


怎样用 esProc 检查组内各行数据的相同状态
某库表的 ID 字段是汽车的分类,每类汽车再细分为品牌和型号。
ID |
Brand |
Type |
1 |
Honda |
Coupe |
1 |
Jeep |
SUV |
2 |
Ford |
Sedan |
2 |
Ford |
Crossover |
现在要按 ID 分组,计算出该组汽车的差异是在品牌上还是在型号上,如果组内汽车的品牌不止一个,则将计算列 difference 赋值为 Brand;如果组内汽车的型号不止一个,则将 difference 赋值为 Type。
ID |
Difference |
1 |
Brand |
1 |
Type |
2 |
Type |
SQL 分组后必须立刻汇总,难以在分组子集中进行逻辑判断,间接实现的代码很复杂。SPL 可以保留分组子集继续计算:https://try.esproc.com/splx?3c3
A |
|
1 |
$select * from tbl.txt |
2 |
=A1.group(ID) |
3 |
=A2.(if(~.icount(Brand)>1,new(ID,"Brand":Difference))|if(~.icount(Type)>1,new(ID,"Type":Difference))) |
4 |
=A3.conj() |
A1:加载数据。
A2:用 group 函数按 ID 分组,但不汇总,每组是一个记录集合。
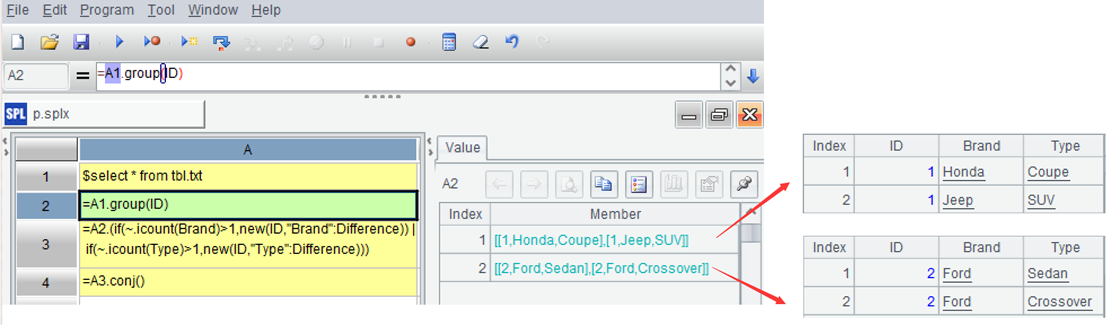
A3:处理每组数据:如果当前组的 Brand 去重计数后大于 1,则新建一条记录,字段 ID 取自当前组,字段 Difference 为字符串”Brand”;对当前组的 Type 字段也做类似处理,但新记录的 Difference 字段为字符串”Type”。符号 ~ 表示当前组,icount 函数用于去重计数,符号 | 可将新记录(或任意数据)合并成集合。
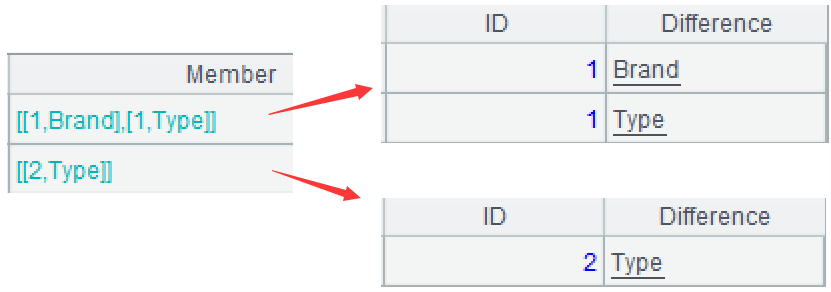
A4:合并各组数据的成员。

上面 A2-A4 是分步计算,便于调试,也可以合为一句:
=A1.group(ID). conj(if(~.icount(Brand)>1,new(ID,"Brand":Difference))|if(~.icount(Type)>1,new(ID,"Type":Difference)))


来源 https://stackoverflow.com/questions/78031456/optimize-query-for-columns-with-distinct-values-per-id
英文版 https://c.esproc.com/article/1746779220856
Title
Identify whether the difference is in Brand or Type per ID group
URL
https://www.sqlazy.com/?4fJ
Category
Dynamic Reporting Transformations