


数据分析编程从 SQL 到 SPL:成绩
学生成绩表 score 的示例数据如下:
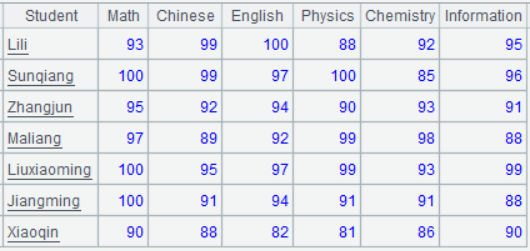
1、统计各科前 3 名
统计结果要如下展示,每个名次一行,每个学科一列,并列名次的多人用逗号连结:

计算结果的格式是固定的,可以用学科生成空的结果集,然后算出各名次的人填充进去即可。SQL 如果按照这种思路编写,要枚举每科的每个名次,将会非常冗长,所以变通成如下的写法:
with t as (select Student, 'Math' Course, Math score from score
union all select Student, 'Chinese' Course, Chinese from score
union all select Student, 'English' Course, English from score
union all select Student, 'Physics' Course, Physics from score
union all select Student, 'Chemistry' Course, Chemistry from score
union all select Student, 'Information' Course, Information from score
),
t1 as (select Student, Course,
rank() over(partition by Course order by score desc) Rnk
from t
),
t2 as (select Course, Rnk, group_concat(Student) Students
from t1
where Rnk<=3
group by Course,Rnk
)
select Rnk `Rank`,
max(if(Course='Math',Students,null)) Math,
max(if(Course='Chinese',Students,null)) Chinese,
max(if(Course='English',Students,null)) English,
max(if(Course='Physics',Students,null)) Physics,
max(if(Course='Chemistry',Students,null)) Chemistry,
max(if(Course='Information',Students,null)) Information
from t2
group by rnk;
SQL 没有分组子集,也就无法针对子集定义计算。要先调整结构,把各科成绩调整到一列,方便统一做排名、汇总学生名称。算出结果后,再用分组操作把结构恢复回去。SQL 中动态处理列名、获得列数不容易,调整结构时要枚举各列。
SPL 容易获得列名和列数,能用动态列预先生成空结果结构;SPL 的集合有序,能按位置找数据、按顺序计算,还有子集合概念,容易找到各个名次的数据子集,直接算出结果:
A |
|
1 |
=file("score.txt").import@t() |
2 |
=3.new(#:rank,${A1.fname().to(2,).(":"/~).concat@c()}) |
3 |
=A2.run( |
A2 中用 3.new() 生成前三名的三行记录, #就是从 1 循环到 3 的序号;
fname()函数得到原始所有字段名,之后的 to(2,) 去除第一个字段,得到所有学科名称;
${各学科名称} 是宏的用法,宏表达式算得的字符串会拼入外部表达式,使得表达式更灵活。
SPL IDE 有很好的交互性,可以单步执行并随时在右边的面板中直观地查看到每一步的结果,选中执行后的 A2,右侧展示生成的空结果结构:
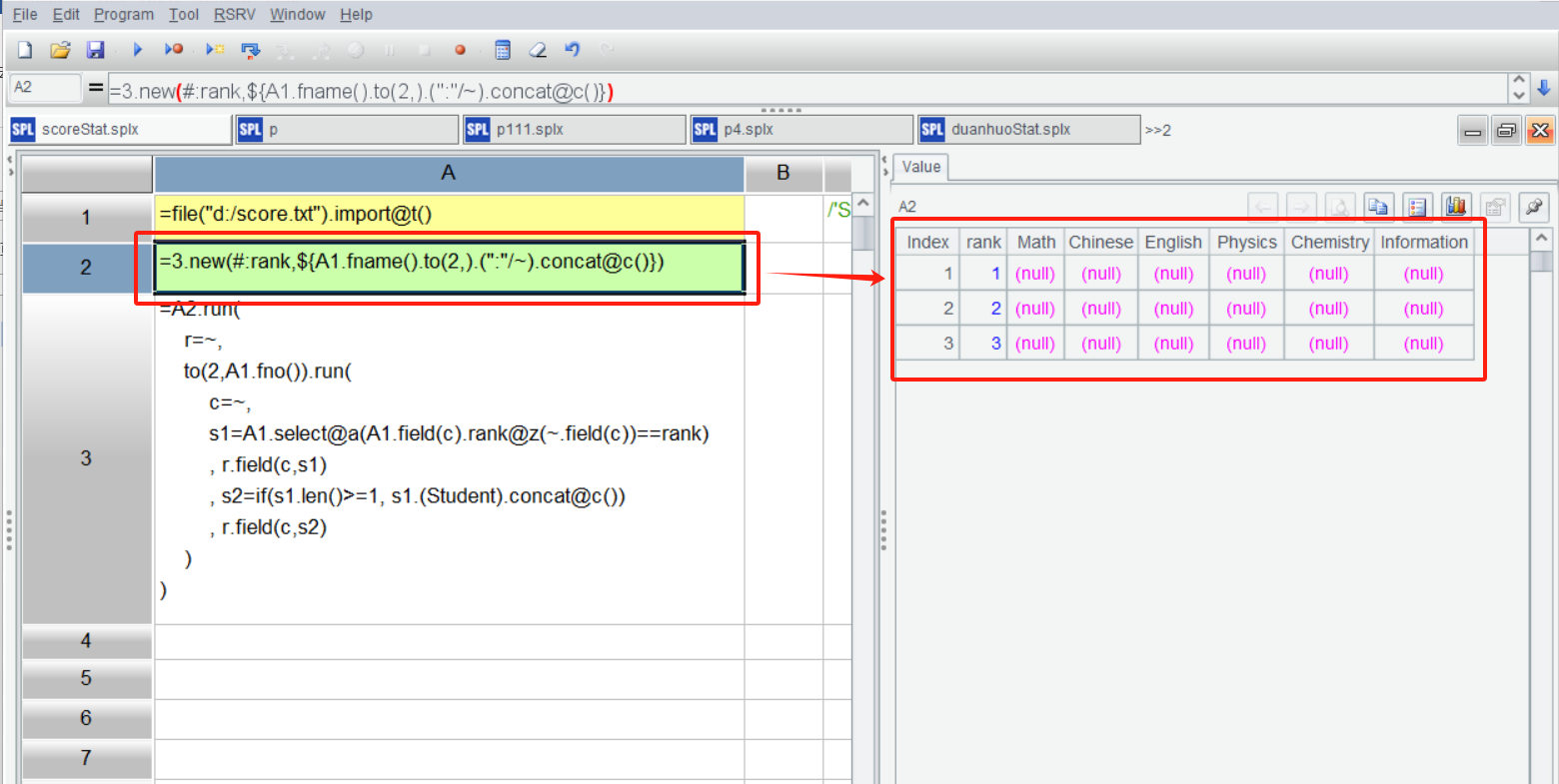
A3 中对每行,每列循环处理,r 是当前行记录,c 是当前列序号,根据这些位置找到相关数据,算出各科各名次的学生 s1,用 field() 函数把 s1 这些子集合设置到当前位置,观察它们符合预期: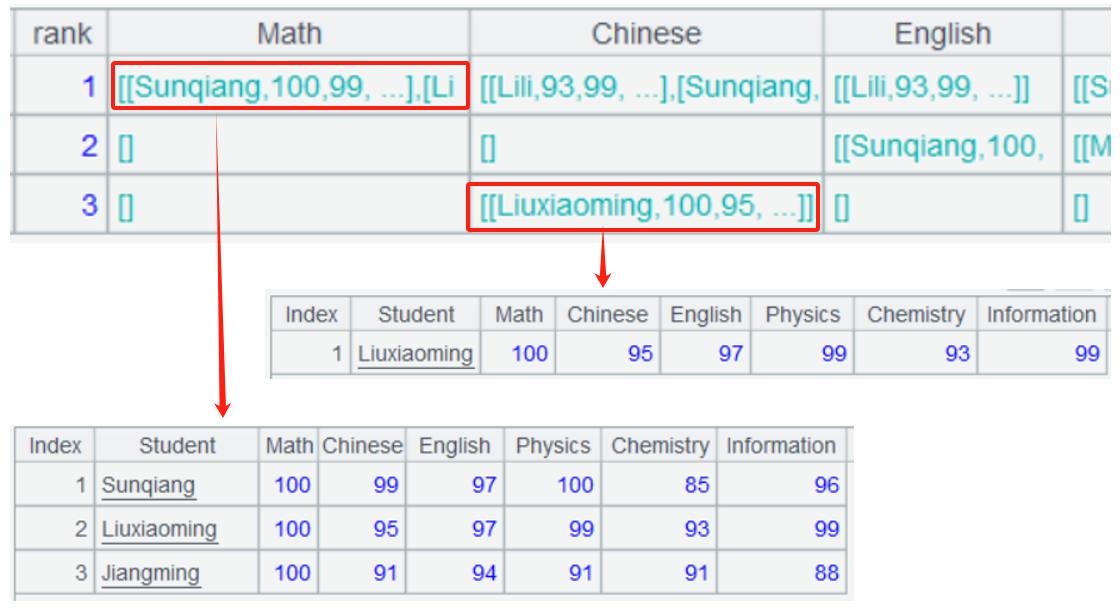
继续用这些子集合 s1 拼出逗号分隔的并列学生 s2,仍然用 field() 函数把 s2 更新入当前位置,就完成统计了。
2、为原表增加一列:成绩最好的 (多个) 学科
SQL 的数据集合无序,计算后不能保证和原表格顺序一致,得人为加个序号字段,完成计算后针对它再排序才能保证结果顺序;
在一行中查找最高分,SQL 仍然需要分组后再排名,而且这些计算不能针对行内数据集合直接做,得先转换结构,把分数弄到一列,算完后再把结构转换回来,这样的 SQL 写出来太麻烦,就不尝试了,有兴趣可以自己尝试下。
SPL 支持有序集合,可以保持住原先的次序。SPL 数据也可以自由组合,同行列或跨行列的数据都可以选为一个子集定义计算,计算后也可以更新 (增加) 入任意位置:
A |
|
1 |
=file("score.txt").import@t() |
2 |
=A1.fname() |
3 |
=A1.derive(A2(~.array().ptop(-1,if(#>1,~))).concat@c():Best) |
A2 用 fname() 得到所有字段名;
A3 中 ~ 代表当前行,~.array()获得当前行所有字段值的子集合,ptop()在这个子集中查找最高分的 (多个) 位置信息,然后在从 A2 中取出最高分位置的学科名称,连接到一起后,用 derive()函数新增为 Best 字段。
3、列出学生 Maliang 低于 90 分的学科 (所有学生) 成绩
SQL 对于这种动态列的处理只能依靠存储过程。
SPL 的集合有序,容易查找数据和所在位置,获得列名、用宏产生动态列也不难:
A |
|
1 |
=file("score.txt").import@t() |
2 |
=A1.select@1(Student:"Maliang") |
3 |
=A2.array().pselect@a(#>1 && ~<90) |
4 |
=A1.fname()(A3).concat@c() |
5 |
=A1.new(Student, ${A4}) |
A3 中用 pselect() 函数查找 Maliang 记录中成绩低于 90 分的列位置,A4 拼出 A3 位置的学科名称,A5 基于 A4 用宏生成动态列。


英文版
第一问统计各科前 3 名的写法遍历量有点大,数据源扩展到 1000 行就慢了,如果是 rank@zi 就会更慢。有没有较快的写法?