


怎样用 esProc 从事件表中查出下一组的开始时刻
某库表的事件表按时间戳排序后,相邻的 value 字段有时连续相同。
id |
value |
timestamp |
1 |
1 |
2023-11-10 13:00:00 |
2 |
2 |
2023-11-11 13:00:00 |
3 |
2 |
2023-11-12 13:00:00 |
4 |
1 |
2023-11-13 13:00:00 |
5 |
1 |
2023-11-14 13:00:00 |
6 |
1 |
2023-11-15 13:00:00 |
7 |
2 |
2023-11-16 13:00:00 |
8 |
2 |
2023-11-17 13:00:00 |
9 |
1 |
2023-11-18 13:00:00 |
现在要将相邻的 value 相同的记录分为一组,取出本组的开始时刻和下一组的开始时刻,当做本组的起止时刻,组成新的二维表。最后一组的下一组的开始时刻约定为” 9999-12-31 00:00:00”。
id |
value |
effective_from |
effective_to |
1 |
1 |
2023-11-10 13:00:00 |
2023-11-11 13:00:00 |
2 |
2 |
2023-11-11 13:00:00 |
2023-11-13 13:00:00 |
4 |
1 |
2023-11-13 13:00:00 |
2023-11-16 13:00:00 |
7 |
2 |
2023-11-16 13:00:00 |
2023-11-18 13:00:00 |
9 |
1 |
2023-11-18 13:00:00 |
9999-12-31 00:00:00 |
SQL 不直接支持把相同的相邻值分为同一组,难以保留分组继续计算,间接实现的代码非常复杂。SPL 支持相邻数据分组,可以保留分组子集继续计算 :https://try.esproc.com/splx?3st
A |
|
1 |
$select * from equipments_staging.csv order by timestamp |
2 |
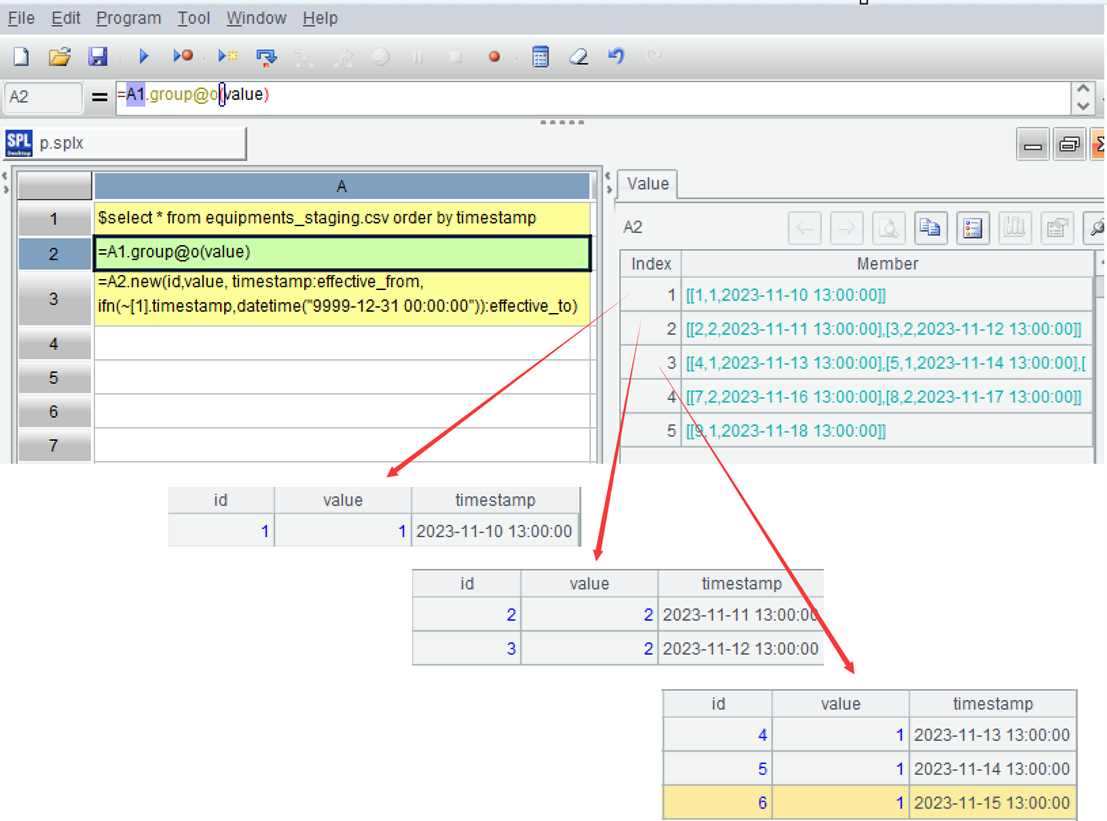
=A1.group@o(value) |
3 |
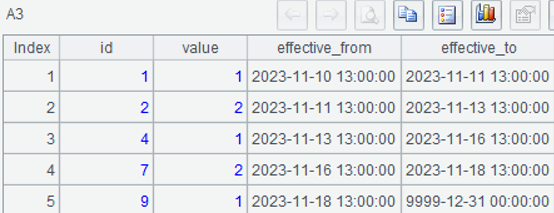
=A2.new(id,value, timestamp:effective_from, ifn(~[1].timestamp,datetime("9999-12-31 00:00:00")):effective_to) |
A1:加载数据,按时间戳排序。
A2:将相邻的 value 相同的记录分为一组,每组是一个集合。函数 group 用于分组,但不汇总,默认比对整列的值,即等值分组,@o 表示比对相邻的值,属于有序分组。前三组如图:
A3:新建二维表,将 A2 的每组数据处理成一条新纪录,id、value、effective_from 取自当前组的第 1 条记录, effective_to 取自下一组的第一条记录,当 effective_to 为 null 时取值为 9999-12-31 00:00:00。
effective_to 的完整代码是 ~[1](1).timestamp,简写做 ~[1].timestamp,~ 表示当前组,单独使用时可省略,表达相对位置等意义时不能省略;[1] 表示相对位置中的下一组;(1) 表示第一个成员,可省略。
函数 ifn 表示从参数中取第一个非 null 的成员。


来源 https://stackoverflow.com/questions/78024974/sql-query-group-by-to-find-effectivefrom-and-effectiveto-dates-for-repeating-key
英文版 https://c.esproc.com/article/1747123197029
Title: retrieve the start time of the next group from the event table
URL: https://www.sqlazy.com/?3Zj
Category: Event Sequencing & Sessionization