"= result = connect(“localhost”).query(finalSql,startTime, endTime) 在查询时,提前定义好 sql,然后将表名动态拼接后进行查询 .."
= result = connect(“localhost”).query(finalSql,startTime, endTime)在查询时,提前定义好 sql,然后将表名动态拼接后进行查询,会导致 cpu 飙升, 现在是在 for 循环中进行表名拼接然后查询
放在集算器单独运行 cpu 会到 40 左右,但是在报表内运行会直接到 100 多
在目前的使用中,用connect连接数据源,创建数据库连接后,执行query后,数据库连接无法关闭。query至少应该加个 @x 选项,在返回结果后关闭。更好的方式,应该在循环外用connect创建数据源连接,在循环中直接调用已有的连接执行query,在循环结束后,再调用con.close()关闭
另外,这里的循环有些奇怪,for A1 的处理中,每次都去给 result 赋值,这样循环本身就没太大作用了,result 只能保存最后一次循环时的结果了
大佬再帮我看一下,这是修改后的 spl,现在还是存在 cpu 飙到 100 的情况
那目前看,主要的运算其实就是在 mysql 中执行 query 取数,cpu 的消耗也就是 jdbc 的这个操作有可能有影响了。数据量很多的话,在取数并存储时也会涉及较多的数据处理。如果说报表明显比集算器的 cpu 消耗更大,那有可能是数据量很大引起的,报表比集算器更多的处理是需要把数据存储为报表数据集。
明白了,就是现在这个写法应该是没问题了,那我再从其他方面看看吧 大佬 谢谢





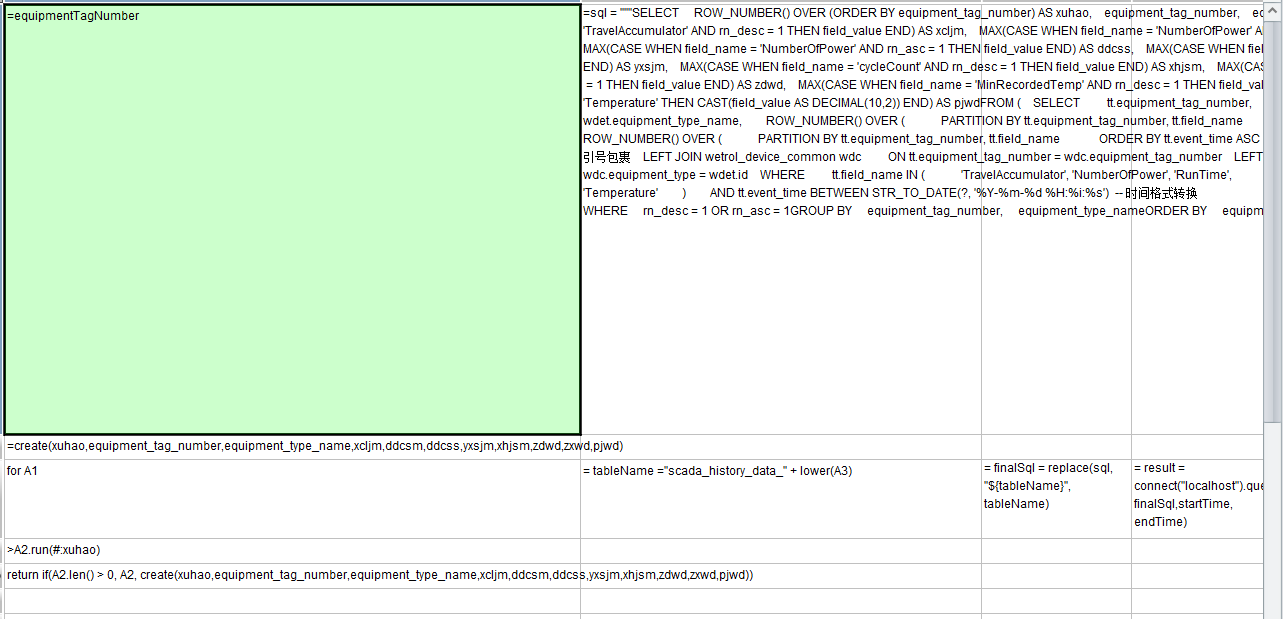

放在集算器单独运行 cpu 会到 40 左右,但是在报表内运行会直接到 100 多
在目前的使用中,用connect连接数据源,创建数据库连接后,执行query后,数据库连接无法关闭。query至少应该加个 @x 选项,在返回结果后关闭。更好的方式,应该在循环外用connect创建数据源连接,在循环中直接调用已有的连接执行query,在循环结束后,再调用con.close()关闭
另外,这里的循环有些奇怪,for A1 的处理中,每次都去给 result 赋值,这样循环本身就没太大作用了,result 只能保存最后一次循环时的结果了
大佬再帮我看一下,这是修改后的 spl,现在还是存在 cpu 飙到 100 的情况
那目前看,主要的运算其实就是在 mysql 中执行 query 取数,cpu 的消耗也就是 jdbc 的这个操作有可能有影响了。数据量很多的话,在取数并存储时也会涉及较多的数据处理。如果说报表明显比集算器的 cpu 消耗更大,那有可能是数据量很大引起的,报表比集算器更多的处理是需要把数据存储为报表数据集。
明白了,就是现在这个写法应该是没问题了,那我再从其他方面看看吧 大佬 谢谢