


怎样用 esProc 计算递归关系下的合计
某数据库有票据表和工时表,票据表存储了每张票据和父票据的关系,形成了自关联结构:
ticketid |
parentID |
1 |
6 |
2 |
7 |
3 |
8 |
4 |
9 |
5 |
10 |
6 |
18 |
7 |
19 |
8 |
20 |
9 |
21 |
10 |
22 |
11 |
23 |
12 |
18 |
13 |
19 |
14 |
20 |
15 |
21 |
16 |
22 |
17 |
23 |
18 |
24 |
19 |
25 |
20 |
26 |
21 |
27 |
22 |
28 |
23 |
29 |
24 |
30 |
25 |
30 |
26 |
30 |
27 |
30 |
28 |
30 |
29 |
30 |
30 |
0 |
30 |
0 |
工时表存储了每张票据对应的直接工时:
ticketid |
hours |
0 |
4 |
1 |
3 |
2 |
6 |
3 |
9 |
4 |
11 |
5 |
5 |
6 |
10 |
7 |
9 |
8 |
11 |
9 |
7 |
10 |
13 |
11 |
2 |
12 |
10 |
13 |
4 |
14 |
9 |
15 |
14 |
16 |
8 |
17 |
8 |
18 |
7 |
19 |
9 |
20 |
9 |
21 |
8 |
22 |
12 |
23 |
14 |
24 |
13 |
25 |
9 |
26 |
12 |
27 |
5 |
28 |
10 |
29 |
5 |
30 |
0 |
现在要递归地计算出每张票据的直接工时和所有下级子票据的工时之和,即总工时。
ticketid |
Total_hours |
1 |
3 |
2 |
6 |
3 |
9 |
4 |
11 |
5 |
5 |
6 |
13 |
7 |
15 |
8 |
20 |
9 |
18 |
10 |
18 |
11 |
2 |
12 |
10 |
13 |
4 |
14 |
9 |
15 |
14 |
16 |
8 |
17 |
8 |
18 |
30 |
19 |
28 |
20 |
38 |
21 |
40 |
22 |
38 |
23 |
24 |
24 |
43 |
25 |
37 |
26 |
50 |
27 |
45 |
28 |
48 |
29 |
29 |
30 |
252 |
SQL不支持引用,不方便表达自关联关系,缺乏递归函数,代码很难写。SPL 提供了引用函数,可以建立自关联;提供了递归函数,可以取所有下级节点:https://try.esproc.com/splx?4l2
A |
|
1 |
$select t.ticketid ticketid,t.parentID parentID,h.hours hours from tickets.txt t left join hours.txt h on t.ticketid=h.ticketid |
2 |
>A1.switch(parentID,A1:ticketid) |
3 |
=A1.new(ticketid,A1.nodes(parentID,~).sum(hours)+hours:Total_hours) |
A1:关联两个表,加载数据。
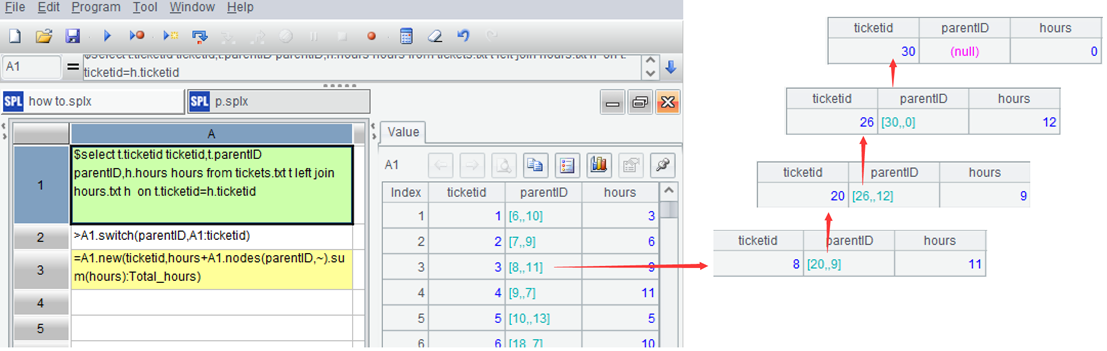
A2:用 switch 函数将父票据的字段值修改为父票据的记录引用,建立自关联关系。记录引用可以直观表达父子关系,下图是 3 号票据所有级别的父票据,[8,20,26,30]。
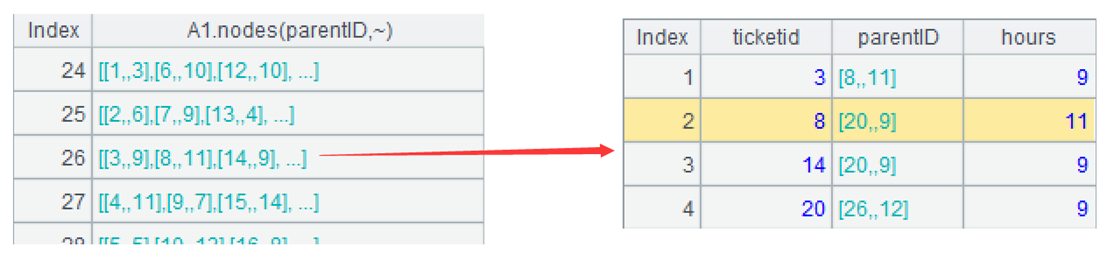
A3=A1.new(A1.nodes(parentID,~))。新建二维表,先计算出当前记录的所有下级记录。函数 nodes 可以递归地计算出某条记录所有的下级记录,~ 表示当前记录。下图是第 26 号票据的所有下级记录,[3,8,14,20]:
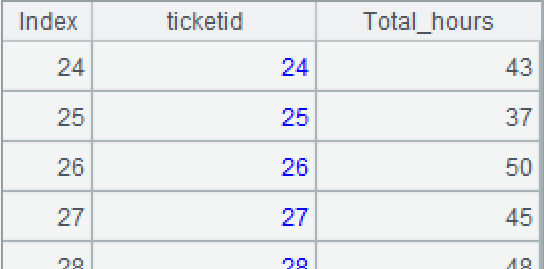
A3=A1.new(ticketid,A1.nodes(parentID,~).sum(hours)+hours:Total_hours)。再计算当前票据的总工时,也就是下级子票据的工时之和 + 直接工时。


英文版 https://c.esproc.com/article/1745484496559