


如何用 esProc 将数据库表转储提速查询
数据量大或者数据库繁忙都会导致数据库查询变慢,这时将数据用 esProc 导出存成文件再计算可以大幅提升性能。
数据与用例
MySQL 数据库有 orders_30m 表存储着历年的订单数据,表结构如下:
数据样例:
1 3001 2023-01-05 701 Smartphone Z 1 699.99 699.99 Credit Card 888 Eighth St, Charlotte, NC Delivered
2 3002 2023-02-10 702 Smart Scale 1 49.99 49.99 PayPal 999 Ninth Ave, Indianapolis, IN Delivered
3 3003 2023-03-15 703 Laptop Air 1 1099.99 1099.99 Credit Card 101 Tenth Rd, Seattle, WA Delivered
数据量:3 千万行
两个样例查询:
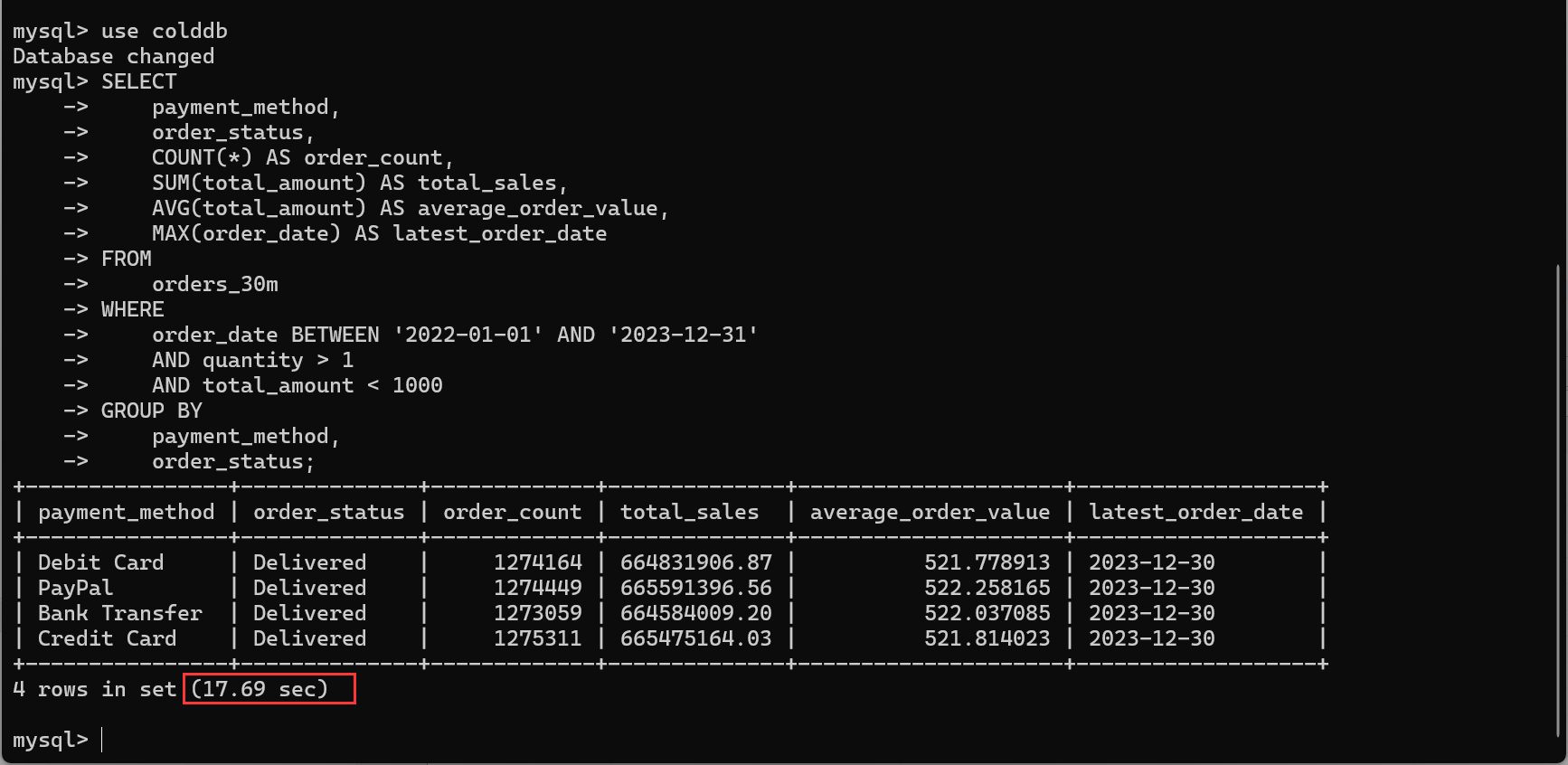
1. 按支付方式和订单状态分析 2022 年 -2023 年销售额
SELECT
payment_method,
order_status,
COUNT(*) AS order_count,
SUM(total_amount) AS total_sales,
AVG(total_amount) AS average_order_value,
MAX(order_date) AS latest_order_date
FROM
orders
WHERE
order_date BETWEEN '2022-01-01' AND '2023-12-31'
AND quantity > 1
AND total_amount < 1000
GROUP BY
payment_method,
order_status;
查询时间:17.69s
2. 每类产品销售最多的三笔订单
WITH ranked_orders AS (
SELECT
product_name,
order_id,
customer_id,
order_date,
total_amount,
DENSE_RANK() OVER (
PARTITION BY product_name
ORDER BY total_amount DESC
) AS amount_rank
FROM
orders
)
SELECT * FROM ranked_orders
WHERE amount_rank <= 3
ORDER BY product_name, amount_rank;
查询时间:63.22s

现在用 esProc 将数据转储成文件加速查询。
安装 esProc
先通过https://www.esproc.com/download-esproc/ 下载 esProc 标准版。
安装后,配 MySQL 数据库连接。
先把 MySQL JDBC 驱动包放到 [esProc 安装目录]\common\jdbc 目录下(其他数据库类似)。
然后启动 esProc IDE,菜单栏选择 Tool-Connect to Data Source,配置 MySQL 标准 JDBC 连接。
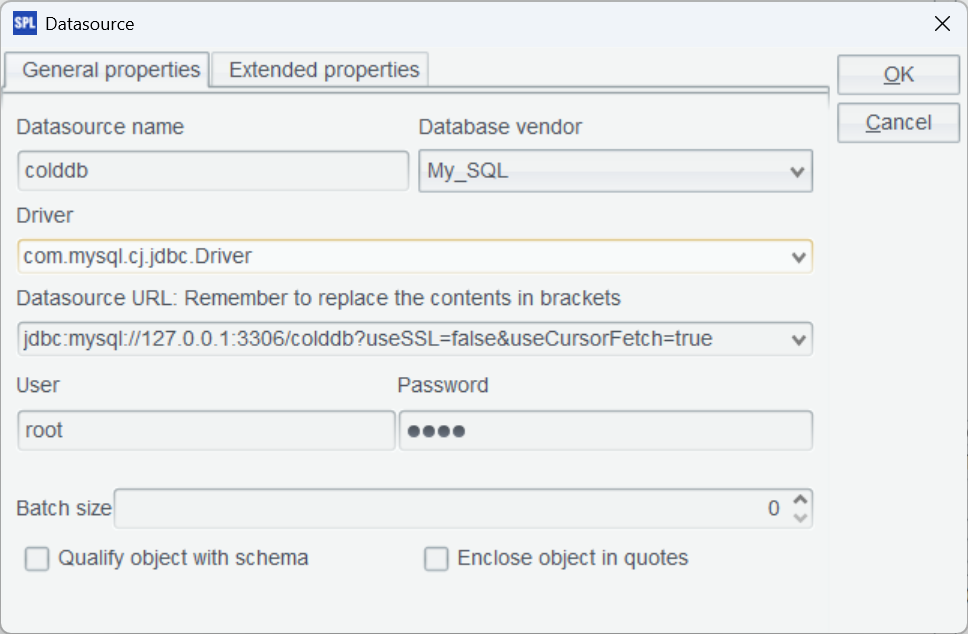
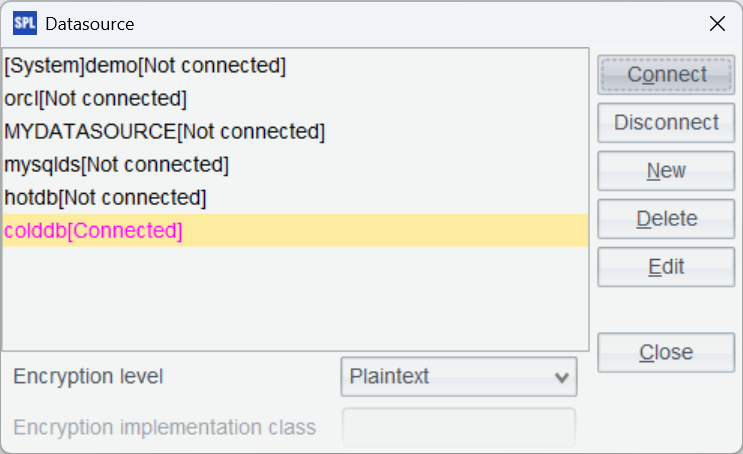
确定后,测试一下连接,点击 Connect,发现刚刚配置的 colddb 数据源变成粉红色证明连接成功。
转储为 BTX
接下来将 orders 表导出转存成二进制行存文件 btx。
A |
|
1 |
=connect("colddb") |
2 |
=A1.cursor@x("select * from orders_30m") |
3 |
=file("D:/data/orders_30m.btx").export@b(A2) |
生成 btx 很简单,直接导出就可以,因为数据量较大 A2 使用了游标,可以应对任意规模的数据。
按 Ctrl+F9 执行:
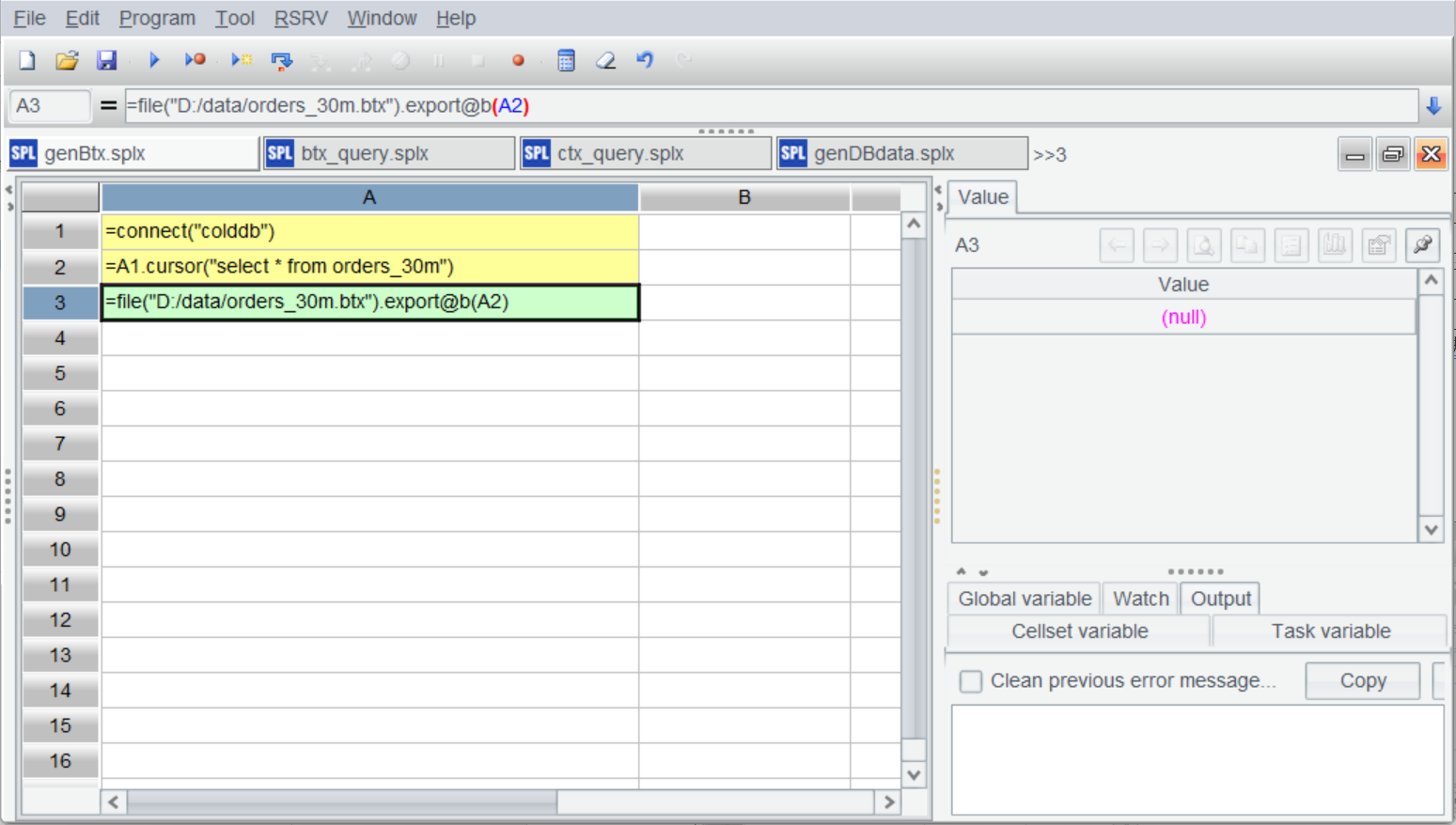
btx 文件就生成了:

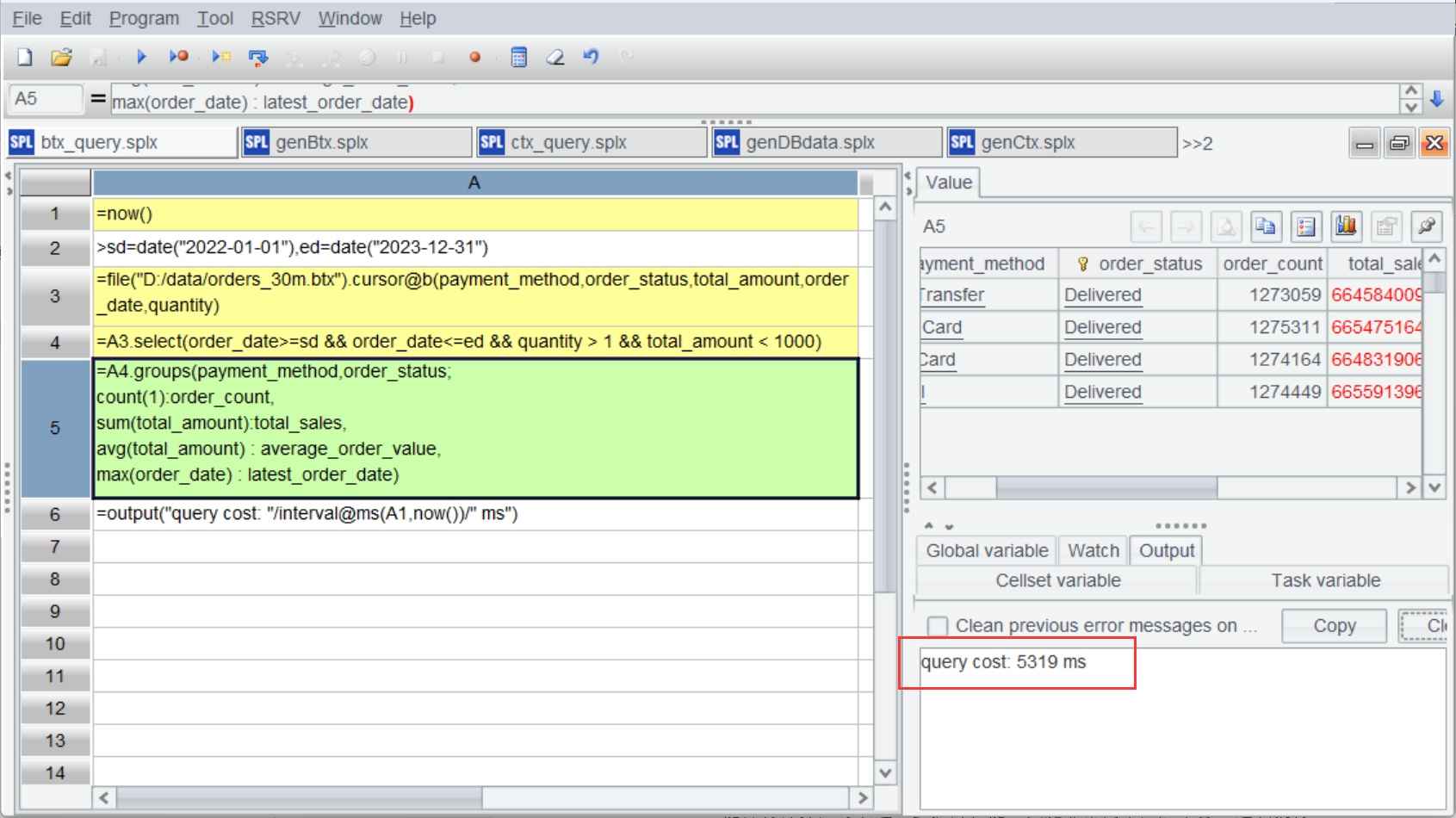
下面用 btx 跑一下上面第一个计算:按支付方式和订单状态分析 2022 年 -2023 年销售额。
A |
|
1 |
=now() |
2 |
>sd=date("2022-01-01"),ed=date("2023-12-31") |
3 |
=file("D:/data/orders_30m.btx").cursor@b(payment_method,order_status,total_amount,order_date,quantity) |
4 |
=A3.select(order_date>=sd && order_date<=ed && quantity > 1 && total_amount < 1000) |
5 |
=A4.groups(payment_method,order_status; count(1):order_count, sum(total_amount):total_sales, avg(total_amount) : average_order_value, max(order_date) : latest_order_date) |
6 |
=output("query cost:"/interval@ms(A1,now())/"ms") |
A3 创建文件游标,只读取用到的列,A4 用 select 进行条件过滤,A5 进行分组汇总,代码很简单不过多解释。
运行一下看,结果没问题,时间消耗了5.319 秒,比 MySQL 快了3.3 倍。
转储为 CTX
除了 btx,esProc 还提供了轻量级的列存二进制文件格式 ctx。我们来试一下,将 orders 表转成 ctx:
A |
|
1 |
=connect("colddb") |
2 |
=A1.cursor@x("select order_id,customer_id,order_date,product_id,product_name,quantity,unit_price,total_amount,payment_method,shipping_address,order_status,created_at,updated_at from orders_30m") |
3 |
=file("D:/data/orders_30m.ctx").create@y(order_id,customer_id,order_date,product_id,product_name,quantity,unit_price,total_amount,payment_method,shipping_address,order_status,created_at,updated_at) |
4 |
=A3.append(A2) |
创建 ctx 时需要先定义结构(A3),与 order 表完全一致就可以了;A4 将数据写入 ctx。

可以看出来,列式的 ctx 的压缩率要远高于行式的 btx。
再做一下上面的计算。
A |
|
1 |
=now() |
2 |
>sd=date("2022-01-01"),ed=date("2023-12-31") |
3 |
=file("D:/data/orders.ctx").open().cursor (payment_method,order_status,total_amount,order_date,quantity) |
4 |
=A3.select(order_date>=sd && order_date<=ed && quantity > 1 && total_amount < 1000) |
5 |
=A4.groups(payment_method,order_status; count(1):order_count, sum(total_amount):total_sales, avg(total_amount) : average_order_value, max(order_date) : latest_order_date) |
6 |
=output("query cost:"/interval@ms(A1,now())/"ms") |
ctx 使用时需要先 open 再创建 cursor,剩下的代码与 btx 完全一样。
运行时间:3.061 秒,比 btx 要快。
ctx 还有一项游标过滤的优化技巧,把过滤条件附加到游标上,esProc 会先只读出用于计算条件的字段值,如果条件不成立就放弃到下一步,条件成立才再继续读出其它需要的字段并创建这条记录。
A |
|
1 |
=now() |
2 |
>sd=date("2022-01-01"),ed=date("2023-12-31") |
3 |
=file("D:/data/orders_30m.ctx").open().cursor (payment_method,order_status,total_amount,order_date;order_date>=sd && order_date<=ed && quantity > 1 && total_amount < 1000) |
4 |
=A3.groups(payment_method,order_status; count(1):order_count, sum(total_amount):total_sales, avg(total_amount) : average_order_value, max(order_date) : latest_order_date) |
5 |
=output("query cost:"/interval@ms(A1,now())/"ms") |
把过滤条件放到 A3 的 cursor 上,其他代码基本一样的。
运行时间变成了:2.374 秒。
这里过滤条件用到了 3 个字段,而全部读取也只有 5 个字段,所以性能只提升了 32%,如果字段数相差更多,性能差距会更明显。
并行计算
esProc 还能方便地写出并行代码,btx 和 ctx 都可以,只要配置一下并行数,跟 CPU 核数一致就可以(这里配置了 8 个)。
看一下并行计算 btx 的脚本:
A |
|
1 |
=now() |
2 |
>sd=date("2022-01-01"),ed=date("2023-12-31") |
3 |
=file("D:/data/orders_30m.btx").cursor@bm(payment_method,order_status,total_amount,order_date,quantity) |
4 |
=A3.select(order_date>=sd && order_date<=ed && quantity > 1 && total_amount < 1000) |
5 |
=A4.groups(payment_method,order_status; count(1):order_count, sum(total_amount):total_sales, avg(total_amount) : average_order_value, max(order_date) : latest_order_date) |
6 |
=output("query cost:"/interval@ms(A1,now())/"ms") |
只需要在 cursor 后加了个@m选项 ,esProc 就会自动根据配置的并行数并行计算,很方便。
运行时间:1.426 秒。
ctx 也类似:
A |
|
1 |
=now() |
2 |
>sd=date("2022-01-01"),ed=date("2023-12-31") |
3 |
=file("D:/data/orders_30m.ctx").open().cursor @m(payment_method,order_status,total_amount,order_date;order_date>=sd && order_date<=ed && quantity > 1 && total_amount < 1000) |
4 |
=A3.groups(payment_method,order_status; count(1):order_count, sum(total_amount):total_sales, avg(total_amount) : average_order_value, max(order_date) : latest_order_date) |
5 |
=output("query cost:"/interval@ms(A1,now())/"ms") |
增加 @m 选项,运行时间降到了:0.566 秒。
当然,很多数据库通常也支持并行计算,但 MySQL 这方面似乎不够好,设置了并行参数后,性能也没显著提升。
汇总一下以上测试的执行时间(单位 s):
MySQL |
BTX |
CTX |
|
串行 |
17.69 |
5.319 |
2.374 |
并行 |
17.66 |
1.426 |
0.566 |
前面还有一个计算组内 TopN 的用例,这里就不给出详细测试结果了,文件仍会快很多(单线程 63.22/2.075=30.5 倍)。这里仅给出 esProc 的代码实现,来感受其语法的简洁和完善性。
每类产品销售最多的三笔订单:
A |
|
1 |
=file("D:/data/orders_30m.ctx").open().cursor(product_name,order_id,customer_id,order_date,total_amount) |
2 |
=A1.groups(product_name;top(-3;total_amount)) |
esProc 将 TopN 理解成聚合运算,实现变得非常简单。
最后总结一下,esProc 的两种文件都比数据库要快,尤其是 ctx,常规运算也能比数据库快出几倍到十几倍;而稍复杂的 TopN 运算则要快出几十倍,将数据转存成文件的确有优势。不过,文件存储有其特定的适用场景,因为要导出数据,所以更适合计算不变的历史数据,这种场景当然也有很多。如果要处理新数据,就需要用 esProc 的混合运算了,这里不再展开,可以参考官网材料。


英文版