


SPL 量化 获取数据
下载数据
我们将股票数据分享在百度网盘上供下载,每工作日更新。
目前可供下载的数据有 A 股的日 K 线数据、股票代码列表和上市公司的基本面数据
下载链接:
https://pan.baidu.com/s/1fTuqDtIjvxzX22EcbeOvtA?pwd=cd5r
下载数据的文件格式为 btx,是 SPL 的特有二进制格式。
btx 称为集文件,是一种简单、开放的二进制文件格式,它覆盖了 csv 文件的所有功能,并且性能要比 csv 文件快 4-5 倍。
SPL 可以支持 btx 文件的操作计算,也支持各种数据源与 btx 之间的相互转换。
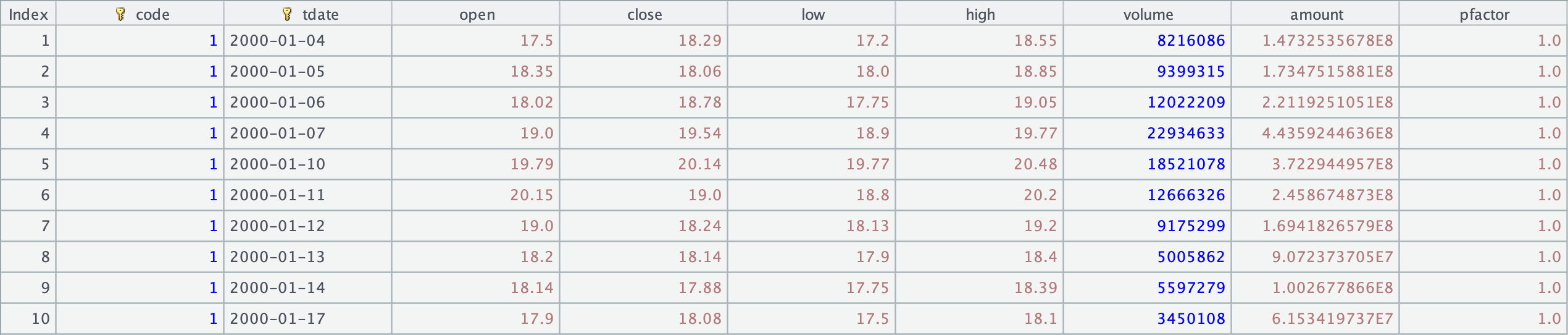
股票日 K 线
文件名: yyyy.trade.btx。
yyyy.trade.btx 文件为yyyy当年的 A 股日线行情;
每天晚上 7、8 点左右会把当天的 A 股日线归并到当年的yyyy.trade.btx 文件中
数据示例:
数据结构:
字段名 |
字段类型 |
含义 |
code |
Integer |
股票代码 |
tdate |
Date |
日期 |
open |
Double |
开盘价 |
close |
Double |
收盘价 |
low |
Double |
最低价 |
high |
Double |
最高价 |
volume |
Long |
成交量 |
amount |
Double |
成交金额 |
pfactor |
Double |
当日价格复权因子 |
注意,股票代码用了整数,而不是常规的字符串,这里 1 表示 000001,2 表示 000002…以此类推。整数的运算性能会远高于字符串。
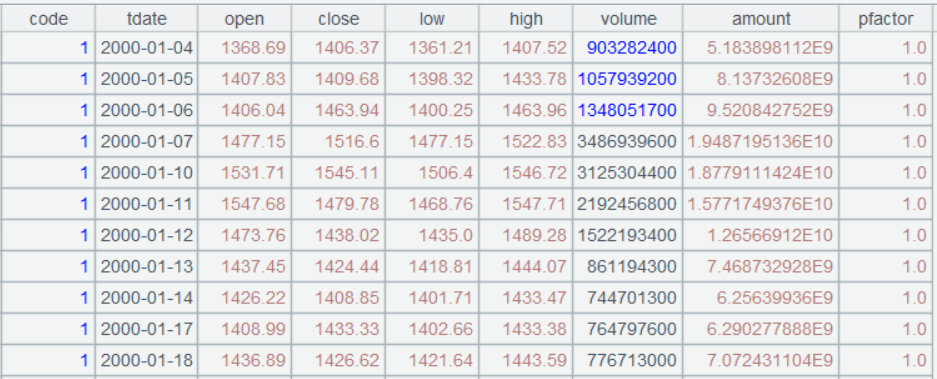
指数日 K 线
文件名: yyyyMMdd.index.btx, yyyy.index.btx。
yyyyMMdd.index.btx 文件为yyyyMMdd日之前的指数日线行情;
yyyy.index.btx 文件为yyyy当年的指数日线行情;
每天晚上 7、8 点左右会把当天的指数日线归并到当年的yyyy.index.btx 文件中
数据示例:
数据结构:
字段名 |
字段类型 |
含义 |
code |
Integer |
股票代码 |
tdate |
Date |
日期 |
open |
Double |
开盘价 |
close |
Double |
收盘价 |
low |
Double |
最低价 |
high |
Double |
最高价 |
volume |
Long |
成交量 |
amount |
Double |
成交金额 |
pfactor |
Double |
当日价格修正因子 |
注意,股票代码用了整数,而不是常规的字符串,这里 1 表示 000001,2 表示 000002…以此类推。整数的运算性能会远高于字符串。
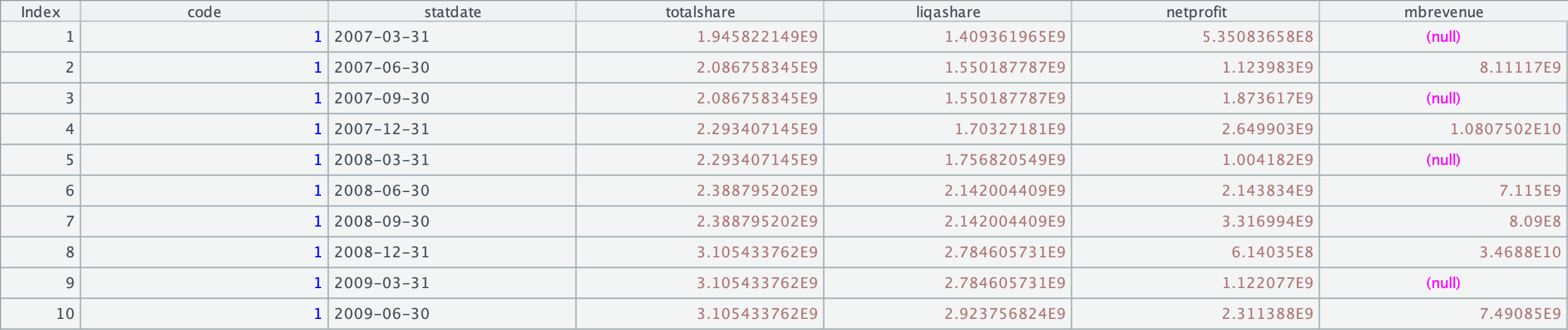
公司基本面
文件名称:company.btx。
提供 2007 年至今的财务数据,每季度一条。
数据示例:
数据结构:
字段名 |
字段类型 |
含义 |
code |
Integer |
股票代码 |
statdate |
Date |
财报统计的季度的最后一天 |
totalshare |
Long |
总股本 |
liqashare |
Long |
流通股本 |
netprofit |
Double |
净利润 (元) |
mbrevenue |
Double |
主营营业收入 (元) |
未来会再补充更多信息
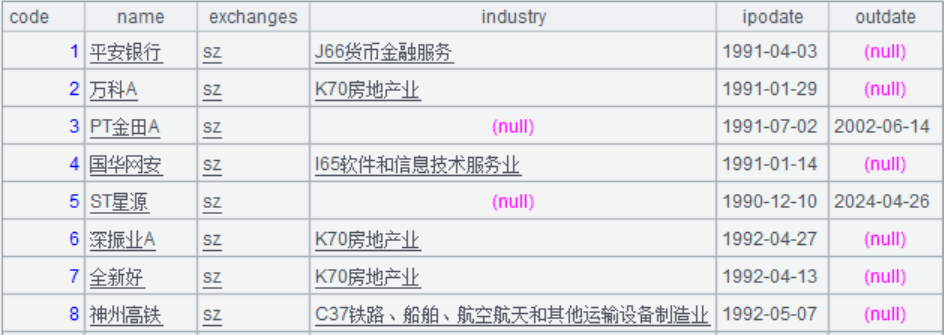
股票代码列表
文件名称:stock.btx。
提供股票基础信息,包括股票代码、名称、所属行业、上市日期、退市日期等。
数据示例:
数据结构:
字段名 |
字段类型 |
含义 |
code |
Integer |
股票代码 |
name |
String |
股票名 |
exchanges |
String |
中国三大交易所的简写 |
industry |
String |
所属行业 |
ipodate |
Date |
上市日期 |
outdate |
Date |
退市日期 |
指数代码列表
文件名称:indexlist.csv。
提供指数基础信息,包括指数代码、名称、上市日期、退市日期等。
数据示例:
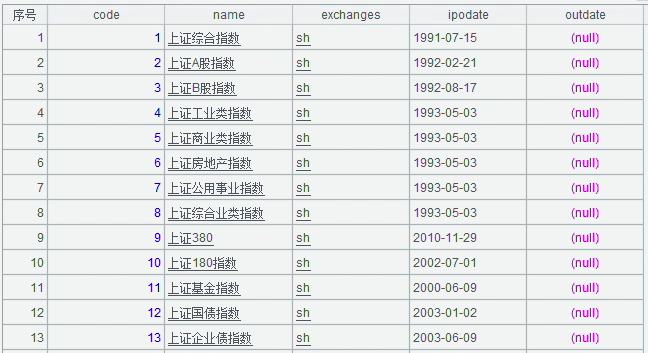
数据结构:
字段名 |
字段类型 |
含义 |
code |
Integer |
股票代码 |
name |
String |
股票名 |
exchanges |
String |
中国三大交易所的简写 |
ipodate |
Date |
上市日期 |
outdate |
Date |
退市日期 |
数据读取
股票代码列表
读取股票列表可以用 T 函数全部读入。
A |
|
1 |
=T("stock.btx") |
运行效果:
指数代码列表
A |
|
1 |
=file("indexlist.csv").import@tc() |
运行效果:
股票日 K 线
将下载的所有yyyy.trade.btx 文件放到同一路径下。
读数脚本代码如下:
A |
|
1 |
=end=ifn(end,now()) |
2 |
=to(year(start),year(end)).(file(~/".trade.btx")).select(~.exists()) |
3 |
=cl=if(ifa(cl), cl.sort(),cl) |
4 |
=if(cl, A2.( ~.iselect@b(cl,code)), A2.(~.cursor@b()) ) |
5 |
=A4.merge(code,tdate).select(tdate>=start && tdate<=end) |
6 |
return A5.fetch@x() |
脚本参数:
cl |
股票代码序列,如 [600000,600001];可以为单值,如 600000;填空表示全读 |
start |
开始日期,如 2024-01-01 |
end |
截止日期,如 2024-12-31。end 为空时截止到当前日期 |
脚本保存为 loadkday.splx,此脚本可返回一支或多支股票任意时间段的 K 线数据。
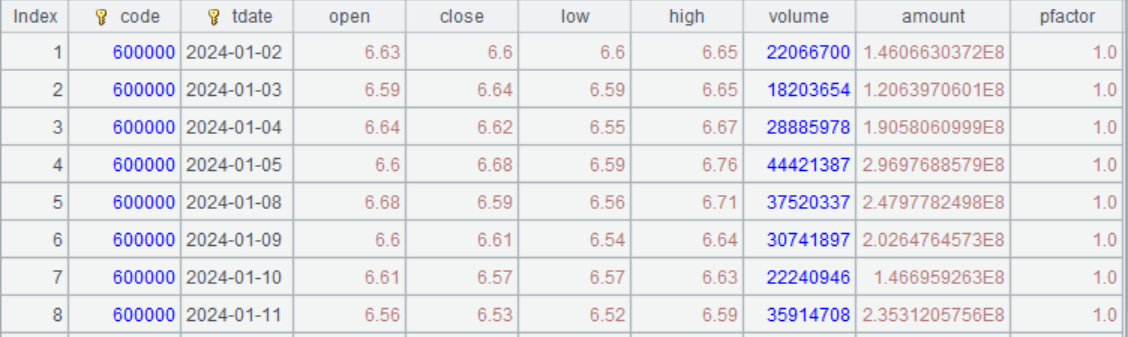
如读取一支股票的 k 线数据:
A |
||
1 |
600000 |
股票代码 |
2 |
2024-01-01 |
开始日期 |
3 |
2024-12-31 |
截止日期 |
4 |
=call("loadkday.splx",A1,A2,A3) |
调用脚本,返回 600000 股票 2024 年数据 |
5 |
=call("loadkday.splx",A1,A2) |
end为空,截止到当前日期 |
运行效果:
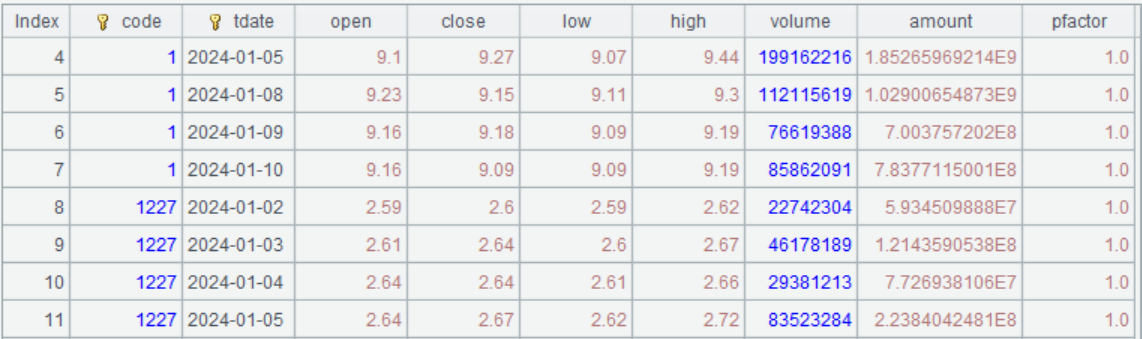
读取多支股票数据,比如读取所有银行股或全部 A 股:
A |
||
1 |
=T("stock.btx").select(industry=="J66货币金融服务 ").(code) |
读取银行股票代码列表 |
2 |
2024-01-01 |
开始日期 |
3 |
2024-01-10 |
截止日期 |
4 |
=call("loadkday.splx",A1,A2,A3) |
调用脚本,返回银行股 2024 年数据 |
5 |
=call("loadkday.splx",A1,A2) |
end为空,截止到当前日期 |
6 |
=call("loadkday.splx",,A2,A3) |
cl为空,读取全部 A 股 |
运行效果:
对于经常使用的脚本,也可以用 register 登记成一个函数来使用。
代码示例:
A |
||
1 |
=register("loadkday","loadkday.splx") |
将脚本登记为函数 |
2 |
=T("stock.btx").select(industry=="J66货币金融服务 ").(code) |
读取银行股票代码列表 |
3 |
2024-01-01 |
开始日期 |
4 |
2024-01-10 |
截止日期 |
5 |
=loadkday(A2,A3,A4) |
返回开始到截止日期的数据 |
6 |
=loadkday(A2,A3) |
end为空,截止到当前日期 |
7 |
=loadkday(,A3,A4) |
cl为空,读取全部股票 |
运行效果同上。
指数日 K 线
将下载的yyyy.index.btx 和yyyyMMdd.index.btx 文件放到同一路径下。
读数脚本代码如下:
A |
|
1 |
=year(now()) |
2 |
=end=ifn(end,now()) |
3 |
=if(year(start)<A1,(A1-1)*10000+1231)|if(year(end)==A1,A1) |
4 |
=A3.(file(~/".index.btx")).select(~.exists()) |
5 |
=cl=if(ifa(cl), cl.sort(),cl) |
6 |
=if(cl, A4.( ~.iselect@b(cl,code)), A4.(~.cursor@b()) ) |
7 |
=A6.merge(code,tdate).select(tdate>=start && tdate<=end) |
8 |
return A7.fetch@x() |
脚本参数:
cl |
指数代码序列,如 [1,2];可以为单值,如 1;填空表示全读 |
start |
开始日期,如 2024-01-01 |
end |
截止日期,如 2024-12-31。end 为空时截止到当前日期 |
脚本保存为 loadkindex.splx,此脚本可返回一支或多支指数任意时间段的 K 线数据。
如读取一支指数的 k 线数据:
A |
||
1 |
1 |
指数代码 |
2 |
2024-01-01 |
开始日期 |
3 |
2024-12-31 |
截止日期 |
4 |
=call("loadkindex.splx",A1,A2,A3) |
调用脚本,返回 000001 指数 2024 年数据 |
5 |
=call("loadkindex.splx",A1,A2) |
end为空,截止到当前日期 |
运行效果:
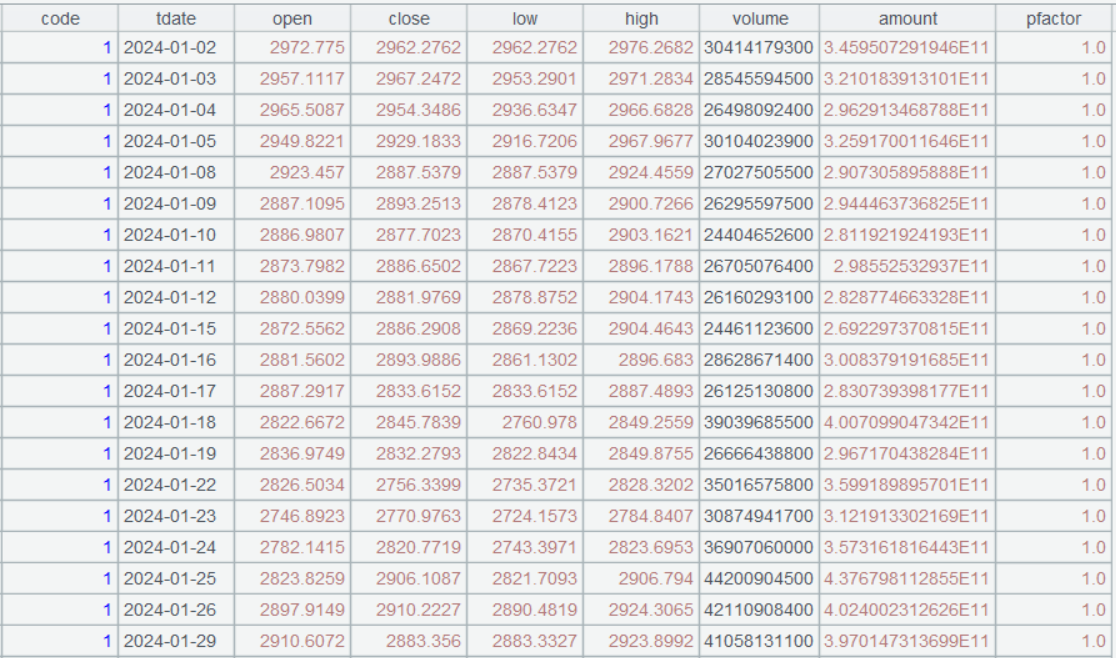
读取多个指数数据:
A |
||
1 |
=[399001,399002] |
指数代码列表 |
2 |
2025-01-01 |
开始日期 |
3 |
2025-01-10 |
截止日期 |
4 |
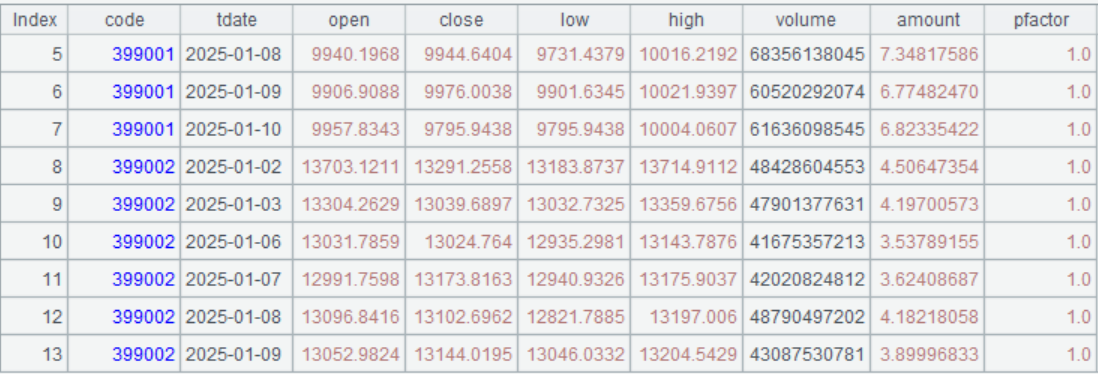
=call("loadkindex.splx",A1,A2,A3) |
调用脚本,返回多个指数 |
5 |
=call("loadkindex.splx",A1,A2) |
end为空,截止到当前日期 |
6 |
=call("loadkindex.splx",,A2,A3) |
cl为空,读取全部指数 |
运行效果:
对于经常使用的脚本,也可以用 register 登记成一个函数来使用。
代码示例:
A |
||
1 |
=register("loadkindex","loadkindex.splx") |
将脚本登记为函数 |
2 |
=[399001,399002] |
指数列表 |
3 |
2025-01-01 |
开始日期 |
4 |
2025-01-10 |
截止日期 |
5 |
=loadkindex(A2,A3,A4) |
返回开始到截止日期的数据 |
6 |
=loadkindex(A2,A3) |
end为空,截止到当前日期 |
7 |
=loadkindex(,A3,A4) |
cl为空,读取全部指数 |
运行效果同上。
基本面
(1) 直接读入全部 btx 文件。
当数据文件不大时,可以直接全部读入内存。
代码示例:
A |
B |
|
1 |
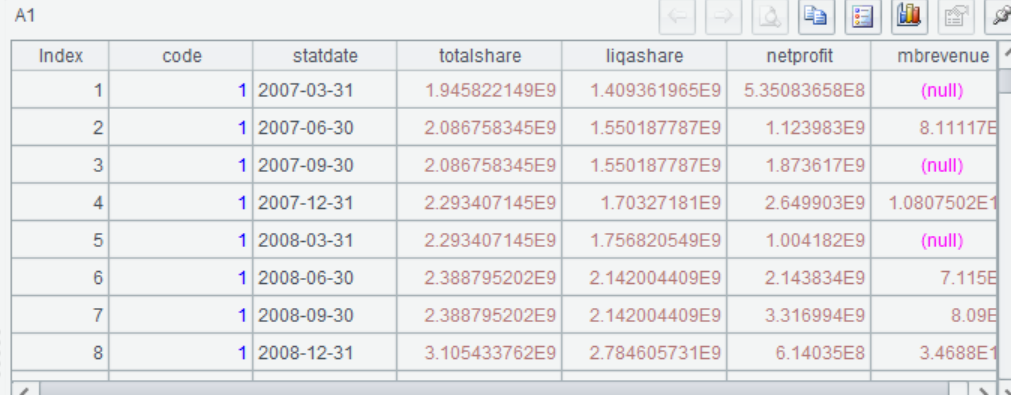
=T("company.btx") |
读入基本面数据 |
2 |
=A1.select(code==600000 && statdate>=date("2024-01-01") && statdate<=date("2024-12-31")) |
选出 600000 股票 2024 年数据 |
运行效果:
A1
A2

(2) 只读取某些股票的基本面
也可以用脚本方式只读取某些股票的基本数据。
脚本代码:
A |
|
1 |
=file("company.btx") |
2 |
=if(cl, A1.iselect@b(cl,code), A1.cursor@b()) |
3 |
=end=ifn(end,now()) |
4 |
=A2.select(statdate>=start &&statdate<=end) |
5 |
=A4.fetch() |
6 |
>A2.close() |
7 |
return A5 |
脚本参数:
cl |
股票代码序列,如 [600000,600001];可以为单值,如 600000;也可为空表示全读 |
start |
开始日期,如 2024-01-01 |
end |
截止日期,如 2024-12-31。end 为空时截止到当前日期 |
脚本保存为 loadcompany.splx,此脚本可返回一支或多支股票任意时间段的基本面。
如读取一支股票的基本面:
A |
B |
|
1 |
600000 |
股票代码 |
2 |
2020-01-01 |
开始日期 |
3 |
2020-12-31 |
截止日期 |
4 |
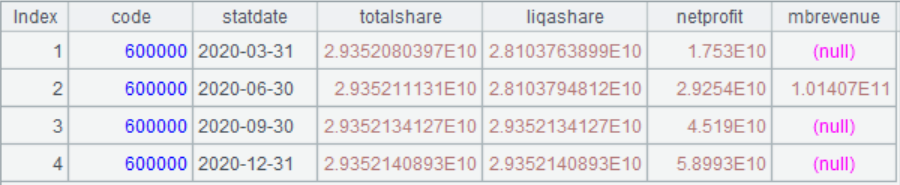
=call("loadcompany.splx",A1,A2,A3) |
调用脚本,返回 2020 年基本面 |
5 |
=call("loadcompany.splx",A1,A2) |
end为空,截止到当前日期 |
运行效果:
读入多支股票的基本面,如读取所有银行股或全部 A 股。
A |
B |
|
1 |
=T("stock.btx").select(industry=="J66货币金融服务 ").(code) |
股票代码序列 |
2 |
2020-01-01 |
开始日期 |
3 |
2020-12-31 |
截止日期 |
4 |
=call("loadcompany.splx",A1,A2,A3) |
调用脚本,返回银行股 2020 年基本面 |
5 |
=call("loadcompany.splx",A1,A2) |
end为空,截止到当前日期 |
6 |
=call("loadcompany.splx",,A2,A3) |
cl为空,读取全部股票 |

