


SPL 轻量级多源混算实践 7 - SQL 移植
应用程序可能要基于不同数据库工作,各种数据库的 SQL 语法大体一致,但仍有些差别,结果就要改造这些 SQL,而这事通常只能手工调整,工作量大还容易出错。
完全自动改造 SQL 几乎是无法做到的,毕竟各种数据库很可能功能就不一样。
不过,梳理一下会发现,大部分问题都是由于 SQL 函数写法不同造成的。
特别是日期和字符串相关的函数,业界没有标准,各个数据库各行其是。比如将字符串 "2020-02-05" 转换成日期,不同数据库有不同的写法。
ORACLE:
select TO_DATE('2020-02-05', 'YYYY-MM-DD') from USER
SQL Server:
select CONVERT(varchar(100), '2020-02-05', 23) from USER
MySQL:
select DATE_FORMAT('2020-02-05','%Y-%m-%d') from USER
如果希望应用在不同的数据库之间切换,就需要改写 SQL 语句。
SPL 方案
SPL 针对这个场景提供了 SQL 转换功能,可以将某种标准 SQL 转换成不同数据库对应的语句,从而完成数据库切换时 SQL 无缝移植。
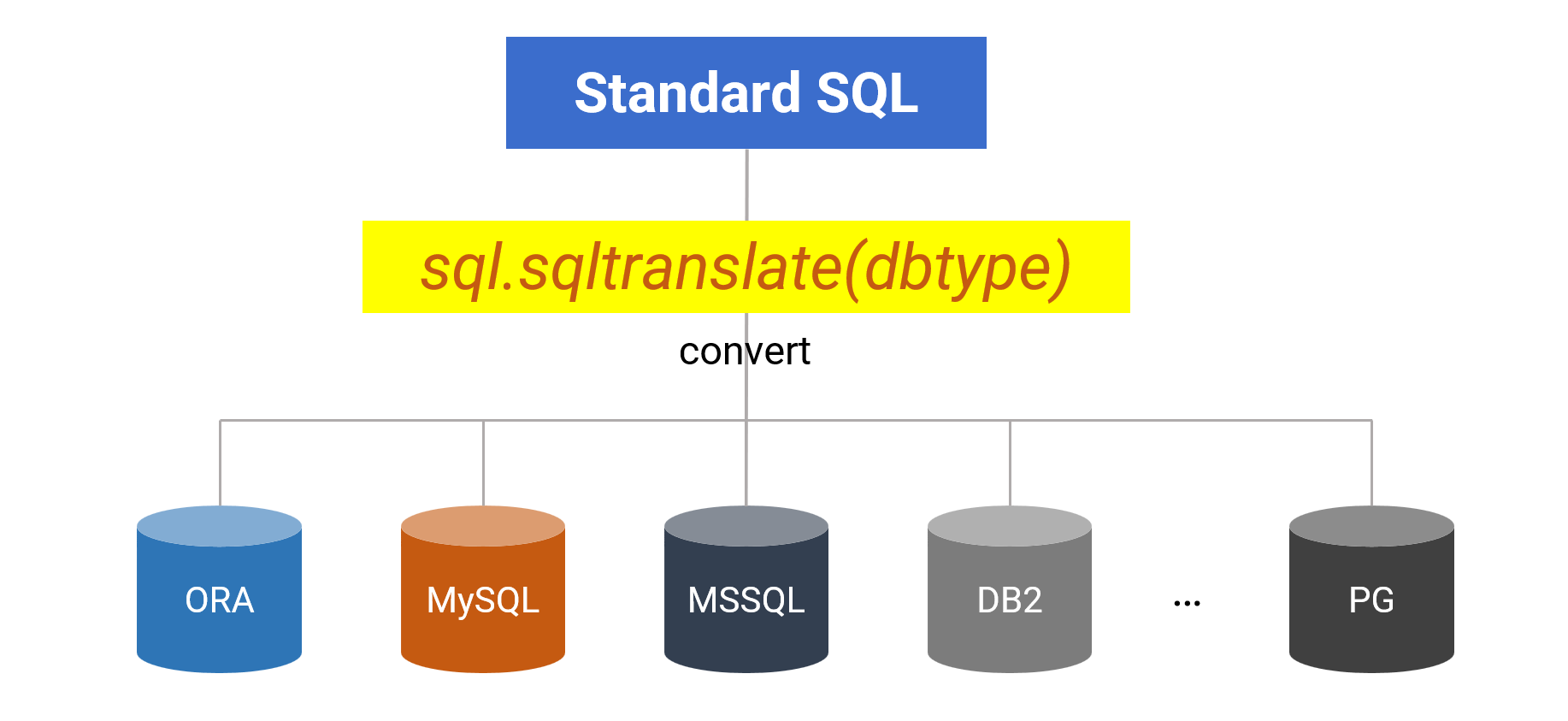
sql.sqltranslate(dbtype) 函数前面的 sql 是需要翻译的 SQL 语句,参数 dbtype 是数据库类型。函数要在 SPL 的简单 SQL 中定义过,未定义的不会被翻译。已定义的函数列表和数据库类型可查阅 sqltranslate 函数帮助:https://d.raqsoft.com.cn:6443/esproc/func/sqltranslate.html
IDE 内使用
我们先在 SPL 的 IDE 内尝试一下,将
SELECT EID, NAME, BIRTHDAY, ADDDAYS(BIRTHDAY,10) DAY10 FROM EMP
转换成不同数据库对应的语法。
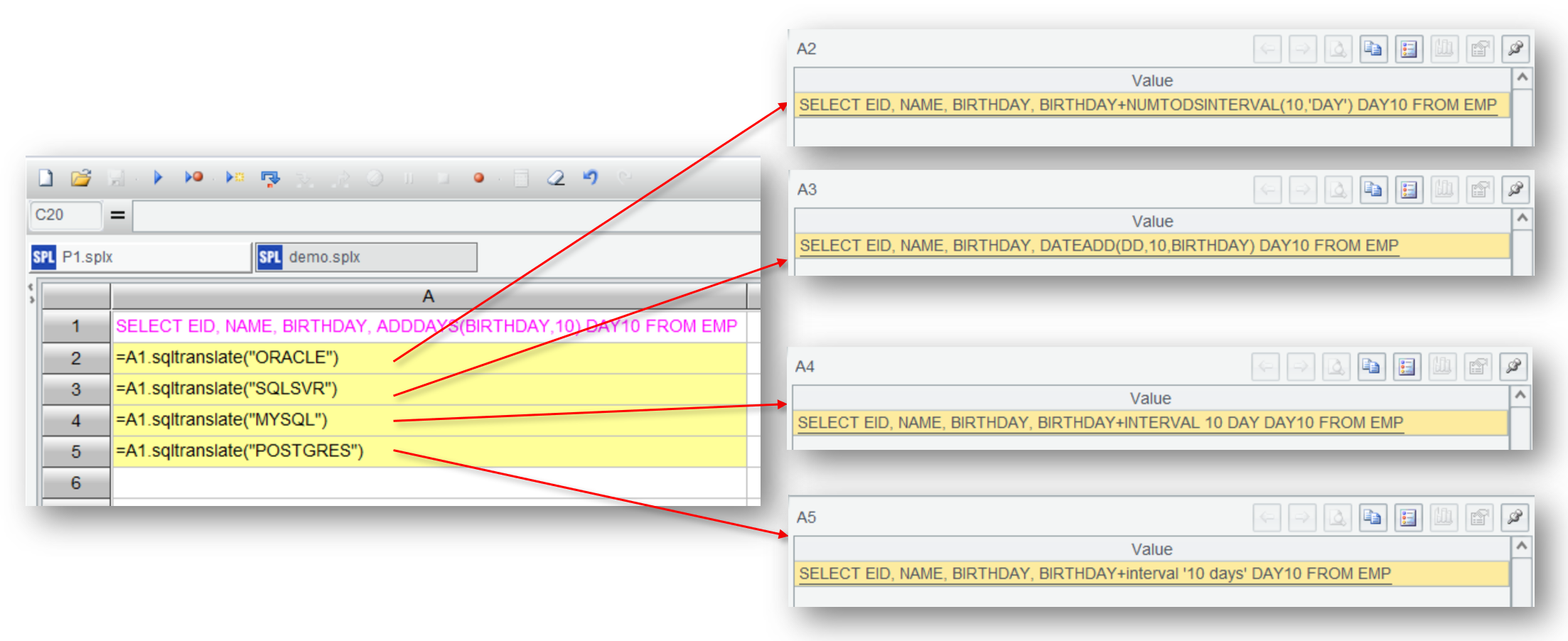
可以看到 ADDDAYS 这个函数被翻译成各个数据库不同的语法,实现了 SQL 在不同数据库之间移植。
我们再看一些例子。
月份加 10
SELECT EID, NAME, BIRTHDAY, ADDMONTHS(BIRTHDAY,10) DAY10 FROM EMP
通过 sqltranslate 翻译成不同数据库的语法:
ORACLE:
SELECT EID, NAME, BIRTHDAY, BIRTHDAY+NUMTOYMINTERVAL(10,'MONTH') DAY10 FROM EMP
SQLSVR:
SELECT EID, NAME, BIRTHDAY, DATEADD(MM,10,BIRTHDAY) DAY10 FROM EMP
DB2:
SELECT EID, NAME, BIRTHDAY, BIRTHDAY+10 MONTHS DAY10 FROM EMP
MYSQL:
SELECT EID, NAME, BIRTHDAY, BIRTHDAY+INTERVAL 10 MONTH DAY10 FROM EMP
POSTGRES:
SELECT EID, NAME, BIRTHDAY, BIRTHDAY+interval '10 months' DAY10 FROM EMP
TERADATA:
SELECT EID, NAME, BIRTHDAY, ADD_MONTHS(BIRTHDAY, 10) DAY10 FROM EMP
ADDMONTHS 函数在不同数据库的实现方式差异很大,SQLServer 有 DATEADD 函数,而 MySQL 和 PG 则直接加,Oracle 则采用两者相结合的方式实现。
求季度
SELECT EID,AREA,QUARTER(ORDERDATE) QUA, AMOUNT FROM ORDERS
转换后:
ORACLE:
SELECT EID,AREA,FLOOR((EXTRACT(MONTH FROM ORDERDATE)+2)/3) QUA, AMOUNT FROM ORDERS
SQLSVR:
SELECT EID,AREA,DATEPART(QQ,ORDERDATE) QUA, AMOUNT FROM ORDERS
POSTGRES:
SELECT EID,AREA,EXTRACT(QUARTER FROM ORDERDATE) QUA, AMOUNT FROM ORDERS
TERADATA:
SELECT EID,AREA,TD_QUARTER_OF_YEAR(ORDERDATE) QUA, AMOUNT FROM ORDERS
求季度的函数,不同数据库虽然都有函数实现,但函数名称和参数的定义又有很大差异。
类型转换
SELECT EID, NAME, DATETOCHAR(BIRTHDAY) FROM EMP
转换后:
ORACLE:
SELECT EID, NAME, TO_CHAR(BIRTHDAY,'YYYY-MM-DD HH:MI:SS') FROM EMP
SQLSVR:
SELECT EID, NAME, CONVERT(CHAR,BIRTHDAY,120) FROM EMP
DB2:
SELECT EID, NAME, TO_CHAR(BIRTHDAY,'YYYY-MM-DD HH:MI:SS') FROM EMP
MYSQL:
SELECT EID, NAME, DATE_FORMAT(BIRTHDAY, '%Y-%m-%d %H:%i:%S) FROM EMP
POSTGRES:
SELECT EID, NAME, TO_CHAR(BIRTHDAY,'YYYY-MM-DD HH:MI:SS') FROM EMP
TERADATA:
SELECT EID, NAME, TO_CHAR(BIRTHDAY,'YYYY-MM-DD HH:MI:SS') FROM EMP
类型转换函数各个数据库的函数名称和格式化形式有较大差异。
这些五花八门的差异都可以用 SPL 的 sqltranslate 来转换。
函数定义与扩展
SPL 支持的数据库类型和函数定义在发布包 esproc-bin.jar 中的字典文件 /com/scudata/dm/sql/function.xml 中。
<?xml version="1.0" encoding="utf-8"?>
<STANDARD>
<FUNCTIONS type="FixParam">
<FUNCTION name="ADDDAYS" paramcount="2" value="">
<INFO dbtype="ORACLE" value="?1+NUMTODSINTERVAL(?2,'DAY')"/>
<INFO dbtype="SQLSVR" value="DATEADD(DD,?2,?1)"/>
<INFO dbtype="DB2" value="?1+?2 DAYS"/>
<INFO dbtype="MYSQL" value="?1+INTERVAL ?2 DAY"/>
<INFO dbtype="HSQL" value="DATEADD('dd', ?2, ?1)"/>
<INFO dbtype="TERADATA" value="?1+CAST(?2 AS INTERVAL DAY)"/>
<INFO dbtype="POSTGRES" value="?1+interval '?2 days'"/>
<INFO dbtype="ESPROC" value="elapse(?1,?2)"/>
</FUNCTION>
</FUNCTIONS>
</STANDARD>
FUNCTIONS 节点代表一个函数组,type 是函数组类型,FixParam 表示参数个数固定的函数组。FUNCTION 节点代表一个简单 SQL 函数,name 是函数名,paramcount 是参数个数,value 是翻译本函数时的默认值,空串时表示无需翻译。INFO 节点代表一种数据库,dbtype 是数据库名称,空串时表示是 SPL 中的简单 SQL,value 是翻译到本数据库时的对应值。value 中的? 或?1 代表函数的第 1 个参数值,?2 代表函数的第 2 个参数值,依此类推。当 INFO 中的 value 值为空串时,则使用父节点 FUNCTION 的 value 值。
在翻译时,如果 FUNCTION 节点下没有指定数据库的 INFO 节点定义,则此函数保持原样,不会被翻译。
SPL 在 funtion.xml 中定义了很多函数,但并不是所有。实际使用中可能碰到新的,可以自行增加。
比如我们要增加函数来计算两个日期的相差天数,我们就可以增加 FUNCTION 节点,定义 DATEDIFF 函数名,然后在 INFO 节点分别配置不同数据库的写法。
<FUNCTION name="DATEDIFF" paramcount="2" value="">
<INFO dbtype="ORACLE" value="?1-?2"/>
<INFO dbtype="SQLSVR" value="DATEDIFF(day,?1,?2)"/>
<INFO dbtype="MYSQL" value="DATEDIFF(?1,?2)"/>
<INFO dbtype="POSTGRES" value="?1-?2"/>
<INFO dbtype="ESPROC" value="interval(?2,?1)"/>
</FUNCTION>
类似地,如果还要增加对其他数据库的支持,直接增加 INFO 节点信息,把新数据库配置上就可以。比如这里要增加对 SQLite 的支持,来完成日期相差天数的翻译。
<FUNCTION name="DATEDIFF" paramcount="2" value="">
<INFO dbtype="ORACLE" value="?1-?2"/>
<INFO dbtype="SQLSVR" value="DATEDIFF(day,?1,?2)"/>
<INFO dbtype="MYSQL" value="DATEDIFF(?1,?2)"/>
<INFO dbtype="POSTGRES" value="?1-?2"/>
<INFO dbtype="ESPROC" value="interval(?2,?1)"/>
<INFO dbtype="SQLite" value="JULIANDAY(?1) - JULIANDAY(?2)"/>
</FUNCTION>
不固定个数参数情况
我们前面看到的都是函数参数个数固定的例子,但还有一些事先无法固定参数个数的情况,比如字符串连接,case when,以及取多个参数中的第一个非空值等。
SPL 对这种动态参数个数的情况也提供支持,将 FUNCTIONS 节点的 type 值配置成 AnyParam,也就是任意个数参数。
<FUNCTIONS type="AnyParam">
<FUNCTION name="coalesce">
<INFO dbtype="ESPROC" script='"ifn(" + ?.concat@c() +")"'/>
</FUNCTION>
<FUNCTION name="concat">
<INFO dbtype="ESPROC" script=' "concat("+ ?.concat@c() +")" '/>
<INFO dbtype="ORACLE" script=' ?.concat("||") '/>
<INFO dbtype="DB2" script=' ?.concat("||")'/>
<INFO dbtype="SQLSVR" script=' ?.concat("+")'/>
<INFO dbtype="POSTGRES" script=' ?.concat("||")'/>
<INFO dbtype="TERADATA" script=' ?.concat("||")'/>
<INFO dbtype="HSQL" script=' ?.concat("||")'/>
</FUNCTION>
</FUNCTIONS>
我们只需要在 FUNCTION 增加数据库类型和对应的翻译脚本(SPL 语法),比如要为字符串函数 CONCAT 增加对 Oracle 的支持,在 <FUNCTION name="concat"> 下添加如下内容:
<INFO dbtype="ORACLE" script=' "("+ ?.concat(" || ") +")" '/>
即可完成。
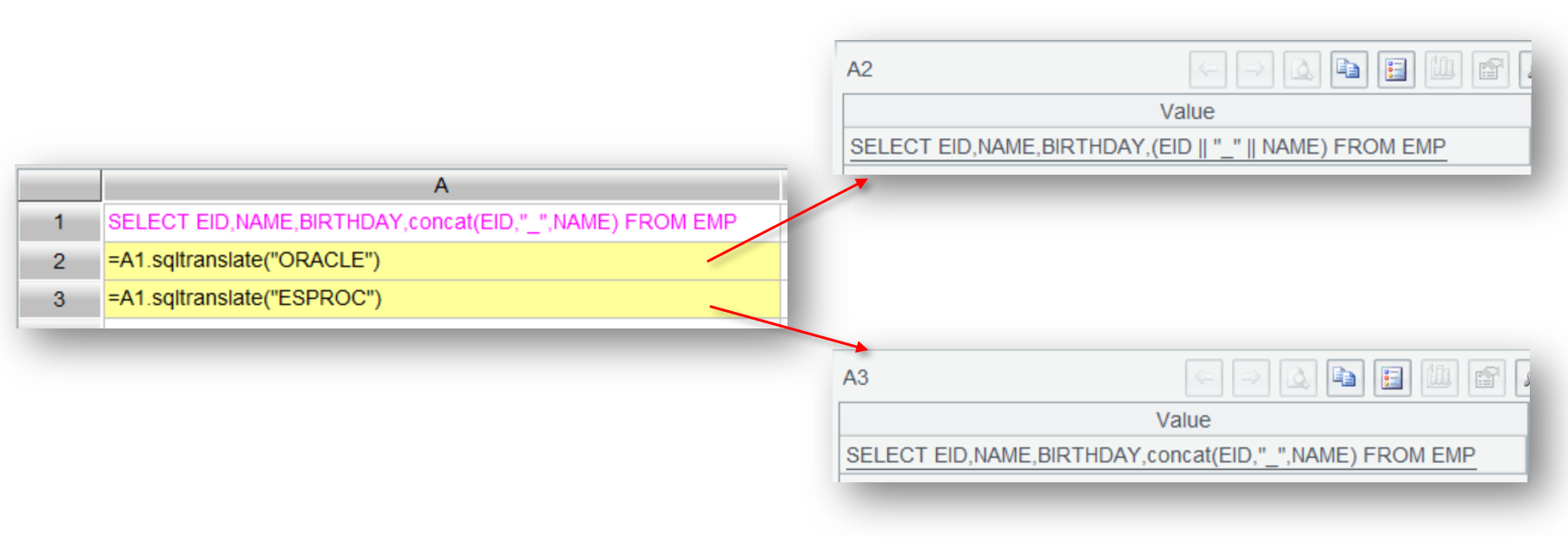
配置完后,当 SQL 语句:
SELECT EID,NAME,BIRTHDAY,concat(EID,"_",NAME) FROM EMP
数据库类型是 ORACLE 时会被翻译成:
SELECT EID,NAME,BIRTHDAY,(EID || "_" || NAME) FROM EMP
数据库类型是 ESPROC 时会被翻译成:
SELECT EID,NAME,BIRTHDAY,concat(EID,"_",NAME) FROM EMP
至此,我们已经学会了如何使用翻译函数,如何配置,以及如何新增函数和数据库,包括参数个数不定的情况。
与应用结合
仅用 SQL 翻译
在应用中使用 SPL 的 SQL 翻译功能,最简单的方式就是用 sqltranslate 把 SQL 翻译成目标数据库的语法后执行。
SPL 中翻译 SQL 的 API 是 com.scudata.dm.sql.SQLUtil.translate 函数,直接使用它就可以实现 SQL 语法的翻译。
String sql = "select name, birthday, adddays(birthday,10) day10 from emp";
sql = com.scudata.dm.sql.SQLUtil.translate(sql, "MYSQL");
不过,需要说明的是,SPL 官方并不推荐直接使用 API,而是建议使用 SPL 的 JDBC 接口,但仅仅为了个字符串转换动作而写好几行代码连接 JDBC 确实有点麻烦,所以我们直接使用了 API。
另外,我们希望把 SQL 移植做到尽量透明,除了首次改写,以后再换数据库无需再更改代码重编译,只要维护配置文件即可。因此,我们把数据库类型维护在配置文件中。
比如,我们增加数据库类型配置文件 dbconfig.properties ,里面配置数据库类型,如 MYSQL。
dbconfig.properties 内容:
database.type=MYSQL
然后封装一个翻译方法,调用 SPL 的 API 完成 SQL 翻译。
public static String translateSQL(String sql) {
String dbType = null;
try (InputStream input = SQLTranslator.class.getClassLoader().getResourceAsStream("dbconfig.properties")) {
Properties prop = new Properties();
if (input == null) {
System.out.println("Sorry, unable to find dbconfig.properties");
return null;
}
prop.load(input);
dbType = prop.getProperty("database.type");
} catch (Exception ex) {
ex.printStackTrace();
}
return SQLUtil.translate(sql, dbType);
}
主程序调用,传入 SQL 并调用 SQL 翻译,后面的代码与原来完全一致,包括设置参数、执行 SQL、获取结果集等等。事实上,主程序代码仅仅增加了一句 sql = translateSQL(sql) 。
public static void main(String[] args) {
……
String sql = “SELECT name, birthday, adddays(birthday,10) day10 “
+ “ FROM emp where dept=? and salary>?” ;
sql = translateSQL(sql);
pstmt.setString(1, "Sales");
pstmt.setDouble(2, 50000);
……
}
透明化并执行 SQL
前面的方法在调用时需要多做一步翻译,如果执行 SQL 的地方比较多,原程序的改动也会比较大。而且还使用了官方不推荐的接口,未来可能有不兼容的风险。
为了克服这些缺点,我们还可以采用更透明的方法,即把 SQL 翻译以及执行 SQL 获取结果集的动作也在 SPL 内完成。
SPL 提供了标准 JDBC 支持,不过与一般数据库 JDBC 不同,SPL 的 URL 允许传递参数,指定 jobVars 代表 SPL 中的任务变量(线程有效),这样我们可以为每次执行脚本传递数据源信息。比如:
url=" jdbc:esproc:local://? jobVars=dbType:MYSQL,dbName:mysqlds"
代表传递的是 MySQL 数据库类型,数据源名字是 mysqlds。
主程序只要将原来连接数据库的代码改成连接 SPL JDBC 并配上相应参数就行了代码:
public static void main(String[] args) {
Map<String, String> info = getDbInfo();
String driver = "com.esproc.jdbc.InternalDriver";
String url="jdbc:esproc:local://?jobVars=dbType:MySQL,dbName:mysqlds;
try {
System.out.println(url);
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
String sql = "SELECT orderid, employeeid, adddays(orderdate,10) day10,amount "
+ "FROM orders WHERE employeeid > ? AND amount > ?";
PreparedStatement st = conn.prepareStatement(sql);
st.setObject(1,"506");
st.setObject(2,9900);
ResultSet rs = st.executeQuery();
while (rs.next()) {
String employeeid = rs.getString("employeeid");
System.out.print(employeeid+",");
}
} catch (Exception e) {
throw new RuntimeException(e);
}
}
这里将数据源信息拼接到 URL 中。但这段代码中并没有翻译的过程,那是怎么实现 SQL 翻译的呢?看起来似乎有点神奇。
关键点在于 SPL 的 JDBC 网关。我们事先配置一个 SPL 脚本,JDBC 中执行所有 SQL 语句都会先交给这个脚本处理执行。也就是说,SQL 的翻译和执行都是在脚本中完成的。
要使用 JDBC 网关,需要在 raqsoftConfig.xml 中的 JDBC 节点配置 SPL 脚本,比如这里配置的 gateway.splx。
<JDBC>
<load>Runtime,Server</load>
<gateway>gateway.splx</gateway>
</JDBC>
网关脚本需要两个参数,一个 sql 参数用于接收 SQL 语句,另一个 args 参数则用于接收 SQL 语句中的参数,也就是 JDBC 给 SQL 传递的参数。
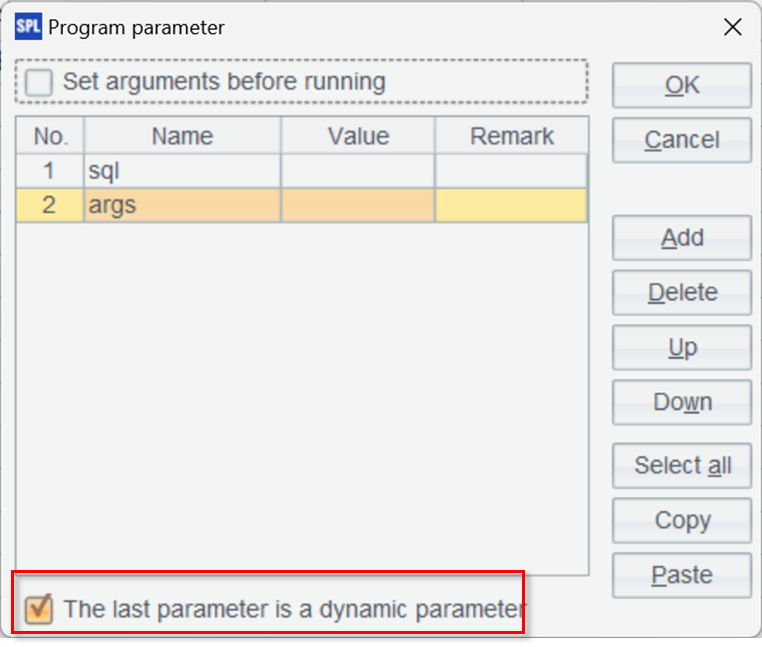
下面有个“最后一个参数是动态参数” 的选项 要勾选,这样才能接收到 SQL 语句的多个参数。
我们来看看脚本内容。
A |
B |
|
1 |
if !ifv(dbName) |
>call("initGlobalVars.splx") |
2 |
=sql=trim(sql).sqltranslate(dbType) |
|
3 |
=argsN=args.len() |
=("sql"|argsN.("args("/~/")")).concat@c() |
4 |
=connect(dbName) |
|
5 |
if pos@hc(sql,"select") |
return A4.query@x(${B3}) |
6 |
else |
=A4.execute(${B3}) |
7 |
>A4.close() |
A1 中判断 dbName 变量是否存在,如果不存在则在 B1 调用初始化脚本 initGlobalVars.splx:
A |
|
1 |
>env(dbType,file("dbconfig.properties").property("database.type")) |
2 |
>env(dbName,file("dbconfig.properties").property("database.name")) |
这个脚本读取配置文件中的数据源名称和数据库类型,用 ENV 函数放置在全局变量 dbType 和 dbName 中。
其中,配置文件 dbconfig.properties 内容:
database.type=MYSQL
database.name=MYDATASOURCE
A2 进行 SQL 翻译,这个方法大家已经不陌生了。
A3 计算参数个数。B3 将参数拼成一个串,比如两个参数的时候 B3 的结果是这样的。
A4 进行数据源连接,这个数据源是在 raqsoftConfig.xml 中配置的,增加 DB 节点配置相应数据源连接信息即可,多个数据源可以依次配置。
<DB name="MYDATASOURCE">
<property name="url" value="jdbc:mysql://127.0.0.1:3306/mydb?useCursorFetch=true"/>
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="type" value="10"/>
<property name="user" value="root"/>
<property name="password" value="root"/>
<property name="batchSize" value="0"/>
<property name="autoConnect" value="false"/>
<property name="useSchema" value="false"/>
<property name="addTilde" value="false"/>
<property name="caseSentence" value="false"/>
</DB>
A5 判断是否是 select 语句,我们要实现所有 SQL 的翻译和执行,而 DQL 和 DML 语句的执行方式不同,返回值也不同,所以要分别处理。
如果是 select 语句,B5 使用 db.query 函数进行查询并获得结果,@x 代表查询后关闭数据库连接。这里使用了 SPL 宏,宏替换的语句是这样。
A6 对于非 select 语句,需要使用 db.execute 函数执行 SQL 语句。
整体脚本并不是很复杂,而且以后修改脚本也不需要重启应用,因为 SPL 是解释执行的,支持热切换。
通过这个网关脚本,也可以执行 update 这类 DML 语句。
public static void main(String[] args) {
String driver = "com.esproc.jdbc.InternalDriver";
String url = "jdbc:esproc:local://";
try {
Class.forName(driver);
Connection conn = DriverManager.getConnection(url);
String sql = "update orders set customername = ? where orderid = ? ";
PreparedStatement st = conn.prepareStatement(sql);
st.setObject(1,"PTCAG001");
st.setObject(2,"1");
st.executeUpdate();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
我们在程序中执行 update 语句看一下,可以看到同样会被翻译成对应的数据库语句,并且更新成功。这意味着所有 SQL 都可以无缝移植。
这种方法同样适用于多个数据库的情况。
至此,我们实践完了 SPL 如何完成多源混算。诚然,这里并没有穷尽所有多源混算情况,但理解了 SPL 的运行原理,知道如何连接各类数据源,进行多源还是单源计算都是一样的了。

