


第六篇 - 枚举字段条件过滤
枚举字段的取值是有限几种值,针对枚举字段 f 的过滤条件写成 f =v1 or f=v2 or…或者 f !=v1 and f !=v2 and…,也可能写成 in 或者 not in。数据库要用 f 与 n 个值比较计算,数据表较大的时候比较次数会很多,性能就会比较差,而且 n 越大性能越差。
如果在过滤的时候,能不再做比较,性能自然大幅提高。esProc SPL 提供的对位序列机制可以起到这样的作用。
下面通过订单表的例子来看怎样使用对位序列。先确定枚举字段的取值范围,字段 customer_id 有对应维表,取值范围已经确定了。字段 employee_id,employee_name 没有对应维表,需要预先遍历事实表 orders 确定取值范围,生成维表。这里假设没有 employee_id 这个字段,且雇员没有同名的。
前面第三篇已经生成了维表 employee.btx,orders 使用前面的 ordersQ3.ctx,employee 已序号化。
例 6.1 找出雇员是 name10 或 name101 的订单,按日期统计订单数。
select order_date,count(1)
from orders
where
employee_name='name10' or employee_name='name101'
group by order_date;
执行时间 20 秒。
SPL 代码 27:
A |
|
1 |
=now() |
2 |
=file("employeeQ6.btx").import@b() |
3 |
=A2.(["name10","name101"].contain(employee_name)) |
4 |
=file("ordersQ6.ctx").open().cursor@m(order_date;A3(employee_num)) |
5 |
=A4.groups(order_date;count(1)) |
6 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
执行时间 0.1 秒。
重点看 A3 利用过滤条件生成对位序列:
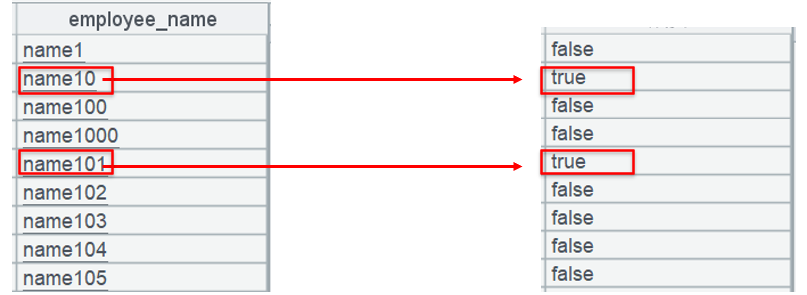
图中左边是 employee 表,右边是对位序列。
对位序列是和维表 employee 等长的布尔值序列。函数 contain 判断 [“name10”,“name101”] 是否包含当前位置 name 值,包含则对位序列同样位置的成员被赋值成 true,否则就是 false。
有了对位序列,A4 就可以用来过滤了:
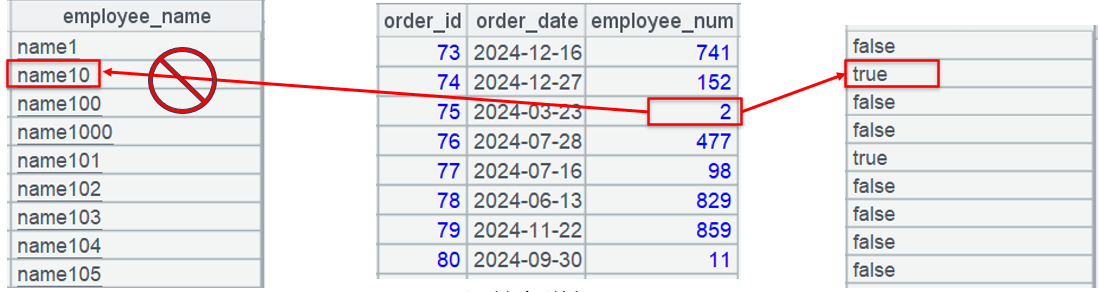
对订单表(图中间)过滤,常规计算是用 employee_num 去 employee 表(图左边)对应位置取 name,然后和 [“name10”,“name101”] 比较。
SPL 则用序号去对位序列(图右边)中取对应位置的布尔值,是 true 表示满足条件,否则就是不满足。这就不需要比较 name 了,把比较运算转化成了按位置取序列成员。
我们看不用对位序列的写法。
SPL 代码 28:
A |
|
1 |
=now() |
2 |
=file("ordersQ6.ctx").open().cursor@m(order_date;employee_name=="name10" || employee_name=="name101") |
3 |
=A2.groups(order_date;count(1)) |
4 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
A2 条件过滤需要比较字符串是否相同。
执行时间:0.1 秒
例 6.2 找出雇员是 name10 等 10 人的订单,按日期统计订单数。
这个例子要写 or 就有点多了,SQL 用 in 写:
select order_date,count(1)
from orders
where
employee_name in ('name10' , 'name101',…)
group by order_date;
执行时间 16 秒。
SPL 代码 29:采用对位序列的写法。
A |
|
1 |
=now() |
2 |
=file("employeeQ6.btx").import@b() |
3 |
=A2.(["name10","name101",…].contain(employee_name)) |
4 |
=file("ordersQ6.ctx").open().cursor@m(order_date;A3(employee_num)) |
5 |
=A4.groups(order_date;count(1)) |
6 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
执行时间 0.15 秒
代码在上面基础上增加待比较的雇员名即可。
SPL 代码 30:不使用对位序列。
A |
|
1 |
=now() |
2 |
=["name10", "name101", …].sort() |
3 |
=file("ordersQ6.ctx").open().cursor@m(order_date;A2.contain@b(employee_name)) |
4 |
=A3.groups(order_date;count(1)) |
5 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
执行时间:0.18 秒。
例 6.3 找出客户城市编号是 35 的订单,统计总运费。
SQL 要使用子查询:
select sum(shipping_fee)
from orders
where
customer_id in (
select customer_id
from customer
where city_id=35);
执行时间:13 秒。
SPL 代码 31:使用对位序列。
A |
|
1 |
=now() |
2 |
=file("customerQ6.btx").import@b() |
3 |
=A2.(city_id==35) |
4 |
=file("ordersQ6.ctx").open().cursor@m(shipping_fee;A3(customer_num) ) |
5 |
=A4.total(sum(shipping_fee)) |
6 |
>output("query cost:"/interval@ms(A1,now())/"ms") |
执行时间 0.1 秒
SPL 代码 32:不使用对位序列。
A |
|
1 |
=now() |
2 |
=file("customerQ6.btx").import@b().keys@i(customer_id) |
3 |
=A2.select@i(city_id==35) |
4 |
=file("ordersQ6.ctx").open().cursor@m(shipping_fee;customer_id:A3) |
5 |
=A4.total(sum(shipping_fee)) |
执行时间:0.1 秒。
用 cutomer_id 主键查找计算和按位置取成员的差别不明显。
性能小结:
MYSQL |
SPL对位序列 |
SPL不用对位序列 |
|
例 6.1 |
20 |
0.1 |
0.1 |
例 6.2 |
16 |
0.15 |
0.18 |
例 6.3 |
13 |
0.1 |
0.1 |
请动手练习:
1、找出客户城市编号是 3 的订单,统计总订单数。
2、思考:在自己熟悉的数据库中有没有大表枚举字段过滤计算?是否可以用对位序列提速?

