


怎样用 esProc 将数据集中重复内容置空
某库表的前两个字段会同时出现重复值,比如下面的前 3 条记录。
Column_A |
Column_B |
Column_C |
1 |
AB |
amount1 |
1 |
AB |
amount2 |
1 |
AB |
amount3 |
2 |
OA |
amount4 |
3 |
OE |
amount5 |
3 |
OE |
amount6 |
4 |
DB |
amount7 |
现在要将所有的重复值改成 null,换句话说,按前 2 个字段分组后(等价于按其中 1 个字段分组),只保留组内第一条不变,其他记录的前两个字段改成 null。
计算结果像下面这样:
Column_A |
Column_B |
Column_C |
1 |
AB |
amount1 |
amount2 |
||
amount3 |
||
2 |
OA |
amount4 |
3 |
OE |
amount5 |
amount6 |
||
4 |
DB |
amount7 |
SQL分组后必须立刻汇总,不能保持分组子集继续计算,也没有天然的组内行号,代码比较难写。
esProc提供了丰富的计算函数,可以保持分组子集继续计算,有天然的行号,包括组内行号: https://try.esproc.com/splx?505
A |
|
1 |
$select * from table_name.txt |
2 |
=A1.group(Column_A) |
3 |
=A2.run(~.(if(#!=1,Column_A=Column_B=null))) |
4 |
=A3.conj() |
A1:加载数据。
A2:用 group 函数按第 1 个字段分组,但不汇总。
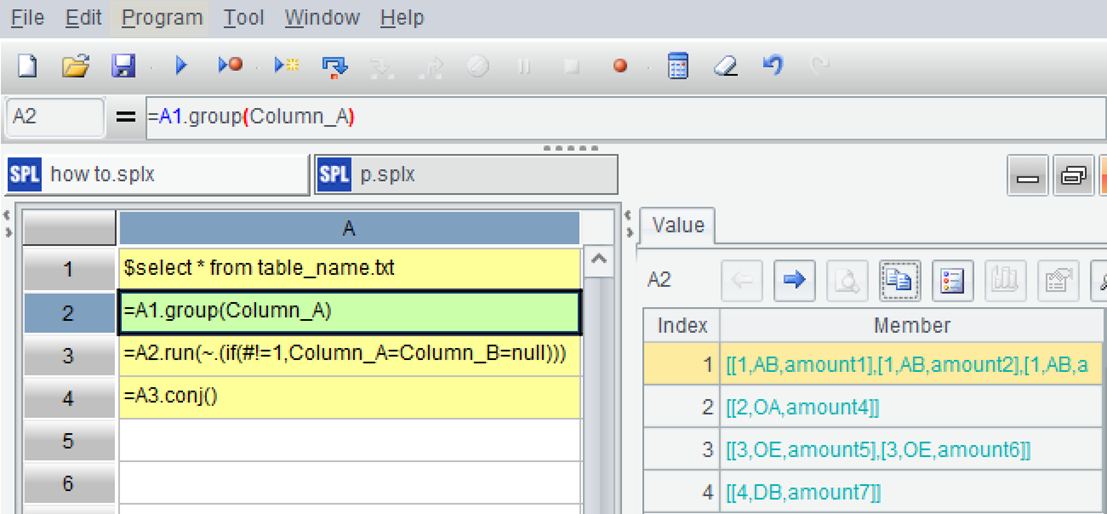
每组是一个集合,可以通过点击展开,如图是前两组。
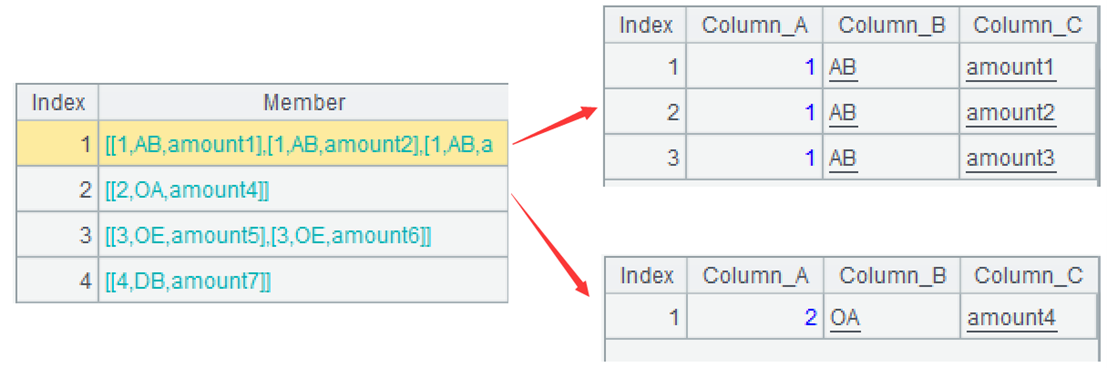
A2:用 run 函数修改各组数据,当成员在组内的序号大于 1 时,将前两个字段改为 null。~ 表示当前组,# 表示组内序号。

A3:合并各组。
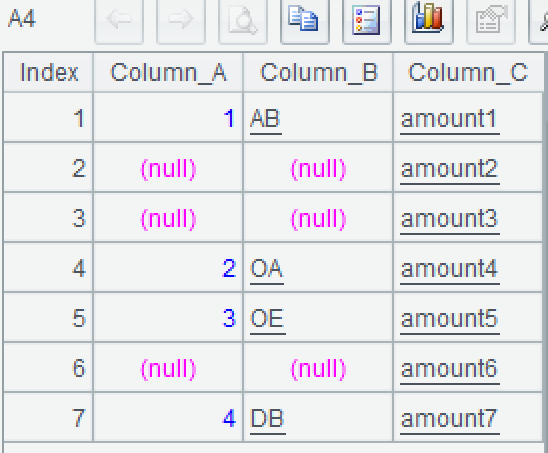
上面分步骤的代码有利于学习和调试,熟练后 A2-A4 可以合为一句:
=A1.group(Column_A).run(~.(if(#!=1,Column_A=Column_B=null))).conj()


英文版 https://c.esproc.com/article/1744965092676