起来更灵活。因此这里我们采用当日复权因子。
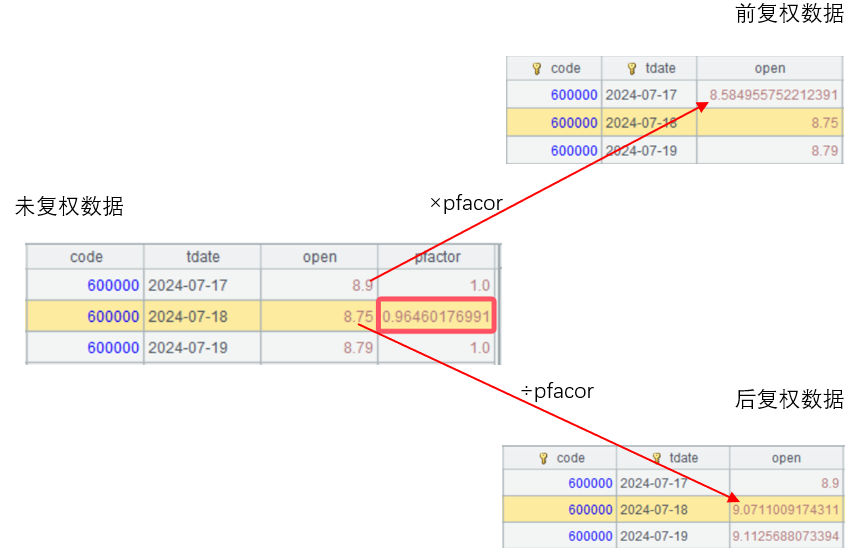
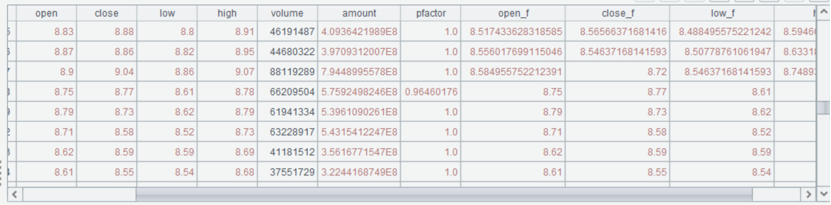
比如以浦发银行为例,数据如下图所示。在2024年7月18日发生了复权动作,复权因子pfactor为0.96460176991。前复权数据就是保持当日股价不变,昨日股价调整为8.9*0.96460176991=8.584955752212391,以此类推,之前的股价也按比例调整。反之,后复权数据就是保存历史股价不变,当日股价调整为8.75/0.96460176991=9.0711009174311,之后的股价同样也按比例调整。
由图中也可以看出pfactor为当日复权因子,只有在发生复权动作时参数才会变,其余都是1。网上有些渠道提供的因子可能为累计因子,因此看起来会有所不同,使用时需注意区分。
3.2 复权价格
因为复权后价格才有涨跌的可比性,所以做量化策略时通常会使用复权价格。
我们来编写代码计算复权价格。
在一段时间周期内可能会经历多次复权,因此要先计算出累计复权因子。
累计后复权因子用cp_b表示,它的计算公式为:今日cp_b=昨日cp_b/今日pfactor
累计前复权因子用cp_f表示,它的计算公式为:昨日cp_f=今日cp_f*今日pfactor
用代码写出来是这样的:
A |
|
1 |
>call("init.splx") |
2 |
600000 |
3 |
2024-01-01 |
4 |
2024-12-31 |
5 |
=Load(A2,A3,A4) |
6 |
=A5.(pfactor) |
7 |
=A6.(if(#==1,cp_b=1,cp_b=cp_b/~)) |
8 |
=A6.rvs().(if(#==1,cp_f=1,cp_f=cp_f*~[-1])).rvs() |
A2:A5 读取一支股票数据
A6 取出pfactor的值返回为序列,A.()是循环函数在2.3小节讲过。
A7 循环A6,依次计算每日的累计后复权因子。
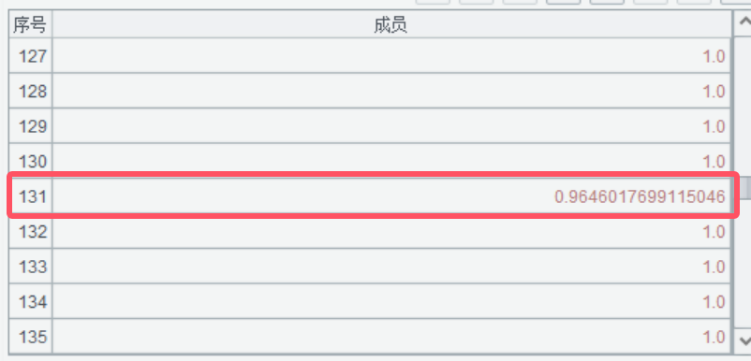
在这句代码中出现了两个特殊符号#和~,这也SPL特有的发明,用在循环函数中,~表示正在参与计算的那个序列成员,#则表示该序列成员的序号。例如当A6循环到上图红色框标记的位置时,对应的~值就是成员本身0.9646017699115046,#值就是该成员的序号131。#和~是所有循环函数的统一规则,很常用,读者要熟练掌握。
再来看if(a,b,c)函数,它表示如果a的表达式结果为真,就返回b,反之返回c。
理解了这两点,A7格里代码就容易理解了,循环A6,如果循环序号等于1,cp_b的值就设为1,反之,cp_b的值就设为cp_b/~,也就是公式里的昨日cp_b/今日pfactor。前面我们已经讲过了==是逻辑判断,=是赋值运算,这里又复习一遍。
理解了A7,A8就容易理解了。A8里~[-1]表示取前1个成员值,如当A6循环到上图红色框标记的位置时,对应的~[-1]就是前面1个成员的值1。类似的,还有~[1]表示取后1个成员。
在SPL里用~[i]来取向前第i个(i<0)或向后第i个(i>0)成员值,这也是循环函数的统一规则。
A8 循环A6,依次计算每日的累计前复权因子。
与后复权不同,前复权是从后往前复权,计算时需要从后往前算,因此要先用rvs()函数将A6倒序排列。然后就和后复权的代码类似,带入公式计算即可。计算完以后再用rvs()将顺序变回来。
有了累计复权因子,用复权因子乘以价格就是对应的复权价格了。
继续这段代码:
A |
|
… |
…… |
9 |
=A5.derive(open*A7(#):open_b,close*A7(#):close_b,low*A7(#):low_b,high*A7(#):high_b) |
10 |
=A5.derive(open*A8(#):open_f,close*A8(#):close_f,low*A8(#):low_f,high*A8(#):high_f) |
A9 计算后复权价格
A10 计算前复权价格
这两句代码虽长,但理解起来很容易,derive()也是循环函数,表示为序表添加衍生字段。冒号前面是字段表达式如open*A7(#),后面的是字段名如open_b。多个字段之间用逗号间隔。表达式open*A7(#)中,#号已经讲过了表示循环序号,A7(#)就表示取A7中相同位置的值,即取对应的累计复权因子值,然后再乘以开盘价open就是open的复权价格了,给其命名为open_b。以此类推计算出其他价格的复权价。
如A9返回后复权价格,可以看到历史价格不变,当前价格发生了改变
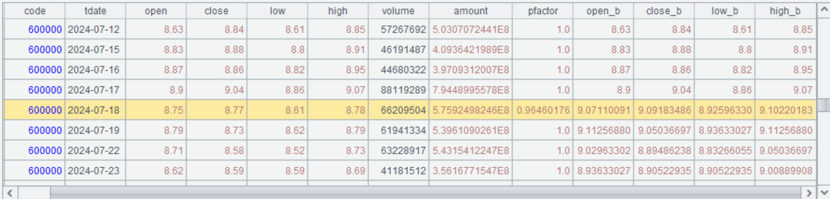
A10返回前复权价格,当前价格不变,历史价格发生了改变。
现在我们已经学会了如何计算单只股票的复权价格,那么多支股票的复权价格该如何计算呢。
显而易见还是用循环,循环每支股票一支一支的算。
代码可以这么写:
A |
B |
C |
|
1 |
[300632,301115,603216] |
||
2 |
2024-01-01 |
||
3 |
2024-12-31 |
||
4 |
=Load(A1,A2,A3) |
||
5 |
=A4.group(code) |
||
6 |
for A5 |
=A6.(pfactor) |
|
7 |
=B6.(if(#==1,cp_b=1,cp_b=cp_b/~)) |
||
8 |
=B6.rvs().(if(#==1,cp_f=1,cp_f=cp_f*~[-1])).rvs() |
||
9 |
=A6.derive(open*B7(#):open_b,close*B7(#):close_b,low*B7(#):low_b,high*B7(#):high_b) |
>B1|=B9 |
|
10 |
=A6.derive(open*B8(#):open_f,close*B8(#):close_f,low*B8(#):low_f,high*B8(#):high_f) |
>C1|=B10 |
|
A1:A4 读取多支股票数据
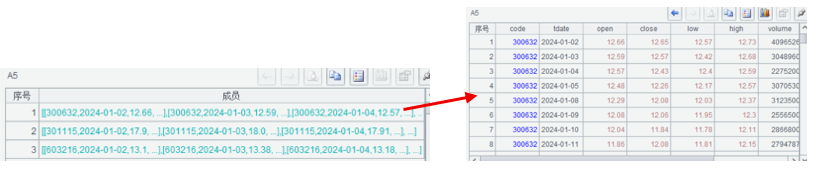
A5 将股票数据按code分组,结果返回序列。
group是分组函数,这句代码表示将序表A4根据字段code进行分组,相同code的记录会被分为一组。结果返回的是一个两层结构的数据,外层是序列,如左图可以看到数据被分为了3个组;内容则是每个组成员的内容,是序表,如双击第1个组,可以看到其内容是股票300632的数据。这种交互式的数据显示方式也是SPL的优点之一,我们可以边看边写。
A6:C10 循环每个组,计算每支股票的复权价格。
A6这种有 for 的格子,称为循环格。A6 的代码块,也就是要被重复执行的代码,称为 A6的循环体。而 A6 本身又称为这个循环的循环变量。for A5就是会循环A5的内容,这里A5是一个序列,会依次循环A5的每个成员。那么循环每个序列成员做什么呢,会执行循环体里的计算,也就是B6:C10的内容(蓝色框)。
这里提到了代码块的概念,在SPL里任何一个单元格,如果它的下面及下面的左边都是空的,那么它的右边和右边下面格子构成的块状区域称为它的代码块。例如A6的代码块是B6:C10。
了解了代码块的概念,红色和蓝色框里的程序结构就清晰了。
蓝色框里B列的代码就是前面计算单只股票的代码,照搬过来就是。
那么C9和C10的代码是什么呢?
在SPL里以>开头的单元格称为执行格,以=开头的称为计算格。计算格将计算 = 后面的表达式,把结果填入当前单元格。而执行格将执行 > 后面的动作,并不会给当前单元格填入任何值。上面代码执行完后,再看C9和C10的值仍然是空的。
C9中的B1|=B9,是B1=B1|B9的简写,表示把B1|B9的结果赋值给B1。符号|是和列运算,表示将B9并到B1后面。循环体每次计算的是一支股票,因此要用C9和C10这样的语句把每次循环结果写出来,合并到一起。
代码运行完之后,B1和C1返回就是多支股票的复权数据。
3.3 复权脚本
这段代码虽然可以正确的计算复权数据,但是使用起来并不太方便,比如有时候我们只需要后复权价格,有时候只需要前复权价格,每次都要先读数再计算太麻烦。而且有些不需要的信息也没必要返回,计算效率上也还可以再优化。
由于开发策略总会用到复权后的数据,极少用到不复权的数据,所以我们替干脆把复权动作附加到读数脚本上,完善上一章的loadkday.splx,让它在读数后顺便把复权也做了。这样可以通过参数设置来选择返回哪种价格。
首先还是定义脚本参数,在之前基础上增加一个参数opt表示返回的复权选项和中文显示,修改后脚本参数如下:
opt |
复权选项。缺省是前复权;”b”:后复权;”o”:未复权;”p”:保留复权因子;”C”:字段名为中文 |
cl |
股票代码序列,如[600000,600001];可以为单值,如600000;也可以填空表示全读 |
start |
开始日期,如2024-01-01 |
end |
截止日期,如2024-12-31。end为空时截止到当前日期 |
因为我们在后面做策略时更常用前复权的数据,所以这里把前复权设置成为了缺省情况。
脚本代码:
A |
B |
C |
|
1 |
=if(ifv(DATAPATH),DATAPATH,"") |
||
2 |
=pos(opt,"o") |
=pos(opt,"b") |
=pos(opt,"p") |
3 |
=start |
=ifn(end,now()) |
|
4 |
=to(year(A3),year(B3)).(file(A1/~/".trade.btx")).select(~.exists()) |
||
5 |
=cl=if(ifa(cl), cl.sort(),cl) |
||
6 |
=if(cl, A4.( ~.iselect@b(cl,code)), A4.(~.cursor@b()) ) |
||
7 |
=A6.merge(code,tdate).select(tdate>=A3 && tdate<=B3) |
||
8 |
=A7.fetch@x() |
||
9 |
if !A2 |
for A8.group(code) |
=B9.(pfactor) |
10 |
=if(B2,C9.(if(#==1,cp=1,cp=cp/~)), C9.rvs().(if(#==1,cp=1,cp=cp*~[-1])).rvs()) |
||
11 |
=B9.run(cp=C10(#), open*=cp, close*=cp, low*=cp,high*=cp ) |
||
12 |
|||
13 |
="code,tdate,open,close,high,low,volume,amount"+if(C2,",pfactor") |
||
14 |
=A8.new(${A13}) |
||
15 |
if pos(opt,"C") |
>A14.rename( code:代码,tdate:日期,open:开盘,close:收盘,high:最高,low:最低,volume:成交量,amount:成交额 ) |
|
16 |
return A14 |
||
A1引用了一个变量DATAPATH,它存储的是股票数据文件所在的路径。这句代码的意思是:如果DATAPATH存在,则A1的计算结果是DATAPATH本身,否则是空串。ifv()函数用来判断参数中的变量是否存在,存在返回true,反之false。A1的计算结果将在A4中使用,如果DATAPATH存在,则会被拼到其中file函数的文件名参数前面,以保证数据能被正确访问到;如果DATAPATH不存在,则拼上空串,脚本则仍会像之前那样到主路径去寻找数据文件。这样就不必一定总依赖于主路经,数据文件可以相对灵活的存放,甚至存放多套,只要在脚本中将DATAPATH设置成不同的值就能正确访问。后面很快我们会讲如何设置变量DATAPATH,这里先理解变量的作用。
A2 查看字符"o"是否在参数opt中出现过。pos()是位置查找函数,同样这里我们也只关心它是不是null,后续用A2判断是否用了某种选项。
B2 同样,查看字符"b"是否在opt中出现。
C2 查看字符"p"是否在opt中出现。
A3:B8 照搬读数脚本,暂不解释,直接拿来用
A9:C11 由if语句及其代码块构成。
在 if 后面跟一个逻辑表达式。如果if 的条件成立,则执行 if 所在格的代码块;不成立则跳过代码块。if语句是程序语言的另一种结构,分支结构,它和循环结构for语句一样,十分常用,必须掌握。
这里用if !A2来判断是否执行复权计算。SPL中约定,逻辑运算时,非空值和true等同,空值null和false等同。如果opt参数中含有“o”,A2是一个非空值,那么!A2就是false,SPL就会跳过代码块,返回原始数据;如果opt参数中不含“o”,A2则是null,!A2就是true,SPL将执行代码块。
if后面的复权代码块我们也进行了优化,C10中增加了一层if()函数,通过判断B2的值来判断计算前复权还是后复权。如果opt为”b”,B2值为true,计算后复权因子;如果opt为空,B2值为false,则计算前复权因子。C11则将原来的derive函数改为了run函数,A.run()也是循环函数,但不同的是它会直接在源数据上进行修改,计算效率更高。
A13:A14 返回需要的字段,new()和derive()使用方法相同,区别是new()是新表不会保留原字段。new()里参数${}是宏,使用宏可将A13中的字符串作为表达式参与计算。这里先不用管宏的语法规则,在后面讲到指标开发时还会详细解释。
A15:B15 如果参数opt中含有C,则将字段名改为中文。rename函数可以修改字段名,将冒号前面的改为冒号后面的。
A16 将A14的结果返回。
修改后脚本"loadkday.splx"可以自由选择返回股票的前复权、后复权以及不复权数据。
例如,计算浦发银行2024年的复权价格:
A |
B |
|
1 |
600000 |
股票代码 |
2 |
2024-01-01 |
开始日期 |
3 |
2024-12-31 |
截止日期 |
4 |
=call("loadkday.splx",,A1,A2,A3) |
“opt”参数为空,返回前复权数据 |
5 |
=call("loadkday.splx","b",A1,A2,A3) |
返回后复权数据 |
6 |
=call("loadkday.splx","o",A1,A2,A3) |
返回未复权数据 |
7 |
=call("loadkday.splx","bp",A1,A2,A3) |
读取后复权数据并保留复权因子 |
我们把修改后的脚本重新在init.splx脚本中登记,然后用函数名调用。
A |
|
1 |
>env(DATAPATH,"D:/量化/stock/") |
2 |
>register@o("Load", "loadkday.splx") |
3 |
>register("Draw", "draw.splx") |
A1 定义全程变量DATAPATH,我们前面已经讲过它的作用。当设置了DATAPATH后,脚本里就会用绝对路径读数。读者在这里需要将DATAPATH的变量值修改成自己的存储路径。
A2 将复权脚本登记为函数,并将第一个参数设为选项.
register添加@o选项,表示将脚本作为函数调用时,会把第一个参数作为函数选项。如"loadkday.splx"的第一个参数opt为复权类型,使用register@o()登记为函数后,opt参数值将作为函数选项使用,这样写法就更方便。
例如:
A |
B |
|
1 |
>call("init.splx") |
执行初始化脚本 |
2 |
600000 |
股票代码 |
3 |
2024-01-01 |
开始日期 |
4 |
2024-12-31 |
截止日期 |
5 |
=Load(A2,A3,A4) |
读取前复权数据 |
6 |
=Load@b(A2,A3,A4) |
读取后复权数据 |
7 |
=Load@o(A2,A3,A4) |
返回未复权数据 |
8 |
=Load@bp(A2,A3,A4) |
读取后复权数据并保留复权因子 |
9 |
=Load@C(A2,A3,A4) |
字段名显示为中文 |
如A5-A9格代码,通过设置不同选项返回不同数据。
运行效果:
A5 前复权
A6 后复权
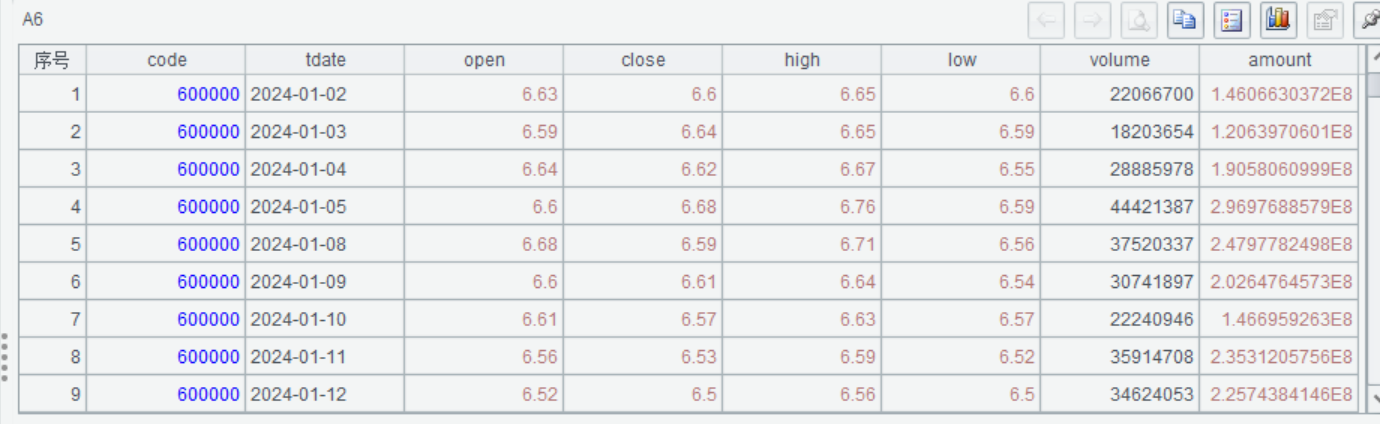
A7 未复权
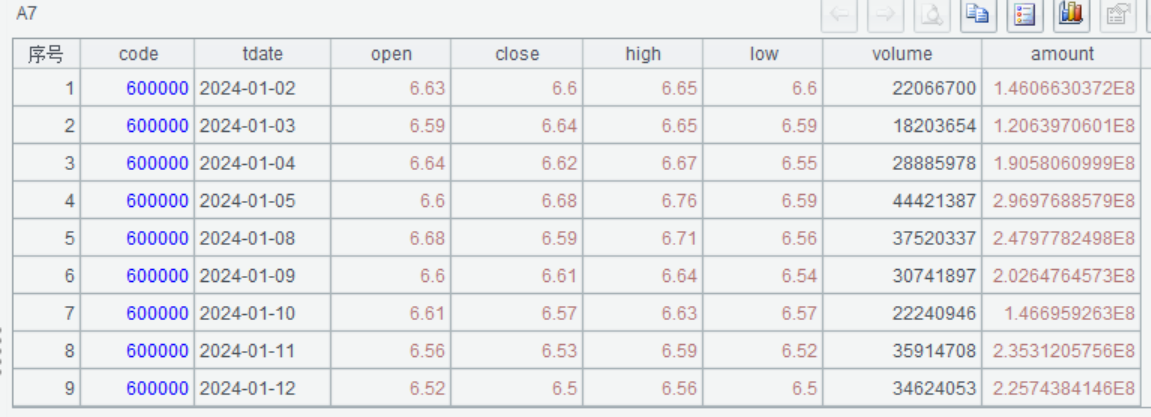
A8 后复权保留复权因子
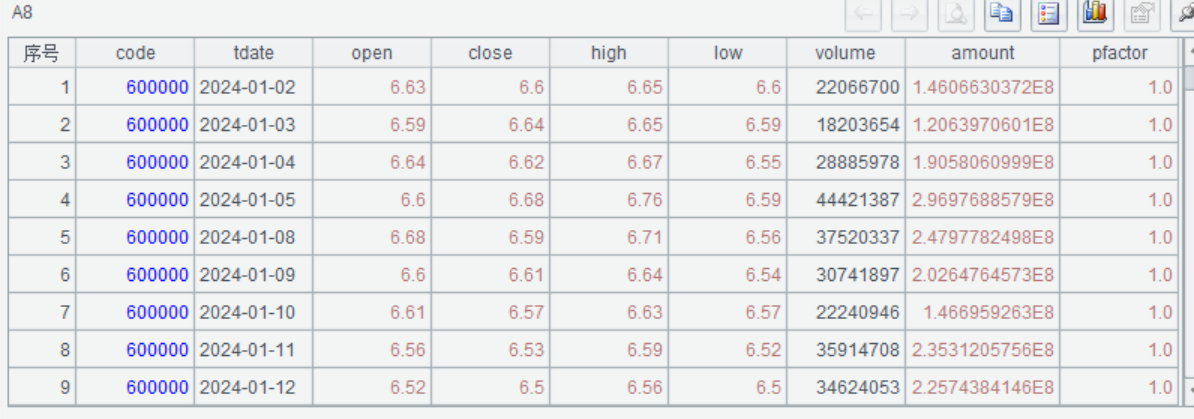
A9 中文显示
我们还可以通过图形来观察复权前后的数据。
编写代码:
A |
|
1 |
>call("init.splx") |
2 |
|
3 |
600000 |
4 |
2024-01-01 |
5 |
2024-12-31 |
6 |
=Load(A3,A4,A5) |
7 |
=Load@b(A3,A4,A5) |
8 |
=Load@o(A3,A4,A5) |
9 |
=A8.join(tdate, A6:tdate, close:close_f; tdate, A7:tdate, close:close_b) |
10 |
=Draw(A9,"tdate","close,close_f",,"600000_f.html") |
11 |
=Draw(A9,"tdate","close,close_b",,"600000_b.html") |
A1 将用到的脚本登记为函数
A3:A8 读取复权和未复权数据
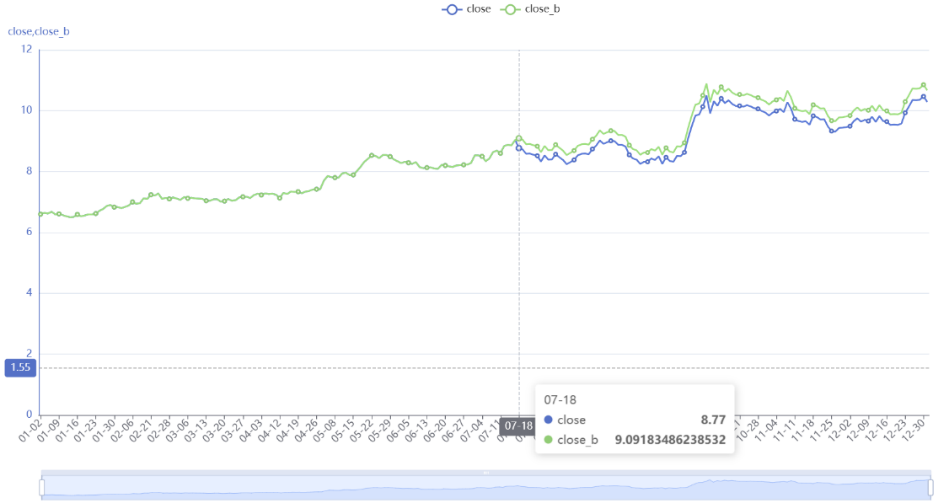
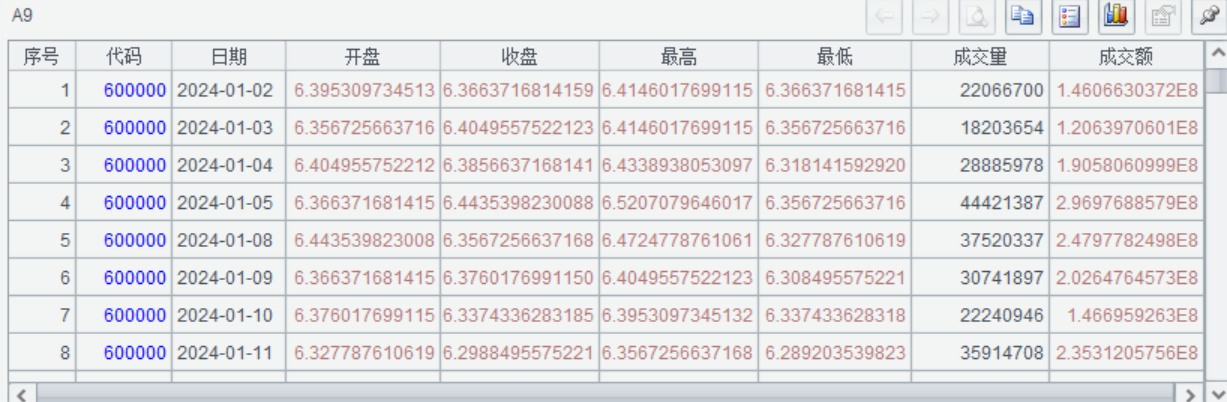
A9 将前复权和后复权数据分别按照tdate拼接到A8上。函数join()可以将一个或多个序表按照指定字段关联到A上,结果返回新序表。这句代码中join的参数较长,我们以分号为间隔分两部分来看,先看第分号前面的部分tdate, A6:tdate, close:close_f,第1个tdate是A8的关联字段,第2个tdate是A6的关联字段,close是A6里要拼接的字段表达式,:close_f表示将字段名设为close_f,因此分号前面这部分的代码就表示将A8的tdate和A6的tdate进行关联,并将A6中的字段close命名为close_f拼接到A8上。同理分号后面的部分tdate, A7:tdate, close:close_b就表示将A8的tdate和A7的tdate进行关联,并将A7中的字段close命名为close_b拼接到A8上。拼接完效果如下图。
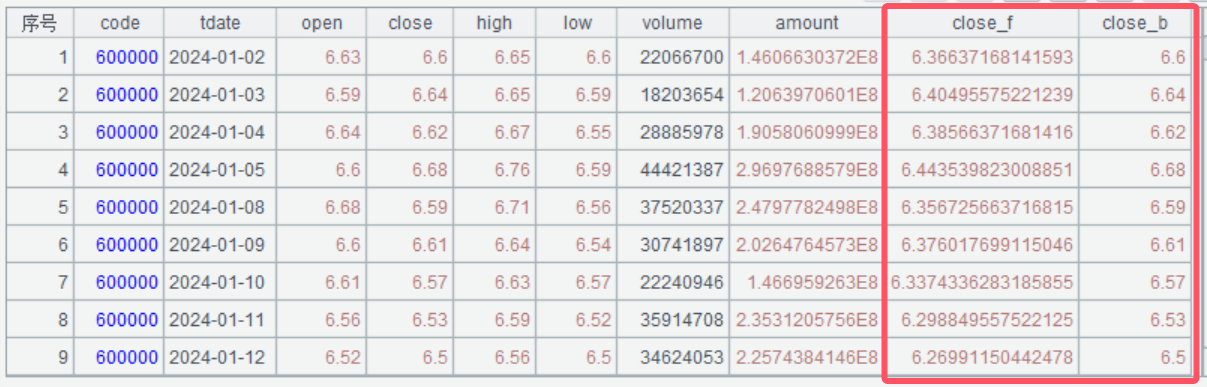
A10 调用绘图脚本,对比收盘价和前复权收盘价。可以看到前复权和未复权数据当前价格相同,历史价格不同。
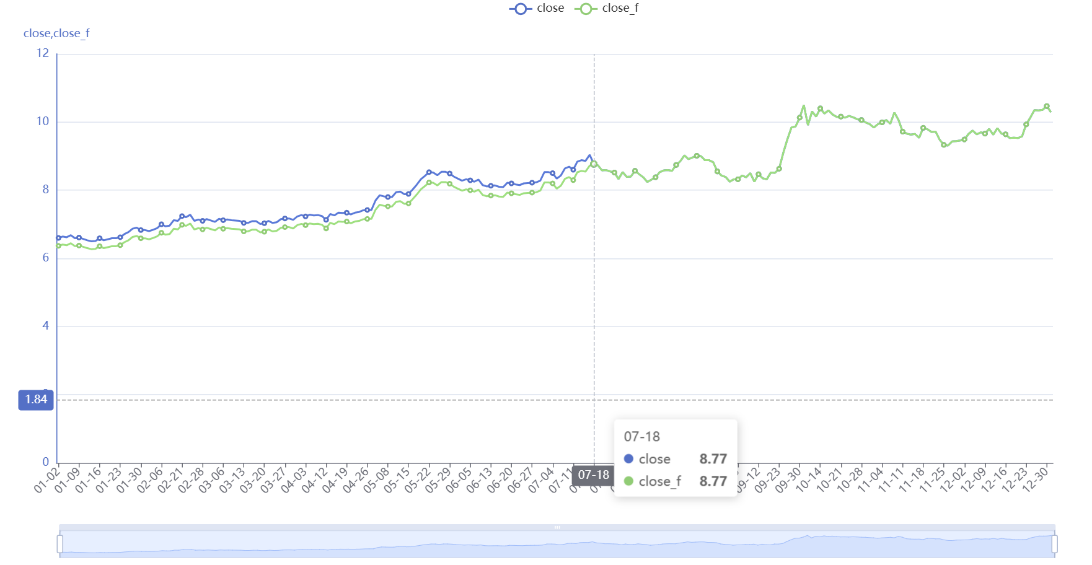
A11 对比收盘价和后复权收盘价,和前复权相反,历史价格相同,当前价格不同。