


SPL 轻量级多源混算实践 6 - 跨库 JOIN
数据结构不一样的多源混合计算会更常见,比如不同业务系统混合分析。
数据结构说明
车辆管理系统(DB_Vehicle)保存了车辆与车主等相关信息,其中车主信息表 owner_info 表结构简化如下:

主键 owner_id 是车主身份证号。
车辆表 vehicle_master 简化结构如下:
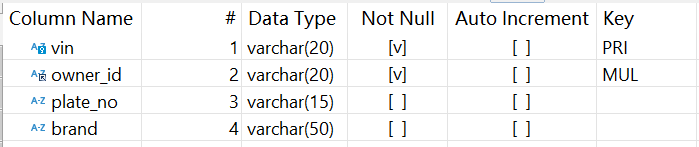
vin 设为主键,plate_no 也是唯一的,两个字段在逻辑上都可以视为主键。
交管系统(DB_Traffic)存储了车辆交通信息,其中违章记录表 traffic_violation 结构如下:
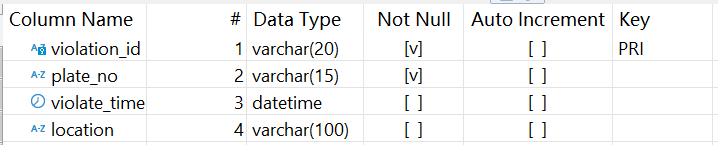
公民信息系统(DB_CitizenEvent)存储了公民相关信息,其中公民事件表 citizen_event 结构如下:
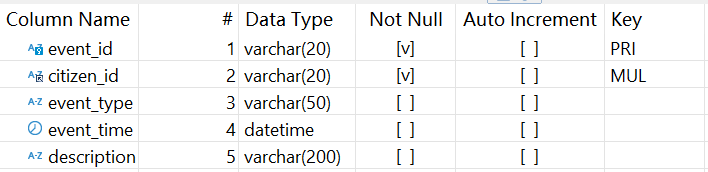
4 个表间逻辑关系简单描述是这样的:
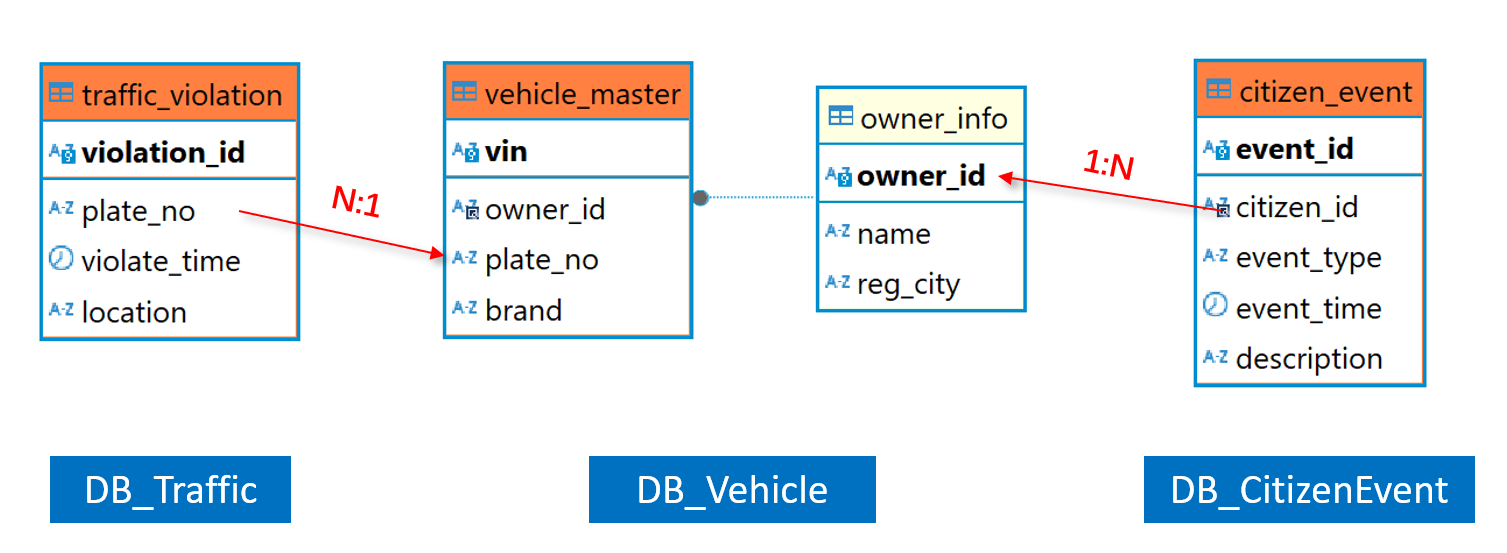
从逻辑上看,citizen_event 是 owner_info 是多对一的关系,作为维表的 owner_info 的规模要远小于 citizen_event。
traffic_violation 和 vehicle_master 这两个表也是一对多的关系,规模都可能很大,从后者的角度来看,traffic 更像一个子表,这两个表构成主子关系(plato_no 是 vehicle 表的逻辑主键)。
为什么要区分表间关系呢?
日常的等值 JOIN 基本都会涉及主键(多对多的关联基本没有业务意义),大体可以分为两种:维表关联是一种,是普通字段和维表的主键关联(如 citizen_event 和 owner_info);另一种是某个表的主键与另一个表的主键或部分主键的关联(如 vehicle_master 和 traffic_violation,traffic_violation 表中,可以把 plate_no 和 violation_id 视为共同主键,即 violation_id 是从属于 plate_no 的)。
SPL 在做 JOIN 运算时会根据不同的关联情况选择不同的方法,简化编码的同时还能提升计算效率。
配置数据源连接
vehicle:
jdbc:mysql://127.0.0.1:3306/db_vehicle?useSSL=false&useCursorFetch=true
traffic:
jdbc:mysql://127.0.0.1:3306/db_traffic?useSSL=false&useCursorFetch=true
citizen:
jdbc:mysql://127.0.0.1:3306/db_citizenevent?useSSL=false&useCursorFetch=true
计算用例
要做这样几个计算:
1. 按城市统计最近一年有车公民的事件数量,用于分析各城市有车人的“行为活跃度”
2. 找出近一年获得表彰(Commendation)的车主姓名和事件描述,用以识别“优秀市民”
3. 按年份和品牌统计车辆违章次数,用于分析某些品牌的车是否更容易违章,用于驾驶行为和车辆品牌的关联研究
下面来实现前面第一个计算需求:按城市统计最近一年有车公民的事件数量。要关联 owner_info 和 citizen_event 两个表,也就是维表的关联计算。
维表的关联
esProc 实现:
A |
|
1 |
=connect("vehicle") |
2 |
=A1.query@x("select * from owner_info").keys@i(owner_id) |
3 |
=connect("citizen") |
4 |
=A3.query@x("select * from citizen_event where event_time >= DATE_SUB(CURDATE(), INTERVAL 1 YEAR)") |
5 |
=A4.switch(citizen_id,A2) |
6 |
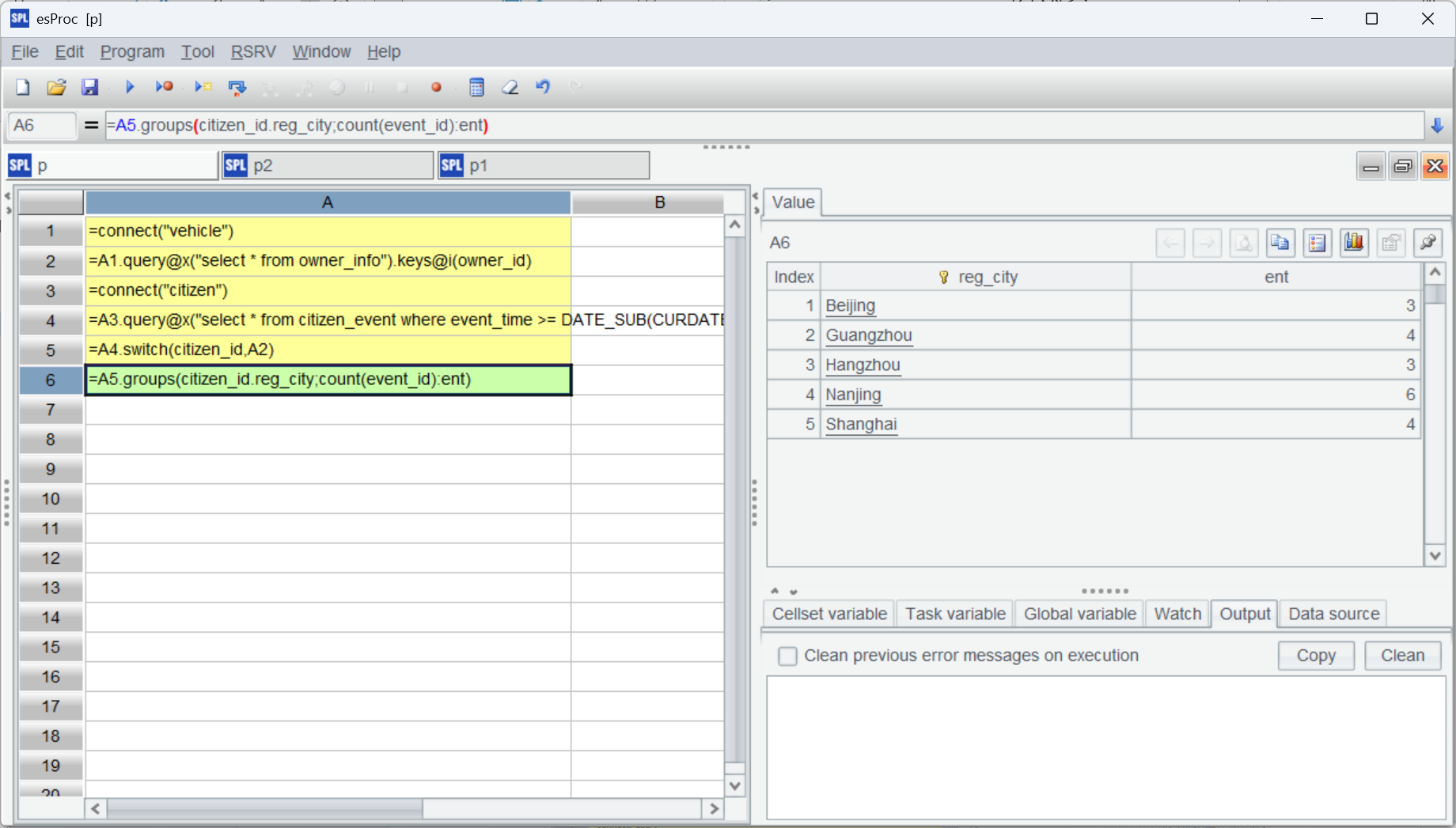
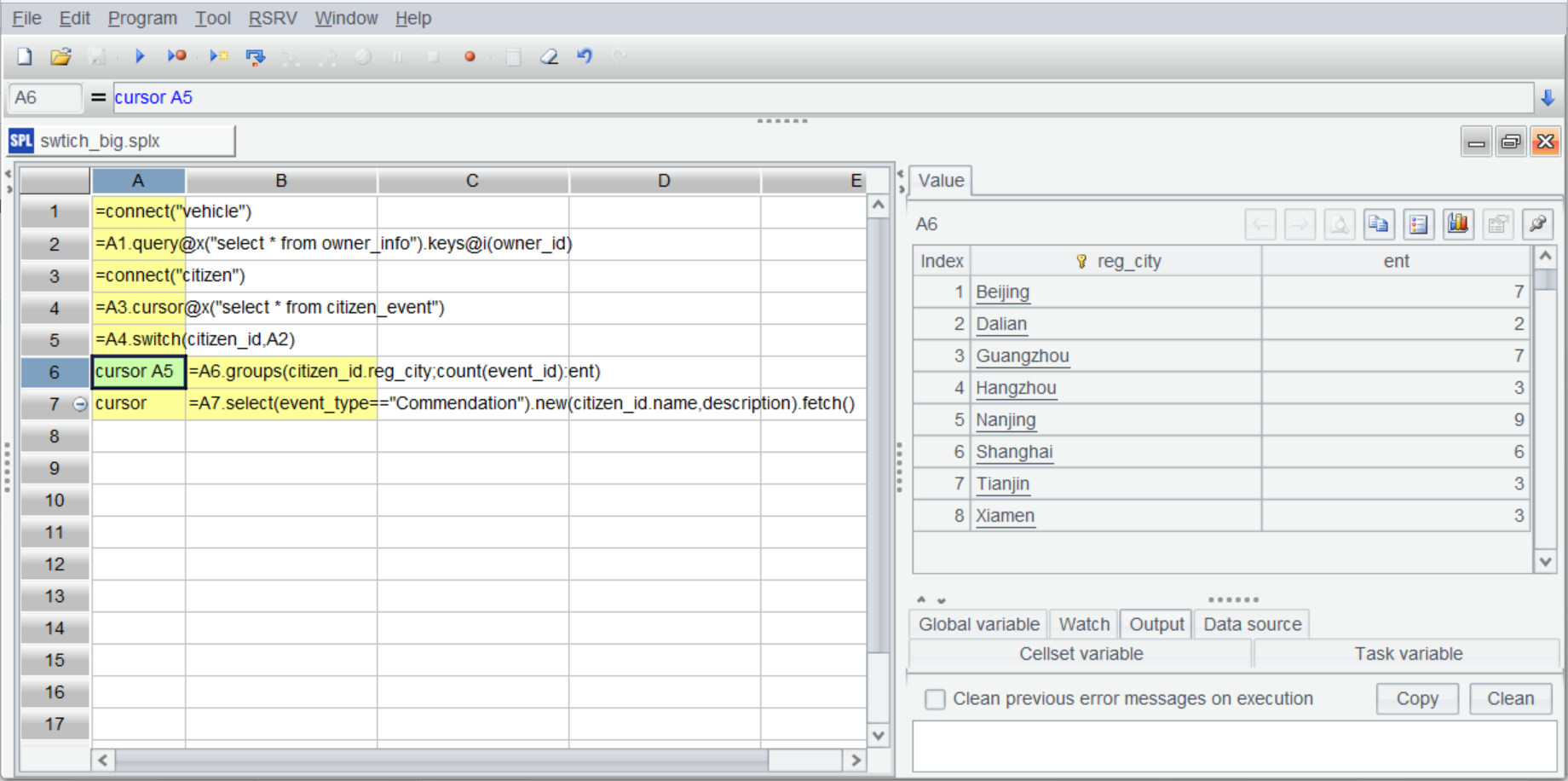
=A5.groups(citizen_id.reg_city;count(event_id):ent) |
A2 从 vehicle 库查询车主信息,query@x 表示数据全部加载内存后关闭数据库连接,使用 keys@i 设置主键并建立索引,通常事实表会远大于维表,这个索引会被复用很多次,能加快计算速度。
A4 查询事件表,筛选最近一年的数据,都读入内存。
A5 使用 switch 进行外键关联。由于外键指向的维表记录是唯一的,switch 直接将关联字段 citizen_id 转换成 A2 中的记录(实际在内存中存储的是维表记录所在地址)。
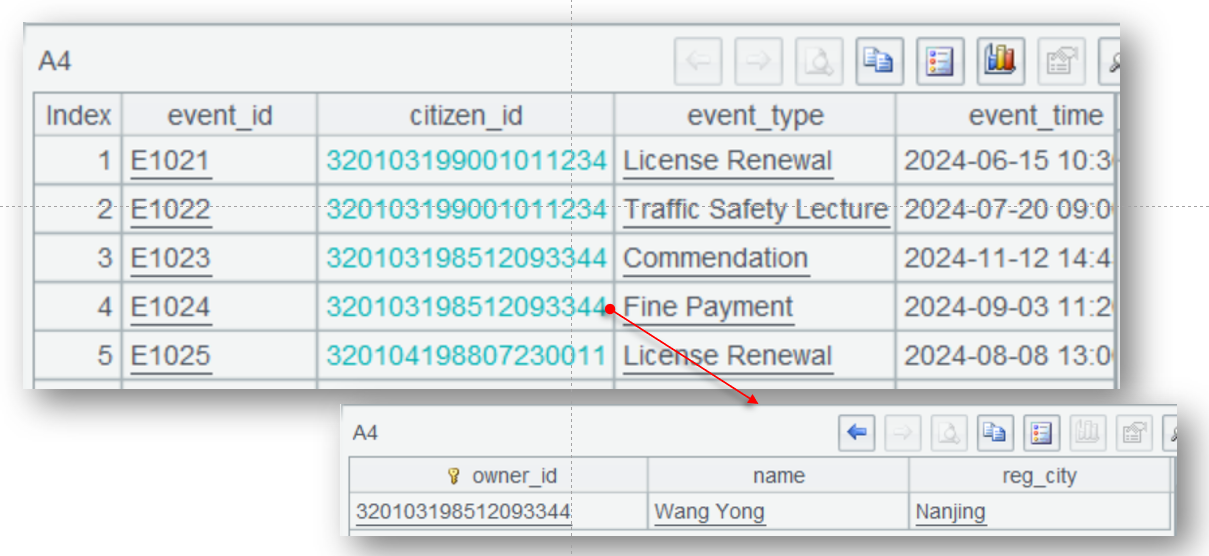
这种转换是一次性的,后续可以重复使用,而且可以同时处理多个维表的外键关联。关联完成后通过“关联字段. 维表字段”方式就能引用任意维表字段。A6 就通过 citizen_id.reg_city 获得注册地进行分组汇总。
整体运行如下:
接下来继续:找出近一年获得表彰的车主姓名和事件描述。
在前面代码的基础上增加:
A |
|
… |
… |
7 |
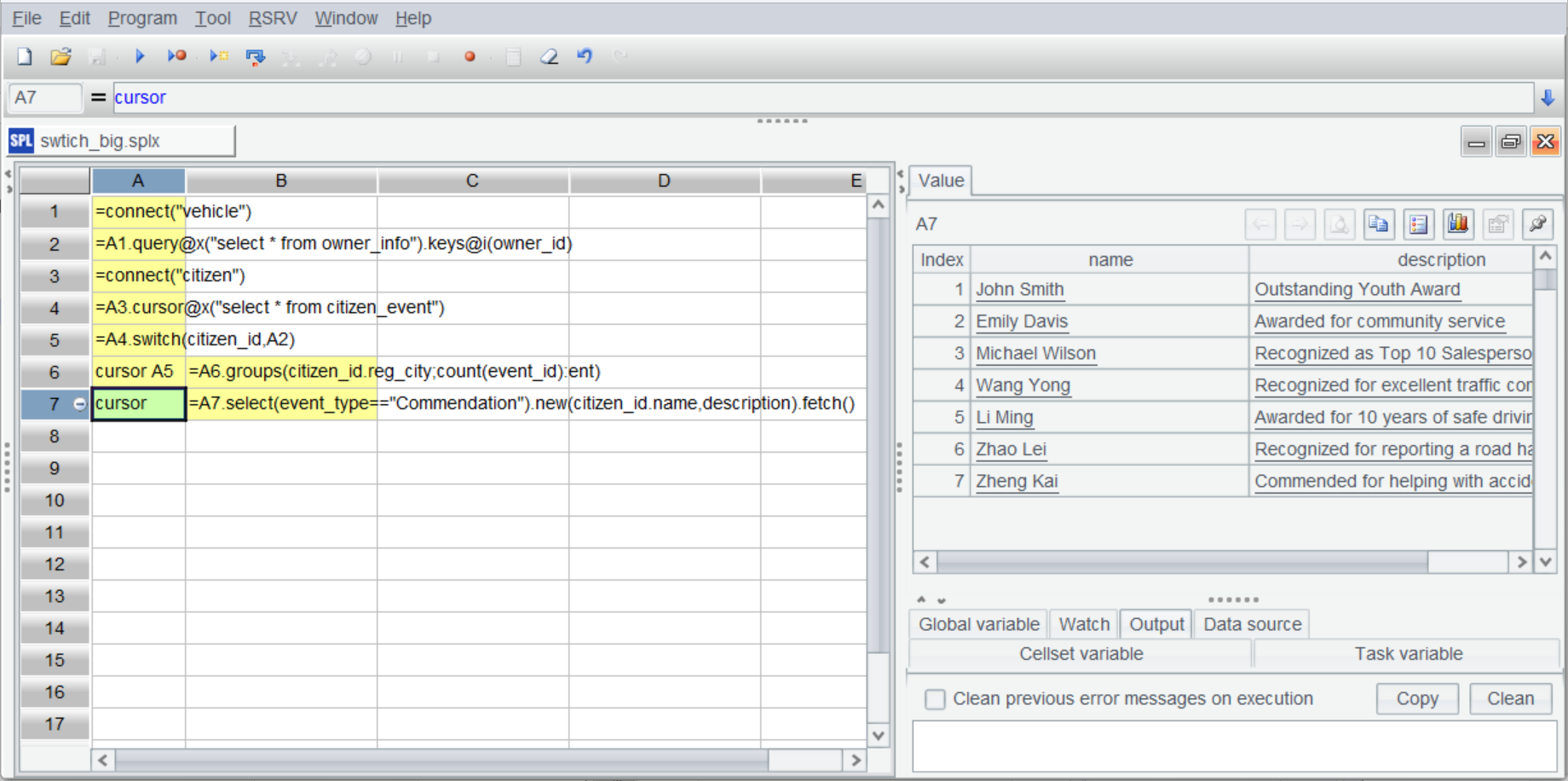
=A5.select(event_type=="Commendation").new(citizen_id.name,description) |
还是基于 A5 的关联结果进行计算,实现了复用。
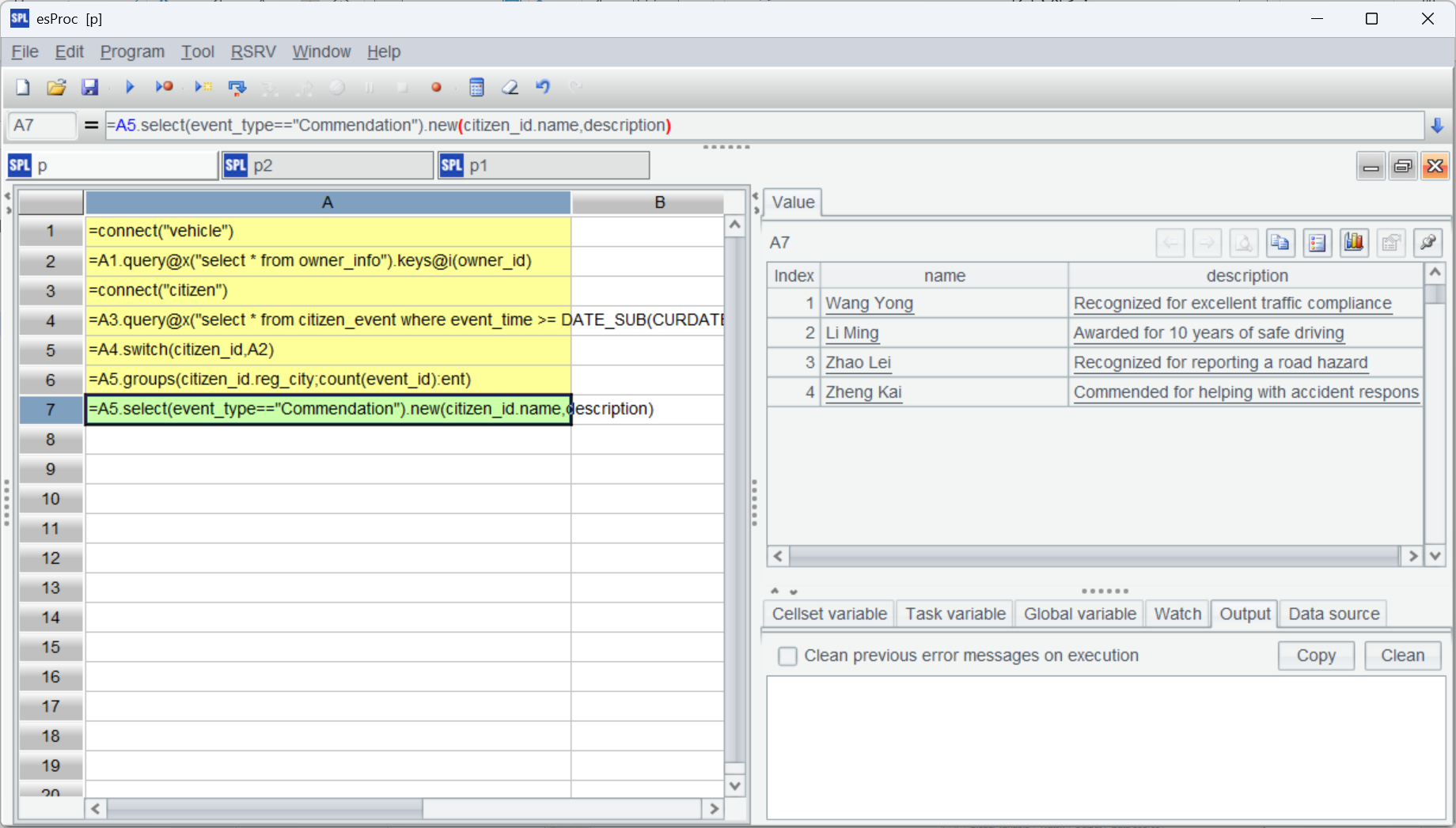
esProc 显著区分外键关系有很大好处,单从书写和理解上,通过点(.)操作符(类似对象. 属性)就能引用外键表的所有字段,有多少层都可以(维表还可能有维表),也很容易表达自关联 / 循环关联的情况。
当 citizen_event 表的数据量很大时,用 esProc 仍然可以处理。不过,当数据量大到无法全部放进内存时,内存地址化方法就不再有效了,因为在外存无法保存事先算好的地址,这时就只能边读入边地址化。
按城市统计所有车公民的事件数量:
A |
|
1 |
=connect("vehicle") |
2 |
=A1.query@x("select * from owner_info").keys@i(owner_id) |
3 |
=connect("citizen") |
4 |
=A3.cursor@x("select * from citizen_event") |
5 |
=A4.switch(citizen_id,A2) |
6 |
=A5.groups(citizen_id.reg_city;count(event_id):ent) |
与全内存的写法大部分一样,区别在 A4 使用 cursor 创建游标分批读取数据。esProc 的游标是延迟游标,附加在游标上的计算等到最后取数时才会真正计算。

但游标是一次性的,如果想再进行其他计算,比如还要获得表彰的车主。再基于 A5 计算是得不到结果的(注意 A7 的计算结果):
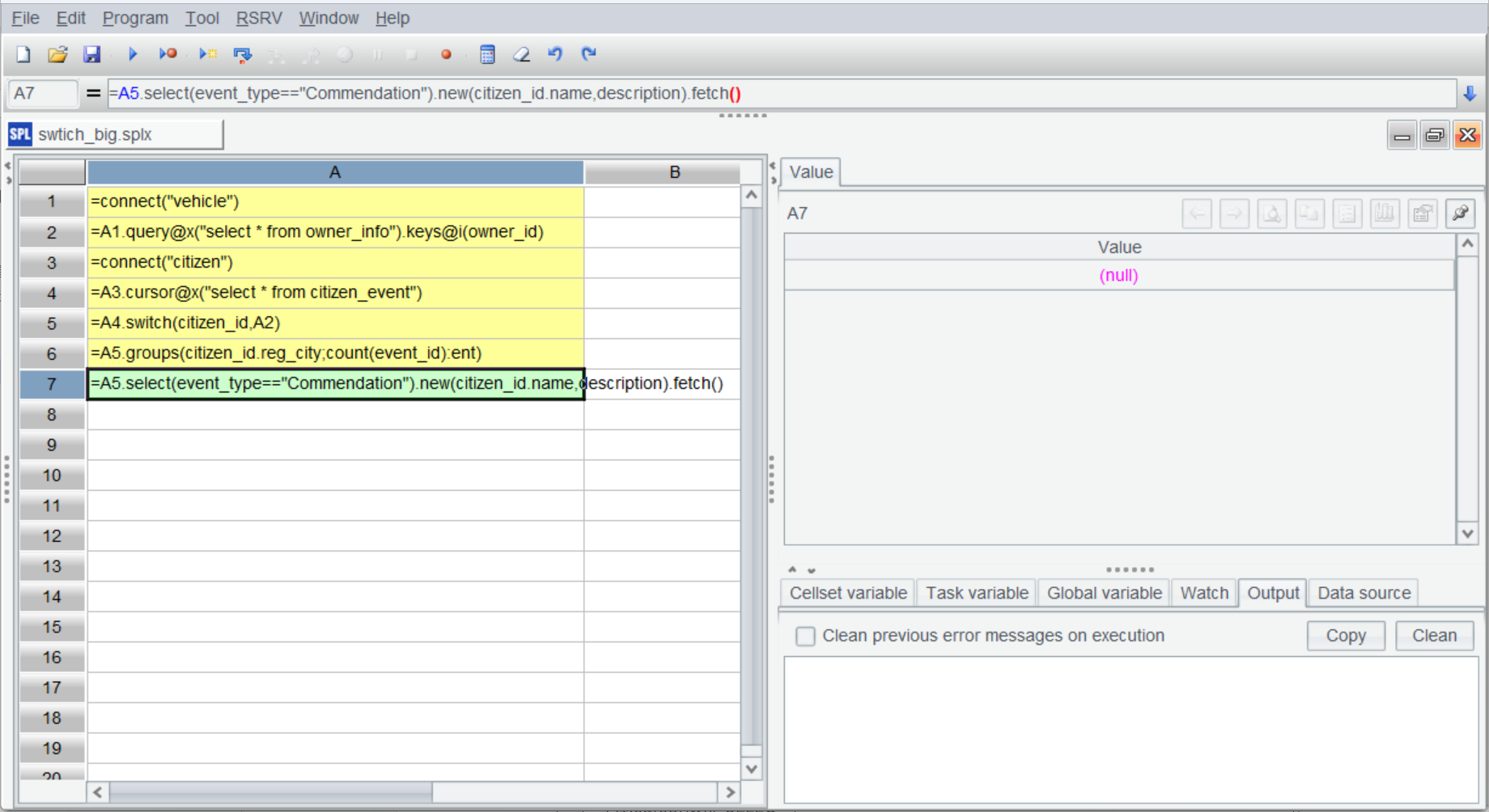
这时可以使用 esProc 提供的管道机制:
A |
B |
|
1 |
=connect("vehicle") |
|
2 |
=A1.query@x("select * from owner_info").keys@i(owner_id) |
|
3 |
=connect("citizen") |
|
4 |
=A3.cursor@x("select * from citizen_event") |
|
5 |
=A4.switch(citizen_id,A2) |
|
6 |
cursor A5 |
=A6.groups(citizen_id.reg_city;count(event_id):ent) |
7 |
cursor |
=A7.select(event_type=="Commendation").new(citizen_id.name,description).fetch() |
A6 和 A7 基于 A5 创建管道(A7 是简化写法),B6 基于管道进行分组汇总,结果返回给 A6:
B7 则根据另一个管道筛选获得表彰的数据,A7 的结果:
主子表的关联
按年份和品牌统计车辆违章次数。
A |
|
1 |
=connect("vehicle") |
2 |
=A1.query@x("select * from vehicle_master") |
3 |
=connect("traffic") |
4 |
=A3.query@x("select * from traffic_violation") |
5 |
=join(A2:v,plate_no;A4:t,plate_no) |
6 |
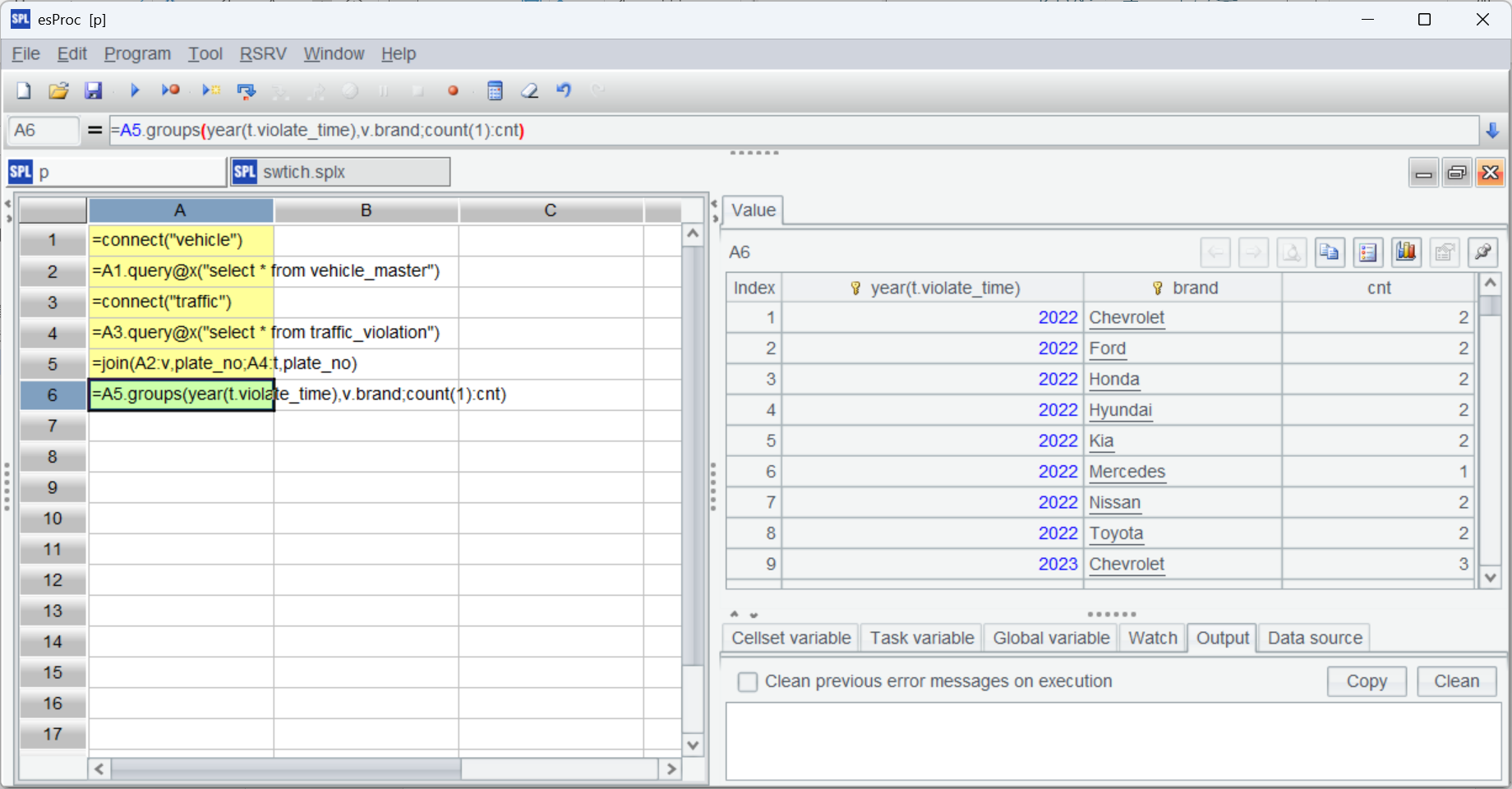
=A5.groups(year(t.violate_time),v.brand;count(1):cnt) |
A5 使用 join 函数根据 plate_no 关联了两个表,其关联结果是这样的:
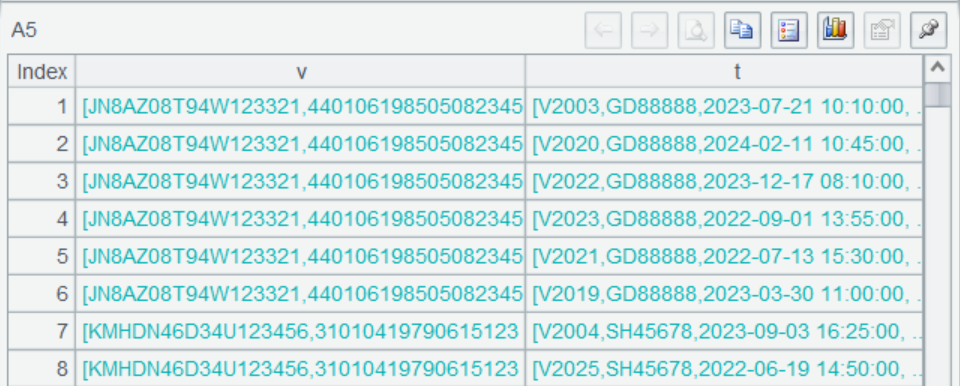
保留了两边完整记录的多层集合,点开可以看到
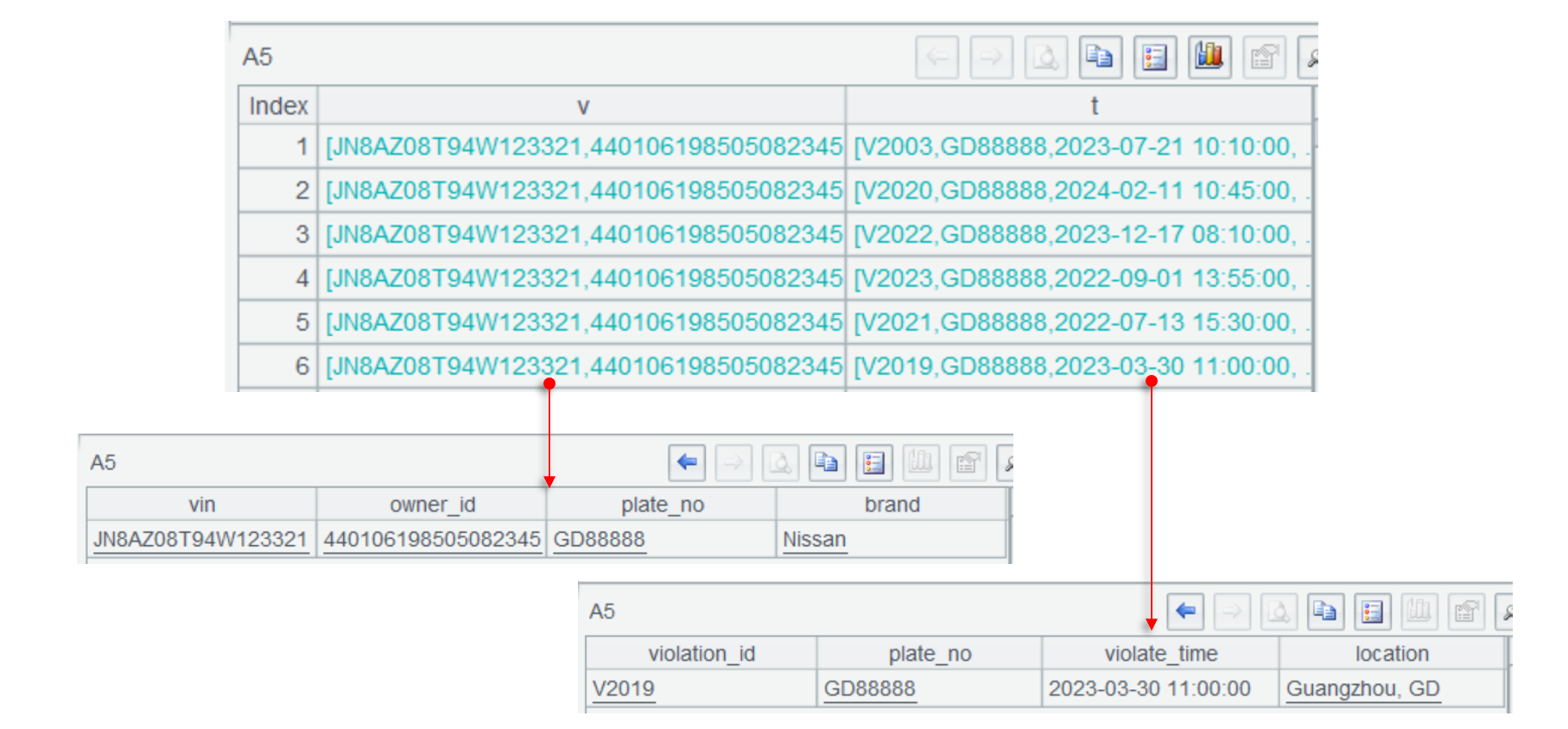
关联完成后,A6 就能通过多层引用进行分组汇总。
处理主子表关联时,我们使用了与外键关联 switch 不同的 join 函数,join 函数提供了一些选项,@1 表示左连接,@f 表示全连接,@d 做差集等,用来满足不同的连接需求。事实上,外键关联也可以使用 join 函数来完成。
那为什么不统一用 join 呢?
这里我们看到的都是两个表关联,如果存在多个维表(大部分情况),使用 switch 可以将维表(维表可能还有维表)都附加到事实表上,但用 join 就很难表达这种层次关系,书写也不方便。
主子表关联时的两个表可能都很大,利用表的关联字段都是主键(或部分主键)的特性,可以采用有序归并的算法一次遍历就完成关联。
按年份和品牌统计车辆违章次数:
A |
|
1 |
=connect("vehicle") |
2 |
=A1.cursor@x("select * from vehicle_master order by plate_no") |
3 |
=connect("traffic") |
4 |
=A3.cursor@x("select * from traffic_violation order by plate_no") |
5 |
=joinx(A2:v,plate_no;A4:t,plate_no) |
6 |
=A5.groups(year(t.violate_time),v.brand;count(1):cnt) |
A2 和 A4 使用 cursor 创建游标,里面的 SQL 都对 plate_no 排序。
A5 使用 joinx 做有序归并,返回的仍是游标。剩下的代码就跟全内存时一样了。
有序遍历利用了关联键有序的特性,只适用于主子表的关联(可对主键有序),但不适用于前面那种维表的外键关联。因为同一个表上可能有多个要参与关联的外键字段,不可能让同一个表同时针对多个字段都有序。这也是区分 JOIN 后采用了不同函数(算法)的原因。
再次强调,无论是跨库还是跨其他任何数据源,SPL 在处理时只要数据源能接入,后续计算都一样,因为 SPL 提供了统一的序表和游标数据对象。

