


怎样用 esProc 加速 COUNT DISTINCT
SQL 中的去重计数 COUNT DISTINCT 一直比较慢。
去重本质上是分组运算,需要把遍历过的分组字段值都保持住,用于后续的比对。结果集太大时,还要把数据写到硬盘上做缓存,性能低下。
如果先将数据按照去重字段排序,计算有序去重就会简单很多,只要在遍历过程中,把与上一条不相同的字段保存下来,并把计数值加 1 即可,不需要保持结果集,更不必做外存缓存。
但数据库无法保证存储的次序,很难实施这样的有序去重算法。esProc SPL 可以把数据导出后有序存储,实现这种高性能的有序去重计数。
下面,通过实际例子比较一下 esProc SPL 和 MYSQL 数据库计算去重计数的性能。
测试环境:普通笔记本电脑,2 核 CPU,8G 内存,SSD 硬盘。操作系统是 Win11,MYSQL 版本是 8.0。
数据库中的事件表 events 有 1 千万条记录,包括字段:事件号 event_id、用户号 user_id、时间 event_time、事件名称 event_name。
先下载 esProc https://www.esproc.com/download-esproc/,用标准版就可以了。
安装 esProc 后,试一下 IDE 是否可以正常访问数据库。先把 MYSQL 数据库的 JDBC 放到目录 "[安装目录]\common\jdbc",这是 esProc 的类路径之一:

在 esProc 中建立 MYSQL 数据源:
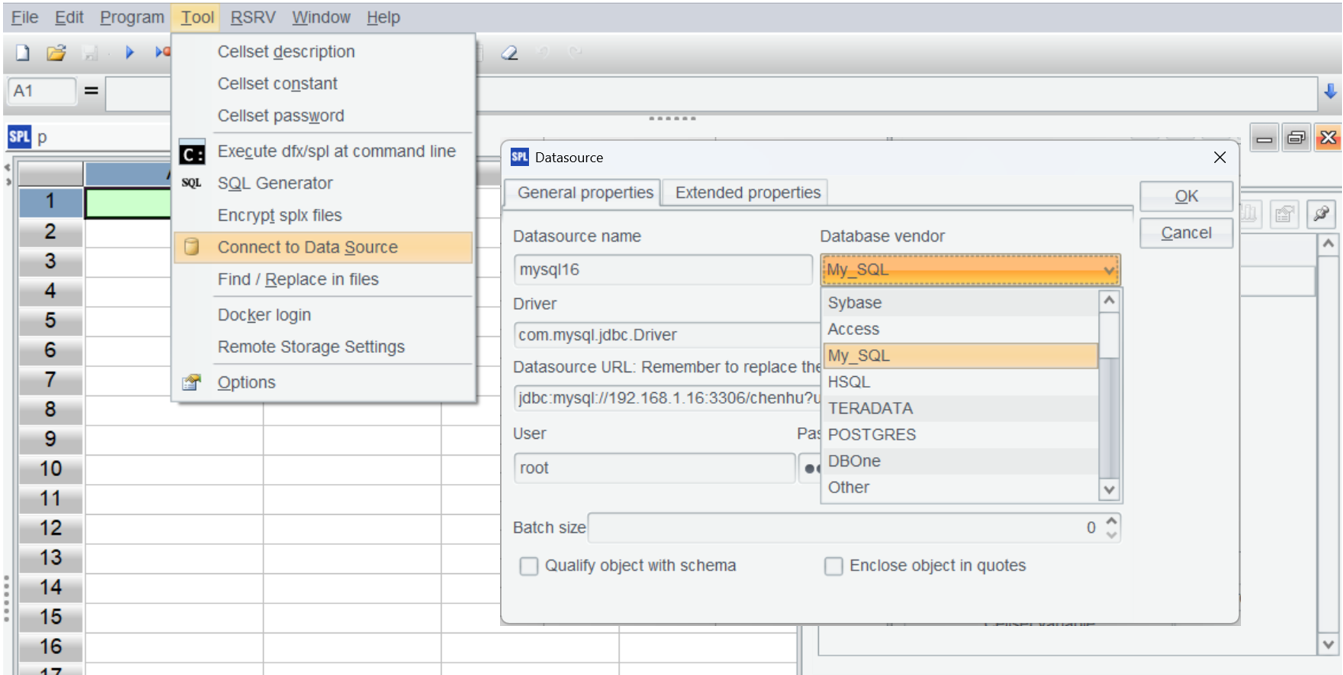
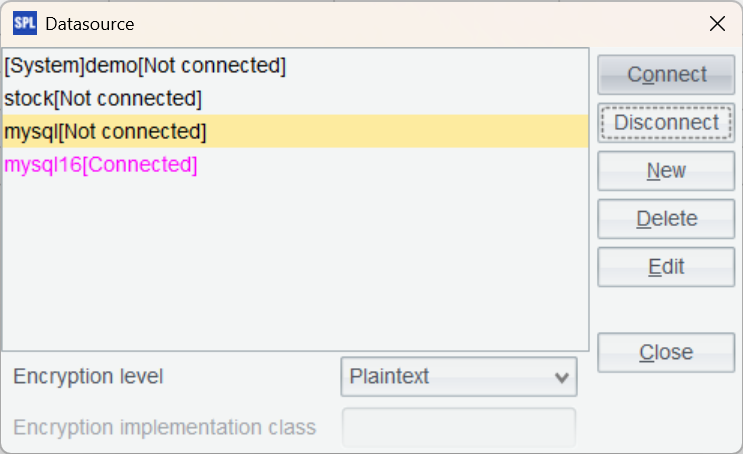
返回到数据源界面并连接刚才配置的数据源,如果数据源名变成粉色,说明配置成功。
在 IDE 中新建脚本,编写 SPL 语句,连接 数据库,通过简单 SQL 加载 users 表的数据:
A |
B |
|
1 |
=connect("mysql16") |
|
2 |
=A1.query@x("select user_id,event_time,event_name from events limit 100") |
|
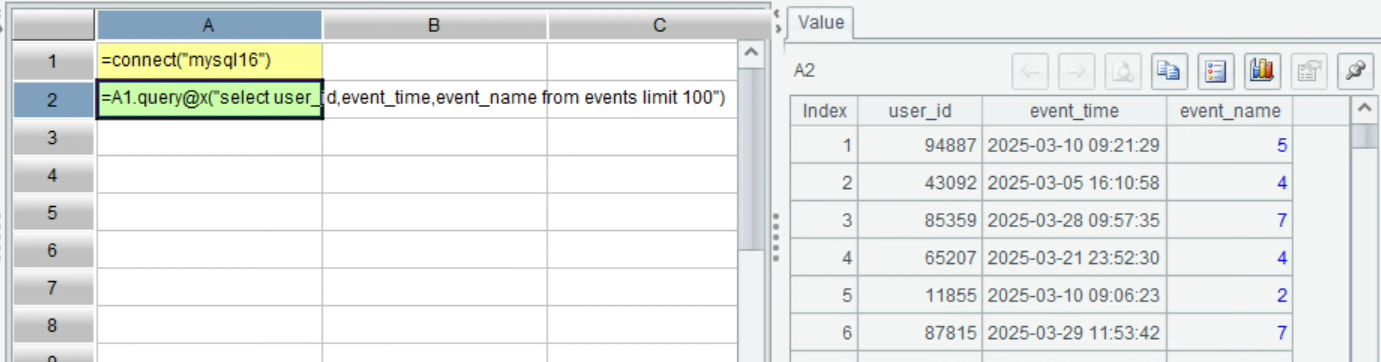
按 ctrl-F9 执行,点击 A2 格后,在右边可以看到前 100 条数据:
从数据库简单加载数据后,就可以用 SPL 导出数据有序存储了:
A |
B |
|
1 |
=connect("mysql16") |
|
2 |
=A1.cursor("select user_id,event_id,event_time,event_name from events order by user_id") |
|
3 |
=file("events.ctx").create@p(#user_id,event_id,event_time,event_name) |
|
4 |
=A3.append(A2) |
>A3.close() |
5 |
>A1.close() |
|
A3 定义 SPL 的组表,字段前面带 #表示维,维必须有序。
A6 中 create 函数的 @p 参数表示第一个字段 user_id 是分段键,这样可以防止分段读取时,把一个 user_id 的记录拆分开。
例一,先看最简单的情况。对 events 表的 user_id 去重计数。
SQL:
select count(distinct user_id) from events;
执行时间:16 秒。
SPL 则采用有序去重计数的写法:
A |
|
1 |
=file("events.ctx").open().cursor@m(user_id).group@1(user_id).skip() |
user_id 有序,游标的 group 函数采用有序分组方式,归并相邻且相同的 user_id。@1 选项表示每组只取第一条记录,这样不用建立分组子集,速度更快。
执行时间:0.4 秒。
SPL 有序去重计数的性能优势非常明显。
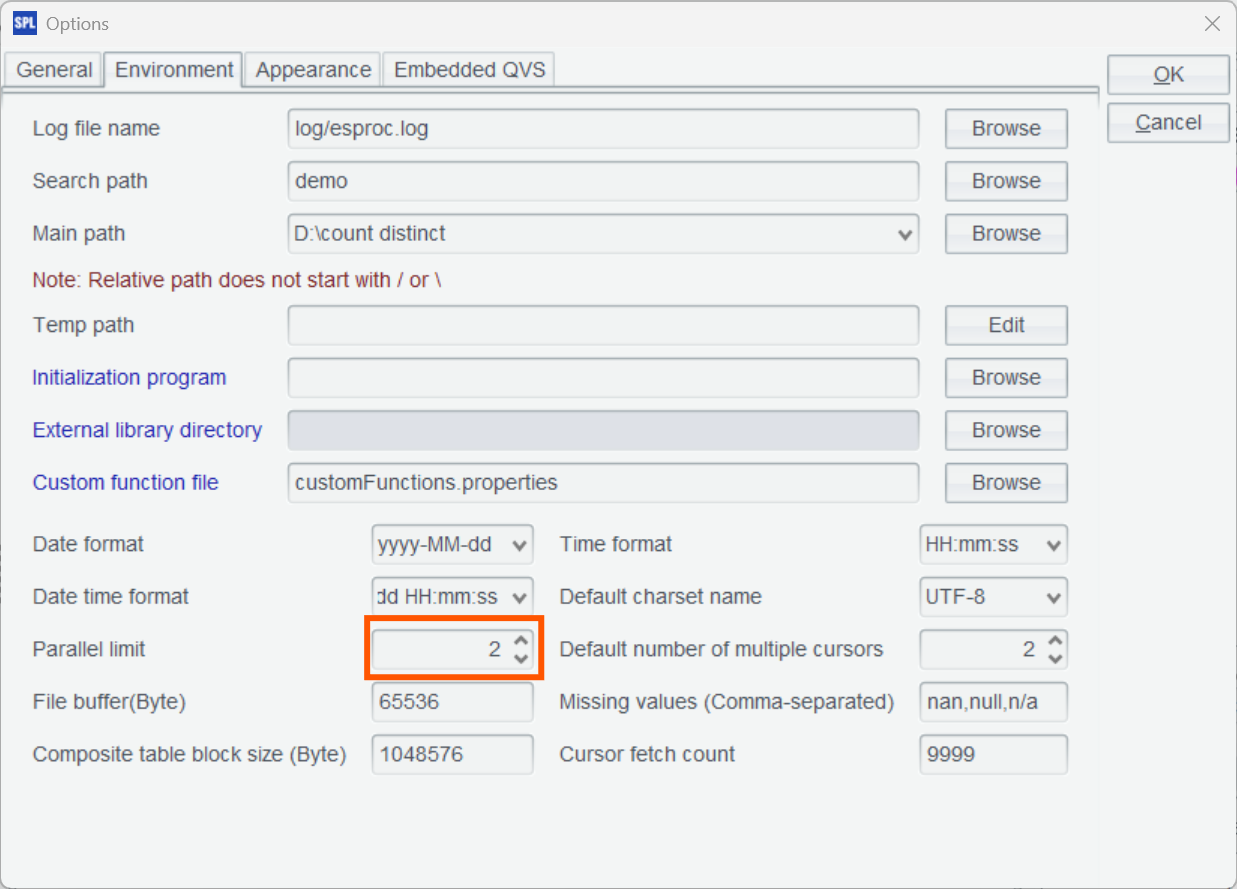
@m 表示按照 option 里配置的并行选项进行多线程计算。
同时把这个并行选项打开。
例二,统计 event_name 出现过 login 或 confirm 的去重 user_id 个数。
SQL:
select
count(distinct case when event_name = 'login' then user_id end) as count1,
count(distinct case when event_name = 'confirm' then user_id end) as count2
from
events
执行时间:16 秒。
SPL 写法:
A |
|
1 |
=file("events.ctx").open().cursor@m(user_id,event_name) |
2 |
=A1.groups(;icount@o(if(event_name=="login",user_id)):count1,icount@o(if(event_name=="confirm",user_id)):count2) |
icount@o 表示有序去重计数。
执行时间:0.9 秒。
例三,更复杂的情况。同一用户,按照时间顺序连续的事件如果名称相同就是重复事件。去掉重复事件后,发生事件个数大于 5 的用户数量。
SQL 比较难写了,这里不再给出,有兴趣的同学可以尝试写一下。
SPL 代码:
A |
|
1 |
=file("events.ctx").open().cursor@m(user_id,event_name,event_time).group(user_id) |
2 |
=A1.select(~.sort(event_time).group@o1(event_name).len()>5).skip() |
group 默认是建立分组子集的。
A2 中的 ~ 就表示当前分组子集。每组 user_id 数据量不大,可以全组读入内存。用序表的分组函数 group@o1,归并相邻且相同的 event_name。
执行时间:
2 秒。
这个任务相对复杂,而且数据量达到千万级。esProc 标准版在配置较差的笔记本上,仍然能达到秒级的计算速度。
测试结果:
MYSQL |
esProc |
|
例一 |
16 秒 |
0.4 秒 |
例二 |
16 秒 |
0.9 秒 |
例三 |
- |
2 秒 |
esProc 计算 COUNT DISTINCT 性能完胜 MYSQL。
esProc 提速方案的前提是数据按照 user_id 有序存储,如果有新增数据的话,可能会包括任意 user_id,就不能在有序的历史数据后直接追加了。而重新生成全量有序数据的过程耗时较长,不能频繁进行。
这时候需要麻烦一些,把新数据和旧数据分开有序存储,经过较长时间周期后定时合并。进行去重计数等计算时,把新旧数据有序归并后再计算,仍能利用有序快速去重。
实际上,针对固定不变的历史数据的计算场景就非常多了,也有不少 COUNT DISTINCT 计算亟需加速。这些场景采用 SPL 有序存储可以有效加速 COUNT DISTINCT,而且实施起来非常方便。


英文版