


怎样用 esProc 将分组内的字段值按次序复制到其它分组
某库表前两个字段都是分组字段,后两个字段是组内明细。按前 3 个字段排序后,数据有以下规律:同一个大组的各小组的记录数一定相同;每个大组里只有最后一个小组的第 4 个字段有值,其他小组都是 null。
Group1 |
Group2 |
LineID |
TargetField |
1 |
1 |
5 |
|
1 |
1 |
6 |
|
1 |
2 |
3 |
|
1 |
2 |
4 |
|
1 |
3 |
1 |
1 |
1 |
3 |
2 |
2 |
2 |
4 |
11 |
|
2 |
4 |
12 |
|
2 |
5 |
9 |
|
2 |
5 |
10 |
|
2 |
6 |
7 |
3 |
2 |
6 |
8 |
4 |
现在要在每个大组内,把最后一个小组的第 4 列,按序列的顺序更新或复制到其他小组。
Group1 |
Group2 |
LineID |
TargetField |
1 |
1 |
5 |
1 |
1 |
1 |
6 |
2 |
1 |
2 |
3 |
1 |
1 |
2 |
4 |
2 |
1 |
3 |
1 |
1 |
1 |
3 |
2 |
2 |
2 |
4 |
11 |
3 |
2 |
4 |
12 |
4 |
2 |
5 |
9 |
3 |
2 |
5 |
10 |
4 |
2 |
6 |
7 |
3 |
2 |
6 |
8 |
4 |
SQL 分组后必须立刻汇总,缺乏天然序号,只能间接实现分组后的有序计算,代码很复杂。SPL 可以保持分组子集,提供了天然序号,方便进行分组后的有序计算::https://try.esproc.com/splx?4Bs
A |
|
1 |
$select * from lines.txt order by Group1, Group2, LineID |
2 |
=A1.group(Group1).(~.group(Group2)) |
3 |
=A2.(last=~.m(-1).(TargetField),~.(~.(TargetField=last(#)))) |
4 |
return A1 |
A1:加载数据,按前 3 个字段排序。
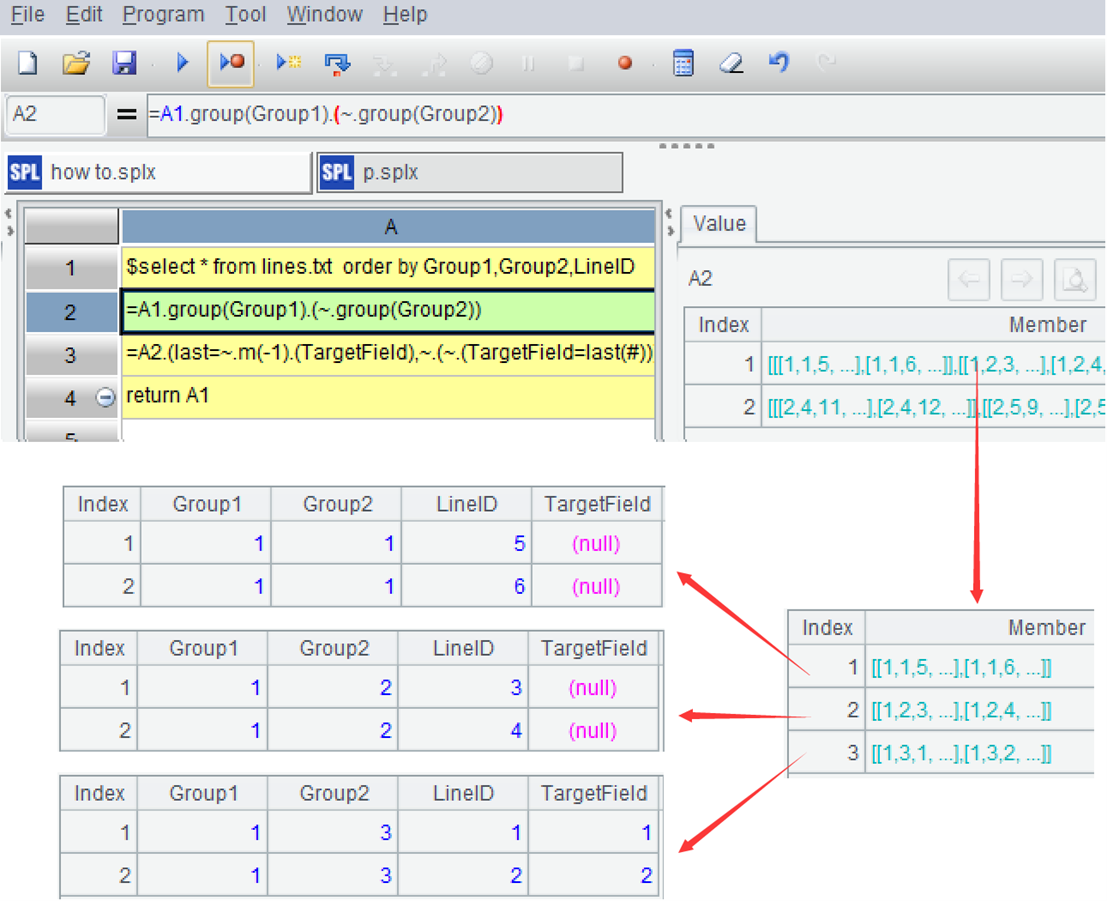
A2:用按第 1 个字段分组,组内再按第 2 个字段分小组,但不汇总,每个大组和小组都是一个集合。函数 group 用于分组,~ 表示当前组。第 1 个大组点击展开后如图:
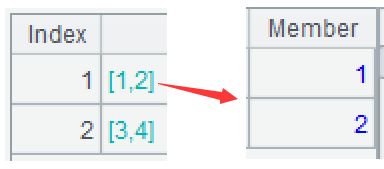
A3=A2.(last=~.m(-1).(TargetField), …) 循环处理 A2 中的每个大组,先取当前大组中的最后一个小组的 TargetField 字段的序列,命名为 last。函数 m 表示按序号取成员,-1 表示倒数第 1 个。第一个大组的 last 如图:
A3=A2.(…, ~.(~.(TargetField=last(#)))) 再循环处理当前大组的每个小组的每条记录,将第 4 个字段改成 last 里位置相同的值。”~.(TargetField)”表示按名字取出字段序列;”last(#)”表示按序号取成员,是”last.m(#)”的简写;符号 #表示当前序号。执行后 A1 被修改成下图:
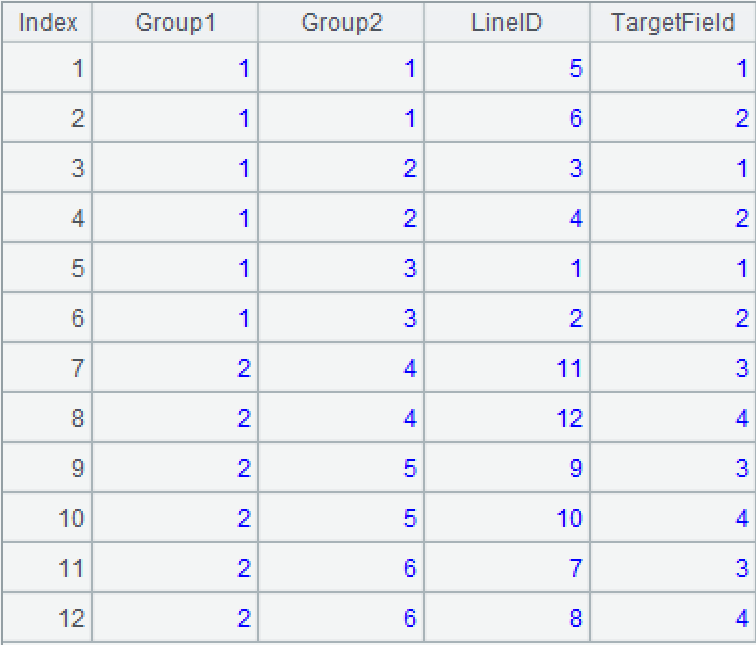
上面代码修改了每个大组的每个小组,实际上最后一个小组可以不改,或者说应该取第 1 到倒数第 2 个小组,代码:~.m(1:-2),简写做 ~.m(:-2)
A4:最后返回 A1。


来源 https://stackoverflow.com/questions/78038438/how-to-update-data-by-order-of-sequence-in-each-subgroup-in-sql
英文版 https://c.esproc.com/article/1745829285944
Title
Update data by order of sequence in each subgroup
URL
https://www.sqlazy.com/?4Mz
Category
Data Cleaning & Normalization