


轻量级文件计算技术,从此告别龟速报表
应用系统中的报表功能直接面对业务用户,太慢的报表会严重影响用户体验。报表的响应时间包括数据源计算取数时间和前端展现时间两部分,经验表明,大部分慢报表是数据库计算性能差造成的,和报表本身关系并不大。
传统数据库,特别是交易(TP)数据库,不擅长报表这种计算。TP 数据库的性能优化主要是提高事务处理和写操作(增删改)的效率,这和报表计算的优化方向并不一致,也就很难让计算跑的快。
把历史数据从 TP 数据库搬到专业 OLAP 数据仓库中计算,当然可以提高运算性能。不过这样做很麻烦,专业数仓太沉重,经常需要集群,硬件成本较高,还可能有昂贵的授权费用,更重要的是,整个技术架构也变得非常复杂。
实际上,报表涉及的历史数据大多数情况下是不再变化的,可以把历史数据搬出来,利用 SPL 的轻量级列存文件存储并实施计算,就可以获得轻量级的高性能解决方案了。
SPL 在列式存储、数据压缩、多线程并行等方面都做了深度优化,能让条件过滤、分组汇总这些常规运算的性能大幅提升,远超传统数据库,可以让原本龟速的报表变成火箭速度。SPL 还提供了更丰富的数据类型和基础运算,很容易写出低复杂度的简洁代码,可以用更小资源跑出甚至超过专业数据仓库的性能。
SPL 具备如此强大的计算能力,自身却非常轻,可以嵌入报表应用中,不会让系统架构变得复杂。主流报表工具润乾报表已经集成了 SPL,在提升性能的同时,系统架构依然简单:

比如下面这个订单报表,要在一千万行的订单表中过滤数据、分组汇总。用润乾报表连接 MYSQL 数据库,在“SQL 检索”数据集中写 SQL 来实现,报表网页的响应时间接近 11 秒,其中 10 秒以上都是 MYSQL 执行 SQL 的时间:
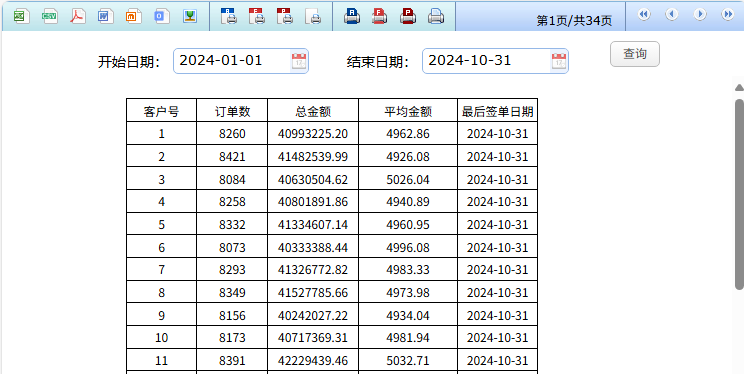
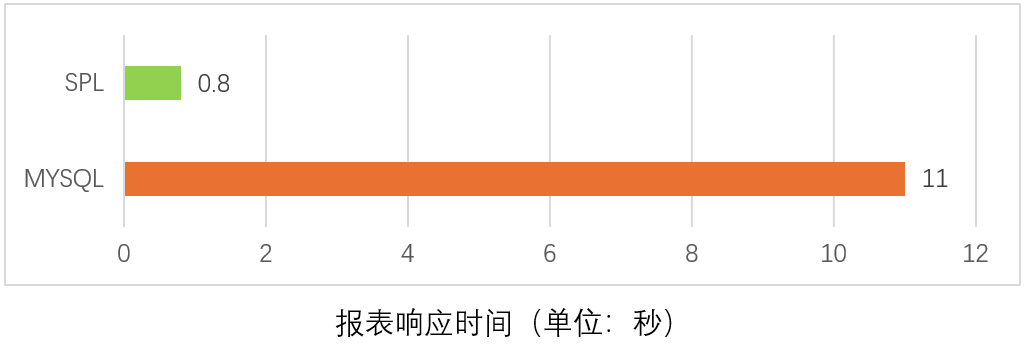
采用 SPL 基于文件计算,在运行环境不变的情况下,报表网页响应时间减少到 0.8 秒,其中 SPL 计算的时间仅有 0.5 秒,报表性能提升了近 14 倍:
润乾报表中已经包含了 SPL 引擎,只要将 SQL 检索数据集换成 SPL 数据集,就可以轻松调用 SPL 脚本文件:
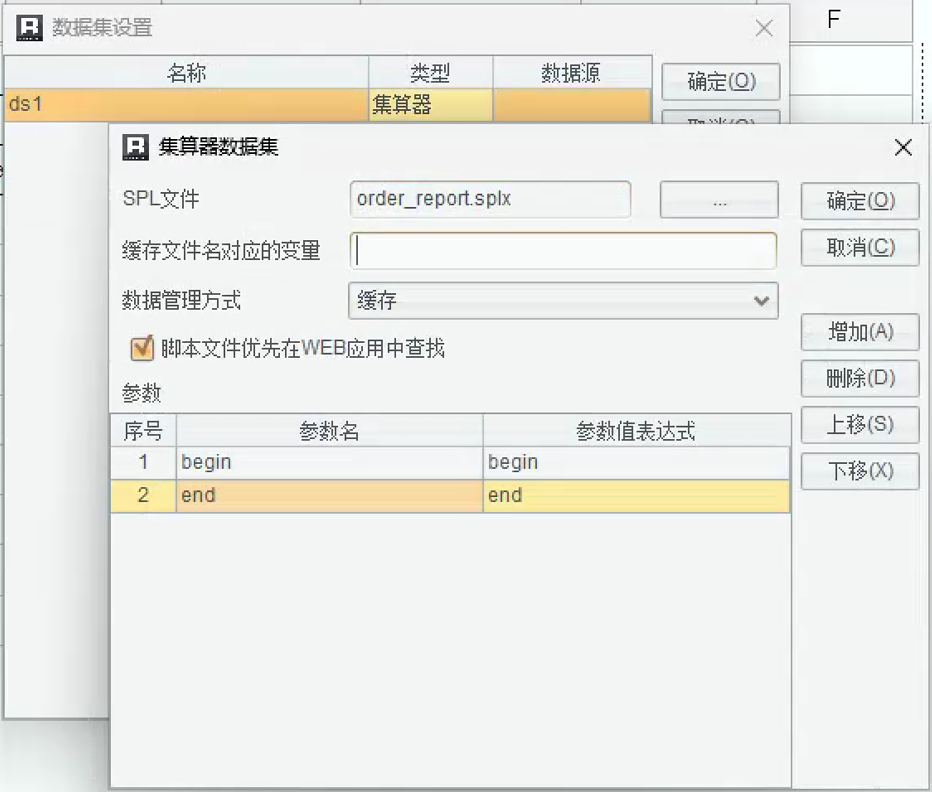
这里还可以配置报表传给 SPL 的参数,开始、结束日期 begin、end。
因为已经完全嵌入,SPL 的主目录、并行数等参数,也能直接在润乾报表设计器的选项中配置:
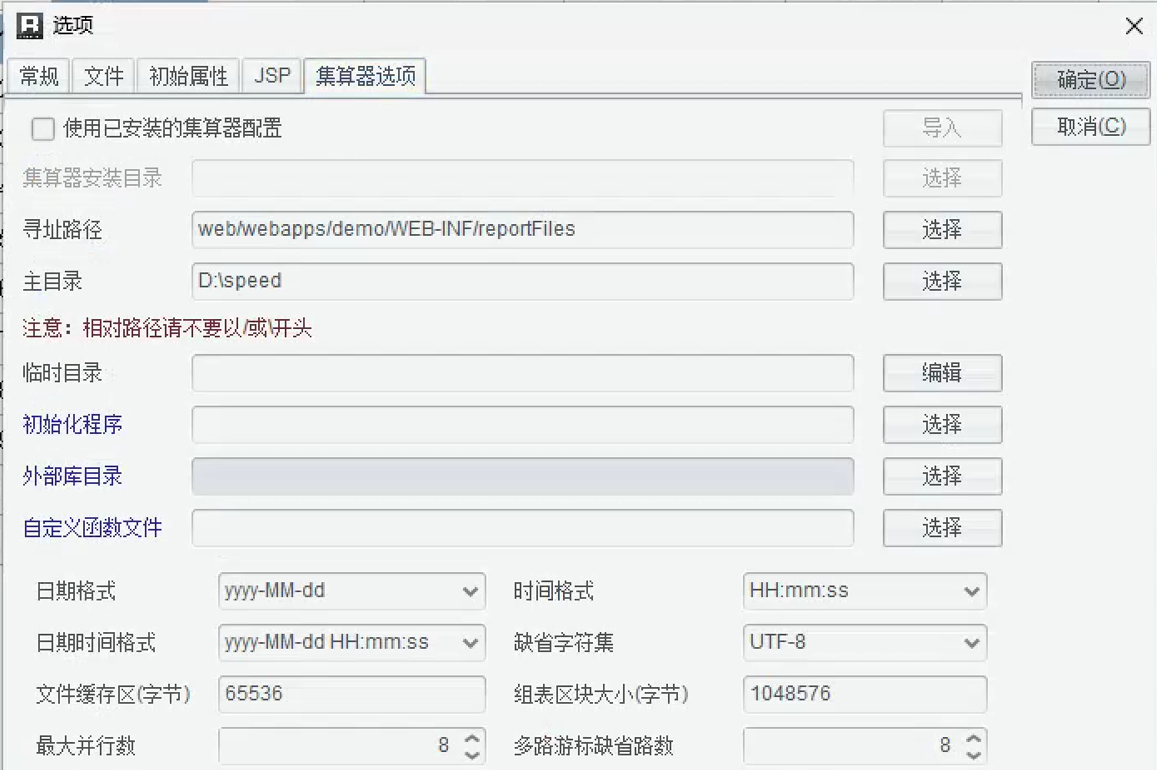
配置好主目录,只要把 SPL 的脚本.splx 文件和数据文件放到主目录中就可以调用了。
SPL 代码也很简单,比如这个报表调用的 order_report.splx 是这样的:
A |
|
1 |
=file("orders.ctx").open().cursor@m(employee_id,shipping_fee,order_date; order_date>=begin && order_date<=end && shipper_id != 1 && shipping_fee > 10) |
2 |
=A1.groups(employee_id; count(1):order_count, sum(shipping_fee):total, avg(shipping_fee) : average, max(order_date) : latest_order_date) |
3 |
return A2 |
这里的 orders.ctx,就是从 MYSQL 外置出来的订单数据,采用 SPL 列存方式存放的数据文件。
这段代码,是用游标 cursor 分批读入 ctx 文件中的订单数据,边读边算,适合数据量很大的情形。
游标中附加了过滤条件,相当于 SQL 的 WHERE 子句。过滤后用 groups 函数做分组汇总,语法形式和 SQL 不同,但仔细看会发现涉及的要素都是一样的。原来的 SQL 是这样:
select
employee_id,
count(*) as order_count,
sum(shipping_fee) as total,
avg(shipping_fee) as average,
max(order_date) as latest_order_date
from
orders
where
order_date between '2024-01-01' and '2024-10-31'
and shipper_id<>1
and shipping_fee > 10
group by
employee_id;
groups 函数参数中,分号前的部分是分组字段,相当于 SQL 的 GROUP BY 部分,分号后是聚合值,相当于 SQL 中 SELECT 子句的聚合运算。SPL 的分组会缺省将分组字段和聚合值拼成结果集,不像 SQL 那样要在 SELECT 中把分组字段再写一遍。
最后,return 把结果集返回给报表去展现。
还有其它例子,比如这个产品分组统计表,涉及订单表和订单明细表两个大表关联,数据量分别是一千万行和三千万行:
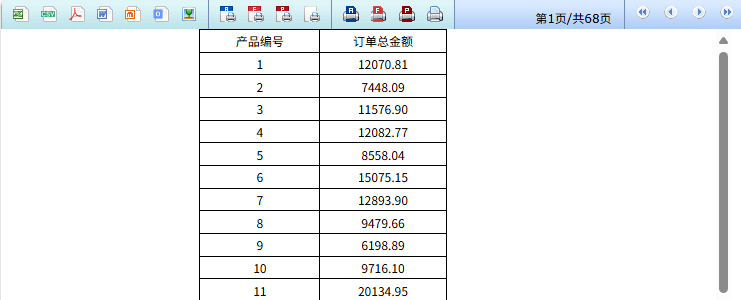
大表关联是数据库的老大难问题,这个报表基于 MYSQL 需要 21 秒完成,其中 MYSQL 的计算用时 20 秒。
用 SPL 外置计算,采用主子表有序归并算法,1.6 秒就出来了,SPL 计算时间仅 0.6 秒。
还有这个雇员 - 日期 - 订单汇总表,要找出指定 10 个雇员的订单,按日期统计订单数:
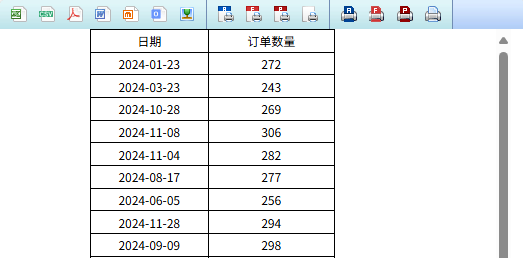
SQL 的 WHERE 子句中用 IN 计算,对于一千万数据的订单表,MYSQL 完成展现需要 17 秒,其中数据库计算占用了 16 秒。
采用 SPL 外置计算,应用 SPL 独有的对位序列算法,0.4 秒完成报表展现,SPL 计算时间仅 0.2 秒。
这样的例子还有很多,比如 COUNT DISNTICT。SPL 的数据文件支持有序存储,特别擅长处理去重计数 COUNT DISTINCT。采用 SPL 的有序去重计数算法,性能甚至超过专业 MPP。
而且,上面例子中提到的这些高性能算法,都可以轻量级的集成到润乾报表中。
集成了 SPL 的润乾报表不仅性能优异,而且价格低廉,公开报价:一套一万,三万买断,可以说是最具性价比的高性能报表工具了,从此彻底告别龟速报表。

